TL;DR
- 场景:在应用 Scikit-Learn 进行逻辑回归时,如何调整 max_iter 来提高训练精度,处理未收敛的问题。
- 结论:过大的 max_iter 可能导致过拟合,实际操作中需平衡计算时间与预测精度。
- 产出:通过调整 max_iter 和 multi_class 参数,获得最优的模型训练和分类效果。

版本矩阵
| 已验证版本 | 说明 |
|---|---|
| Scikit-Learn 0.24+ | 使用 LogisticRegression 类的 max_iter 和 multi_class 参数 |
| Python 3.8+ | 适用于该版本的 Python 环境 |
| matplotlib 3.4+ | 绘制学习曲线和准确度变化图 |
逻辑回归的Scikit-Learn实现
续接上一节剩余的内容。
max_iter
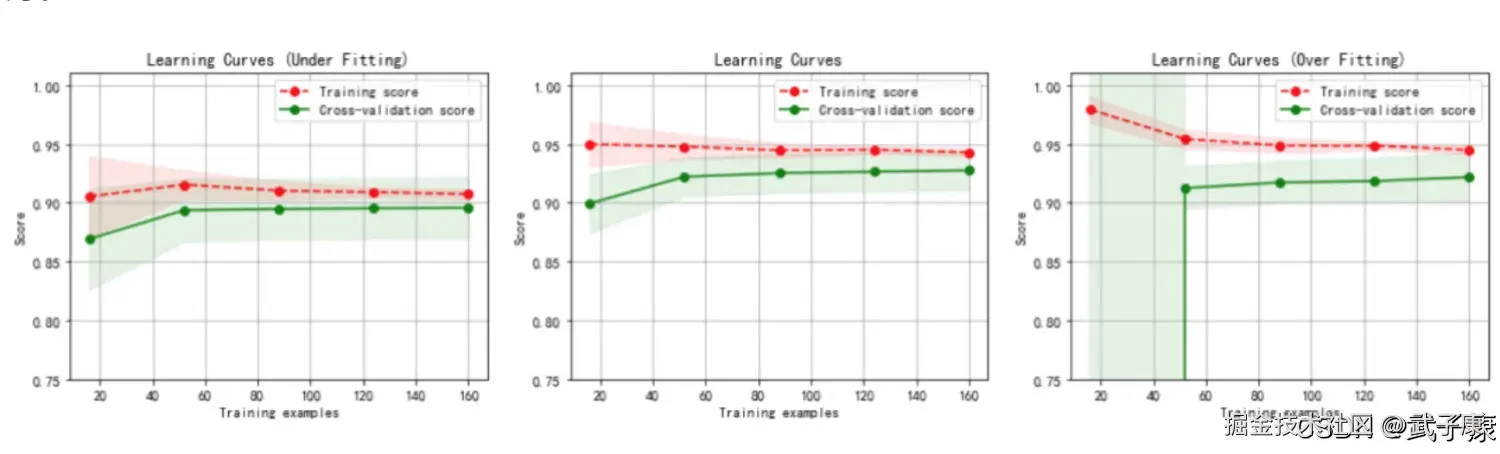
逻辑回归的数学目的是求解能够让模型最优化,你和成都最好的参数w的值,即求解能够让损失函数J(w)最小化的w值。对于二元逻辑回归来说,有多种方法可以用来求解参数w,最常见的有梯度下降法(Gradient Descent),坐标下降法(Coordinate Descent),牛顿法(Newton-Raphson method)等,其中又以梯度下降法最著名。每种方法都涉及到了复杂的数学原理,但这些计算在执行的任务其实是类似的。 来看看数据集下的max_iter的学习曲线:
