文章目录
C语言笔记14:结构体、联合体、枚举
一、结构体的声明
声明格式
c
struct tag
{
member-list;
}variable-list;声明和初始化示例
c
struct Stu
{
char name[20];
int age;
char gender[5];
char id[20];
}
int main()
{
struct Stu s0 = {"张飞",20,"男","2016010601"};
struct Stu s1 = {.age = 21,.name = "朱棣",.gender = "男",.id = "2026010602"};
return 0;
}特殊声明:匿名结构体类型
c
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}y,*p;这个赋值合法吗?
c
p = &x;答案是不合法,因为&x类型和p的类型不一样。
结构体自引用
c
struct Node
{
int data;
struct Node next;
};
struct Node
{
int data;
struct Node* next;
};上面两个自引用的方式中,下面的是正确的
加入typedef的自引用
c
typedef struct Node
{
int data;
Node* next;
}Node;
typedef struct Node
{
int data;
struct Node* next;
}Node;下面的是正确的。
二、结构体内存对齐
内存对齐规则
每个结构体变量都有一个对齐数 ,这个对齐数的值是编译器默认对齐数和该成员变量大小的较小值 。成员变量对齐到对齐数的整数倍。结构体 的大小 要是 所有成员变量中最大对齐数的整数倍。
练习
c
struct S1
{
char c1;
int i;
char c2;
};
struct S3
{
double d;
char c;
int i;
};
struct S4
{
char c1;
struct S3 s3;
double d;
};
#include <stdio.h>
int main()
{
printf("%d\n", sizeof(struct S1));//12
printf("%d\n", sizeof(struct S4));//32
}为什么存在内存对齐
内存对齐是拿空间换时间的做法,CPU每次访问的地址都是4字节(32位)或者8字节(64位),并且变量的起始位置也是4或8字节的倍数,结构体内部遵循了内存对齐的规则之后,CPU想取出结构体内的int或者double这种类型的变量,就不会面临一个int横跨两个4字节或者8字节块的情况。就只用进行一次内存读取,提高了效率。
声明结构体最佳实践
让占用空间小的成员尽量集中在一起
c
struct s1
{
char a;
int b;
char c;
};
struct s2
{
char a;
char b;
int c;
};修改默认对齐数
c
//设置为1
#pragma pack(1)
struct s1
{
char a;
int b;
char c;
};
//取消设置
#pragma pack()
#include <stdio.h>
int main()
{
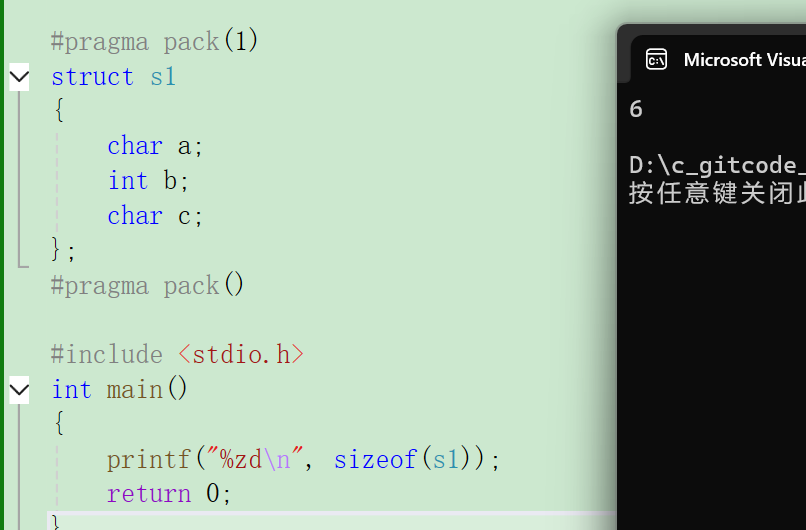
printf("%zd\n",sizeof(s1));
return 0;
}结果:
三、结构体传参
c
struct S
{
int data[1000];
int num;
};
struct S s = {{1,2,3,4},1};
#include <stdio.h>
void print1(struct S s)
{
printf("%d\n",s.num)
}
void print2(struct S* ps)
{
printf("%d\n",ps->num);
}
int main()
{
print1(s);
print2(&s);
return 0;
}哪个好?
