Milvus 是 LF AI & Data 旗下、Zilliz 主导的开源云原生向量数据库(Apache 2.0 许可),主打高维向量相似性搜索,支持百亿级规模与毫秒级查询,适配 RAG 等 AI 场景,有单机 / 分布式 / 云托管等灵活部署方案,如下为相关部署及使用方案。
一、Milvus部署
1.单机部署(Docker Compose 方式)
(1).安装 Docker 和 Docker Compose
确保系统已安装 Docker 和 Docker Compose。
可以通过命令 docker --version 和 docker-compose --version 检查是否安装成功。
(2).下载 Milvus 的 Docker Compose 配置文件
从 Milvus 的 GitHub 仓库下载最新版本的 milvus-standalone-docker-compose.yml 文件。修改文件名称为:docker-compose.yml
wget https://github.com/milvus-io/milvus/releases/download/v2.6.8/milvus-standalone-docker-compose.yml -O docker-compose.yml
(3).启动 Milvus 服务
在配置文件所在目录下执行命令 docker-compose up -d。
这将启动 Milvus 的三个核心组件容器:milvus-etcd(元数据存储)、milvus-minio(对象存储)和 milvus-standalone(核心服务)。
(4).验证服务状态
使用命令 docker-compose ps 查看容器状态,确保所有容器都正常运行。
可以通过访问 http://localhost:9091/api/v1/health(或 Milvus 服务器的 IP 地址)来验证 Milvus 服务是否健康。
常见的几个端口:
- miio:http://IP:9001/login。用户名密码在docker-compose.yml文件中,默认为minioadmin、minioadmin
- MilvusWebui地址:http://IP:9091/webui/configs
二、Milvus使用
1.java
1.核心pom
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-autoconfigure-vector-store-milvus</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.5.8</version>
</dependency>2.application.yml配置
yml
spring:
application:
name: spring-ai-alibaba-rag-milvus-example
ai:
dashscope:
api-key: sk-XXX
embedding:
options:
model: text-embedding-v1
vectorstore:
milvus:
client:
host: XXXX
port: 19530
username: root
password: Milvus
databaseName: default
collectionName: vector_store
id-field-name: id # 你的集合主键字段(替换默认的 doc_id)
vector-field-name: embedding # 你的集合向量字段(替换默认的 vector)
content-field-name: content # 你的集合文本字段(和你一致)
metadata-field-name: metadata # 你的集合元数据字段(和你一致)3.系统链接
java
package com.alibaba.cloud.ai.example.rag.config;
import io.milvus.client.MilvusServiceClient;
import io.milvus.param.ConnectParam;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Milvus客户端配置类(手动创建客户端,避免依赖MilvusVectorStore的非公开方法)
*/
@Configuration
public class MilvusConfig {
// 从application.yml中读取Milvus配置(与原有配置保持一致)
@Value("${spring.ai.vectorstore.milvus.client.host:localhost}")
private String milvusHost;
@Value("${spring.ai.vectorstore.milvus.client.port:19530}")
private Integer milvusPort;
// 暴露MilvusServiceClient到Spring容器
@Bean
public MilvusServiceClient milvusServiceClient() {
// 构建Milvus连接参数
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost(milvusHost)
.withPort(milvusPort)
// 若有认证(后续开启),可添加以下配置:
// .withUsername(username)
// .withPassword(password)
.build();
// 创建并返回Milvus客户端
MilvusServiceClient client = new MilvusServiceClient(connectParam);
System.out.println("Milvus客户端连接成功:" + milvusHost + ":" + milvusPort);
return client;
}
}2.python
1.安装 PyMilvus
使用命令 pip install pymilvus 安装 PyMilvus 库。
2.创建连接及相关操作
python
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
# 1. 连接到你的 Milvus 服务器(使用你的密码)
connections.connect(
alias="default",
host='XXX', # 你的服务器IP
port='19530',
user='root', # 用户名
password='pw' # 你的密码
)
# 2. 定义集合名称(必须与Spring AI期望的完全一致)
collection_name = "vector_store"
# 3. 如果集合已存在,先删除(仅第一次运行时可能需要)
if utility.has_collection(collection_name):
collection = Collection(collection_name)
collection.drop()
print(f"已删除现有集合: {collection_name}")
# 4. 定义字段(必须与Spring AI MilvusVectorStore的默认schema匹配)
# Spring AI MilvusVectorStore 的默认主键字段名是 "id",向量字段名是 "embedding"
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=65535),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1536), # 维度需与你的嵌入模型匹配,text-embedding-v1 是1536维
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=65535), # 存储原始文本
FieldSchema(name="metadata", dtype=DataType.JSON), # 存储元数据
]
# 5. 创建集合Schema
schema = CollectionSchema(fields, description="Spring AI vector store collection")
# 6. 创建集合
collection = Collection(name=collection_name, schema=schema)
# 7. 创建索引(非常重要,否则无法搜索)
index_params = {
"index_type": "AUTOINDEX", # 或根据场景选择 "IVF_FLAT", "HNSW"
"metric_type": "COSINE", # 文本相似度通常用余弦相似度
"params": {} # AUTOINDEX 无需额外参数
}
collection.create_index(
field_name="embedding",
index_params=index_params,
index_name="embedding_index"
)
print(f"✅ 集合 '{collection_name}' 创建成功!")
