FinBERT 深度技术解析:面向金融领域的领域自适应 BERT 实践
1. 整体介绍
1.1 项目概要
FinBERT 是一个针对金融文本情感分析 任务进行领域自适应(Domain Adaptation)的预训练语言模型。项目由 Prosus AI 团队的研究人员发布,其核心贡献在于证明了在特定领域(金融)语料上对通用 BERT 模型进行中间阶段训练(Further Pre-training),再在特定任务(情感分类)上微调的有效性。
- 项目地址 : GitHub - ProsusAI/finBERT (注:原文未提供 star/fork 数据,实际分析时可补充)
- 模型地址 : Hugging Face - ProsusAI/finbert
- 技术基底: 基于 Google BERT,使用 PyTorch 实现。
1.2 主要功能与解决问题
- 核心功能: 对金融文本(如新闻标题、财报摘要、社交媒体评论)进行细粒度情感三分类(正面、负面、中性),并提供置信度概率。
- 面临问题 :
- 领域鸿沟: 通用语言模型(如 BERT-base)在通用语料上训练,其词汇和语义理解与包含大量专业术语、特定表达(如"熊市"、"稀释每股收益")的金融文本存在差距。
- 标注数据稀缺: 高质量、大规模的金融情感标注数据获取成本高。
- 对应人群与场景 :
- 量化投资研究员: 自动化分析海量财经新闻对市场情绪的影响。
- 风险管理部门: 监测公众舆论对特定公司或行业的负面情绪。
- 金融科技开发者: 为其产品(如投资助手、资讯聚合平台)嵌入情感分析能力。
- 解决方案与优势 :
- 旧方式: 1) 直接使用通用情感分析模型,准确率在金融领域欠佳;2) 使用特征工程+传统机器学习(如 SVM),需要大量人工设计特征,泛化能力有限。
- 新方式 (FinBERT) : 采用"预训练-领域适应-任务微调"的范式。
- 步骤一 (领域适应): 在大型无标签金融语料(Reuters TRC2)上继续预训练 BERT,使其吸收领域知识。
- 步骤二 (任务微调): 在规模相对较小的有标签金融情感数据集(Financial PhraseBank)上进行有监督微调。
- 优势: 相较于从头训练,它利用了 BERT 强大的通用语言表示能力;相较于直接微调,它通过领域适应弥合了领域鸿沟,从而在有限的标注数据上取得更好性能。
1.3 商业价值预估
- 代码/技术成本 :
- 数据成本: 需获取 Reuters TRC2(需申请)和 Financial PhraseBank(公开),主要成本在于数据处理与标注(如果自建数据集)。
- 算力成本: 对 BERT-base 进行继续预训练和微调需要 GPU 资源,但远低于从头训练一个大模型。
- 开发成本: 项目已开源核心训练、预测流程,提供了可复现的代码,降低了实现门槛。
- 覆盖问题空间效益 :
- 效益逻辑: 金融文本情感分析是市场情绪量化、自动化报告、风险预警等应用的基础模块。FinBERT 提供了一个效果优于通用模型的现成解决方案。
- 估算 : 其价值并非直接货币收入,而体现在 "效率提升" 和 "决策支持" 上。例如,替代人工审阅部分报告,或将情绪因子纳入量化模型可能带来的潜在收益提升。对于一家中型基金或金融信息公司,自研类似模块的工程师投入可能超过数人月,FinBERT 可直接节省这部分成本并加速产品上线。
2. 详细功能拆解
| 功能模块 | 产品视角 | 技术视角 |
|---|---|---|
| 情感预测服务 | 用户输入文本,获得情感标签和得分。支持批量文本文件处理。 | 提供 predict.py 脚本和 Flask API (main.py)。内部完成句子分割、Tokenization、模型推理、Softmax 计算和得分聚合。 |
