仙盟创梦代码
完整代码
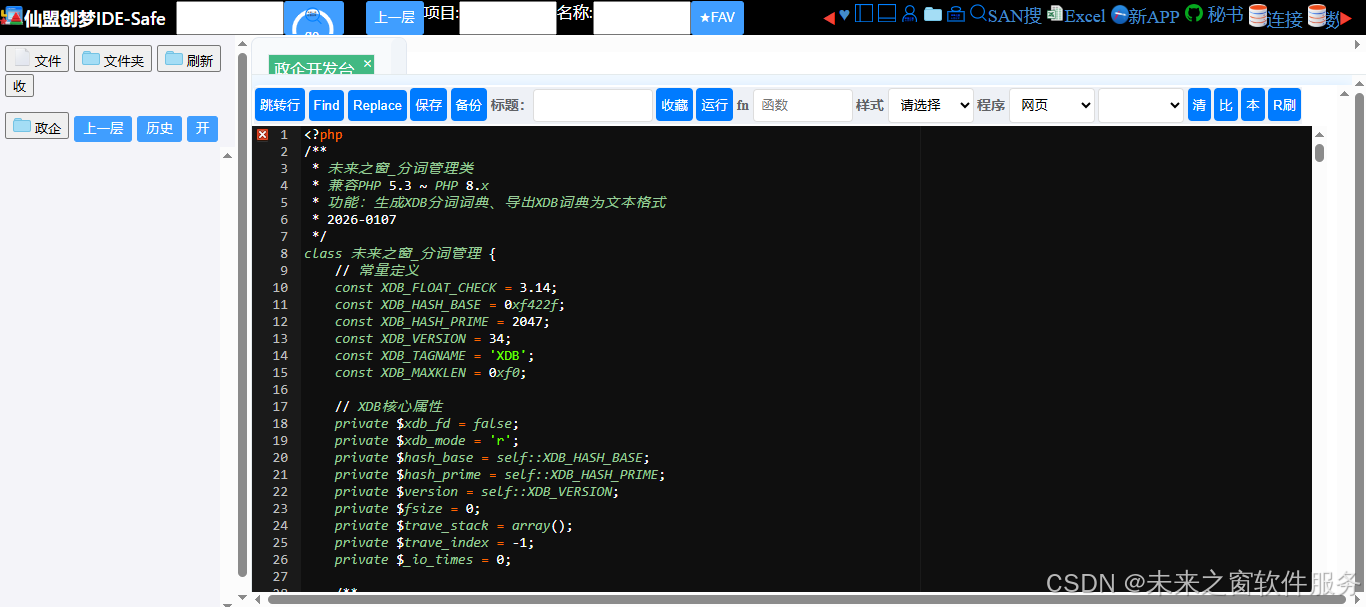
<?php
/**
* 未来之窗_分词管理类
* 兼容PHP 5.3 ~ PHP 8.x
* 功能:生成XDB分词词典、导出XDB词典为文本格式
* 2026-0107
*/
class 未来之窗_分词管理 {
// 常量定义
const XDB_FLOAT_CHECK = 3.14;
const XDB_HASH_BASE = 0xf422f;
const XDB_HASH_PRIME = 2047;
const XDB_VERSION = 34;
const XDB_TAGNAME = 'XDB';
const XDB_MAXKLEN = 0xf0;
// XDB核心属性
private $xdb_fd = false;
private $xdb_mode = 'r';
private $hash_base = self::XDB_HASH_BASE;
private $hash_prime = self::XDB_HASH_PRIME;
private $version = self::XDB_VERSION;
private $fsize = 0;
private $trave_stack = array();
private $trave_index = -1;
private $_io_times = 0;
/**
* 构造函数
* @param int $base hash计算基数
* @param int $prime hash求模基数
*/
public function __construct($base = 0, $prime = 0) {
if ($base != 0) {
$this->hash_base = $base;
}
if ($prime != 0) {
$this->hash_prime = $prime;
}
}
/**
* 生成XDB词典文件
* @param string $xdb_file 输出的XDB文件路径
* @param string $input_file 输入的文本词典路径(可选,默认标准输入)
* @param bool $is_utf8 是否UTF8文本(默认GBK)
* @return bool 成功返回true,失败返回false
*/
public function 词典生成($xdb_file, $input_file = 'php://stdin', $is_utf8 = false) {
// 内存和超时设置
ini_set('memory_limit', '1024M');
set_time_limit(0);
// 检查mbstring扩展
if (!extension_loaded('mbstring')) {
trigger_error("生成词典失败:需要mbstring扩展", E_USER_ERROR);
return false;
}
// 检查输出文件是否存在
if (file_exists($xdb_file)) {
trigger_error("生成词典失败:XDB文件已存在 {$xdb_file}", E_USER_ERROR);
return false;
}
// 打开输入文件
if (!($fd = @fopen($input_file, 'r'))) {
trigger_error("生成词典失败:无法打开输入文件 {$input_file}", E_USER_ERROR);
return false;
}
// 打开XDB文件(写模式)
if (!$this->Open($xdb_file, 'w')) {
fclose($fd);
trigger_error("生成词典失败:无法打开XDB文件写入 {$xdb_file}", E_USER_ERROR);
return false;
}
// 加载数据
mb_internal_encoding($is_utf8 ? 'UTF-8' : 'gbk');
$total = 0;
$rec = array();
echo "INFO: 正在加载文本词典数据 ... ";
while ($line = fgets($fd, 512)) {
// 跳过注释行
if (substr($line, 0, 1) == '#') continue;
// 分割行数据
$parts = explode("\t", $line, 4);
if (count($parts) < 4) continue;
list($word, $tf, $idf, $attr) = $parts;
$k = (ord($word[0]) + ord($word[1])) & 0x3f;
$attr = trim($attr);
// 主词记录
if (!isset($rec[$k])) $rec[$k] = array();
if (!isset($rec[$k][$word])) {
$total++;
$rec[$k][$word] = array();
}
$rec[$k][$word]['tf'] = $tf;
$rec[$k][$word]['idf'] = $idf;
$rec[$k][$word]['attr'] = $attr;
// 生成前缀词(仅支持GBK)
$len = mb_strlen($word);
while ($len > 2) {
$len--;
$temp = mb_substr($word, 0, $len);
if (!isset($rec[$k][$temp])) {
