在服务器运维工作中,实时掌握系统运行状态与MySQL数据库性能,是及时排查故障、保障服务稳定的关键。本文整理了系统层面与MySQL层面的核心监控指标及实操命令,涵盖从基础资源到数据库深层性能的全维度监控方法,适用于运维人员日常巡检与问题定位。
一、系统相关监控
系统基础资源的负载情况直接影响服务可用性,需重点监控CPU、内存、网络、磁盘等核心指标,以下为具体监控方法与操作命令。
| 系统相关的监控项 |
|---|
| CPU |
| 内存 |
| 网络流量 |
| 磁盘利用率 |
| 磁盘IOPS |
1. CPU负载
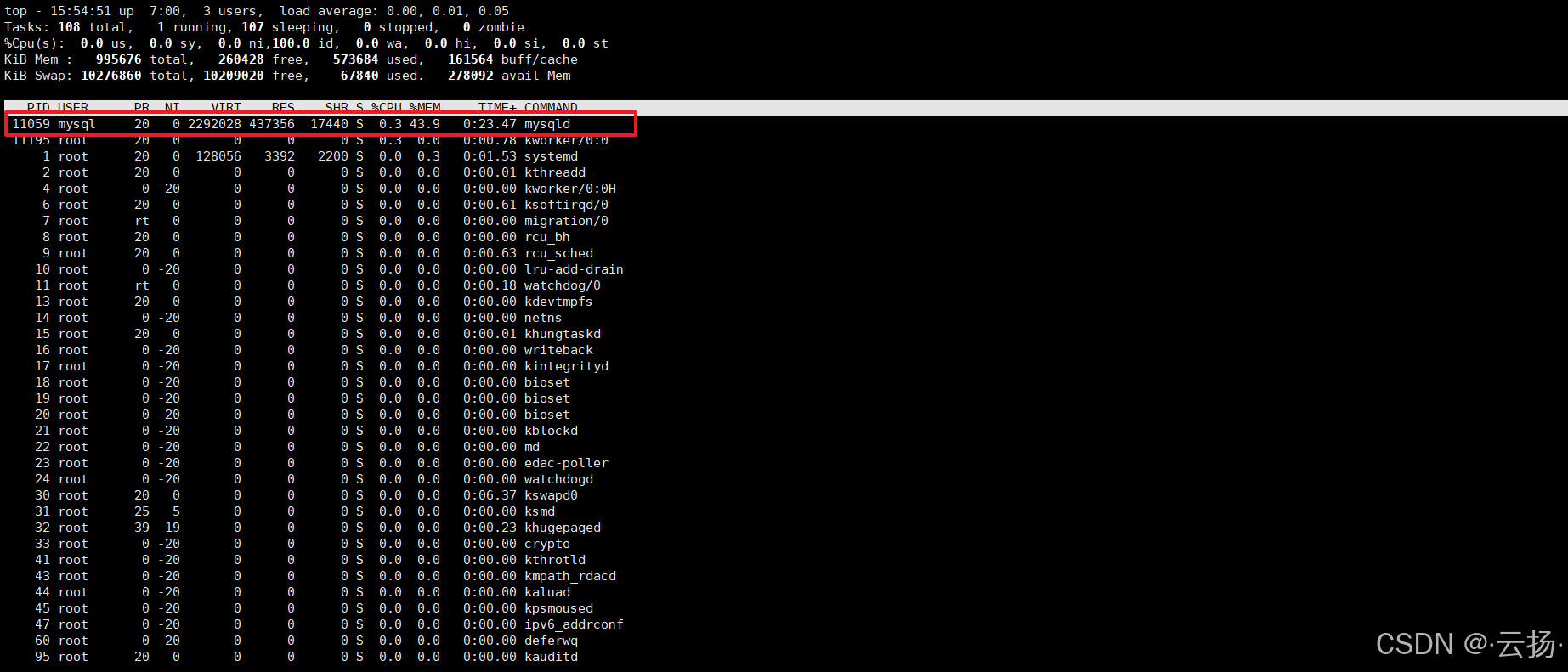
通过top命令可实时查看CPU使用率、进程占用情况等信息,帮助判断CPU是否存在过载。
plain
top执行后将展示CPU整体负载、各进程CPU占用率等动态数据,若持续出现高负载(如1分钟负载值远超CPU核心数),需进一步排查占用资源的进程。
2. 内存使用
使用free命令查看内存占用,支持按GB或MB单位展示,便于快速判断内存是否充足。
plain
# 以GB为单位展示内存信息
free -g
# 以MB为单位展示内存信息
free -m输出结果中,"available"字段代表可实际分配给应用的内存,若该值持续过低,需警惕内存泄漏或资源分配不足问题。

3. 网络流量
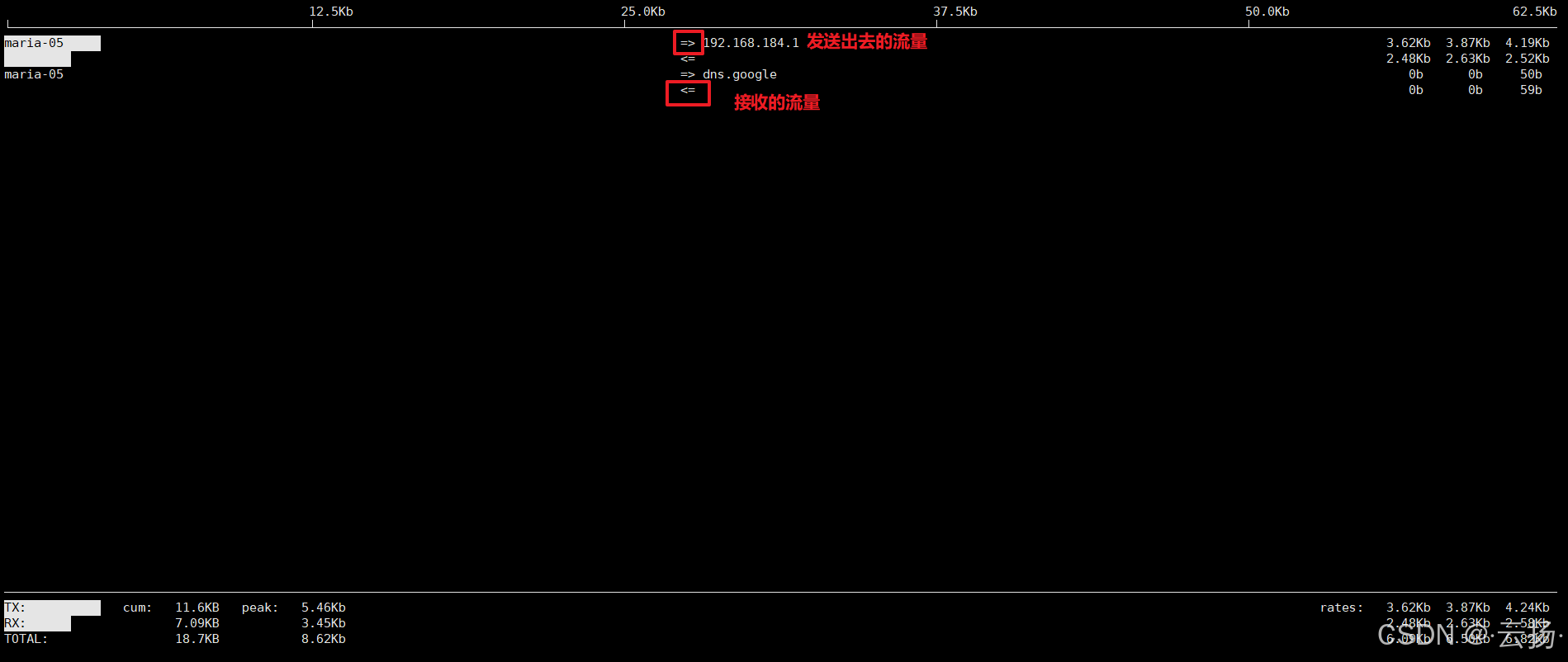
iftop命令可实时监控网络接口的流量情况,包括进出带宽、连接IP等细节。若系统未预装iftop,需通过以下步骤安装:
bash
# 尝试直接安装iftop
yum install -y iftop
# 若出现"No package iftop available"错误,先安装EPEL源
yum install -y epel-release
# 再次安装iftop
yum install -y iftop