| 模型训练与微调 | 允许用户使用自定义金融情感数据训练更适合自己场景的模型。 | 提供 finbert_training.ipynb。实现了数据加载、动态 Masking、训练循环、验证、以及对抗灾难性遗忘的渐进式解冻 和判别式学习率技术。 |
| 领域自适应语言模型 | 提供已适应金融领域的预训练 BERT 权重,作为下游任务的更好起点。 | 在 Reuters TRC2 语料上执行 MLM(掩码语言模型)任务进行继续预训练。项目提供了训练好的模型下载。 |
| 数据处理工具 | 将原始 Financial PhraseBank 数据转换为模型训练所需的格式。 | 提供 scripts/datasets.py,处理原始标注文件,划分训练/验证/测试集,并转换为 .csv 格式。 |
3. 技术难点挖掘
- 领域适应与灾难性遗忘的平衡: 在金融语料上继续预训练时,如何保留 BERT 在通用语料上学到的通用语法、语义知识,避免"遗忘"。
- 小样本任务微调: Financial PhraseBank 数据集规模有限,如何在不过拟合的情况下,有效微调一个拥有 1.1 亿参数的模型。
- 金融文本的语义复杂性: 例如,"公司股价承压"是负面,但"空头承压"可能对多方是正面。模型需要理解上下文和金融逻辑。
- 遗留技术栈迁移 : 项目基于旧的
pytorch_pretrained_bert,向现代transformers库迁移需要兼容性处理。
4. 详细设计图
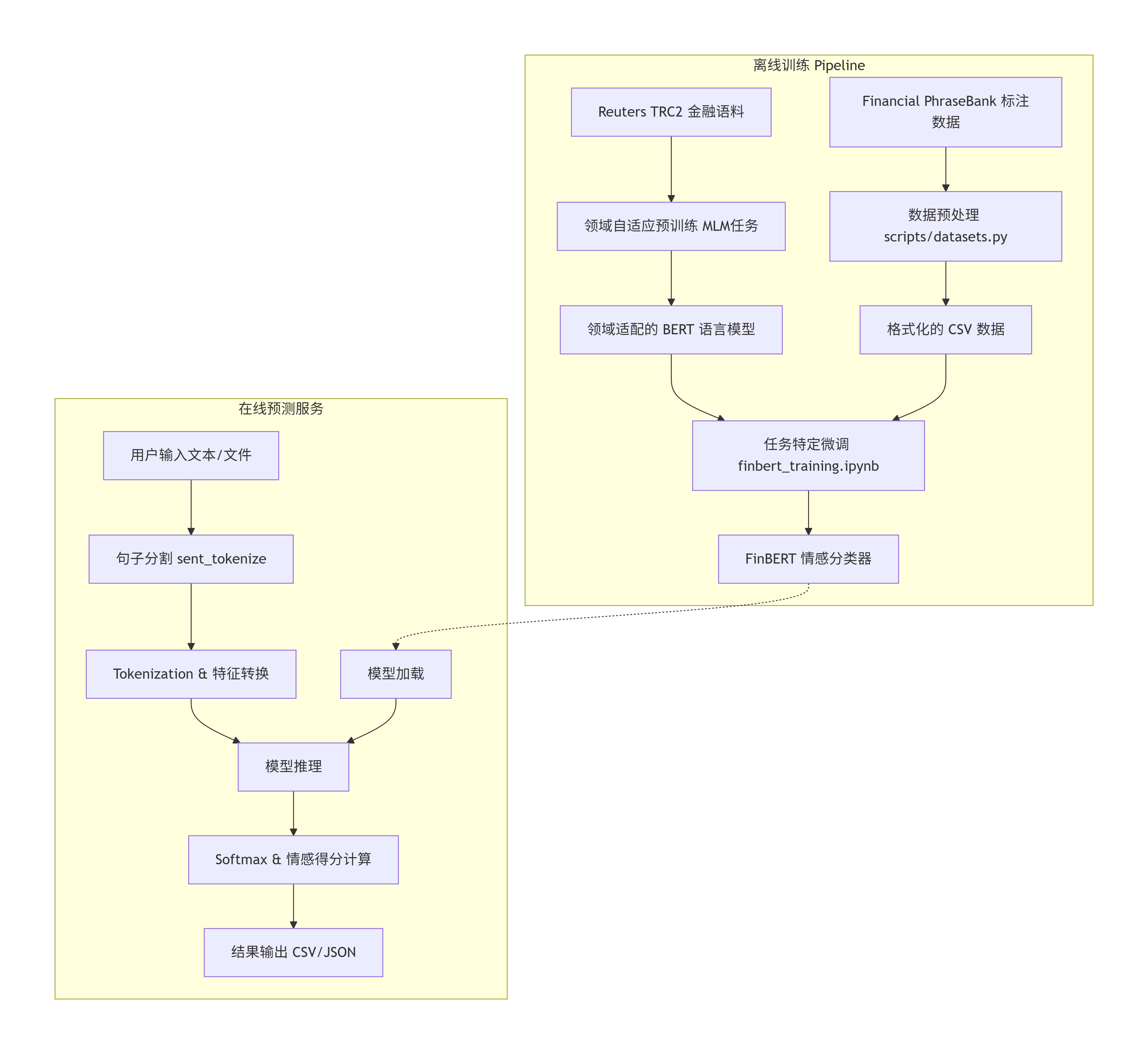
4.1 系统架构图
该图展示了 FinBERT 从训练到服务的核心组件和数据流。
4.2 核心预测链路序列图
此图描述了 predict 函数处理一段文本时的内部调用序列。
torch Model finbert.utils nltk predict.py User torch Model finbert.utils nltk predict.py User loop 每个批次 调用 predict(text, model) sent_tokenize(text) 句子列表 sent1, sent2... chunks(句子列表, batch_size) convert_examples_to_features() tokenizer.tokenize(), 添加 CLS, SEP 构建 input_ids, attention_mask... features tensor(features).to(device) model(**batch_tensors) logits softmax(logits) 计算 sentiment_score (pos - neg) DataFrame(句子, 预测, 分数)
4.3 核心类关系图
展示了项目核心类之间的依赖和组成关系。
配置依赖
使用
继承
创建
创建
处理
FinBert
+Config config
+prepare_model(label_list)
+get_data(phase)
+create_the_model()
+get_loader(examples, phase)
+train(train_examples, model)
+evaluate(model, examples)
Config
-data_dir
-bert_model
-model_dir
-max_seq_length
-discriminate
-gradual_unfreeze
...