$total++;
$rec[$k][$temp] = array();
}
$rec[$k][$temp]['part'] = 1;
}
}
fclose($fd);
echo "OK, 总词汇数=$total\n";
// 写入XDB
for ($k = 0; $k < 0x40; $k++) {
if (!isset($rec[$k])) continue;
$cnt = 0;
printf("正在插入 [%02d/64] ... ", $k);
foreach ($rec[$k] as $w => $v) {
$flag = (isset($v['tf']) ? 0x01 : 0);
if (!empty($v['part'])) $flag |= 0x02;
// 打包数据
$tf_val = isset($v['tf']) ? (float)$v['tf'] : 0.0;
$idf_val = isset($v['idf']) ? (float)$v['idf'] : 0.0;
$attr_val = isset($v['attr']) ? substr($v['attr'], 0, 3) : '';
$data = pack('ffCa3', $tf_val, $idf_val, $flag, $attr_val);
$this->Put($w, $data);
$cnt++;
}
printf("%d 条记录已保存\n", $cnt);
}
// 优化并关闭
echo "INFO: 正在优化XDB文件 ... ";
flush();
$this->Optimize();
$this->Close();
echo "完成!\n";
return true;
}
/**
* 导出XDB词典为文本格式
* @param string $xdb_file 输入的XDB文件路径
* @param string $output_file 输出的文本文件路径(可选,默认标准输出)
* @return bool 成功返回true,失败返回false
*/
public function 词典导出($xdb_file, $output_file = 'php://stdout') {
// 内存和超时设置
ini_set('memory_limit', '1024M');
set_time_limit(0);
// 检查输入文件
if (!is_file($xdb_file)) {
trigger_error("导出词典失败:XDB文件不存在 {$xdb_file}", E_USER_ERROR);
return false;
}
// 打开输出文件
if (!($fd = @fopen($output_file, 'w'))) {
trigger_error("导出词典失败:无法打开输出文件 {$output_file}", E_USER_ERROR);
return false;
}
// 打开XDB文件(读模式)
if (!$this->Open($xdb_file, 'r')) {
fclose($fd);
trigger_error("导出词典失败:无效的XDB文件 {$xdb_file}", E_USER_ERROR);
return false;
}
// 写入表头
$line = "# WORD\tTF\tIDF\tATTR\n";
fwrite($fd, $line);
// 遍历XDB并导出
$this->Reset();
while ($tmp = $this->Next()) {
if (strlen($tmp['value']) != 12) continue;
$word = $tmp['key'];
$data = unpack("ftf/fidf/Cflag/a3attr", $tmp['value']);
// 只导出完整词条(跳过前缀词)
if (!($data['flag'] & 0x01)) continue;
$line = sprintf("%s\t%.2f\t%.2f\t%.2s\n",
$word, $data['tf'], $data['idf'], $data['attr']);
fwrite($fd, $line);
}
// 关闭文件
fclose($fd);
$this->Close();
echo "词典导出完成:{$output_file}\n";
return true;
}
// --------------------- 以下为原XDB核心方法(兼容改造) ---------------------
/**
* 打开XDB文件
* @param string $fpath 文件路径
* @param string $mode 模式(r/w)
* @return bool
*/
public function Open($fpath, $mode = 'r') {
$this->Close();
$newdb = false;
// 打开文件
if ($mode == 'w') {
if (!($fd = @fopen($fpath, 'rb+'))) {
if (!($fd = @fopen($fpath, 'wb+'))) {
trigger_error("XDB打开失败:{$fpath}", E_USER_WARNING);
return false;
}
$this->_write_header($fd);
$this->fsize = 32 + 8 * $this->hash_prime;
$newdb = true;
}
} else {