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression as LR
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
# 加载数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 定义存储结果的列表
l2 = []
l2test = []
# 划分训练集和测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, y, test_size=0.3, random_state=420)
# 使用不同的最大迭代次数进行训练
for i in np.arange(1, 201, 10):
# 使用L2正则化,改变最大迭代次数
lrl2 = LR(penalty="l2", solver="liblinear", C=0.9, max_iter=i)
lrl2 = lrl2.fit(Xtrain, Ytrain)
l2.append(accuracy_score(lrl2.predict(Xtrain), Ytrain))
l2test.append(accuracy_score(lrl2.predict(Xtest), Ytest))
# 将训练集和测试集的结果绘制成图
graph = [l2, l2test]
color = ["black", "gray"]
label = ["L2", "L2test"]
plt.figure(figsize=(20, 5))
# 绘制图形
for i in range(len(graph)):
plt.plot(np.arange(1, 201, 10), graph[i], color[i], label=label[i])
plt.legend(loc=4) # 图例位置右下角
plt.xticks(np.arange(1, 201, 10)) # 设置x轴刻度
plt.xlabel('Max Iterations')
plt.ylabel('Accuracy')
plt.title('Accuracy vs Max Iterations')
plt.show()
# 打印本次求解中真正实现的迭代次数
lr = LR(penalty="l2", solver="liblinear", C=0.9, max_iter=300).fit(Xtrain, Ytrain)
print("Number of iterations:", lr.n_iter_)当max_iter中限制的步数已经走完了,逻辑回归却还没没有找到损失函数的最小值,参数w的值还没有被收敛,sklearn就会弹出下面的警告。 