文章目录
- [1. 前言](#1. 前言)
- [2. 环境准备](#2. 环境准备)
- [2.1 安装必要依赖](#2.1 安装必要依赖)
- [3. 模型下载](#3. 模型下载)
- [4. 核心部署代码](#4. 核心部署代码)
- [5. 效果演示](#5. 效果演示)
- [6. 进阶配置:针对不同场景的优化](#6. 进阶配置:针对不同场景的优化)
-
- [方案 A:显存不足?使用 4-bit 量化](#方案 A:显存不足?使用 4-bit 量化)
- [方案 B:高并发推理?使用 vLLM 部署](#方案 B:高并发推理?使用 vLLM 部署)
- [7. 常见坑点排查(FAQ)](#7. 常见坑点排查(FAQ))
- [8. 结语](#8. 结语)
1. 前言
GLM-4V-9B 是智谱 AI 推出的最新一代开源视觉多模态模型,具备强大的图像理解、对话及推理能力。相比于云端 API,本地部署能更好地保护数据隐私,并显著降低长期使用的成本。
本教程将指导你如何在已安装 PyTorch 的 Linux 服务器上,快速完成 GLM-4V-9B 的部署与推理。
2. 环境准备
在开始之前,请确保你的服务器满足以下基础条件:
- 操作系统: Ubuntu 20.04+ (推荐)
- 显存 :
- FP16 模式:至少 24GB(如 RTX 3090/4090, A10/A100)
- Int4 量化模式:至少 12GB(如 RTX 3060/4070)
- 已安装: Python 3.10+, CUDA 11.8+, PyTorch 2.0+
2.1 安装必要依赖
如果你已经安装了 PyTorch,可以进入该步骤安装额外的库来处理图像和复杂的 Tokenizer:
bash
pip install transformers>=4.45.0 accelerate tiktoken einops scipy pillow
# 强烈建议安装 flash-attn 以获得更快的推理速度(需支持 CUDA 11.6+)
pip install flash-attn --no-build-isolation
3. 模型下载
由于模型权重文件较大(约 18GB),国内用户推荐使用 ModelScope(魔搭社区),下载速度通常比 Hugging Face 快得多。
bash
pip install modelscope
# 下载模型到当前目录下的 glm-4v-9b 文件夹
modelscope download --model ZhipuAI/glm-4v-9b --local_dir ./glm-4v-9b
推荐用多线程脚本加速
python
from modelscope import snapshot_download
model_id = 'ZhipuAI/glm-4v-9b'
# local_dir 为你想要存放模型的路径
local_dir = './glm-4v-9b'
# snapshot_download 默认支持多线程
# 增加 max_workers 参数(视你的服务器带宽而定,建议设置 4-8)
snapshot_download(
model_id,
local_dir=local_dir,
cache_dir='./cache', # 临时缓存目录
max_workers=16 # 开启8个线程同时下载
)4. 核心部署代码
创建一个 inference.py 文件,填入以下代码。该脚本支持加载本地权重并进行一次图文对话。
python
import os
import warnings
import torch
# 1. 屏蔽环境变量日志 (必须在 import transformers 之前执行)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 屏蔽 TensorFlow 日志
os.environ['TRANSFORMERS_VERBOSITY'] = 'error' # 屏蔽 Transformers 自带的大部分警告
os.environ['HF_HUB_DISABLE_SYMLINKS_WARNING'] = '1' # 屏蔽 HF 软连接警告
# 2. 屏蔽 Python 警告
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
# 3. 此时再导入剩下的库
from PIL import Image
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
# 4. 屏蔽 transformers 内部库的输出
transformers.logging.set_verbosity_error()
def run_inference():
model_path = "./glm-4v-9b"