if (!($fd = @fopen($fpath, 'rb'))) {
trigger_error("XDB打开失败:{$fpath}", E_USER_WARNING);
return false;
}
}
// 检查头部
if (!$newdb && !$this->_check_header($fd)) {
trigger_error("XDB格式无效:{$fpath}", E_USER_WARNING);
fclose($fd);
return false;
}
// 设置属性
$this->xdb_fd = $fd;
$this->xdb_mode = $mode;
$this->Reset();
// 写模式加锁
if ($mode == 'w') {
flock($this->xdb_fd, LOCK_EX);
}
return true;
}
/**
* 写入数据
* @param string $key
* @param string $value
* @return bool
*/
public function Put($key, $value) {
if (!$this->xdb_fd || $this->xdb_mode != 'w') {
trigger_error("XDB写入失败:只读模式或句柄无效", E_USER_WARNING);
return false;
}
$klen = strlen($key);
$vlen = strlen($value);
if (!$klen || $klen > self::XDB_MAXKLEN) {
return false;
}
// 查找旧记录
$rec = $this->_get_record($key);
if (isset($rec['vlen']) && ($vlen <= $rec['vlen'])) {
// 更新旧值
if ($vlen > 0) {
fseek($this->xdb_fd, $rec['voff'], SEEK_SET);
fwrite($this->xdb_fd, $value, $vlen);
}
// 更新长度
if ($vlen < $rec['vlen']) {
$newlen = $rec['len'] + $vlen - $rec['vlen'];
$newbuf = pack('I', $newlen);
fseek($this->xdb_fd, $rec['poff'] + 4, SEEK_SET);
fwrite($this->xdb_fd, $newbuf, 4);
}
return true;
}
// 新建记录
$new = array('loff' => 0, 'llen' => 0, 'roff' => 0, 'rlen' => 0);
if (isset($rec['vlen'])) {
$new['loff'] = $rec['loff'];
$new['llen'] = $rec['llen'];
$new['roff'] = $rec['roff'];
$new['rlen'] = $rec['rlen'];
}
$buf = pack('IIIIC', $new['loff'], $new['llen'], $new['roff'], $new['rlen'], $klen);
$buf .= $key . $value;
$len = $klen + $vlen + 17;
$off = $this->fsize;
fseek($this->xdb_fd, $off, SEEK_SET);
fwrite($this->xdb_fd, $buf, $len);
$this->fsize += $len;
$pbuf = pack('II', $off, $len);
fseek($this->xdb_fd, $rec['poff'], SEEK_SET);
fwrite($this->xdb_fd, $pbuf, 8);
return true;
}
/**
* 读取数据
* @param string $key
* @param bool $debug
* @return mixed
*/
public function Get($key, $debug = false) {
if (!$this->xdb_fd) {
trigger_error("XDB读取失败:句柄无效", E_USER_WARNING);
return false;
}
$klen = strlen($key);
if ($klen == 0 || $klen > self::XDB_MAXKLEN) {
return false;
}
$rec = $this->_get_record($key);
if ($debug) {
return $rec;
}
if (!isset($rec['vlen']) || $rec['vlen'] == 0) {
return false;
}
return $rec['value'];
}
/**
* 遍历下一条记录
* @return array|false
*/
public function Next() {
if (!$this->xdb_fd) {
trigger_error("XDB遍历失败:句柄无效", E_USER_WARNING);
return false;
}
// 遍历栈处理
if (!($ptr = array_pop($this->trave_stack))) {
do {
$this->trave_index++;
if ($this->trave_index >= $this->hash_prime) {