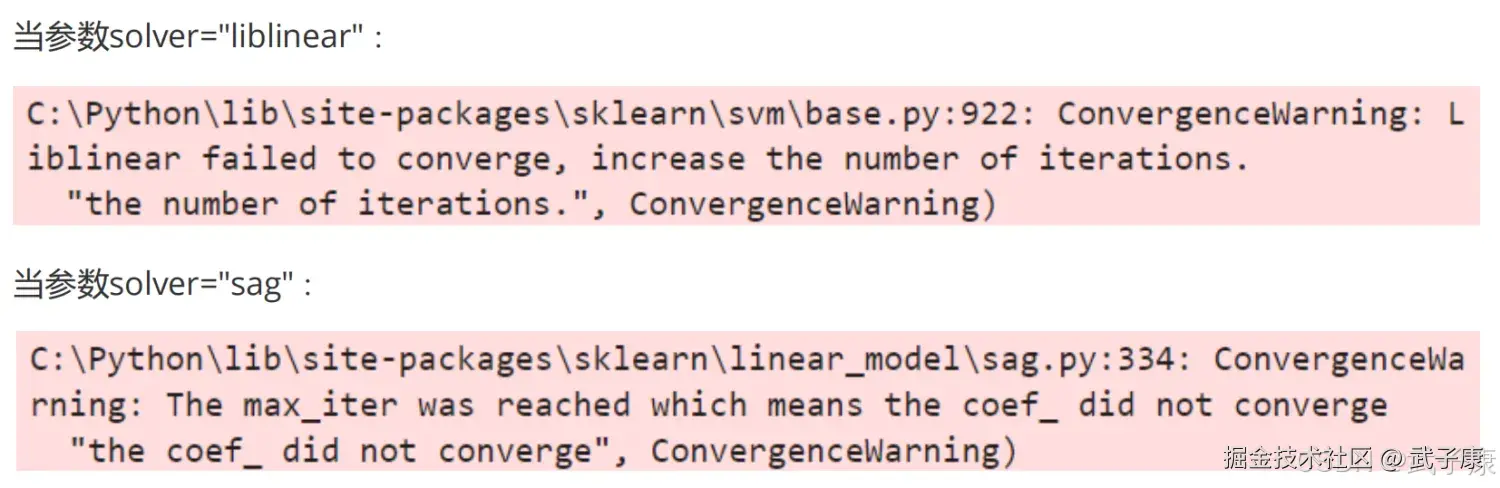 虽然写法看起来不同,但是其实含义都一样,这是在提醒我们:参数没有收敛,请增大max_iter中输入的数字。 但是我们不一定要听sklearn的,max_iter很大,意味着步长小,模型运行得会更加缓慢。我们在梯度下降中追求的是损失函数的最小值,但这也可能意味着我们的模型会过拟合(在训练集上表现的太好,在测试集上不一定)。因此,如果在max_iter红条的情况下,模型的训练和预测效果都已经不错了,那我们就不需要再增大max_iter中的数目了,毕竟一切都以模型的预测效果为基准,只要模型预测的效果好,运行又快,那就一切都好。
虽然写法看起来不同,但是其实含义都一样,这是在提醒我们:参数没有收敛,请增大max_iter中输入的数字。 但是我们不一定要听sklearn的,max_iter很大,意味着步长小,模型运行得会更加缓慢。我们在梯度下降中追求的是损失函数的最小值,但这也可能意味着我们的模型会过拟合(在训练集上表现的太好,在测试集上不一定)。因此,如果在max_iter红条的情况下,模型的训练和预测效果都已经不错了,那我们就不需要再增大max_iter中的数目了,毕竟一切都以模型的预测效果为基准,只要模型预测的效果好,运行又快,那就一切都好。
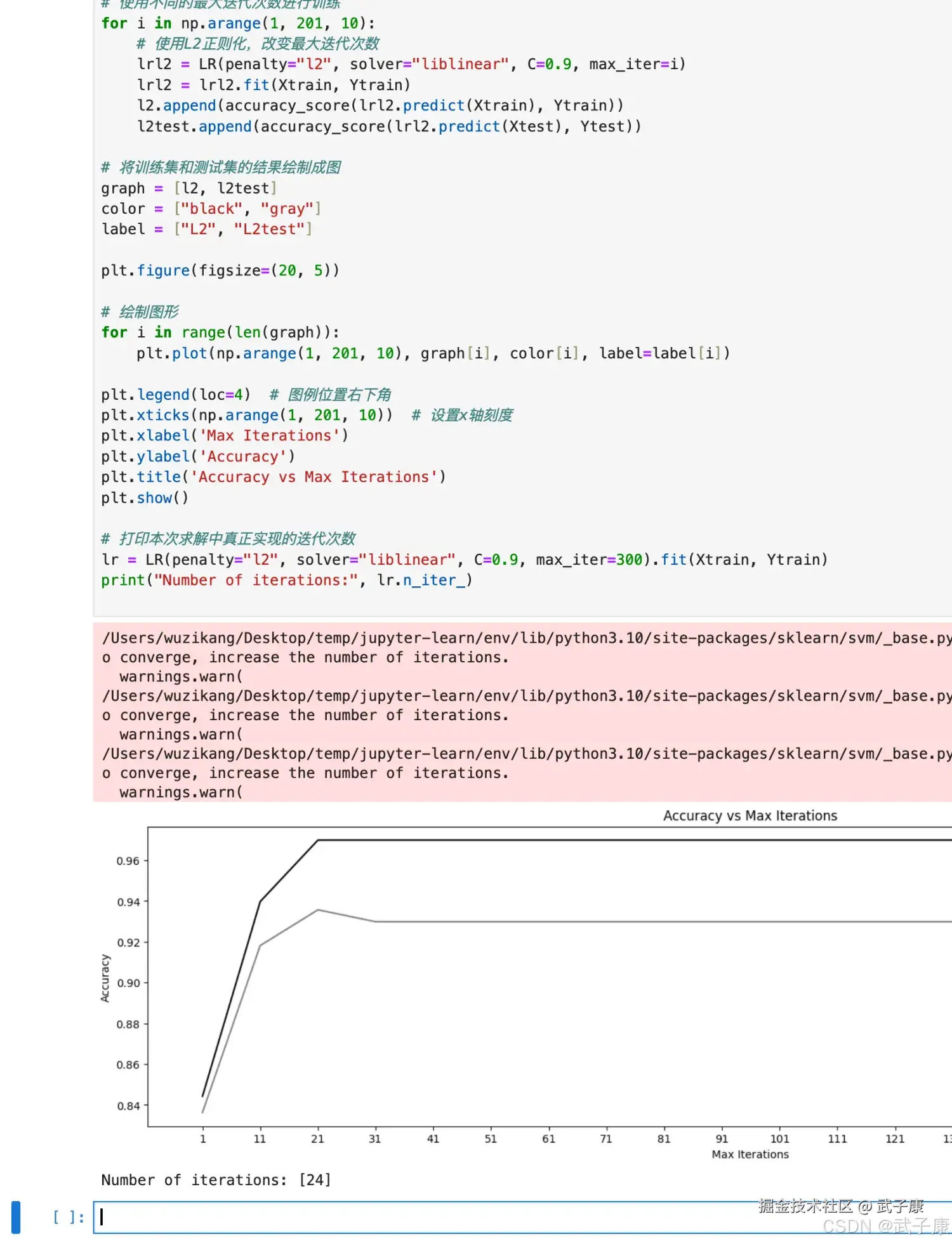
生成的图片如下图所示: 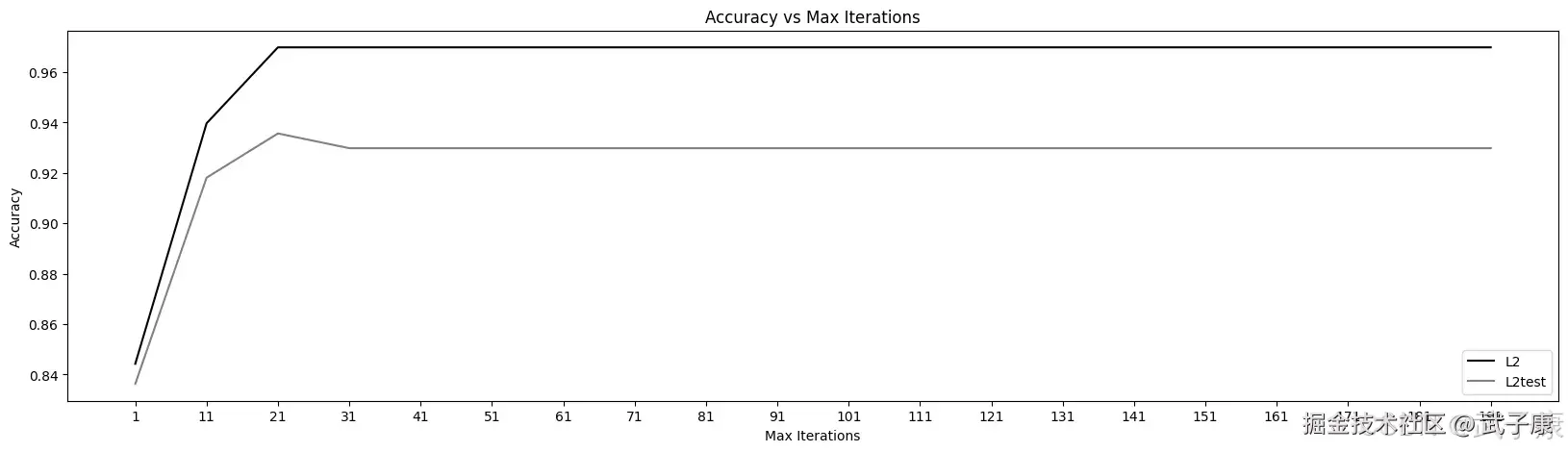
