引言:在大数据技术飞速发展的今天,企业级大数据集群的构建、运维与生态整合成为核心痛点。传统大数据集群部署需手动配置海量组件、调试版本兼容性,运维过程中缺乏统一监控与管理工具,生态组件选型混乱且集成难度大,这些问题严重制约了大数据项目的落地效率与稳定性。Apache Ambari与Apache Bigtop两大开源工具的出现,为解决这些痛点提供了成熟方案。Ambari专注于大数据集群的全生命周期管理,实现集群部署、监控、运维的可视化与自动化;Bigtop则聚焦于大数据生态的标准化打包、测试与分发,保障不同组件间的兼容性与一致性。本文将从核心作用、组件架构、组件用处等维度,深入解析Ambari与Bigtop,帮助读者全面掌握这两大工具的核心价值与应用逻辑。

一、大数据集群管理的核心痛点与解决方案概述
在企业大数据实践中,集群管理与生态整合面临诸多挑战:其一,部署复杂,大数据生态包含Hadoop、Spark、Hive、HBase等数十个组件,手动部署需完成组件下载、配置文件修改、环境变量配置等上百个步骤,且易出现版本冲突;其二,运维难度高,集群运行状态监控、组件故障排查、集群扩容缩容等操作缺乏统一入口,依赖运维人员的经验积累;其三,生态碎片化,不同厂商的组件版本差异大,集成过程中需大量定制化开发,增加了项目复杂度;其四,可移植性差,基于特定环境构建的集群难以快速迁移到其他环境。
Ambari与Bigtop从不同维度解决上述痛点:Ambari提供可视化的集群管理界面与自动化运维工具,覆盖集群从部署到退役的全生命周期;Bigtop通过标准化的打包流程、兼容性测试与部署脚本,实现大数据生态组件的统一分发与集成,保障集群在不同环境下的一致性与可移植性。两者相辅相成,共同构建高效、稳定、易运维的企业级大数据集群。
二、Apache Ambari:大数据集群全生命周期管理利器
Apache Ambari是Apache软件基金会旗下的开源大数据集群管理工具,核心定位是"让大数据集群的部署、管理与监控更简单"。它提供了直观的Web界面和REST API,支持Hadoop、Spark、Hive、HBase等主流大数据组件的自动化部署、配置管理、监控告警、升级迁移等操作,极大降低了大数据集群的运维门槛。截至目前,Ambari已成为企业级大数据集群管理的主流工具,广泛应用于金融、互联网、政务等多个领域。
2.1 Ambari核心作用
Ambari的核心价值在于实现大数据集群全生命周期的可视化、自动化管理,具体可概括为以下四点:
-
自动化集群部署:支持通过向导式界面完成集群规划、组件选型、节点分配、配置参数设置等操作,自动完成组件下载、安装与配置,替代传统的手动部署流程,将集群部署时间从数天缩短至数小时。
-
统一配置管理:提供集中式的配置管理界面,支持对集群中所有组件的配置文件进行统一修改、分发与版本控制,避免手动修改配置文件导致的不一致问题,且支持配置参数的动态刷新(部分组件)。
-
全维度监控告警:实时采集集群节点的硬件资源(CPU、内存、磁盘、网络)和组件运行状态(进程、日志、性能指标),通过可视化仪表盘展示集群运行情况,支持自定义告警规则,及时发现并预警集群故障。
-
便捷运维与升级:支持集群节点的扩容缩容、组件的启停与重启、集群版本的升级迁移等运维操作,且所有操作可通过Web界面一键完成,降低运维人员的操作成本与出错概率。
2.2 Ambari核心组件架构
Ambari采用"服务端-客户端"的架构模式,核心组件包括Ambari Server、Ambari Agent、Ambari Web UI、Ambari Metrics System、Ambari Alert Framework等,各组件协同工作实现集群的全生命周期管理。其架构如图所示:
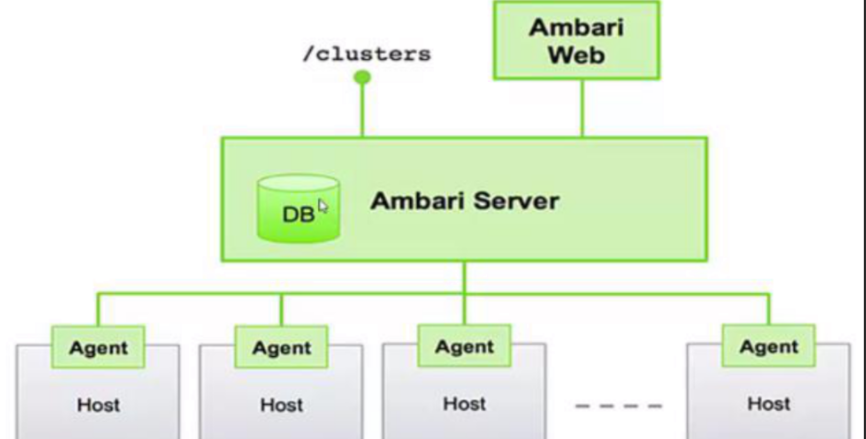