break;
}
$poff = $this->trave_index * 8 + 32;
fseek($this->xdb_fd, $poff, SEEK_SET);
$buf = fread($this->xdb_fd, 8);
if (strlen($buf) != 8) {
$ptr = false;
break;
}
$ptr = unpack('Ioff/Ilen', $buf);
} while ($ptr['len'] == 0);
}
if (!$ptr || $ptr['len'] == 0) {
return false;
}
// 读取记录
$rec = $this->_tree_get_record($ptr['off'], $ptr['len']);
// 压入左右子节点
if ($rec['llen'] != 0) {
$left = array('off' => $rec['loff'], 'len' => $rec['llen']);
array_push($this->trave_stack, $left);
}
if ($rec['rlen'] != 0) {
$right = array('off' => $rec['roff'], 'len' => $rec['rlen']);
array_push($this->trave_stack, $right);
}
return $rec;
}
/**
* 重置遍历指针
*/
public function Reset() {
$this->trave_stack = array();
$this->trave_index = -1;
}
/**
* 获取版本信息
* @return string
*/
public function Version() {
$ver = $this->version;
$str = sprintf("%s/%d.%d", self::XDB_TAGNAME, ($ver >> 5), ($ver & 0x1f));
$str .= " <base={$this->hash_base}, prime={$this->hash_prime}>";
return $str;
}
/**
* 关闭XDB文件
*/
public function Close() {
if (!$this->xdb_fd) {
return;
}
if ($this->xdb_mode == 'w') {
$buf = pack('I', $this->fsize);
fseek($this->xdb_fd, 12, SEEK_SET);
fwrite($this->xdb_fd, $buf, 4);
flock($this->xdb_fd, LOCK_UN);
}
fclose($this->xdb_fd);
$this->xdb_fd = false;
}
/**
* 优化XDB文件
* @param int $i 索引
* @return bool
*/
public function Optimize($i = -1) {
if (!$this->xdb_fd || $this->xdb_mode != 'w') {
trigger_error("XDB优化失败:只读模式或句柄无效", E_USER_WARNING);
return false;
}
$start = ($i < 0 || $i >= $this->hash_prime) ? 0 : $i;
$end = ($i < 0 || $i >= $this->hash_prime) ? $this->hash_prime : ($i + 1);
for ($index = $start; $index < $end; $index++) {
$this->_optimize_index($index);
}
return true;
}
// --------------------- 私有方法 ---------------------
/**
* 写入XDB头部
* @param resource $fd
*/
private function _write_header($fd) {
$buf = pack('a3CiiIfa12', self::XDB_TAGNAME, $this->version,
$this->hash_base, $this->hash_prime, 0, self::XDB_FLOAT_CHECK, '');
fseek($fd, 0, SEEK_SET);
fwrite($fd, $buf, 32);
}
/**
* 检查XDB头部
* @param resource $fd
* @return bool
*/
private function _check_header($fd) {
fseek($fd, 0, SEEK_SET);
$buf = fread($fd, 32);
if (strlen($buf) !== 32) return false;
$hdr = unpack('a3tag/Cver/Ibase/Iprime/Ifsize/fcheck/a12reversed', $buf);
if ($hdr['tag'] != self::XDB_TAGNAME) return false;
// 检查文件大小
$fstat = fstat($fd);
if ($fstat['size'] != $hdr['fsize']) return false;
// 设置属性
