深度学习-处理文本
NLP任务
任务:字符串分类 -- 判断字符串中是否出现了指定字符
- 指定字符:a
- abcd 为正样本
- bcde 为负样本
神经网络处理文本
第一步:字符数值化
我们需要把字符转换为数学上的东西才能进入模型
单个字符转换为标量 ❌
把单个字符转换为标量,这样合理么?
a -> 1, b -> 2, c -> 3 .... z -> 26
不合理,如果这样的话,会引入一些本不存在的关系,比如,a+b=c,a+a=b
单个字符转换为向量 ✅
把单个字符转换为同维度向量,这样就合理了
a -> 0.32618175 0.20962898 0.43550067 0.07120884 0.58215387
b -> 0.21841921 0.97431001 0.43676452 0.77925024 0.7307891
...z -> 0.72847746 0.72803551 0.43888069 0.09266955 0.65148562
多个字符-字符串转换为矩阵
"abcd" -> 4 * 5 的矩阵
矩阵形状 = 文本长度 * 向量长度
\[0.32618175 0.20962898 0.43550067 0.07120884 0.58215387
0.21841921 0.97431001 0.43676452 0.77925024 0.7307891
0.95035602 0.45280039 0.06675379 0.72238734 0.02466642
0.86751814 0.97157839 0.0127658 0.98910503 0.92606296\]
第二步:矩阵转化为向量
求平均
\[0.32618175 0.20962898 0.43550067 0.07120884 0.58215387
0.21841921 0.97431001 0.43676452 0.77925024 0.7307891
0.95035602 0.45280039 0.06675379 0.72238734 0.02466642
0.86751814 0.97157839 0.0127658 0.98910503 0.92606296\]
列的每个值相加除以4
0.59061878 0.65207944 0.2379462 0.64048786 0.56591809
由4 * 5 矩阵 -> 1* 5 向量 (这称之为pooling池化)
第三步:向量到实数
采取最简单的线性公式 y = w * x + b
w 维度为1*向量维度 b为实数
例:
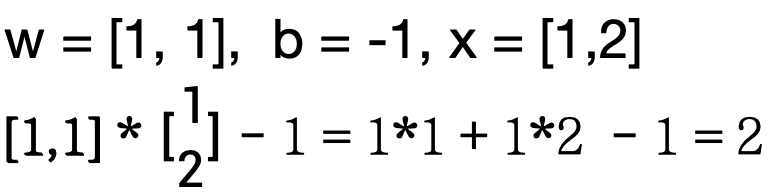
第四步:实数归一化
通过sigmoid函数
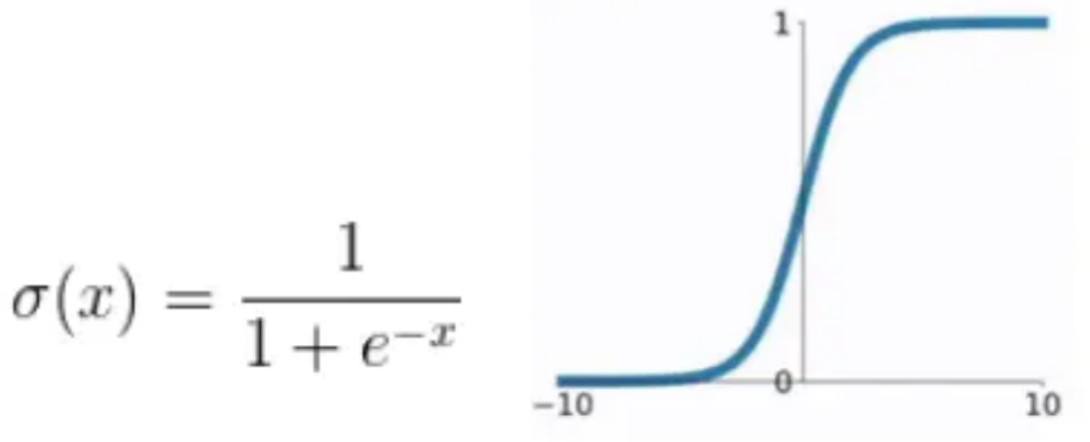
例:x = 2 σ(x) = 0.8808
整体流程
"abcd" ----每个字符转化成向量----> 4 * 5矩阵
4 * 5矩阵 ----向量求平均----> 1 * 5向量
1 * 5向量 ----w * x + b线性公式 ---> 实数
实数 ----sigmoid归一化函数---> 0-1之间实数
加粗部分需要通过训练优化
Embedding
定义
Embedding矩阵是可训练的参数,一般会在模型构建时随机初始化
也可以使用预训练的词向量来做初始化,此时也可以选择不训练Embedding层中的参数
输入的整数序列可以有重复,但取值不能超过Embedding矩阵的列数
核心价值:将离散值 转化为向量
代码
python
import torch
import torch.nn as nn
'''
embedding层的处理
'''
# 通常对于nlp任务,此参数为字符集字符总数
# 词汇表大小,表示有8个不同的字符
num_embeddings = 8
# 每个字符将被映射为4维的向量
embedding_dim = 4
# 创建一个Embedding层,形状为{8, 4}
# 内部维护一个可训练的权重矩阵,随机初始化
# padding_idx = 0 表示0索引对应的字符为填充字符,填充字符的向量全为0(不进行运算)
embedding_layer = nn.Embedding(num_embeddings, embedding_dim, padding_idx =0)
print("随机初始化权重")
print("embedding_layer.weight:", embedding_layer.weight)
print("################")
# 字符表
vocab = {
"pad" : 0,
"a" : 1,
"b" : 2,
"c" : 3,
"d" : 4,
"e" : 5,
"f" : 6,
"unk": 7
}
# 将输入字符串中的每个字符转换为对应字符表的索引值
# 例如:"abc" → [1, 2, 3]
def str_to_sequence(string, vocab):
