动机
当前大模型在复杂推理任务上表现出色,但计算成本和延迟让人望而却步;小模型虽然高效,但推理能力又明显不足
现有的协作方案(如级联路由)通常采用"全有或全无"的策略:路由器判断题目难度,简单的给小模型,难的整个交给大模型。但问题在于,很多"难题"其实小模型能做出 90% 的推理步骤,仅在个别关键节点卡住了。这种粗粒度的任务分配就像:学生只要有一步不会,就把整道题都交给老师------显然造成了巨大的计算浪费
对此作者提出 RelayLLM,一种通过 token 级协作解码实现高效推理的框架。它让小模型在生成过程中主动识别"需要帮助的关键时刻",通过特殊指令仅在这些位置调用大模型,实现真正的"接力"生成
论文标题
RelayLLM: Efficient Inference through Collaborative Decoding
论文地址
https://arxiv.org/pdf/2601.05167
作者背景
华盛顿大学圣路易斯分校、马里兰大学、弗吉尼亚大学
代码地址
https://github.com/Chengsong-Huang/RelayLLM
问题分析
粗粒度路由的计算浪费
传统路由方法的工作流程是:先用一个路由模块判断查询难度,然后决定是交给小模型还是大模型。一旦判定为"困难",整个生成任务就会完全卸载到大模型
这种策略存在明显的低效:小模型其实具备处理大部分推理步骤的能力,可能只在某些关键位置(比如复杂的逻辑跳转、知识盲区)才需要专家干预。把整个任务交给大模型,就像因为一道题的最后一步不会,就让老师从头到尾全部重做一遍
关键推理步骤在哪里?
另一个重要问题是:小模型如何知道自己在哪里需要帮助?这不是简单的"难度判断" ------ 同一个问题的不同解题步骤,难度分布是不均匀的:
- 大部分步骤是常规推理,小模型完全能够胜任
- 少数关键步骤(比如巧妙的数学变换、跨领域知识调用)才是真正的瓶颈