$this->hash_base = $hdr['base'];
$this->hash_prime = $hdr['prime'];
$this->version = $hdr['ver'];
$this->fsize = $hdr['fsize'];
return true;
}
/**
* 获取索引
* @param string $key
* @return int
*/
private function _get_index($key) {
$l = strlen($key);
$h = $this->hash_base;
while ($l--) {
$h += ($h << 5);
$h ^= ord($key[$l]);
$h &= 0x7fffffff;
}
return ($h % $this->hash_prime);
}
/**
* 获取记录
* @param string $key
* @return array
*/
private function _get_record($key) {
$this->_io_times = 1;
$index = ($this->hash_prime > 1 ? $this->_get_index($key) : 0);
$poff = $index * 8 + 32;
fseek($this->xdb_fd, $poff, SEEK_SET);
$buf = fread($this->xdb_fd, 8);
if (strlen($buf) == 8) {
$tmp = unpack('Ioff/Ilen', $buf);
} else {
$tmp = array('off' => 0, 'len' => 0);
}
return $this->_tree_get_record($tmp['off'], $tmp['len'], $poff, $key);
}
/**
* 从树中获取记录
* @param int $off
* @param int $len
* @param int $poff
* @param string $key
* @return array
*/
private function _tree_get_record($off, $len, $poff = 0, $key = '') {
if ($len == 0) {
return array('poff' => $poff);
}
$this->_io_times++;
fseek($this->xdb_fd, $off, SEEK_SET);
$rlen = self::XDB_MAXKLEN + 17;
if ($rlen > $len) $rlen = $len;
$buf = fread($this->xdb_fd, $rlen);
$rec = unpack('Iloff/Illen/Iroff/Irlen/Cklen', substr($buf, 0, 17));
$fkey = substr($buf, 17, $rec['klen']);
$cmp = ($key ? strcmp($key, $fkey) : 0);
if ($cmp > 0) {
unset($buf);
return $this->_tree_get_record($rec['roff'], $rec['rlen'], $off + 8, $key);
} elseif ($cmp < 0) {
unset($buf);
return $this->_tree_get_record($rec['loff'], $rec['llen'], $off, $key);
} else {
$rec['poff'] = $poff;
$rec['off'] = $off;
$rec['len'] = $len;
$rec['voff'] = $off + 17 + $rec['klen'];
$rec['vlen'] = $len - 17 - $rec['klen'];
$rec['key'] = $fkey;
fseek($this->xdb_fd, $rec['voff'], SEEK_SET);
$rec['value'] = fread($this->xdb_fd, $rec['vlen']);
return $rec;
}
}
/**
* 优化索引
* @param int $index
*/
private function _optimize_index($index) {
static $cmp = null;
$poff = $index * 8 + 32;
// 加载节点
$this->_sync_nodes = array();
$this->_load_tree_nodes($poff);
$count = count($this->_sync_nodes);
if ($count < 3) return;
// 排序节点
if ($cmp === null) {
$cmp = function($a, $b) {
return strcmp($a['key'], $b['key']);
};
}
usort($this->_sync_nodes, $cmp);
// 重置节点
$this->_reset_tree_nodes($poff, 0, $count - 1);
unset($this->_sync_nodes);
}
/**
* 加载树节点
* @param int $poff
*/
private function _load_tree_nodes($poff) {