# 1. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 2. 加载模型
print("[1/3] 正在加载模型至显存 (BF16)...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
).eval()
# 兼容性小补丁
if not hasattr(model.config, "num_hidden_layers"):
model.config.num_hidden_layers = model.config.num_layers
# 3. 准备输入
image_path = "demo.jpg"
query = "请详细描述这张图片。"
try:
image = Image.open(image_path).convert("RGB")
except Exception:
print(f"错误:无法找到图片 {image_path}")
return
inputs = tokenizer.apply_chat_template(
[{"role": "user", "image": image, "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
).to("cuda")
# 4. 执行推理
print("[2/3] 模型正在思考...")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
do_sample=False,
use_cache=True,
eos_token_id=tokenizer.eos_token_id
)
response_ids = outputs[0][len(inputs['input_ids'][0]):]
response = tokenizer.decode(response_ids, skip_special_tokens=True)
print("[3/3] 推理完成。")
print("\n" + "="*30 + " 模型回答 " + "="*30)
print(response)
print("="*70 + "\n")
if __name__ == "__main__":
run_inference()
5. 效果演示
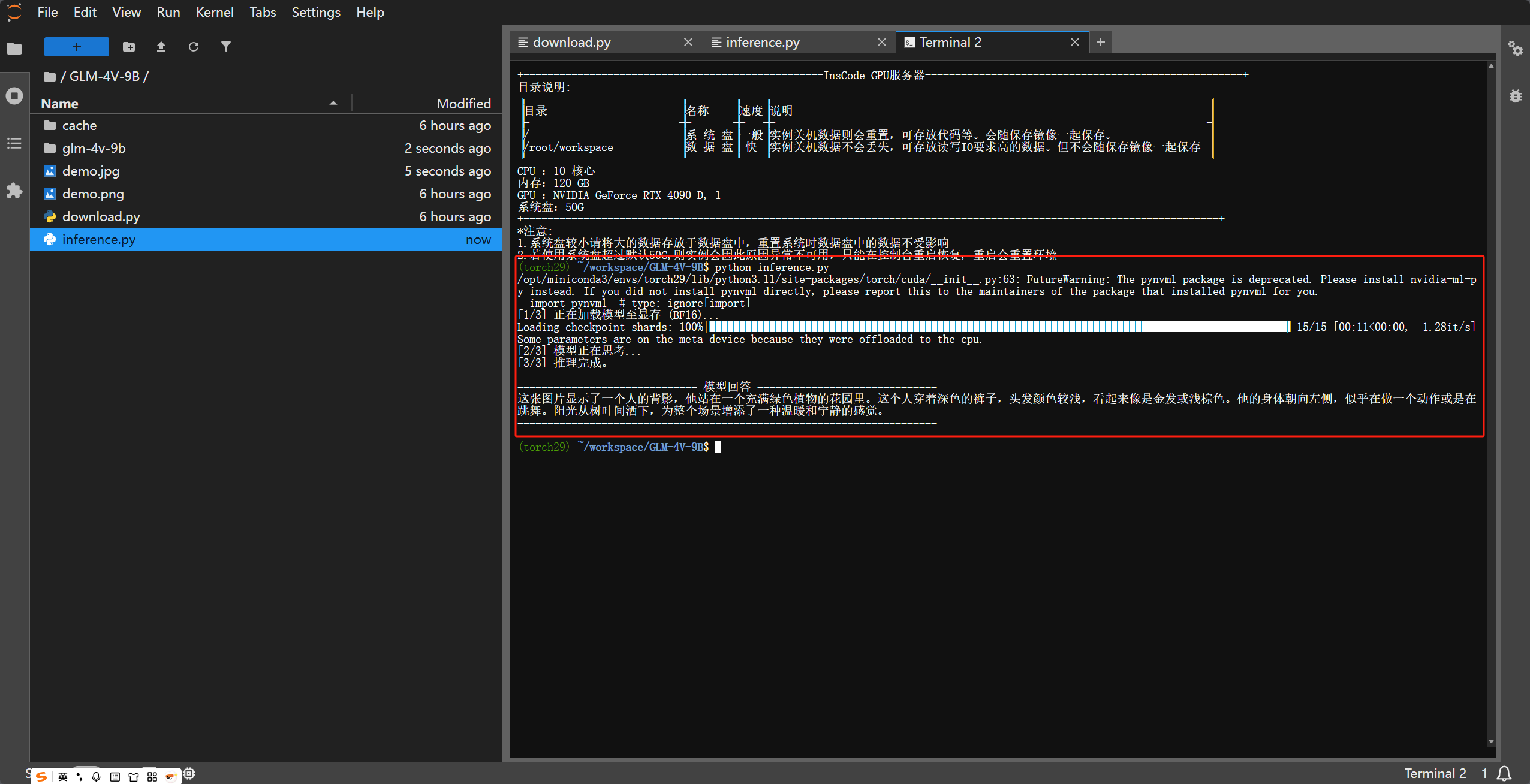
6. 进阶配置:针对不同场景的优化
方案 A:显存不足?使用 4-bit 量化
如果你的显存小于 20GB,可以通过 bitsandbytes 开启 4-bit 量化加载,显存占用将降至约 9-11GB。
首先安装:pip install bitsandbytes
修改模型加载部分:
python
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_4bit=True, # 开启 4bit 量化
device_map="auto" # 自动分配显存
)方案 B:高并发推理?使用 vLLM 部署
如果你希望将模型作为 API 服务提供给前端使用,推荐使用 vLLM 框架,它的吞吐量比原生 Transformers 高出数倍。
bash
pip install vllm
# 启动兼容 OpenAI 接口的服务
python -m vllm.entrypoints.openai.api_server \
--model ./glm-4v-9b \
--trust-remote-code \
--gpu-memory-utilization 0.9 \
--max-model-len 4096 \
--port 8000部署后,你可以直接使用 OpenAI 的 SDK 调用它。
7. 常见坑点排查(FAQ)
- 报错
AttributeError: 'ChatGLMTokenizer' object has no attribute 'apply_chat_template'- 解决 : 请确保
transformers版本大于 4.44.0。如果版本正确仍报错,检查tokenizer_config.json是否在模型目录中。
- 解决 : 请确保
- 显存溢出 (OOM)
- 解决 : 减小
max_length;或者使用上文提到的 4-bit 量化方案。
- 解决 : 减小
- 图片识别效果差
- 解决 : 检查图片读取时是否转换为了
.convert("RGB"),GLM-4V 对灰度图或带 Alpha 通道的图可能不兼容。
- 解决 : 检查图片读取时是否转换为了
8. 结语
GLM-4V-9B 展现了极强的图文理解能力,通过本地部署,你可以将其集成到自动化办公、智能安检、医疗影像辅助等多种私有化场景中。如果你在部署过程中遇到问题,欢迎在评论区交流!