😊文章背景
题目:Labeling-free RAG-enhanced LLM for intelligent fault diagnosis via reinforcement learning
期刊:Advanced Engineering Informatics
检索情况:IF 9.9 sciUpTop 工程技术 TOPSCI升级版 工程技术1区 SCIQ1EI检索
作者:Jiamin Xu a, Zixuan Xu a, Zhaohui Jiang a, Zhiwen Chen a,∗, Hao Luo b, Yalin Wang a, Weihua Gui a
单位:中南大学
发表年份:2025
DOI:https://doi.org/10.1016/j.aei.2025.103864
网址:Labeling-free RAG-enhanced LLM for intelligent fault diagnosis via reinforcement learning
❓ 研究问题
-
缺乏专业知识:大型语言模型(LLMs)虽然拥有广泛的通用领域知识,但由于工业复杂系统故障发生的频率较低且具有技术保密性,LLMs 在预训练阶段往往缺乏特定领域的故障诊断知识 。
-
标注成本高昂:现有的检索增强生成(RAG)框架大多依赖监督学习,需要对每个查询标注相关的语料库,这在处理大规模工业数据时极其耗时且劳动强度大 。
-
模型输出不稳定性:LLM 固有的随机性导致生成的响应不稳定,使得在监督学习中难以一致地确定不同检索文档集的优劣 。
📌 研究目标
-
开发一种无标记 RAG 方法:提出一种基于强化学习的 RAG 方法(TG-RL-RAG),旨在消除对人工标注相关性标签的依赖 。
-
优化检索策略:通过近端策略优化(PPO)算法直接优化检索网络,提高检索的准确性和系统响应的质量 。
-
实现持续学习:引入"递减式教师引导策略",使模型能够随着新故障查询的增加而不断自更新,增强在动态工业环境中的实用性 。
🧠 所用方法
一、基于专业词库的图结构构建
-
相似度计算:利用专家精心挑选的专业词汇库。 计算两个文档间的词级重叠度,其中专业词汇的权重高于普通词汇 。
-
构图逻辑:为每个文档 计算与其相似度最高的top-k_{graph} 个文档,并在它们之间建立边,生成邻接矩阵。
-
定位:这个图并非直接用于检索,而是作为强化学习智能体的训练"环境",起到"粗调"的作用 。
二、基于 PPO 算法的策略优化
智能体的任务是在图中寻找与当前查询最相关的文档路径 。
-
状态表示:智能体在每一步都会感知以下信息:
-
语义信息:查询语句和故障文档的向量嵌入。
-
轨迹信息:当前所在节点的位置以及已经访问过的节点历史轨迹 。
-
-
神经网络架构:采用 Actor-Critic 框架。 Actor 网络负责输出下一步移动到哪个节点的概率分布,Critic 网络负责估计当前状态的价值。
-
复合奖励函数 (R_{PPO}):这是模型无需标签的核心:
-
结构探索奖励:如果智能体选择了图中存在的合法路径,给予正向奖励,确保其行为符合物理逻辑。
-
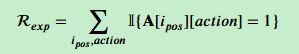
-
检索质量奖励 :这是关键。 系统将智能体检索到的文档交给 Frozen LLM 生成回答,计算该回答与"预期文本"(由人类反馈确认)的语义相似度(如 BLEU 或 ROUGE 分数)作为奖励值。
-
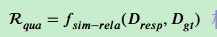
-
三、渐进式递减导师指导策略
针对实际生产中不断涌现的新查询,该策略解决了重复训练成本高的问题 。
-
知识迁移:将之前在原始查询集上训练好的智能体作为"预训练智能体"(Teacher),引导正在学习新查询的"处理智能体"(Student) 。
-
引导奖励 :计算教师和学生两个模型动作分布之间的 KL 散度。 散度越小,说明学生越好地继承了教师的检索经验。
-
动态衰减机制:
-
前期:较大,学生模型主要模仿老师处理旧数据的能力。
-
后期:逐渐减小,学生模型开始侧重于通过自主探索来优化新出现的补充查询。
-
🔮 未来研究方向
无监督奖励函数设计:这种利用 LLM 自身输出质量来反馈优化检索器(Retriever)的思路,是目前解决工业小样本数据难题的非常前沿的方向。
📕专业名词
核心技术术语
-
LLM (大语言模型 / Large Language Models):像 ChatGPT 这样拥有数十亿参数、能够理解并生成人类语言的复杂人工智能系统 。
-
RAG (检索增强生成 / Retrieval-Augmented Generation):一种通过从外部知识库检索相关信息来增强人工智能模型准确性的技术,使模型在回答问题前能先"查阅资料" 。