fseek($this->xdb_fd, $poff, SEEK_SET);
$buf = fread($this->xdb_fd, 8);
if (strlen($buf) != 8) return;
$tmp = unpack('Ioff/Ilen', $buf);
if ($tmp['len'] == 0) return;
fseek($this->xdb_fd, $tmp['off'], SEEK_SET);
$rlen = self::XDB_MAXKLEN + 17;
if ($rlen > $tmp['len']) $rlen = $tmp['len'];
$buf = fread($this->xdb_fd, $rlen);
$rec = unpack('Iloff/Illen/Iroff/Irlen/Cklen', substr($buf, 0, 17));
$rec['off'] = $tmp['off'];
$rec['len'] = $tmp['len'];
$rec['key'] = substr($buf, 17, $rec['klen']);
$this->_sync_nodes[] = $rec;
unset($buf);
// 递归加载左右节点
if ($rec['llen'] != 0) $this->_load_tree_nodes($tmp['off']);
if ($rec['rlen'] != 0) $this->_load_tree_nodes($tmp['off'] + 8);
}
/**
* 重置树节点
* @param int $poff
* @param int $low
* @param int $high
*/
private function _reset_tree_nodes($poff, $low, $high) {
if ($low <= $high) {
$mid = ($low + $high) >> 1;
$node = $this->_sync_nodes[$mid];
$buf = pack('II', $node['off'], $node['len']);
// 递归重置左右子树
$this->_reset_tree_nodes($node['off'], $low, $mid - 1);
$this->_reset_tree_nodes($node['off'] + 8, $mid + 1, $high);
} else {
$buf = pack('II', 0, 0);
}
fseek($this->xdb_fd, $poff, SEEK_SET);
fwrite($this->xdb_fd, $buf, 8);
}
}
// --------------------- 使用示例 ---------------------
/*
// 1. 生成XDB词典
$分词管理 = new 未来之窗_分词管理();
$分词管理->词典生成('dict.xdb', 'dict.txt', false);
// 2. 导出XDB词典
$分词管理 = new 未来之窗_分词管理();
$分词管理->词典导出('dict.xdb', 'dict_export.txt');
*/
?>未来之窗分词服务训练源码 dic 生成(初学者易懂版,东方仙盟 + 科技双比喻,完整适配源码逻辑)
一、核心定位:这份 PHP 源码的本质作用
这份代码是「未来之窗分词管理」的核心训练与词典构建源码,核心作用只有两个:① 把我们整理好的「文本分词词典(dict.txt)」,转换成高性能的 XDB 二进制词典文件(dic 核心文件),供分词服务调用;② 把已生成的 XDB 二进制词典,反向还原成可读的文本格式,方便我们查看、修改、校对分词数据。
对初学者来说,你可以理解为:这是一套「分词词典的锻造炉 + 解码器」,输入的是普通文本词条,输出的是能被程序高速识别的二进制词典,是中文分词服务的核心训练与数据准备环节,没有这个 XDB 词典,分词服务就像没有内功心法的武者,空有招式却无法运转。
二、整体运行逻辑(循序渐进,初学者无压力,含完整流程)
这份源码的逻辑极其规整,全程无复杂嵌套,所有功能都是「线性执行 + 模块化分工」,就像工厂流水线一样,一步接一步,整体分为两大核心功能,所有代码都是围绕这两个功能展开,先讲通用基础,再分述核心功能:
✅ 前置基础:源码的核心支撑与环境要求
- 兼容范围:支持 PHP5.3 ~ PHP8.x 所有版本,不用纠结 PHP 版本,几乎所有服务器都能运行;
- 必装扩展:依赖
mbstring扩展,作用是精准处理中文的字符长度、截取、编码转换(GBK/UTF-8),没有这个扩展,中文处理会乱码,这是源码的「基础经脉」; - 运行配置:自动设置内存上限 1024M、脚本永不超时,因为词典数据可能有成千上万条,足够的资源才能保证处理不中断。
✅ 核心功能一:词典生成(核心!重中之重,源码 80% 代码在做这件事)
作用:文本词典 → XDB 二进制词典(dic 核心文件),也是分词训练的核心环节,流程共 7 步,一步都不复杂:
- 校验准备:检查输出的 XDB 文件是否已存在(避免覆盖)、输入的文本词典能否打开、是否安装 mbstring 扩展,做「战前检查」;
- 打开文件:以写入模式打开 XDB 文件,以读取模式打开文本词典,做好数据读写准备;
- 编码设置:根据配置选择 UTF-8 或 GBK 编码(默认 GBK),保证中文词条不出现乱码;
- 逐行读取文本词典:跳过注释行(开头带 #的行),只处理有效词条,每条词条按「词汇 TF 值 IDF 值 属性」的格式分割,缺一不可;