print1是传值,传参压栈就是多个指令push。造成极大开销。print2是传址,开销较小。
四、位段
声明结构体时,在成员变量后面加
:数字就实现了位段。位段的类型必须是整型。位段通常用于节省结构体空间。在网络数据报中常用。
c
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
#include <stdio.h>
int main()
{
struct A a = { 1,3,255,1 };
printf("%zd\n", sizeof(A));
return 0;
}&a:0x005DFE1C
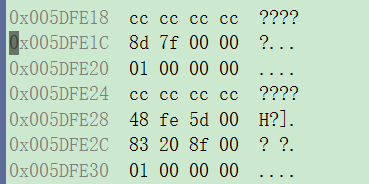
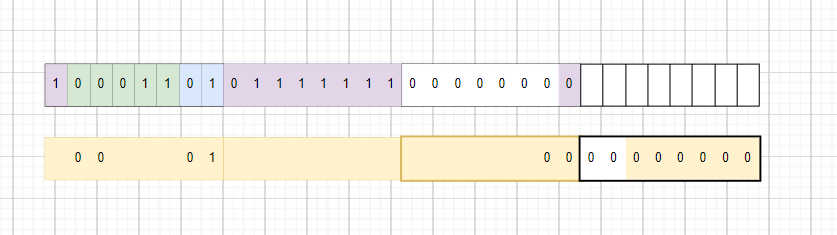
1.int 位段被当成有符号数还是⽆符号数是不确定的。
2.位段中最⼤位的数⽬不能确定。(16位机器最⼤16,32位机器最⼤32,写成27,在16位机器会 出问题。)
3.位段中的成员在内存中从左向右分配,还是从右向左分配,标准尚未定义。
4.当⼀个结构包含两个位段,第⼆个位段成员⽐较⼤,⽆法容纳于第⼀个位段剩余的位时,是舍弃 剩余的位还是利⽤,这是不确定的。
在上面代码中,当前平台会利用一个字节的剩余位,字节用完之后会从左向右使用新字节,比如int_c:10;,紫色部分,横跨三个字节,但是字节的拼接顺序应该是最右边的0 + 中间的01111111 + 最左边的1,也就是小端字节序。0011111111:255。
位段使用注意事项
内存中每个字节一个地址,但是字节内的比特位是没有地址的,所以&a.a这种写法是错的。想要赋值给位段成员,要先拿一个值接收再传给位段:
cstruct A { int _a:2; int _b:5; int _c:10; int _d:30; }; #include <stdio.h> int main() { struct A a = {0}; int input = 0; scanf("%d\n",&input); a.a = input; }
五、联合体
只为最大成员分配空间,所有成员这块空间,叫做联合体,也叫共用体。
c
union tag
{
member-list;
}variable-list;联合体内一个大的成员变量和一个小的成员变量,小成员变量使用联合体的内存时和数组一样,是从低地址到高地址使用的,可以利用这个特点来判断机器的大小端。
联合体的大小
联合体的大小至少是最大的成员变量,为什么说是至少呢?因为联合体也要遵守内存对齐的规则,联合体大小要对齐到最大对齐数的整数倍,当最大对齐数不是成员变量大小的时候,比如编译器默认对齐数是8的时候。联合体大小就要对齐到8的整数倍。
联合体使用案例
c
struct gift_list
{
int stock_number;//库存数
double price;//定价
int item_type;//商品类型
union{
struct
{
char title[20];//书名
char author[20];//作者
int num_pages;
}book;
struct
{
char design[30];
}mug;
struct
{
char design[30];
int colors;
int sizes;
}shirt;
}item;
};六、枚举
和结构体以及联合体不同,声明枚举类型只会声明一些常量而不是变量。
使用枚举常量的优点
- 可读性强
- 枚举有类型检查
c//方案1 #define Green 1 #define Red 2 #define Blue 3.0f int main() { int clr0 = Green; int clr1 = Red; int clr2 = Blue; return 0; }
c//方案2 enum Color { Green, Red, Blue = 3.0f; }; int main() { enum Color clr0 = Green; enum Color clr1 = Red; return 0; }可以看到,在枚举内部定义常量时必须是整型,而#define却可以随意定义。
枚举遵循作用域规则,#define不遵循
C++类型检查通常比C语言更严格,比如一些C语言可以使用的强制类型转换在C++做不到,同样定义一个枚举类型变量,C语言可以给这个变量赋一个整数,而C++必须赋值枚举类型内部的常量。
}
c//方案2 enum Color { Green, Red, Blue = 3.0f; }; int main() { enum Color clr0 = Green; enum Color clr1 = Red; return 0; }可以看到,在枚举内部定义常量时必须是整型,而#define却可以随意定义。
- 枚举遵循作用域规则,#define不遵循
C++类型检查通常比C语言更严格,比如一些C语言可以使用的强制类型转换在C++做不到,同样定义一个枚举类型变量,C语言可以给这个变量赋一个整数,而C++必须赋值枚举类型内部的常量。