print(f" 主键字段: id (VARCHAR)")
print(f" 向量字段: embedding (FLOAT_VECTOR, dim=1536)")
print(f" 索引类型: AUTOINDEX, 度量方式: COSINE")三、客户端管理工具-Attu
1.部署 Attu
Attu 是 Milvus 的官方图形化管理工具,可以通过 Docker 部署。
下载 Attu 的 Docker Compose 配置文件并启动服务。
shell
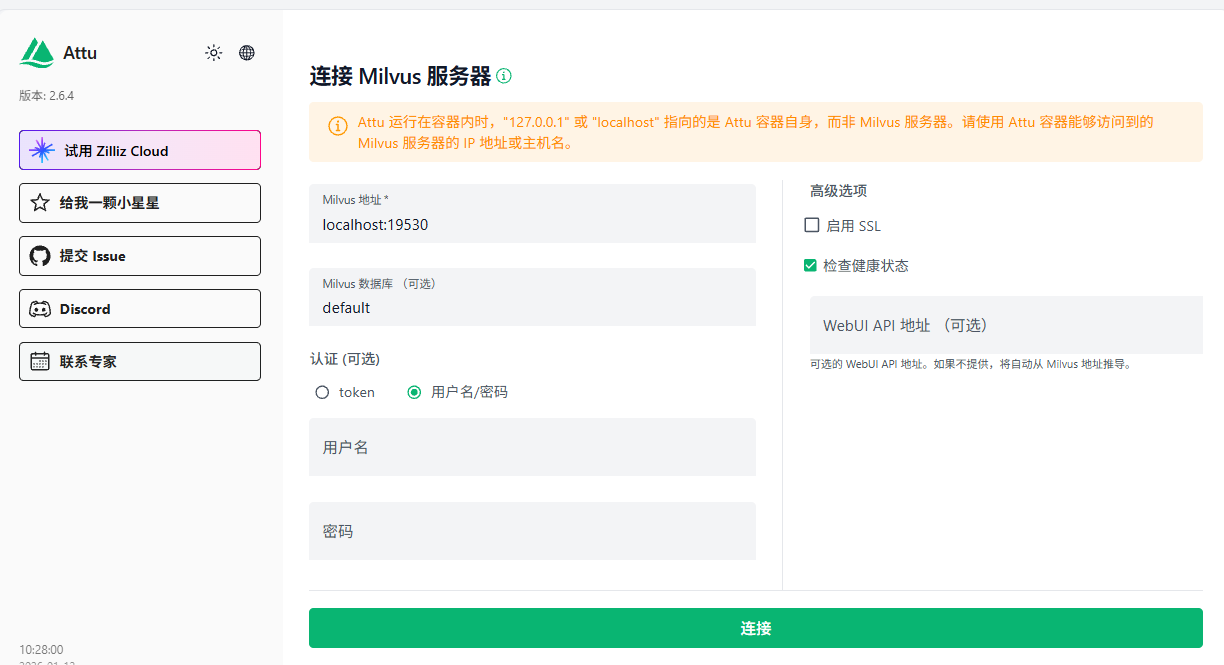
docker run --name milvus-attu -p 8100:3000 -e MILVUS_URL=localhost:19530 zilliz/attu:latest2.连接 Milvus
打开 Attu 的 Web 界面 http://IP:8100/#/connect,输入 Milvus 服务器的 IP 地址和端口(默认为 19530)进行连接。
注意:Attu的容器与Milvus不是一个容器,若Milvus主机开启了防火墙,需要在防火墙上放通
3.管理集合和数据
在 Attu 界面上可以直观地创建、查看、编辑和删除集合,以及插入、查询和删除数据。