- 核心处理:主词条入库 + 自动生成前缀词。比如读取到「未来之窗」这个词,不仅会把完整词存入数据池,还会自动生成「未来」这类前缀词,目的是让分词服务在匹配时,能识别词汇的前缀,实现「长词优先匹配」,避免分词不完整;
- 数据打包写入:把每个词汇的 TF、IDF、属性、前缀标识等信息,用
pack函数打包成固定 12 字节的二进制数据,写入 XDB 文件,保证数据紧凑、读取高效; - 优化收尾:对 XDB 文件做结构优化,关闭文件并释放资源,最终生成可直接使用的 XDB 分词词典(dic 文件)。
✅ 核心功能二:词典导出(辅助功能,反向解析)
作用:XDB 二进制词典 → 文本词典,流程更简单,只有 4 步:
- 校验准备:检查 XDB 词典是否存在、输出的文本文件能否写入;
- 打开文件:以只读模式打开 XDB 文件,以写入模式打开文本文件;
- 遍历解析:从头到尾读取 XDB 里的所有词条,用
unpack函数把二进制数据还原成「词汇 TF IDF 属性」的文本格式,自动跳过前缀词,只导出完整有效词条; - 收尾保存:写入注释表头,关闭文件,生成可读的文本词典,方便我们校对、修改分词数据。
三、核心算法与核心技术点(初学者易懂,无复杂公式,配东方仙盟 + 科技双比喻)
这份源码的核心算法和技术点,是支撑「分词词典高效生成 + 高速读取」的灵魂,也是这份源码的精髓,所有算法都无复杂公式、无高深语法,都是「实用型算法」,专为分词词典设计,全部提炼成初学者能看懂的知识点,每个知识点都配「东方仙盟 + 科技」双比喻,好理解、易记忆:
✅ 1. 哈希索引算法(_get_index 方法)------ 词典的「宗门分堂 + 数据索引」
核心作用
给每一个中文词汇计算一个唯一的哈希索引值 ,这个值决定了词汇在 XDB 文件中的存储位置,核心目的是:把海量词汇均匀分配,避免数据扎堆,让后续读取时能「秒定位」词汇,不用从头到尾遍历。
算法逻辑(极简版)
以源码内置的哈希基数(0xf422f)为基础,遍历词汇的每一个字符,通过「移位 + 异或 + 取模」的简单运算,最终得到一个固定范围的索引值,这个值永远在「0 ~ 哈希素数 2047」之间。
双比喻理解
▷ 东方仙盟比喻:整个 XDB 词典是一座「仙盟总坛」,哈希素数 2047 就是总坛的 2047 个「分堂」,每个词汇就是一个「弟子」,哈希算法就是「弟子的入门令牌」,通过令牌上的标记,能瞬间知道这个弟子属于哪个分堂,不用挨个分堂查找;▷ 科技比喻:哈希索引就是词典的「目录页码」,我们查字典时通过拼音查页码,这个算法就是「自动生成页码」,让每个词汇都有自己的专属页码,读取时直接翻到对应页码,效率提升百倍。
✅ 2. TF-IDF 权重算法(核心分词评分机制)------ 词汇的「弟子品阶 + 重要度评分」
核心作用
这是中文分词的核心权重算法,源码中所有词条都必须包含「TF 值」和「IDF 值」,这两个值是分词服务的「核心评分依据」,决定了一个词汇在分词时的「优先级和重要程度」,是这份源码的核心灵魂。
极简解释(初学者必记,不用背公式)
- TF 值(词频):这个词汇在文本中「出现的频率」,值越高,说明这个词越常用;
- IDF 值(逆文档频率):这个词汇的「稀有度」,值越高,说明这个词越独特、辨识度越强;
- 组合作用:分词服务在匹配词汇时,会优先匹配「TF 高 + IDF 高」的词汇,比如「未来之窗」的 TF 和 IDF 都很高,会优先被识别成完整词,而不是被拆成「未来」+「之窗」。
双比喻理解
▷ 东方仙盟比喻:TF 值是弟子的「修炼次数」,修炼越多越熟练;IDF 值是弟子的「独门功法」,功法越稀有,身份越尊贵。仙盟在挑选核心弟子时,一定会优先选「修炼次数多 + 功法稀有」的弟子,分词服务也是如此;▷ 科技比喻:TF-IDF 就是词汇的「搜索权重」,就像搜索引擎里,关键词的匹配优先级由「出现次数 + 稀有度」决定,这个算法是中文分词、搜索引擎、文本分析的通用核心算法,学会这个,就懂了分词的底层逻辑。
✅ 3. 二叉搜索树存储算法(_tree_get_record 等核心方法)------ 词典的「宗门藏书阁 + 有序存储」
核心作用
这是 XDB 文件的「底层存储结构」,源码把所有词汇按二叉树的形式存入文件,核心目的是:让词汇的存储是「有序的」,后续读取、匹配、遍历词汇时,能以最快速度找到目标词汇,时间效率极高。
极简解释
二叉树就像一棵「分叉的树」,每个词汇是一个「节点」,每个节点只有左、右两个子节点:比当前词汇小的词,放在左节点;比当前词汇大的词,放在右节点。查找时,只需要不断对比,就能快速定位,不用遍历所有词汇。
双比喻理解
▷ 东方仙盟比喻:二叉搜索树就是仙盟的「藏书阁」,所有功法秘籍按「功法名称排序」摆放,第一层放核心功法,左边放名称拼音靠前的,右边放靠后的。弟子找秘籍时,不用挨个翻找,只需要按排序对比,就能快速找到想要的秘籍;▷ 科技比喻:二叉搜索树就是词典的「有序索引表」,就像我们的手机通讯录按字母排序,找联系人时不用从头翻,这是编程中最常用的「高效存储结构」之一,也是这份源码能处理海量词汇的关键。
✅ 4. 前缀词自动生成算法(词典生成的核心细节)------ 分词的「宗门心法衔接 + 完整匹配保障」
核心作用
这是源码中一个「隐形但至关重要」的算法逻辑,也是保证分词准确率的核心细节:读取到一个完整长词时,会自动生成它的所有前缀短词。比如读取到「未来之窗」(4 个字符),会自动生成「未来」(3 个字符)这类前缀词,并标记为「前缀标识」。
设计目的
让分词服务在匹配时,能实现「最长匹配原则」:优先匹配最长的完整词,再匹配短词。比如遇到「未来之窗科技」,会先匹配「未来之窗」,而不是先匹配「未来」,避免分词碎片化,这是中文分词的核心原则。