# 安装成功后执行,监控网络流量
iftop通过iftop可快速定位异常流量来源,排查是否存在网络攻击或无效连接占用带宽。
4. 磁盘利用率
df -Th命令可查看各磁盘分区的使用率、文件系统类型等信息,避免磁盘满导致服务中断。
plain
df -Th重点关注"Use%"字段,若某分区使用率接近或超过90%,需及时清理冗余文件(如日志、临时文件)或扩展磁盘容量。

5. 磁盘IOPS
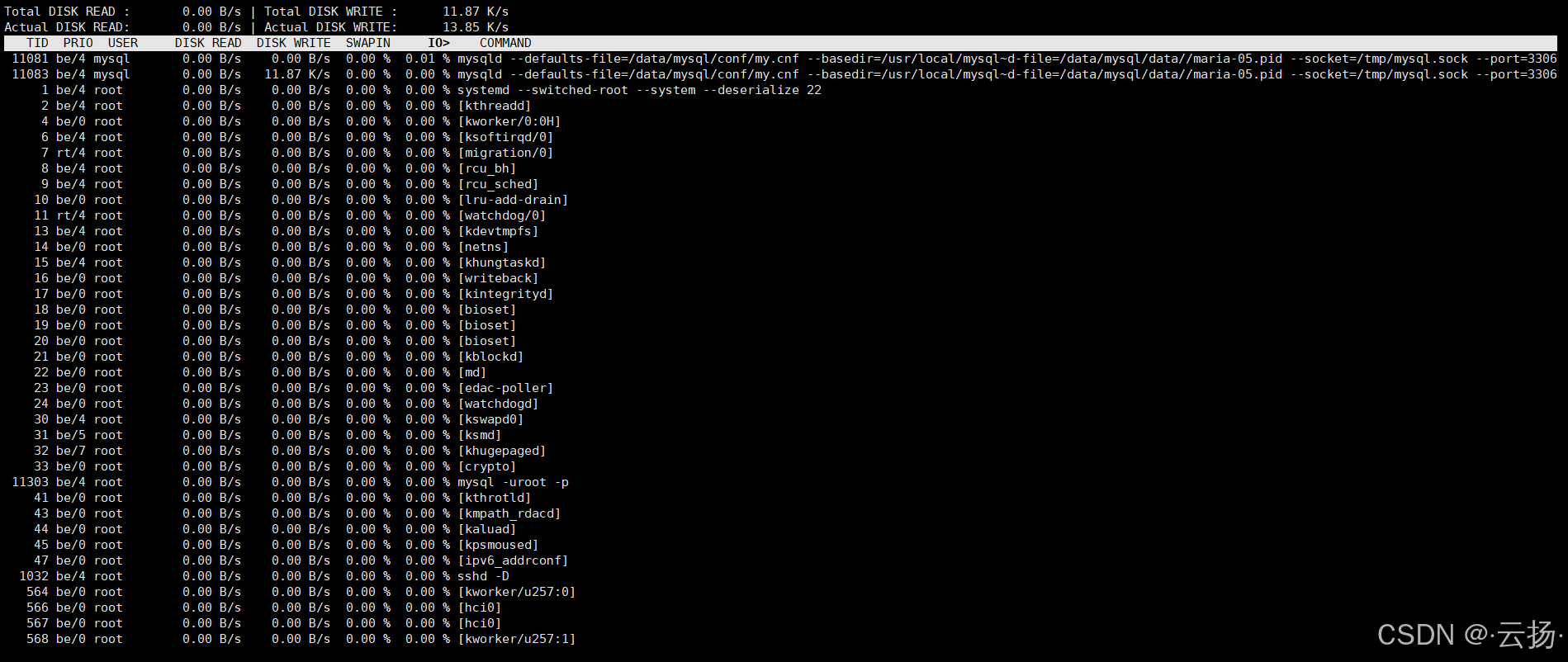
iotop命令用于监控磁盘IO读写情况,包括进程IO占用、读写速度等,定位磁盘IO瓶颈。
plain
iotop若出现磁盘IO等待时间过长("%util"字段接近100%),需检查是否存在频繁读写的进程,或优化磁盘存储方案(如更换SSD)。
二、MySQL相关监控
MySQL作为核心数据库,其性能、锁状态、复制情况等直接影响业务稳定性,需从多维度开展监控。
1. MySQL状态监控
| MySQL状态相关的监控项 |
|---|
| MySQL的进程状态 |
| QPS |
| TPS |
| 增、删、查、改的数量 |
| 慢查询数量 |
| 日志缓冲区是否够用 |
| 临时表相关 |
(1)进程状态与启动时间
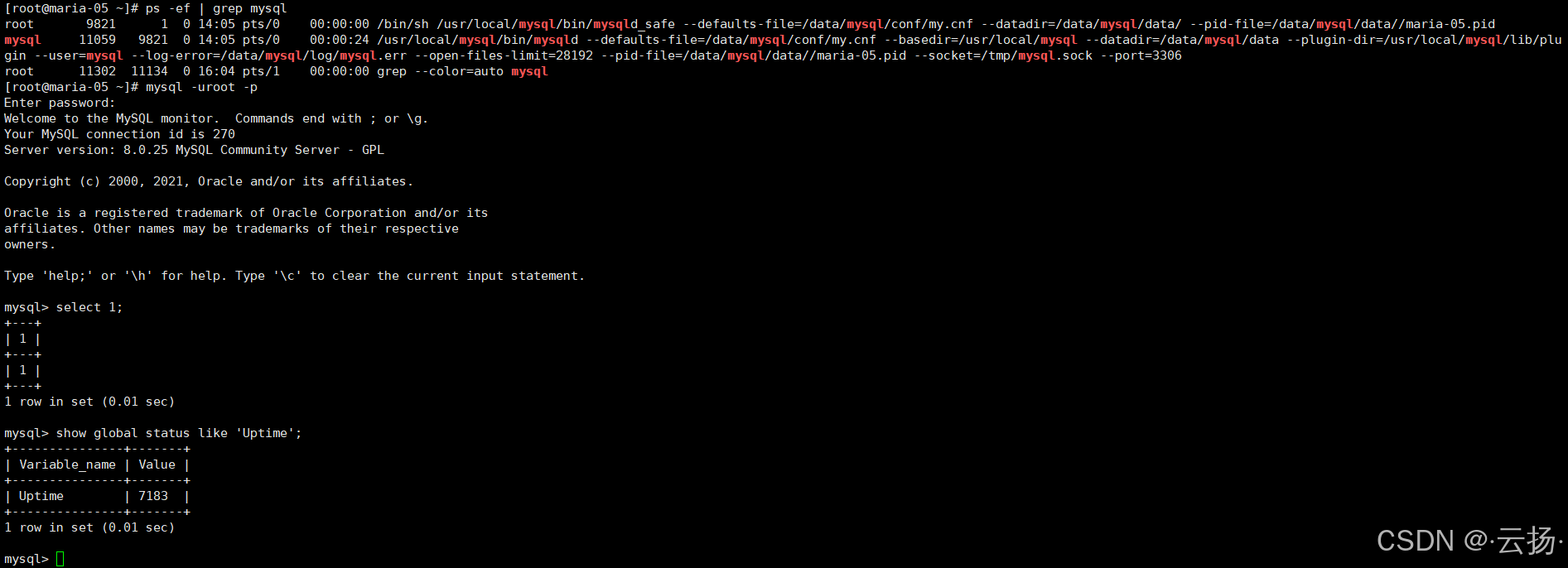
通过以下命令确认MySQL进程是否正常运行,及服务启动时长:
bash
# 查看MySQL进程
ps -ef | grep mysql
# 在MySQL客户端执行,查看服务启动时间(单位:秒)
show global status like "Uptime";
# 快速验证MySQL连接可用性
select 1;若ps命令无MySQL进程,或select 1无法执行,需检查MySQL服务是否异常停止并重启。
(2)QPS(每秒查询数)
QPS反映MySQL处理查询的能力,计算方式为两次查询"Queries"指标的差值除以时间间隔(通常取60秒):