return [vocab[s] for s in string]
# 创建3个示例字符串并转换为3个对应字符表索引list
string1 = "abcde"
string2 = "ddccb"
string3 = "fedab"
list1 = str_to_sequence(string1, vocab)
list2 = str_to_sequence(string2, vocab)
list3 = str_to_sequence(string3, vocab)
print("list1:", list1)
print("list2:", list2)
print("list3:", list3)
print("\n")
# 将三个索引list堆叠成形状为{3, 5}的张量
x = torch.LongTensor([list1, list2, list2])
print("输入张量形状:", x)
print("\n")
"""
输入x的每个元素对应字符表索引,通过Embedding层进行映射,得到结果
例如:
embedding_layer.weight 权重矩阵为:
[0.1, 0.2, 0.3, 0.4]
[0.5, 0.6, 0.7, 0.8]
[0.9, 1.0, 1.1, 1.2]
"acb" 对应的字符表索引为 [1, 3, 2] 作为x输入
输出为: [[0.1, 0.2, 0.3, 0.4],
[0.9, 1.0, 1.1, 1.2],
[0.5, 0.6, 0.7, 0.8]]
"""
embedding_out = embedding_layer(x)
print(embedding_out)输出
python
随机初始化权重
embedding_layer.weight: Parameter containing:
tensor([[ 0.0000, 0.0000, 0.0000, 0.0000],
[-1.2829, -0.5944, -0.5828, 0.9199],
[ 0.3016, 1.3304, 0.0693, -1.0530],
[ 0.7432, 0.6106, -0.0946, -0.0349],
[-0.2063, -1.2251, 0.7196, 0.8559],
[-0.1538, -0.3300, -0.2811, -0.3768],
[ 0.1613, -1.4955, -1.6733, 1.3582],
[ 1.8100, 0.5757, 0.2786, -0.9209]], requires_grad=True)
################
list1: [1, 2, 3, 4, 5]
list2: [4, 4, 3, 3, 2]
list3: [6, 5, 4, 1, 2]
输入张量形状: tensor([[1, 2, 3, 4, 5],
[4, 4, 3, 3, 2],
[4, 4, 3, 3, 2]])
tensor([[[-1.2829, -0.5944, -0.5828, 0.9199],
[ 0.3016, 1.3304, 0.0693, -1.0530],
[ 0.7432, 0.6106, -0.0946, -0.0349],
[-0.2063, -1.2251, 0.7196, 0.8559],
[-0.1538, -0.3300, -0.2811, -0.3768]],
[[-0.2063, -1.2251, 0.7196, 0.8559],
[-0.2063, -1.2251, 0.7196, 0.8559],
[ 0.7432, 0.6106, -0.0946, -0.0349],
[ 0.7432, 0.6106, -0.0946, -0.0349],
[ 0.3016, 1.3304, 0.0693, -1.0530]],
[[-0.2063, -1.2251, 0.7196, 0.8559],
[-0.2063, -1.2251, 0.7196, 0.8559],
[ 0.7432, 0.6106, -0.0946, -0.0349],
[ 0.7432, 0.6106, -0.0946, -0.0349],
[ 0.3016, 1.3304, 0.0693, -1.0530]]], grad_fn=<EmbeddingBackward0>)pad
看上面的代码流程,你会发现,字符串转换为对应字符表索引list后,需要堆叠为张量
例:
-
abc -> 1, 2, 3
-
cdba -> 3, 4, 2, 1
-
ac -> 1, 3
这三个字符串长度不一致,没办法放到一个张量里进行训练,所以需要补齐 或者截断
比如我想要的长度是3
-
abc -> 1, 2, 3 不动
-
cdba -> 3, 4, 2 截断
-
ac -> 1, 3, 0 补齐
unk
有一些没写在词表里的未知字符,会用unk来代替