-
RL (强化学习 / Reinforcement Learning):一种机器学习方法,通过让智能体在环境中不断试错,并根据结果获得"奖励"或"惩罚"来学习最佳决策策略 。
-
TG-RL-RAG:本文提出的方法全称,指结合了"教师引导"和"强化学习"的检索增强生成框架。
算法与模型组件
-
PPO (近端策略优化 / Proximal Policy Optimization):强化学习中一种常用的算法,其特点是在训练过程中非常稳定且易于实现 。
-
智能体 (Agent):在强化学习框架中负责执行动作(如在文档图中行走以寻找答案)的人工智能核心部分 。
-
Actor-Critic (演员-评论家框架):一种神经网络结构,其中"演员"负责提出动作,而"评论家"负责评价这些动作的好坏 。
-
KL 散度 (Kullback-Leibler Divergence):一种数学度量方式,用于衡量两个概率分布(例如老师的建议和学生的行为)之间的差异 。
数据与结构术语
-
邻接矩阵 (Adjacency Matrix):一种数学"地图",用表格的形式记录了哪些文档节点之间存在连接关系 。
-
图结构数据 (Graph-structured data):将信息组织成点(文档)和线(相关性连接)的网络形式,方便智能体进行探索 。
-
垂直领域 (Vertical domains):指特定的专业行业或领域(如工业故障诊断),这些领域通常具有通用大模型难以触及的专业知识壁垒 。
评估与优化指标
-
BLEU / ROUGE:用于衡量人工智能生成的文本与人类提供的标准答案之间相似程度的自动化评估工具 。
-
Hit Rate (命中率):一种衡量检索准确性的指标,表示在模型找出的前 N 个结果中,包含正确答案的比例 。
-
TTA (测试时自适应 / Test-Time Adaptation):使模型在实际部署运行过程中,能够根据新出现的数据分布实时调整自身能力的技术 。
教学策略术语
- 递减式教师引导策略 (Progressively Diminishing Teacher Guidance):本文创新提出的一种方法,即让已训练好的模型像老师一样指导新模型,且指导力度随新模型能力的增强而逐渐减弱 。
邻接矩阵
- 基本定义
邻接矩阵通常用 A表示。 如果图中有 n个节点(在本文中为n篇故障文档),那么邻接矩阵就是一个n*n的矩阵 。
-
矩阵元素A(i, j) = 1:表示节点 i与节点 j之间存在一条边;
-
矩阵元素A(i, j) = 0:表示节点 i与节点 j之间没有直接连接。
- 在本论文中的构建方式
本文通过以下步骤计算并填充邻接矩阵:
-
相似度排序:针对每一篇文档,利用专业词汇库计算它与其他所有文档的相似度,并生成一个降序排列的列表。
-
Top-k 筛选:为了保证图的稀疏性和检索效率,论文仅选取排序最靠前的 k_{graph}个相关文档建立连接。
- 邻接矩阵的核心作用
在 TG-RL-RAG 框架中,邻接矩阵不仅仅是一个数据结构,它承担了以下角色:
-
定义行动空间:它规定了强化学习智能体在当前节点时,哪些下一步动作(跳转到其他文档)是合法的 。
-
结构约束:通过"结构探索奖励",智能体如果尝试跨越邻接矩阵中不存在的边,会受到惩罚或被视为无效动作,从而确保智能体只在语义相关的文档间跳转。
-
粗调机制:邻接矩阵构成了图结构的基础,起到"粗调"(Coarse-tuning)作用,限制了搜索范围,而具体的精确检索则交给智能体在这些路径中进行"微调"优化 。
TTA测试时适应(Test-Time Adaptation)
- 核心定义
通常的机器学习是"先训练,后使用",训练好后模型就固定不变了。 而 TTA 的目标是让模型在测试阶段(即实际部署运行阶段),能够根据输入的数据实时地(Real-time)进行自我调整 。
- 为什么要用TTA?
解决"分布偏移"
在实验室环境下训练模型时,数据是完美的。 但在现实工业场景中,会出现分布偏移 :
-
设备老化:机器用久了,振动信号会变,和刚买时不一样 。
-
环境变化:冬天和夏天的运行参数不同 。
-
新故障出现:出现了模型以前没见过的故障类型 。
-
后果:如果不进行适应,模型的诊断准确率会大幅下降 。
- TTA 的关键特点
-
无须标签(Label-free):在实际测试时,我们通常不知道正确答案(标签),TTA 必须在没有人工标注的情况下完成自我进化 。
-
无需大规模重训:它不需要停机并使用全部历史数据进行长时间的重新训练,而是在运行过程中进行轻量化的更新 。
-
高效与轻量:工业场景要求系统反应快,因此 TTA 方法必须足够简单、高效,以减少停机时间并提高系统的长期可用性 。