- 这些关键步骤的位置高度依赖上下文,无法提前标注
因此,我们需要一种机制,让小模型在生成过程中"实时自我感知"------知道自己当前能力够不够,并在必要时主动请求帮助
RelayLLM 的设计方案
RelayLLM 的核心创新在于:将小模型同时作为推理器和控制器,让它在生成过程中通过特殊命令主动调用大模型,实现 token 级别的协作解码
协作推理机制
整个流程分为三个阶段:
1. 小模型主导生成
默认情况下,小模型 M_S 正常进行自回归生成。但它被赋予了一项特殊能力:可以生成一个命令 token:
<call>n</call>其中 n 表示需要大模型生成多少个 token(比如 50 表示请求 50 个 token)
2. 大模型干预
当检测到这个命令时,小模型的生成会暂停。系统会将当前上下文(不包含命令 token 本身,以保持与大模型标准输入分布的兼容性)转发给大模型 M_L,后者接管生成接下来的 n 个 token
3. 控制权回归小模型
大模型完成指定数量的 token 生成后,控制权返回小模型。关键的是,小模型保留了完整的历史记录(包括自己生成的命令 token),这使得它能够维持对自己主动委派决策的记忆。随后小模型继续生成,消化专家提供的指导来完成剩余推理
这种设计的巧妙之处在于:
- 动态性
不需要预先判断整个问题难度,而是在生成过程中实时决策 - 精准性
可以精确控制在哪个 token 位置调用,以及调用多长时间 - 可学习性
何时调用、调用多久都是可以通过训练优化的策略
两阶段训练框架
为了让小模型学会"恰当的时机恰当地求助",作者设计了一套两阶段训练方法:
阶段 1:监督预热(冷启动)
小模型最初并不知道如何生成 n 命令。直接用强化学习训练,模型可能完全不会输出这个模式。因此需要监督预热来建立基础能力
数据构造流程:
- 避免分布偏移