plain
# 第一次查询总查询数,记录为Q1
show global status like "Queries";
# 60秒后执行第二次查询,记录为Q2
show global status like "Queries";
# 计算QPS:QPS = (Q2 - Q1)/60QPS突增或骤降均需关注,突增可能导致数据库压力过大,骤降可能是业务异常或连接中断。

(3)TPS(每秒事务数)
若MySQL开启GTID,建议通过GTID增长率计算TPS(一个事务对应一个GTID);若未开启,可参考"Con_commit"与"Con_rollback"指标(需注意:仅显式执行commit/rollback后数值才会增加,结果存在一定偏差):
plain
# 查看显式commit次数
show global status like "Con_commit";
# 查看显式rollback次数
show global status like "Con_rollback";
(4)增删改查(CRUD)数量
通过以下命令查看MySQL各类操作的累计次数,分析业务访问模式:
plain
# 查看插入操作次数
show global status like "Com_insert";
# 查看删除操作次数
show global status like "Com_delete";
# 查看查询操作次数
show global status like "Com_select";
# 查看更新操作次数
show global status like "Com_update";
(5)慢查询数量
慢查询会占用大量数据库资源,需通过"Slow_queries"指标监控慢查询次数:
plain
show global status like "Slow_queries";若该数值持续增长,需结合慢查询日志(需提前开启)分析慢查询SQL,优化索引或语句结构。