分类方式选参数
multi_class参数决定了我们分类方式的选择,有ovr和multinomial两个值可以选择,默认是ovr。 ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要是在多元回归逻辑上。 OvR的思想很简单,无论你是多少元回逻辑回归,我们都可以看做二元逻辑回归。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。
生成三个假的数据集: 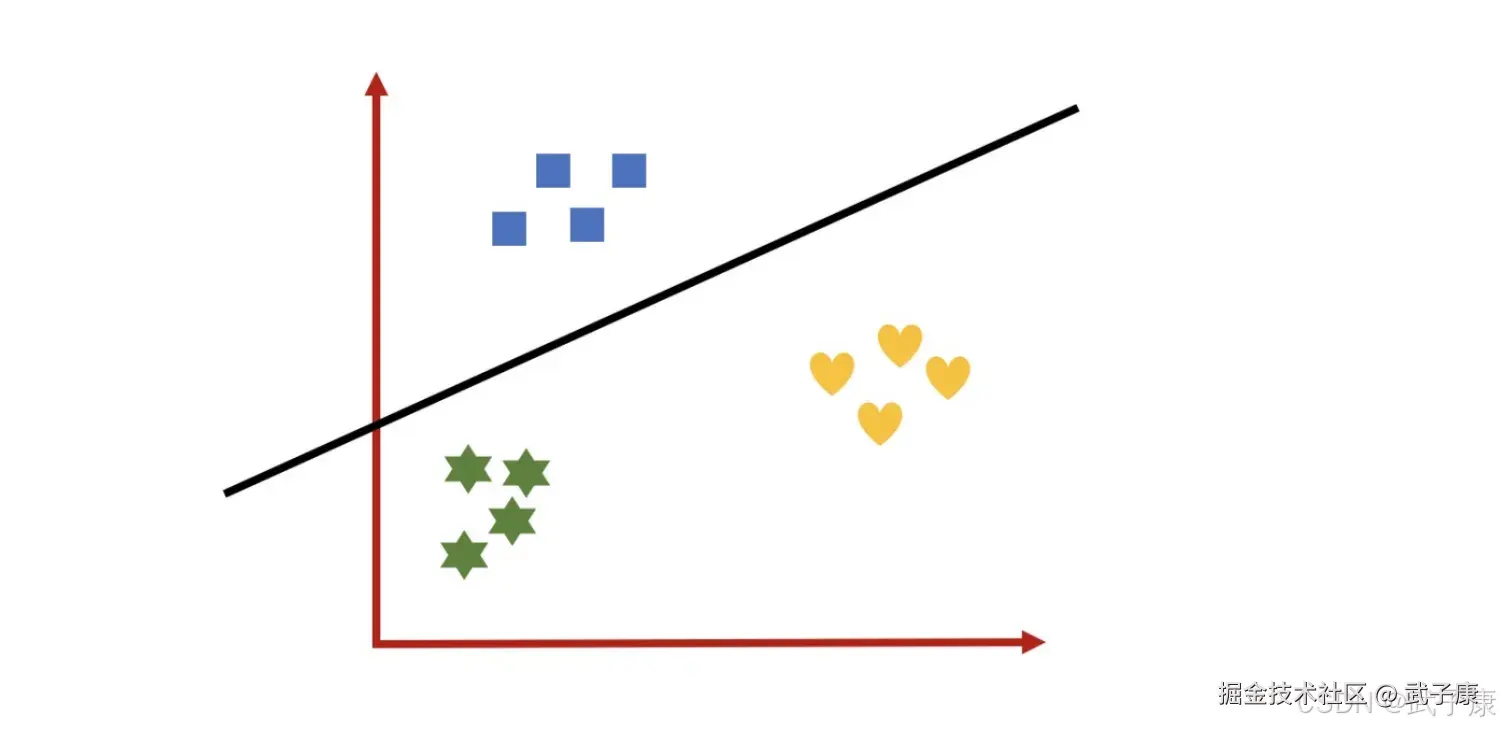
定义一个函数: 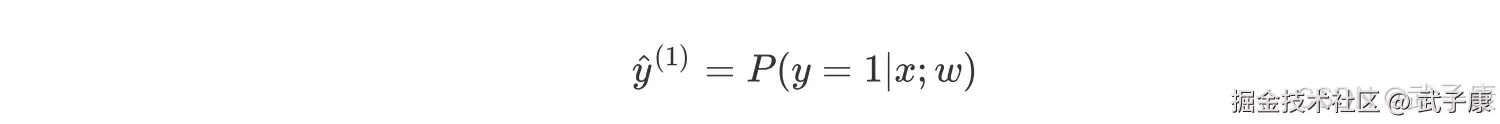
处理过的数据集是二分类问题,通过逻辑回归可能得到黑线区分不同类别。 同理: 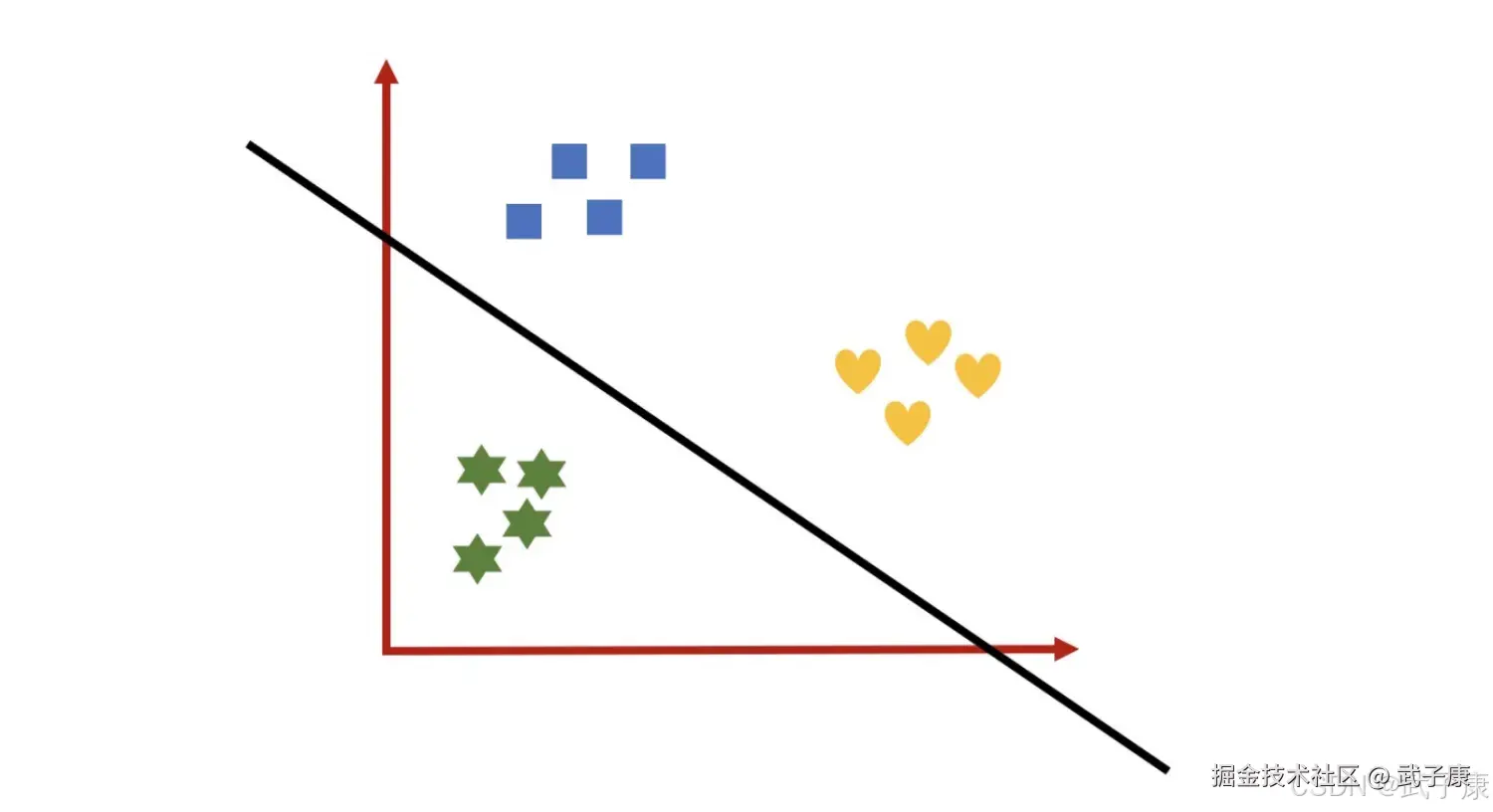 定义一个函数:
定义一个函数: 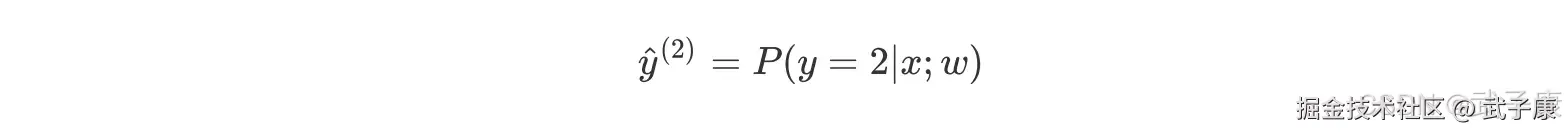 绘制的图像如下所示:
绘制的图像如下所示: 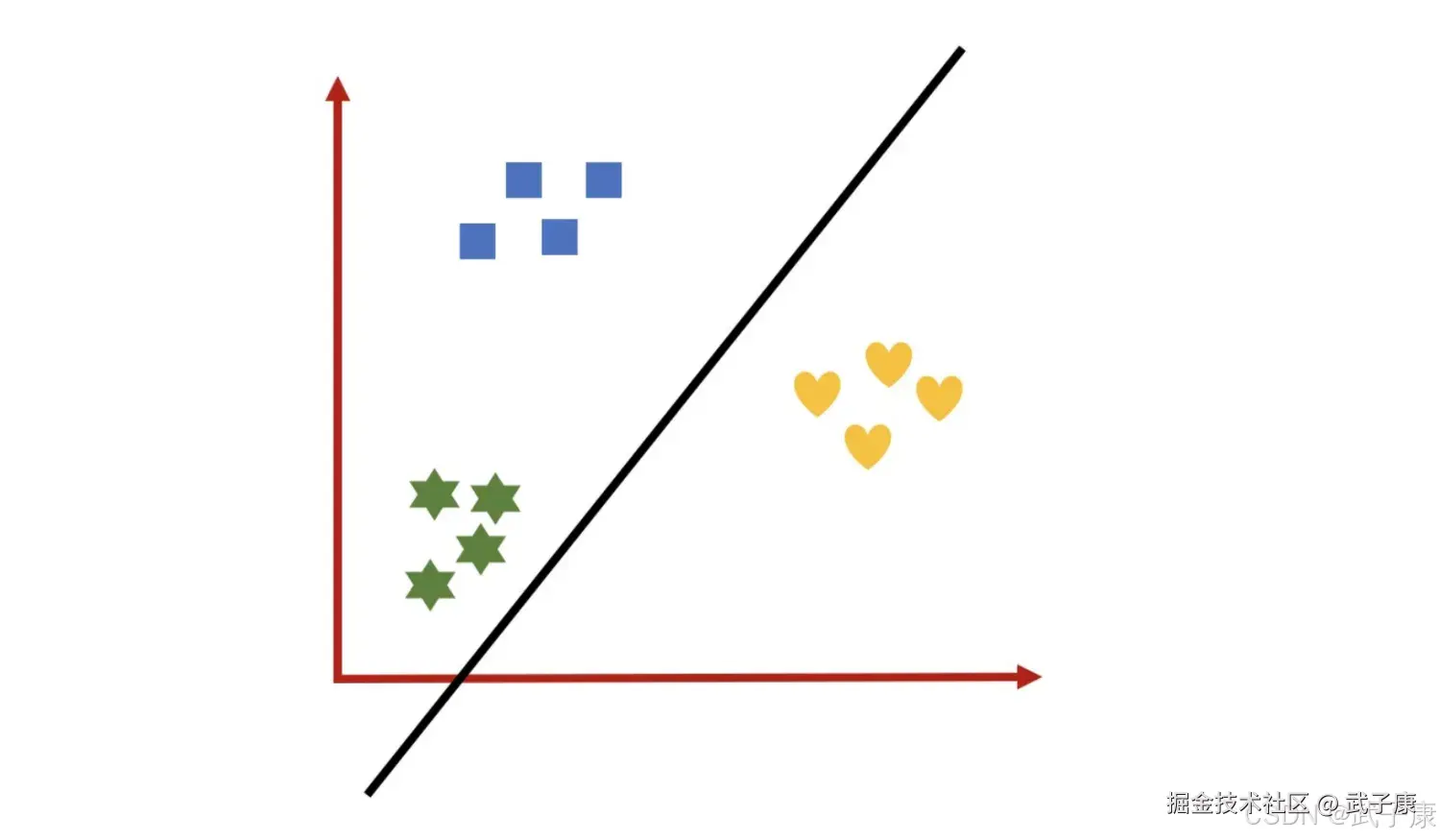 定义一个函数:
定义一个函数: 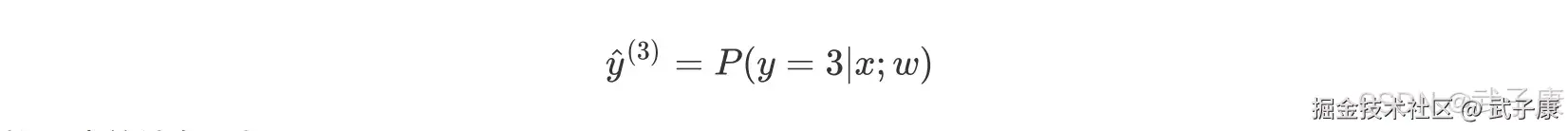