直接从原始小模型采样生成基础序列(而非使用外部语料),确保训练数据与模型自身分布一致 - 随机插入命令
在生成序列的随机位置插入 n,让模型学会在任意时刻触发求助 - 多尺度长度采样
随机采样 n = d × 10^k(d ∈ {1,...,9}, k ∈ {0,...,3}),模拟不同程度的依赖
通过标准的交叉熵损失在这个合成数据集上微调,小模型就获得了生成有效命令的能力
阶段 2:基于 GRPO 的策略优化
有了生成命令的能力后,关键是教会模型"何时该求助、何时该独立"。这是一个明确的强化学习问题,作者采用组相对策略优化(GRPO)来训练
训练流程:
- 对每个查询,从旧策略采样一组输出(包含调用与不调用大模型的情况)
- 用奖励函数评估每个输出,计算相对于组平均值的优势
- 通过策略梯度更新模型参数,让模型倾向于生成高奖励的行为模式
奖励设计:
-
简单奖励
r_simple(y) = 𝟙(答案正确) - ρ(y)
其中 ρ(y) 是调用比率(大模型生成的 token 数 / 总 token 数)。这个奖励鼓励准确率,同时惩罚过度调用
- 难度感知奖励
简单奖励把所有问题一视同仁,但实际上不同问题需要不同的策略。作者根据采样组的集体表现,将查询分为三种情境并设计不同的奖励:
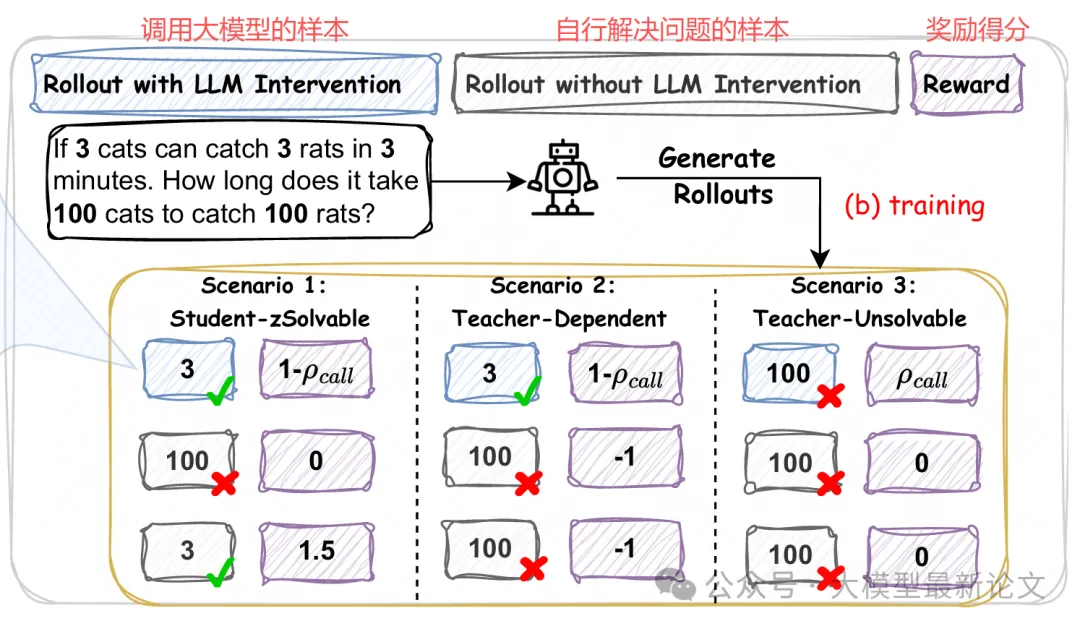
情境 1:学生可解(鼓励独立性)
如果采样组中至少有一个样本不调用大模型就答对了,说明小模型完全有能力独立解决。此时:
- 独立成功:r = 1.5(增强奖励)
- 依赖成功(ρ > 0):r = r_simple(标准奖励)
- 答错:r = 0
这样设计是为了明确告诉模型:"你本来可以自己做对的,不要总想着偷懒找老师"
情境 2:教师依赖型(惩罚固执)
如果正确答案只出现在调用了大模型的样本中,说明这个问题超出了小模型的能力边界。此时:
- 盲目独立(ρ = 0):r = -1.0(惩罚固执)