(6)日志缓冲区可用性
"innodb_log_waits"指标反映日志缓冲区不足导致的等待次数,若数值较大,需调整innodb_log_buffer_size参数:
plain
show global status like "innodb_log_waits";
(7)临时表创建情况
临时表过多可能导致磁盘IO压力增大,需监控内存临时表与磁盘临时表的创建次数:
plain
# 查看磁盘临时表创建次数
show global status like "Created_tmp_disk_tables";
# 查看内存临时表创建次数
show global status like "Created_tmp_tables";若磁盘临时表占比过高,需优化SQL语句(如避免大表关联、合理使用索引)。

2. MySQL锁监控
| MySQL锁相关的监控项 |
|---|
| 表锁情况 |
| InnoDB正在等待行锁的数量 |
| 行锁总耗时 |
| 行锁平均耗时 |
| 行锁最久耗时 |
| 行锁发生次数 |
锁等待会导致业务响应延迟,需重点监控表锁与行锁状态:
(1)表锁等待次数
"table_locks_waited"指标反映表锁等待情况,数值越大说明表锁竞争越激烈:
plain
show global status like "table_locks_waited";
(2)行锁相关指标
InnoDB行锁的等待与耗时情况,可通过以下命令全面监控:
plain
# 正在等待行锁的数量
show global status like "innodb_row_lock_current_waits";
# 行锁总耗时(单位:毫秒)
show global status like "innodb_row_lock_time";
# 行锁平均耗时(单位:毫秒)
show global status like "innodb_row_lock_time_avg";