将公式总结在一起: 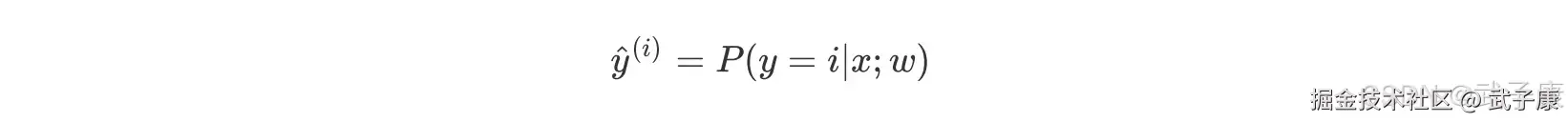 处理过的数据集就是二分类问题,通过逻辑回归可能得到黑线区分不同类别。 同理,当需要预测新的数据类别时,使用如下公式:
处理过的数据集就是二分类问题,通过逻辑回归可能得到黑线区分不同类别。 同理,当需要预测新的数据类别时,使用如下公式: 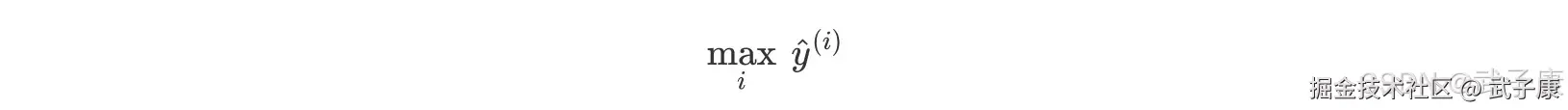 使用不同的函数来预测输入x,分别计算不同y^的值,然后取其中的最大值。哪个类别对应的 i 越大,就认为 y^属于哪个类别。 而 MvM 则相对复杂,这里举 MvM 特例 one-vs-one(OvO)作讲解。 如果模型有 T 类,我们每次在所有的 T 类样本里面选择两类样本出来,不防记为 T1 和 T2,把所有的输出为 T1 和 T2 的样本放在一起,把 T1 作为正例,T2 作为负例,进行二元逻辑回归,得到模型参数,我们一共需要 T(T-1)/2 次分类。 从上面描述可以看出 OvR 相对简单,但分类效果相对较差(这里指大多数样本分布情况,某些样本分布下 OvR 可能更好)。而 MvM 分类相对精确,但是分类速度没有 OvR 快。 如果选择了 OvR,则 4 种损失函数的优化方法 liblinear、newton-cg、bfgs 和 sag 都可以选择。但是如果选择了multinomial。