Ambari的核心交互流程为:Ambari Server作为核心中枢,接收用户通过Web UI或REST API发起的操作指令;Ambari Agent部署在集群的每个节点上,与Ambari Server保持通信,执行Server下发的部署、配置、监控等指令;Ambari Metrics System负责采集集群的性能指标,Ambari Alert Framework负责监控组件状态并触发告警。
2.3 Ambari各核心组件用处详解
Ambari的每个核心组件都承担着特定的功能,各组件的具体用处如下:
2.3.1 Ambari Server:集群管理核心中枢
Ambari Server是Ambari的核心组件,部署在单独的管理节点上,负责统筹协调集群的所有管理操作,其主要用处包括:
-
指令分发与任务调度:接收用户通过Web UI或REST API发起的部署、配置、启停组件、扩容缩容等指令,将指令拆解为具体的任务,分发给对应的Ambari Agent执行,并监控任务的执行状态。
-
元数据管理:存储集群的核心元数据,包括集群拓扑结构(节点信息、组件分布)、组件版本信息、配置参数历史记录、任务执行日志等,为集群管理提供数据支撑。
-
组件依赖管理:解析不同大数据组件之间的依赖关系(如Hive依赖Hadoop HDFS和YARN),在部署或升级组件时,自动按依赖顺序执行操作,避免因依赖问题导致的部署失败。
-
安全认证管理:集成Kerberos等安全认证机制,负责集群用户的身份认证与权限控制,保障集群的访问安全。例如,通过Ambari Server可配置Kerberos主体、生成密钥文件,并分发给集群节点。
Ambari Server的核心优势在于简化了集群管理的复杂度,将分散的运维操作集中到统一的中枢节点,实现了对集群的集中管控。
2.3.2 Ambari Agent:节点执行代理
Ambari Agent是部署在集群每个节点上的轻量级代理程序,其核心作用是接收并执行Ambari Server下发的任务,同时向Server反馈节点与组件的运行状态。具体用处包括:
-
任务执行:执行Ambari Server下发的组件安装、配置修改、服务启停、日志采集、性能指标采集等任务。例如,当用户通过Web UI触发Hadoop HDFS的安装指令时,Ambari Agent会自动从指定的软件源下载HDFS安装包,完成安装并配置相关参数。
-
状态上报:定期向Ambari Server上报节点的硬件资源使用情况(CPU、内存、磁盘、网络)、组件运行状态(进程是否存活、端口是否占用)、任务执行进度等信息,确保Server实时掌握集群状态。
-
配置同步:接收Ambari Server下发的配置文件,同步到节点对应的组件配置目录,并根据需要重启组件使配置生效。例如,当用户修改了HDFS的副本数配置后,Ambari Agent会将修改后的hdfs-site.xml文件同步到所有DataNode节点,并重启DataNode服务。
-
本地日志管理:收集节点上各组件的运行日志,为故障排查提供数据支撑。Ambari Agent会将关键日志上传到Ambari Server,方便用户在Web界面上统一查看。
Ambari Agent的存在使得集群节点的管理实现了自动化,无需运维人员手动登录每个节点执行操作,极大提升了运维效率。
2.3.3 Ambari Web UI:可视化管理界面
Ambari Web UI是Ambari提供的可视化操作界面,基于Web技术构建,用户可通过浏览器访问,是用户与Ambari交互的主要入口。其核心用处包括:
-
集群部署向导:提供向导式的集群部署流程,引导用户完成集群名称设置、节点添加、组件选型、配置参数设置等操作,即使是非专业运维人员也能完成集群部署。
-
集群状态监控:通过仪表盘直观展示集群的整体运行状态,包括节点数量、组件分布、硬件资源使用情况、组件性能指标等。例如,用户可通过Web UI查看每个DataNode的磁盘使用率、HDFS的总容量与已用容量、YARN的任务执行情况等。