- 有效求助:r = r_simple(标准奖励)
这告诉模型:"明明不会还硬撑着,该求助时就要求助"
情境 3:教师不可解(激励探索)
如果所有样本都没答对(包括调用大模型的),说明问题极其困难或大模型也帮不上忙。此时:
- 尝试求助:r = ρ(y)(小的探索奖励)
- 其他情况:r = 0
这鼓励模型在极度不确定时仍保持寻求帮助的倾向,避免完全放弃探索
这种分段式奖励设计精妙地平衡了三个目标:
- 效率
在能力范围内尽量独立完成 - 准确
在能力边界外积极求助 - 探索
在极端不确定情况下保持求助倾向
数据过滤
还有一个重要细节:如果大模型对某个查询的成功率很低(比如只有 20%),那在训练中调用它不会带来多少正向信号,反而浪费计算。因此作者在训练前对数据做预处理:为每个查询采样 10 个响应,只保留大模型通过率 ≥ 50% 的样本
实验结果
作者选用 Qwen3 系列模型进行实验:Qwen3-0.6B 和 Qwen3-1.7B 作为小模型,Qwen3-8B 作为大模型(教师)。在六个数学推理基准上进行评估:Minerva、MATH-500、GSM8K、Olympiad-Bench、AIME-2024、AIME-2025
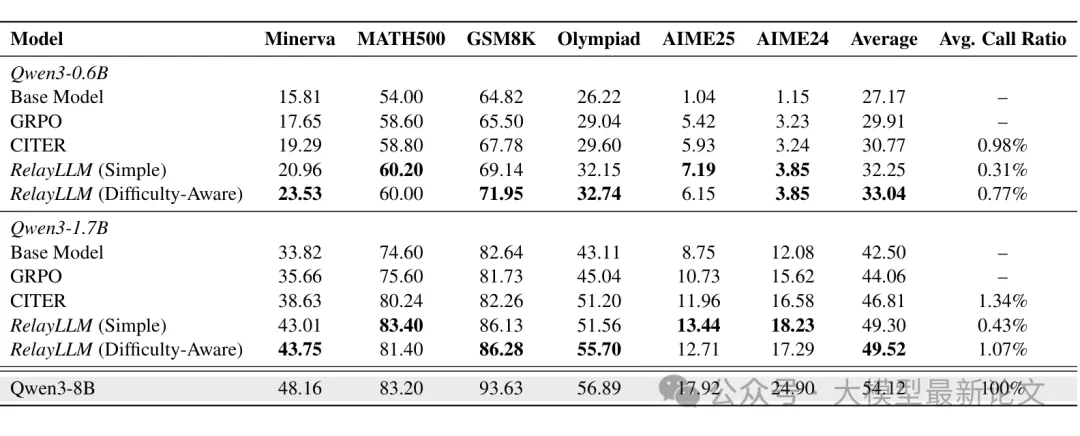
几个关键发现:
1. 显著的性能提升,极低的计算开销
以 Qwen3-1.7B(难度感知奖励)为例:
- 平均准确率:从基础模型的 42.50% 提升到 49.52%
- 平均调用比率:仅 1.07%(只有 1% 的 token 由大模型生成)
- 在 Minerva 这样的困难基准上,0.6B 模型从 15.81% 提升到 23.53%(相对提升 48.8%),调用比率仅 0.77%
这意味着:RelayLLM 弥合了小模型与大模型之间约 60% 的性能差距,而计算开销几乎可以忽略不计