双比喻理解
▷ 东方仙盟比喻:前缀词就是「心法的基础招式」,完整词是「心法大招」,想要学会大招,必须先学会基础招式。仙盟弟子修炼时,会先练前缀招式,再练完整大招,分词服务也是如此,先识别前缀词,再匹配完整词,保证招式连贯;▷ 科技比喻:前缀词就是「词汇的基础片段」,就像我们输入拼音时,输入法会先匹配前缀拼音,再匹配完整词语,本质是一样的,都是为了保证匹配的完整性和准确性。
✅ 5. 二进制打包 / 解包算法(pack/unpack 函数)------ 词典的「乾坤袋 + 数据压缩」
核心作用
源码用pack把词汇的 TF、IDF、属性、标识等信息,打包成固定长度的二进制数据;用unpack把二进制数据还原成可读的文本格式。核心目的是:二进制数据体积小、读取快、存储紧凑,相比文本格式,XDB 二进制词典的体积能缩小一半以上,读取速度提升数倍。
双比喻理解
▷ 东方仙盟比喻:pack就是「乾坤袋」,把弟子的功法、令牌、品阶等所有信息,压缩装进一个小小的乾坤袋里,方便携带和存储;unpack就是打开乾坤袋,把里面的信息完整还原出来,不丢失任何内容;▷ 科技比喻:二进制打包就是「文件压缩」,就像我们把 txt 文件压缩成 zip 文件,体积变小但内容不变,XDB 词典就是被「压缩优化」后的分词数据,专为程序高速读取设计。
四、源码的核心设计亮点(初学者能看懂的优势,为什么这份源码好用)
这份源码能兼容 PHP5 到 PHP8,适配所有环境,还能高效处理海量分词数据,核心优势全是「实用型设计」,没有花架子,也是初学者可以学习的编程思路:
- 无依赖轻量化:除了必装的 mbstring 扩展,没有其他第三方依赖,下载就能运行,不用配置复杂环境;
- 自动容错处理:跳过注释行、跳过格式不完整的词条,不会因为一条无效数据导致整个词典生成失败;
- 内存与性能优化:自动设置足够的内存和超时时间,处理几万、几十万条词汇都不会崩溃;
- 结构模块化:核心方法分离,「打开文件、写入数据、读取数据、优化文件」各司其职,代码可读性极强,初学者能轻松看懂每一部分的作用;
- 双向兼容:既能生成词典,也能导出词典,方便我们校对和修改数据,形成「生成 - 使用 - 修改 - 再生成」的闭环。
五、初学者快速上手使用(源码自带示例,直接复制运行)
源码末尾已经给出了完整的使用示例,不需要修改任何核心代码,只需要两步就能生成自己的分词词典,是初学者最友好的设计:
✅ 第一步:准备文本词典(dict.txt)
新建一个 txt 文件,按以下格式写入词条,一行一条,字段之间用「制表符(Tab 键)」分隔,注释行开头加 #:
plaintext
# 词汇 TF值 IDF值 属性
未来之窗 8.96 7.25 科技
分词服务 9.12 6.88 工具
PHP源码 7.85 8.10 开发✅ 第二步:运行生成 / 导出代码
直接复制源码末尾的示例代码,修改文件路径,运行即可:
php
运行
// 1. 生成XDB分词词典(核心:文本转二进制dic文件)
$分词管理 = new 未来之窗_分词管理();
$分词管理->词典生成('dict.xdb', 'dict.txt', false); // false=GBK编码,true=UTF-8
// 2. 导出XDB词典为文本(辅助:二进制转文本,方便校对)
$分词管理 = new 未来之窗_分词管理();
$分词管理->词典导出('dict.xdb', 'dict_export.txt');六、总结(初学者必记核心要点,一句话概括所有重点)
这份「未来之窗分词服务训练源码」,本质是一套基于 PHP 的、轻量级的中文分词词典构建工具,核心是通过「哈希索引 + TF-IDF 权重 + 二叉搜索树 + 二进制打包」四大核心技术,把普通的文本分词数据,转换成高性能的 XDB 二进制词典。
对初学者来说,不用纠结源码里的每一行细节,记住这 3 个核心点就够了:
- 这份源码的核心作用:造词典、解词典,是分词服务的「训练准备环节」;
- 分词的核心算法:TF-IDF 权重算法,决定词汇的匹配优先级;
- 存储的核心逻辑:哈希索引 + 二叉树,保证词典的高效读取和存储。
而所有的技术逻辑,用东方仙盟的比喻收尾就是:这份源码,就是为「中文分词仙盟」锻造「内功心法词典」的核心法器,算法是心法,数据是弟子,最终锻造出的 XDB 词典,就是能让分词服务「运转自如、精准高效」的核心心法
阿雪技术观
让我们积极投身于技术共享的浪潮中,不仅仅是作为受益者,更要成为贡献者。无论是分享自己的代码、撰写技术博客,还是参与开源项目的维护和改进,每一个小小的举动都可能成为推动技术进步的巨大力量
Embrace open source and sharing, witness the miracle of technological progress, and enjoy the happy times of humanity! Let's actively join the wave of technology sharing. Not only as beneficiaries, but also as contributors. Whether sharing our own code, writing technical blogs, or participating in the maintenance and improvement of open source projects, every small action may become a huge force driving technological progrss.