-
组件运维操作:支持对集群中的组件进行启停、重启、升级等操作,用户只需在Web界面上选择对应的组件和操作,即可一键完成。例如,当Hive服务出现故障时,用户可通过Web UI直接重启Hive服务,无需执行命令行操作。
-
配置管理:提供集中式的配置管理界面,用户可查看和修改所有组件的配置参数,支持按组件、按配置文件类型筛选,且会记录配置参数的修改历史,方便回滚。
-
告警管理:展示集群的告警信息,包括告警级别(警告、错误、致命)、告警原因、受影响的节点与组件等,用户可自定义告警规则,设置告警通知方式(如邮件、短信)。
Ambari Web UI的核心价值在于降低了大数据集群的使用门槛,将复杂的命令行操作转化为直观的图形化操作,提升了管理效率。
2.3.4 Ambari Metrics System:性能指标采集与分析系统
Ambari Metrics System(AMS)是Ambari的性能监控组件,负责采集、存储和展示集群的性能指标,为集群优化与故障排查提供数据支撑。其主要用处包括:
-
多维度指标采集:采集集群的硬件资源指标(CPU使用率、内存使用率、磁盘IO、网络IO)和组件性能指标(如HDFS的读写吞吐量、YARN的任务提交速率、Spark的作业执行时间等),采集频率可自定义。
-
指标存储与聚合:采用TimeSeries Database(TSDB)存储性能指标数据,支持对指标进行聚合分析(如按分钟、小时、天聚合),方便用户查看不同时间维度的性能趋势。
-
可视化指标展示:通过Web UI展示性能指标的趋势图、柱状图等,用户可直观查看集群的性能变化情况。例如,用户可通过趋势图分析HDFS在高峰期的读写吞吐量变化,判断集群是否需要扩容。
-
指标告警阈值设置:支持为性能指标设置告警阈值,当指标超过阈值时,触发告警通知。例如,设置DataNode的磁盘使用率阈值为85%,当磁盘使用率超过该值时,Ambari会发出警告,提醒用户及时清理数据。
AMS的核心优势在于实现了集群性能指标的集中化管理,帮助用户实时掌握集群的运行状态,及时发现性能瓶颈。
2.3.5 Ambari Alert Framework:告警框架
Ambari Alert Framework是Ambari的告警组件,负责监控集群组件的运行状态,当出现异常时触发告警,保障集群的稳定运行。其主要用处包括:
-
组件状态监控:监控集群中各组件的核心服务进程是否存活、端口是否正常监听、组件间的通信是否正常等。例如,监控NameNode、DataNode、ResourceManager等关键进程的运行状态。
-
自定义告警规则:支持用户根据业务需求自定义告警规则,包括告警指标、告警阈值、告警级别、告警周期等。例如,用户可设置当YARN的等待任务数超过100时,触发错误级告警。
-
告警通知与处理:支持多种告警通知方式,如邮件、短信、SNMP陷阱等,方便运维人员及时接收告警信息。同时,提供告警处理流程,用户可标记告警状态(未处理、处理中、已解决),记录处理日志。
-
告警聚合与关联:对相同类型、相同节点的告警进行聚合,避免告警风暴;同时,支持告警关联分析,帮助用户定位告警的根本原因。例如,当DataNode进程异常终止时,可能会触发多个告警,Alert Framework会将这些告警关联,提示用户根本原因是DataNode进程故障。
Ambari Alert Framework的核心价值在于实现了集群故障的早发现、早预警、早处理,降低了故障对业务的影响。
2.3.6 其他辅助组件
除上述核心组件外,Ambari还包含多个辅助组件,进一步提升集群管理的便利性:
-
Ambari REST API:提供REST风格的API接口,支持第三方系统或脚本调用,实现集群管理的自动化与集成化。例如,用户可通过API编写脚本,实现集群的自动扩容、配置自动备份等功能。
-