使用不同的函数来预测输入x,分别计算不同y^的值,然后取其中的最大值。哪个类别对应的 i 越大,就认为 y^属于哪个类别。 而 MvM 则相对复杂,这里举 MvM 特例 one-vs-one(OvO)作讲解。 如果模型有 T 类,我们每次在所有的 T 类样本里面选择两类样本出来,不防记为 T1 和 T2,把所有的输出为 T1 和 T2 的样本放在一起,把 T1 作为正例,T2 作为负例,进行二元逻辑回归,得到模型参数,我们一共需要 T(T-1)/2 次分类。 从上面描述可以看出 OvR 相对简单,但分类效果相对较差(这里指大多数样本分布情况,某些样本分布下 OvR 可能更好)。而 MvM 分类相对精确,但是分类速度没有 OvR 快。 如果选择了 OvR,则 4 种损失函数的优化方法 liblinear、newton-cg、bfgs 和 sag 都可以选择。但是如果选择了multinomial。
python
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_iris
iris = load_iris()
for multi_class in ('multinomial', 'ovr'):
clf = LR(solver='sag', max_iter=100, random_state=42,
multi_class=multi_class).fit(iris.data,iris.target)
#打印两种multi_class模式下的训练分数
#%的⽤法,⽤%来代替打印的字符串中,想由变量替换的部分。%.3f表示,保留三位⼩数的浮点数。%s表示,
字符串。
#字符串后的%后使⽤元祖来容纳变量,字符串中有⼏个%,元组中就需要有⼏个变量
print("training score : %.3f (%s)" % (clf.score(iris.data,
iris.target),multi_class))执行结果如下图所示: 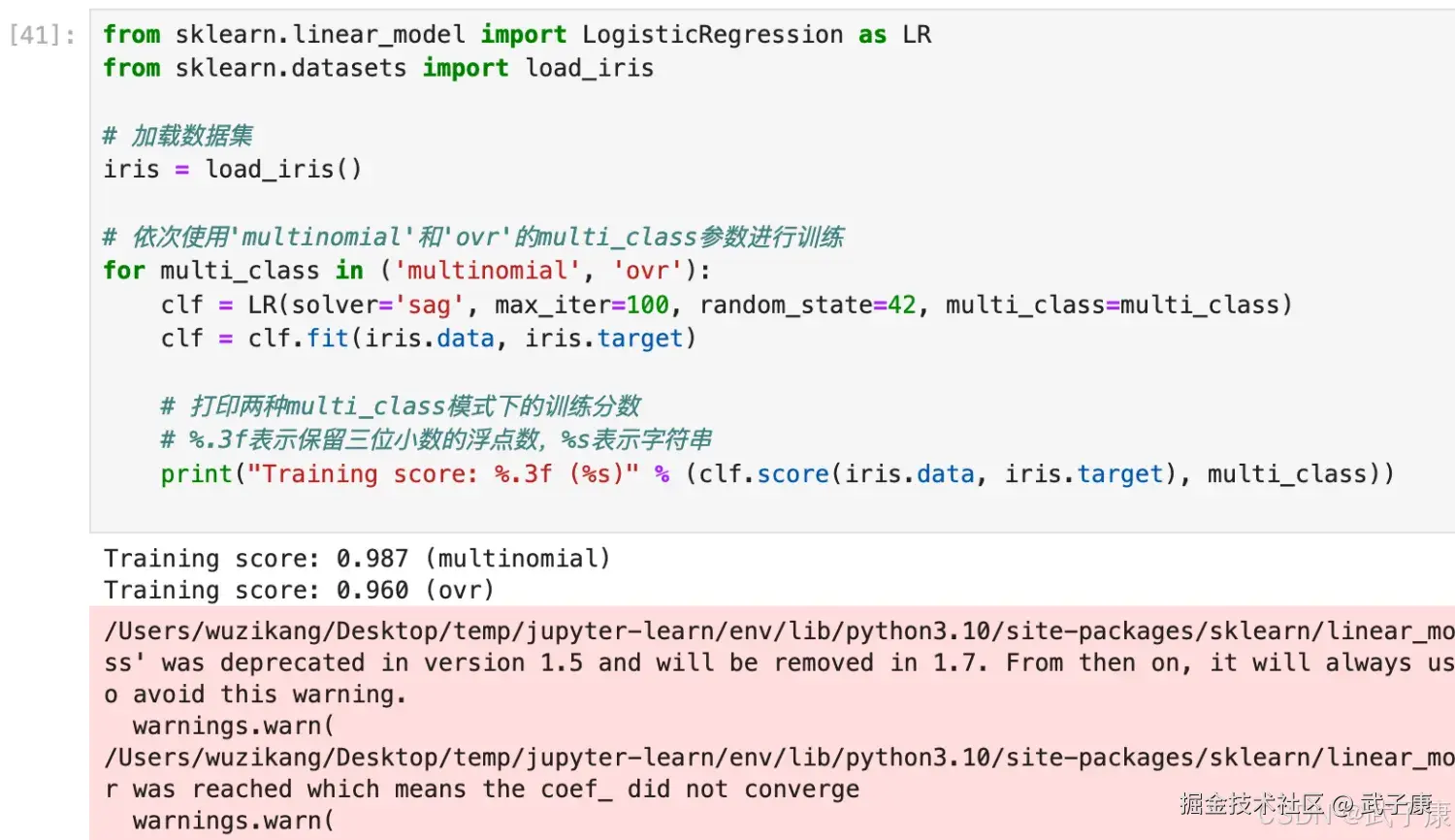
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 警告:max_iter 未收敛 | 迭代次数不足,模型未收敛 | LogisticRegression 中 max_iter 参数 | 增大 max_iter,同时注意平衡训练速度与过拟合 |
| 模型过拟合(训练集准确率高,测试集低) | 迭代次数过高,模型学习过多细节 | max_iter 设置过大,训练过程过于精细 | 调整 max_iter 至合理范围,避免过度迭代 |
| 分类效果不理想 | multi_class 参数选择不当 | LogisticRegression 中 multi_class 设置 | 对于多类问题,使用 multinomial 或调整 OvR 设置 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解