2. 优于基线方法
- 相比 GRPO 基准(标准强化学习训练),RelayLLM 全面领先
- 相比 CITER(需要额外 MLP 控制器的 token 级路由方法),RelayLLM 性能更好且开销更低
- CITER 需要每个 token 都用外部 MLP 估算得分,带来显著延迟
- RelayLLM 仅用少量额外 token(命令)就实现了更高效的控制
3. 难度感知奖励 vs 简单奖励
难度感知奖励在性能上略优于简单奖励(Qwen3-1.7B:49.52% vs 49.30%),但调用比率稍高(1.07% vs 0.43%)。这符合预期:难度感知机制更鼓励模型在复杂场景中求助,从而带来更高的准确率,但相应地增加了一些调用开销
与路由方法的对比
论文中的一个关键对比是:RelayLLM 相比"资源相当的随机路由器"(调用相似比例的大模型 token)实现了 6.9% 的准确率提升,或者说相比性能相当的路由器,token 开销降低了 98.2%
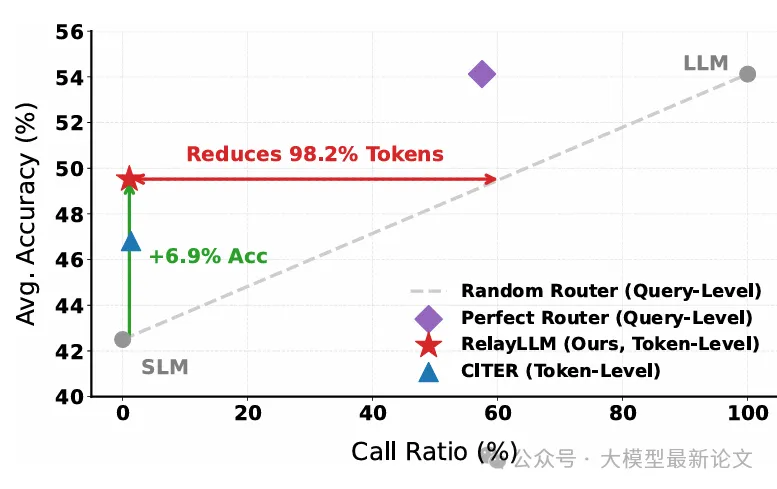
这说明什么?传统路由方法要么在整个问题上做粗粒度分配(浪费计算),要么需要额外的控制模块(增加延迟)。而 RelayLLM 通过让小模型自身学会"在关键推理步骤精准求助",在极低开销下实现了远超路由方法的效率
泛化能力
尽管 RelayLLM 仅在数学领域的 DAPO 数据集上训练,但在未见过的通用推理领域(Big-Bench Hard、MMLU-Pro、SuperGPQA)上依然显著优于基线:
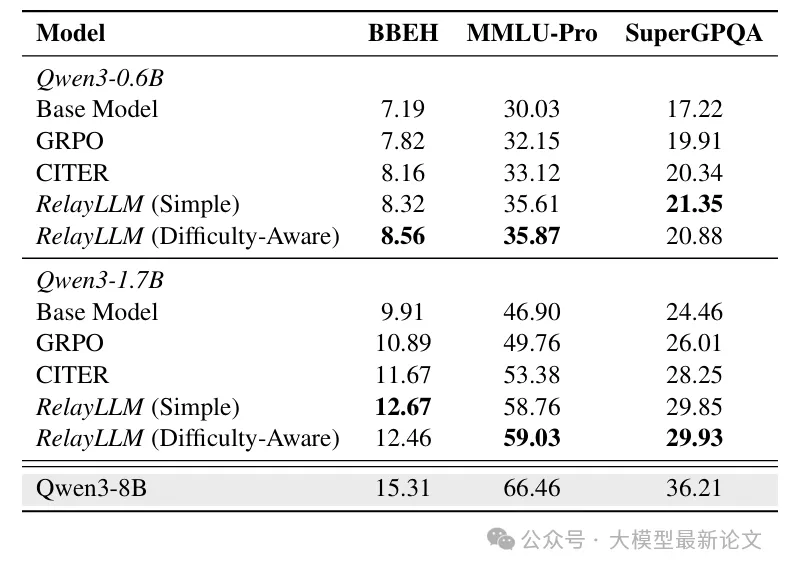
这表明模型学到的不是特定领域的模式,而是一种泛化的求助行为------即使面对不熟悉的输入,也能成功识别知识盲区并调用大模型
消融实验
作者进行了细致的消融研究,验证了设计中每个组件的必要性:
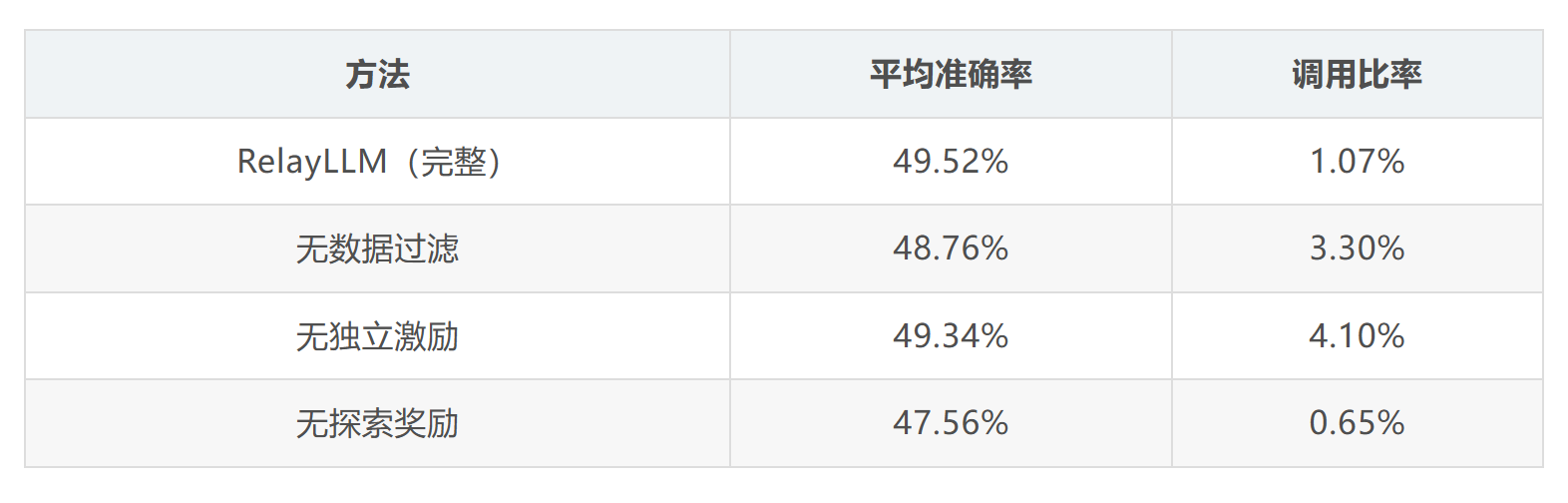
内在推理能力
一个有趣的问题是:RelayLLM 是真的提升了小模型的推理能力,还是仅仅学会了任务卸载?
作者在"无教师"情景下评估了模型(在推理时禁止生成 token),结果显示:
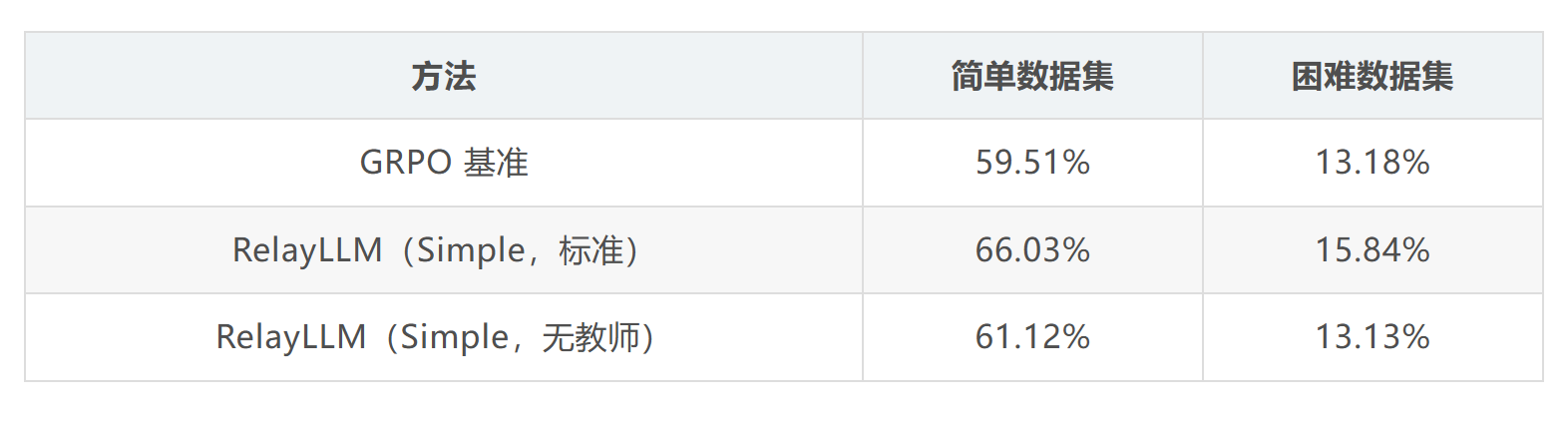
在简单数据集上,即使没有大模型帮助,RelayLLM(Simple)仍达到 61.12%,超过 GRPO 基准。这说明小模型在协作训练过程中成功内化了部分专家推理能力
而在困难数据集上,移除大模型导致性能显著下降,证实在复杂任务中模型仍严重依赖专家干预------这也是符合预期的
动态长度调用
作者还验证了动态预测调用长度 n 是否优于固定长度。他们重新训练了多个模型,每个模型在训练和推理时都硬编码固定的调用长度 k ∈ {20, 100, 500}:
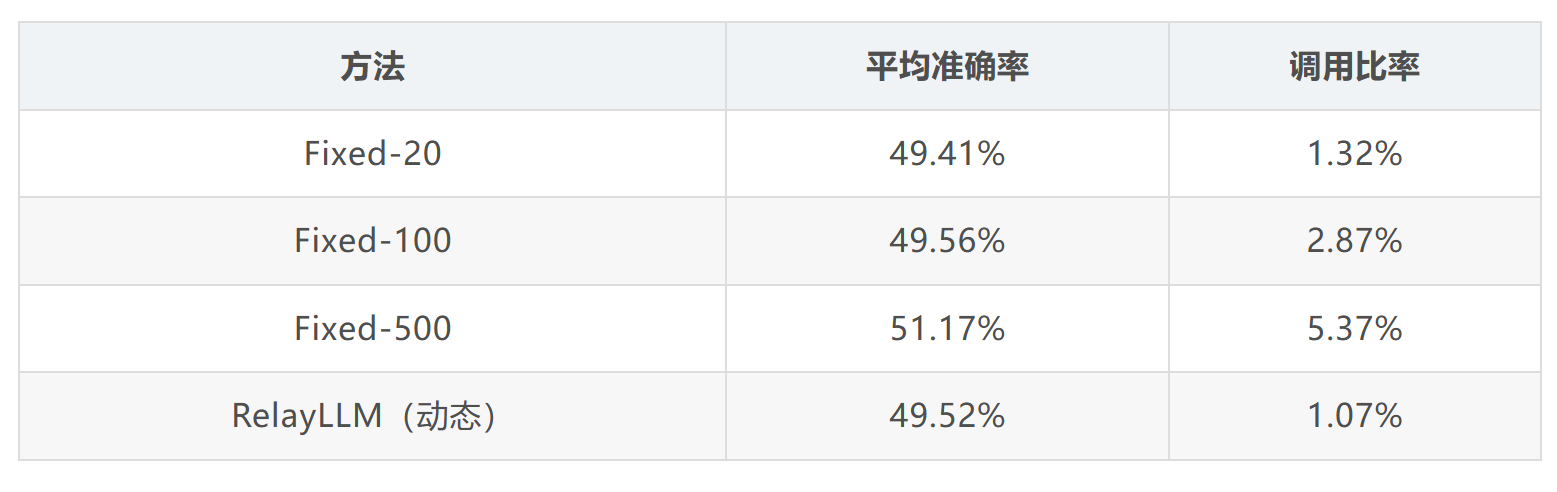
RelayLLM 在保持相似准确率的同时,调用比率远低于 Fixed-100(1.07% vs 2.87%)。尽管 Fixed-500 准确率最高,但代价是 5 倍以上的计算开销。这表明:固定长度模型即使面对简单查询也会强制消耗计算预算,而 RelayLLM 能有效学习"仅需足够"的策略,最小化浪费
跨教师模型评估
作者还测试了推理时使用不同教师模型的效果。结果显示:
- 与训练用大模型保持一致时性能最佳(Qwen3-8B)
- 用更大的模型(如 14B)替代反而性能略降,说明分布偏移的影响超过了更强推理能力的优势
- 即使用比自身更弱的教师(0.6B 或 1.7B),性能也优于"无教师"基准,表明模型已适应外部辅助的存在
这个发现很有意思:说明 RelayLLM 学到的不仅是"调用一个更强的模型",而是一种更本质的"在特定上下文下接收并利用外部指导"的能力