Ambari Views:提供可扩展的视图插件,支持集成第三方工具的界面,如Hive View(用于执行Hive SQL查询)、Spark View(用于提交和监控Spark作业)等,实现一站式的集群操作与管理。
-
Ambari Log Search:提供集中式的日志搜索功能,支持对集群中所有组件的运行日志进行检索、过滤和分析,方便故障排查。例如,用户可通过关键词搜索HDFS的日志,快速定位文件读写失败的原因。
三、Apache Bigtop:大数据生态标准化与分发工具
Apache Bigtop是Apache软件基金会旗下的开源大数据生态工具,核心定位是"为大数据生态提供标准化的打包、测试、部署与分发方案"。它不直接提供集群管理功能,而是通过对Hadoop、Spark、Hive等主流大数据组件进行标准化打包、兼容性测试,生成统一的安装包与部署脚本,保障不同组件间的兼容性与一致性,简化大数据集群的构建与迁移过程。Bigtop的核心价值在于解决了大数据生态的碎片化问题,为企业提供了"开箱即用"的大数据组件套装。
3.1 Bigtop核心作用
Bigtop的核心价值在于实现大数据生态的标准化与一体化,具体可概括为以下四点:
-
生态组件标准化打包:对主流大数据组件进行统一打包,解决不同组件版本之间的兼容性问题,生成可在不同操作系统(如CentOS、Ubuntu)上运行的安装包(RPM、DEB等)。
-
兼容性与功能测试:提供全面的测试套件,对打包后的组件进行功能测试、性能测试、兼容性测试,确保组件在不同环境下能够稳定运行,且组件间能够正常协同工作。
-
统一部署与运维脚本:提供标准化的部署脚本(基于Puppet、Chef等配置管理工具),支持快速构建大数据集群,简化集群的部署与运维流程。
-
生态组件集成与分发:整合大数据生态的核心组件,形成完整的大数据解决方案,方便企业快速获取并部署整套大数据生态,降低生态整合的难度。
3.2 Bigtop核心组件架构
Bigtop的核心架构围绕"打包-测试-部署"三大核心流程展开,核心组件包括Bigtop Toolchain、Bigtop Packages、Bigtop Tests、Bigtop Deployment、Bigtop Utils等。各组件协同工作,实现大数据生态的标准化与分发。其架构的核心逻辑是:通过Toolchain构建打包环境,对大数据组件进行打包生成Packages;通过Tests对Packages进行全面测试;通过Deployment提供标准化的部署脚本,将测试通过的组件部署到目标环境;通过Utils提供辅助工具,提升打包、测试、部署的效率。
3.3 Bigtop各核心组件用处详解
Bigtop的每个组件都围绕"标准化"核心目标,承担着特定的功能,各组件的具体用处如下:
3.3.1 Bigtop Toolchain:打包工具链
Bigtop Toolchain是Bigtop的打包工具集合,负责构建标准化的打包环境,为大数据组件的打包提供工具支撑。其主要用处包括:
-
打包环境构建:提供标准化的打包环境配置脚本,自动安装打包所需的依赖工具(如Maven、Ant、GCC等),确保打包环境的一致性,避免因环境差异导致的打包失败。
-
组件源码处理:支持从Apache官方仓库或自定义仓库获取大数据组件的源码,对源码进行统一的补丁处理(如修复已知bug、优化性能),确保组件的稳定性与可用性。
-
打包脚本生成:为不同的大数据组件提供标准化的打包脚本模板,支持生成不同类型的安装包(RPM、DEB、Tarball等),适配不同的操作系统环境。
-
版本管理:统一管理大数据组件的版本信息,支持为不同版本的组件生成对应的安装包,方便用户根据业务需求选择合适的组件版本。
Bigtop Toolchain的核心价值在于实现了打包环境的标准化,确保不同组件、不同版本的打包过程一致,提升了打包效率与安装包的可靠性。
3.3.2 Bigtop Packages:标准化组件安装包