# 行锁最久耗时(单位:毫秒)
show global status like "innodb_row_lock_time_max";
# 行锁发生次数
show global status like "innodb_row_lock_waits";若行锁等待次数多、耗时久,需排查长事务或优化SQL的行锁范围。

3. MySQL连接监控
| MySQL连接相关的监控项 |
|---|
| 连接使用率 |
| 活跃连接数 |
| 客户端异常中断数 |
连接数异常可能导致业务无法访问数据库,需监控连接使用率、活跃连接等指标:
(1)连接使用率
连接使用率=当前连接数/最大连接数,若使用率过高(如超过80%),需调整max_connections参数:
plain
# 查看当前连接数
show global status like "threads_connected";
# 查看最大连接数
show global variables like "max_connections";
# 计算连接使用率:connect_used_ratio = threads_connected/max_connections
(2)活跃连接数
"Threads_running"指标反映当前正在执行SQL的连接数,若数值持续过高,说明数据库压力较大:
plain
show global status like "Threads_running";
(3)客户端异常中断数
"Aborted_clients"指标记录客户端异常中断的连接数,若数值突增,需检查网络稳定性或客户端配置:
plain
show global status like "Aborted_clients";
4. MySQL复制监控
| MySQL复制相关的监控项 |
|---|
| I/O线程和SQL线程 |
| 主从延迟 |
| 从库read only |
主从复制异常会导致数据不一致,需监控复制线程状态、主从延迟等:
(1)复制线程状态
通过show slave status\G查看I/O线程与SQL线程是否正常(均为"Yes"表示正常):
plain
show slave status\G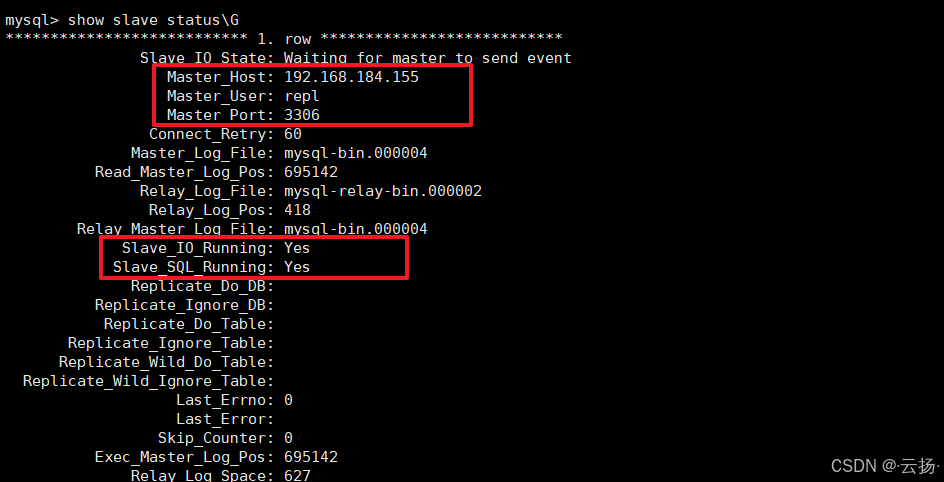
(2)主从延迟
- 基础判断:"Seconds_Behind_Master"字段为0时通常表示无延迟,但需注意:网络中断时该值可能仍为0,存在"假无延迟"情况。
- 位点复制校验:查看
Master_Log_File与Relay_Master_Log_File是否一致,Read_Master_Log_Pos与Exec_Master_Log_Pos是否一致,不一致则存在延迟。 - GTID复制校验:查看
Retrieved_Gtid_Set(已获取的GTID)与Executed_Gtid_Set(已执行的GTID),若后者落后较多,说明存在延迟。

(3)从库只读设置
为避免从库数据被误修改,建议从库开启read_only,主库关闭:
plain
show global variables like "read_only";
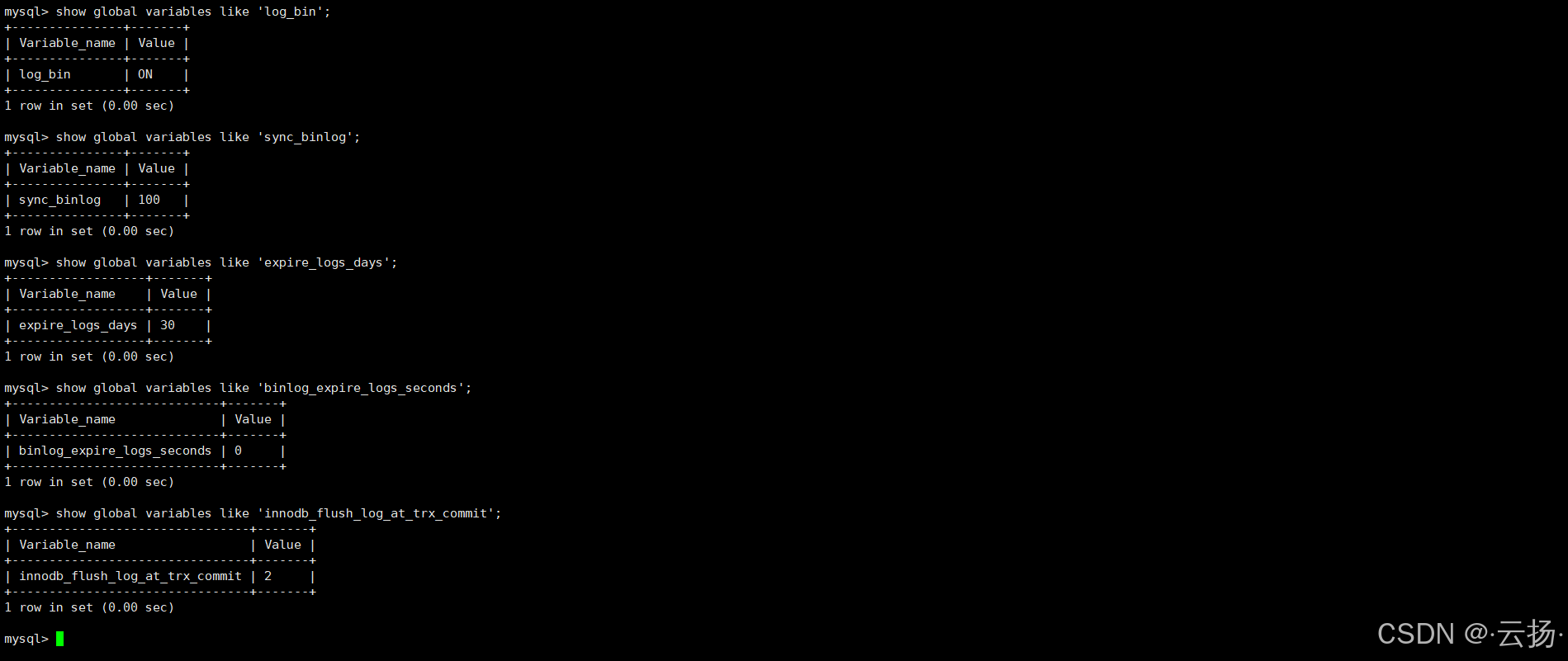
5. MySQL参数监控
| MySQL参数相关的监控项 |
|---|
| log_bin |
| sync_binlog |
| expire_logs_days或者binlog_expire_logs_seconds |
| innodb_flush_log_at_trx_commit |
关键参数配置影响MySQL性能与数据安全性,需重点检查以下参数:
| 参数 | 说明 | 建议配置 |
|---|---|---|
log_bin |
是否开启二进制日志(用于数据恢复、主从复制) | 建议开启 |
sync_binlog |
控制binlog刷盘频率,影响数据一致性 | 数据一致性要求高时设为1 |