Bigtop Packages是Bigtop的核心输出,即经过标准化打包与测试的大数据组件安装包。其主要用处包括:
-
组件版本兼容保障:Bigtop Packages对大数据组件进行严格的版本兼容性测试,确保同一套装中的组件(如Hadoop、Spark、Hive)能够正常协同工作。例如,Bigtop会确保Spark的版本与Hadoop的版本兼容,避免出现因版本不匹配导致的作业提交失败问题。
-
跨平台适配:支持在多种操作系统(CentOS、Ubuntu、SUSE等)上运行,用户可根据自己的服务器环境选择对应的安装包类型,无需进行额外的适配开发。
-
简化安装流程:安装包内置了标准化的安装脚本,支持一键安装与配置,避免了手动安装组件时的复杂配置步骤。例如,通过Bigtop提供的Hadoop RPM包,用户可通过yum命令快速安装Hadoop,并自动完成基础配置。
-
组件完整性保障:每个安装包都包含组件运行所需的所有依赖文件,确保用户安装后即可正常使用组件,无需额外手动安装依赖库。
Bigtop Packages的核心价值在于解决了大数据生态的碎片化问题,为用户提供了"开箱即用"的标准化组件,降低了生态整合的难度。
3.3.3 Bigtop Tests:测试套件
Bigtop Tests是Bigtop的测试组件,提供全面的测试用例,对Bigtop Packages进行功能、性能、兼容性等多维度测试,确保安装包的质量。其主要用处包括:
-
功能测试:验证大数据组件的核心功能是否正常工作。例如,测试HDFS的文件读写、复制、删除功能,YARN的任务提交与执行功能,Hive的SQL查询功能等。
-
兼容性测试:测试不同组件之间的兼容性、组件与操作系统之间的兼容性、组件与不同版本JDK之间的兼容性等。例如,测试Spark在Hadoop 3.x和Hadoop 2.x版本上的运行情况,确保组件在不同环境下都能正常工作。
-
性能测试:测试大数据组件的性能指标,如HDFS的读写吞吐量、YARN的任务并发处理能力、Spark的作业执行效率等,为用户选择组件版本和优化集群配置提供参考。
-
稳定性测试:通过长时间运行组件,测试组件的稳定性,检查是否存在内存泄漏、进程异常终止等问题。例如,持续运行HDFS服务72小时,监控服务的运行状态与资源使用情况。
-
回归测试:当组件版本更新或修复bug后,执行回归测试,确保新的修改不会影响已有的功能。
Bigtop Tests的核心价值在于保障了Bigtop Packages的质量与可靠性,降低了用户使用过程中出现故障的概率。
3.3.4 Bigtop Deployment:标准化部署工具
Bigtop Deployment是Bigtop的部署组件,提供基于主流配置管理工具(如Puppet、Chef、Ansible)的标准化部署脚本,支持快速构建大数据集群。其主要用处包括:
-
集群拓扑规划:支持用户通过配置文件定义集群的拓扑结构,包括节点角色(NameNode、DataNode、ResourceManager等)、组件分布、网络配置等。
-
自动化部署:通过部署脚本自动完成集群节点的初始化、组件安装包的分发、配置文件的修改、组件服务的启停等操作,实现集群的自动化部署。例如,用户可通过Puppet脚本,一键部署包含Hadoop、Spark、Hive的完整大数据集群。
-
部署配置标准化:提供标准化的部署配置模板,用户可根据业务需求修改配置参数,避免手动配置导致的不一致问题。例如,通过配置模板设置HDFS的副本数、YARN的资源分配策略等。
-
跨环境部署支持:支持在物理机、虚拟机、容器等不同环境下部署集群,确保集群在不同环境下的部署流程与配置一致,提升集群的可移植性。
Bigtop Deployment的核心价值在于简化了大数据集群的部署流程,实现了部署过程的标准化与自动化,降低了集群构建的难度与时间成本。
3.3.5 Bigtop Utils:辅助工具集
Bigtop Utils是Bigtop的辅助工具集合,提供一系列实用工具,提升打包、测试、部署的效率。其主要用处包括:
-
日志分析工具:提供日志收集与分析工具,支持收集打包、测试、部署过程中的日志,快速定位问题。例如,当组件打包失败时,通过日志分析工具可快速找到失败的原因。
-
环境检查工具:检查目标环境的硬件资源、操作系统版本、依赖工具是否满足大数据组件的运行要求,提前发现环境问题。例如,检查节点的内存是否满足Spark的运行要求,是否安装了所需的JDK版本。
-
配置备份与恢复工具:支持对集群的配置文件进行备份与恢复,避免因配置错误导致的集群故障。例如,在修改关键配置前,自动备份原始配置文件,以便出现问题时快速回滚。
-
版本管理工具:管理Bigtop Packages的版本信息,支持版本的查询、升级、回滚等操作,方便用户管理集群的组件版本。
四、Ambari与Bigtop的关联与协同实践
Ambari与Bigtop并非竞争关系,而是互补关系,两者在大数据集群的构建与管理中可协同工作,发挥更大的价值。两者的核心区别与关联如下:
4.1 核心区别
| 维度 | Apache Ambari | Apache Bigtop |
|---|---|---|
| 核心定位 | 大数据集群全生命周期管理工具 | 大数据生态标准化打包与分发工具 |
| 核心功能 | 集群部署、监控、配置管理、告警、升级迁移 | 组件打包、兼容性测试、标准化部署脚本 |
| 作用对象 | 已部署的大数据集群 | 大数据组件的打包与分发过程 |
| 核心价值 | 降低集群运维难度,提升运维效率 | 解决生态碎片化,保障组件兼容性 |
4.2 协同实践场景
在实际的大数据集群构建与管理中,Ambari与Bigtop可协同工作,形成"标准化打包-自动化部署-可视化管理"的完整流程:
-
标准化组件准备:通过Bigtop对大数据组件进行标准化打包与测试,生成兼容目标操作系统的安装包,确保组件间的兼容性。例如,通过Bigtop打包Hadoop 3.3.4、Spark 3.3.2、Hive 3.1.3的标准化套装。
-
自动化集群部署:将Bigtop生成的标准化安装包作为Ambari的软件源,通过Ambari的Web UI或REST API,引导用户完成集群部署。Ambari会自动从Bigtop的软件源下载安装包,完成组件的安装与配置,同时利用Bigtop的部署脚本确保配置的标准化。
-
可视化集群管理:集群部署完成后,通过Ambari的Web UI监控集群的运行状态,管理组件配置,处理告警信息;当需要升级组件时,可通过Ambari调用Bigtop提供的升级脚本,确保升级过程的标准化与兼容性。
-
跨环境集群迁移:基于Bigtop的标准化组件与部署脚本,可快速在新环境中构建与原集群配置一致的集群;通过Ambari的配置导出功能,将原集群的配置导出并导入新集群,实现集群的快速迁移。
这种协同模式的核心优势在于:既保障了集群组件的兼容性与一致性(基于Bigtop),又实现了集群管理的自动化与可视化(基于Ambari),极大提升了大数据集群的构建效率与运维稳定性。
五、总结与展望
Apache Ambari与Apache Bigtop是大数据集群构建与管理领域的两大核心工具,分别从"管理运维"与"生态标准化"两个维度解决了企业大数据实践中的核心痛点。Ambari通过可视化的Web界面与自动化的运维工具,覆盖集群从部署到退役的全生命周期,降低了集群运维的难度;Bigtop通过标准化的打包、测试与部署方案,解决了大数据生态的碎片化问题,保障了组件间的兼容性与一致性。两者协同工作,可形成"标准化打包-自动化部署-可视化管理"的完整解决方案,为企业构建高效、稳定、易运维的大数据集群提供有力支撑。
END
如果觉得这份基础知识点总结清晰,别忘了动动小手点个赞👍,再关注一下呀~ 后续还会分享更多有关面试问题的干货技巧,同时一起解锁更多好用的功能,少踩坑多提效!🥰 你的支持就是我更新的最大动力,咱们下次分享再见呀~🌟