expire_logs_days/binlog_expire_logs_seconds |
binlog过期时间(前者按天,后者按秒) | 不建议过小,避免数据恢复失败或主从复制异常 |
innodb_flush_log_at_trx_commit |
控制redo log刷盘频率,影响事务安全性 | 数据一致性要求高时设为1 |
6. 业务相关监控
| 业务相关的监控项 |
|---|
| 自增值的使用率 |
| 表数据量 |
(1)自增值使用率
自增值耗尽会导致插入操作失败,需根据主键类型(int/bigint)计算使用率:
plain
# 查看表自增值(需替换table_schema与table_name)
select auto_increment from information_schema.tables where table_schema='maria' and table_name='user_info';- 主键为int(非负):最大值为
2^32-1,即 4294967295,使用率=当前自增值/(2^32-1) - 主键为bigint(非负):最大值为
2^48-1,使用率=当前自增值/(2^48-1)

(2)表数据量
表数据量过大易导致查询缓慢、维护困难,需监控并在达到阈值时触发告警:
plain
# 查看表数据量(需替换table_schema与table_name)
select table_rows from information_schema.tables
where table_schema='maria' and table_name='user_info';
总结
本文覆盖的系统与MySQL监控方法,是运维工作的基础工具。实际应用中,建议结合监控平台(如Prometheus+Grafana)实现指标可视化与自动告警,同时根据业务场景调整监控频率与阈值。通过常态化监控,可提前发现潜在风险,减少服务中断概率,保障系统与数据库稳定运行。