+init(...)
InputExample
+guid
+text
+label
+agree
+init(guid, text, label, agree)
InputFeatures
+input_ids
+attention_mask
+token_type_ids
+label_id
+init(...)
DataProcessor
+_read_tsv(input_file)
FinSentProcessor
+get_examples(data_dir, phase)
+get_labels()
+_create_examples(lines, set_type)
finbert.utils
4.4 核心函数 predict 拆解图
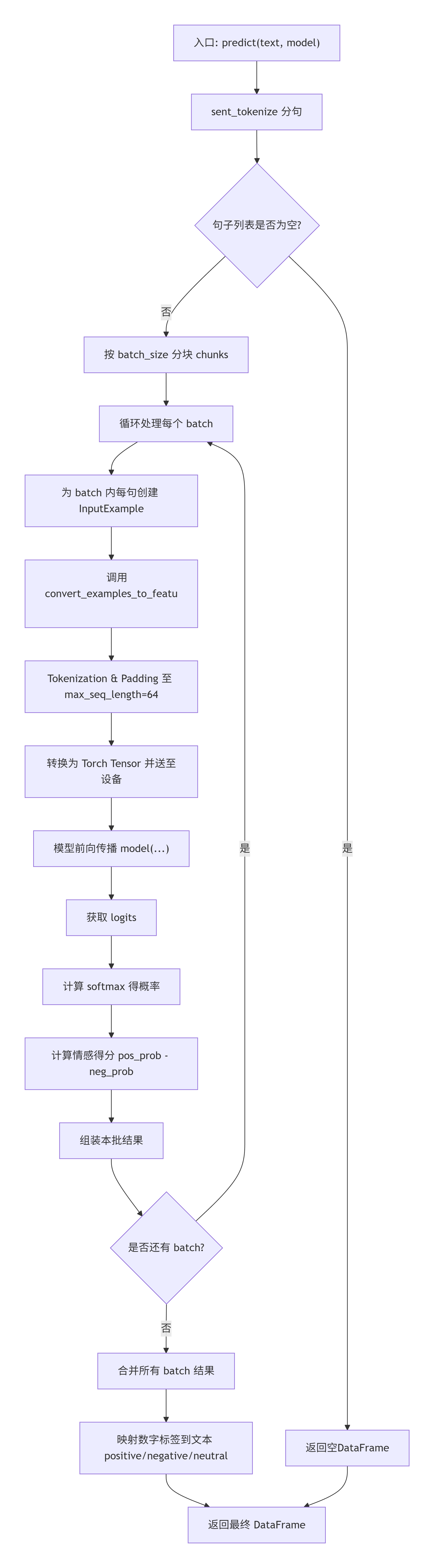
5. 核心函数解析
以下重点解析驱动预测流程的核心函数 predict(位于 finbert/finbert.py)。该函数完美体现了将原始文本转换为模型输入、执行推理、后处理输出的完整链路。
python
def predict(text, model, write_to_csv=False, path=None, use_gpu=False, gpu_name='cuda:0', batch_size=5):
"""
预测给定文本中句子的情感。
参数:
text: 待分析的字符串文本。
model: 已加载的 BertForSequenceClassification 模型。
write_to_csv: 是否将结果写入CSV文件。
path: CSV文件路径。
use_gpu: 是否使用GPU进行推理。
gpu_name: 指定GPU设备名称。
batch_size: 批处理大小,影响内存占用和速度。
返回:
包含句子、预测结果、概率和情感得分的DataFrame。
"""
# 设置模型为评估模式,关闭Dropout等训练层
model.eval()
# 1. 文本预处理:使用NLTK进行句子级分割
# 金融文本常由多个句子组成,分句处理更精细
sentences = sent_tokenize(text)
# 2. 设备设置:根据参数决定使用CPU或GPU
device = gpu_name if use_gpu and torch.cuda.is_available() else "cpu"
logging.info("Using device: %s " % device)
# 3. 标签定义
label_list = ['positive', 'negative', 'neutral']
label_dict = {0: 'positive', 1: 'negative', 2: 'neutral'} # 数字索引到文本标签的映射
# 4. 初始化结果DataFrame
result = pd.DataFrame(columns=['sentence', 'logit', 'prediction', 'sentiment_score'])
# 5. 批处理预测:将句子列表分块,减少内存峰值并可能加速
for batch in chunks(sentences, batch_size):
# 5.1 为当前batch中的每个句子创建InputExample对象
# InputExample是项目内部定义的数据结构,包含guid和文本
examples = [InputExample(str(i), sentence) for i, sentence in enumerate(batch)]
# 5.2 特征转换:将文本转换为BERT模型所需的数字特征
# 这是关键步骤,调用`convert_examples_to_features`函数
# 它会进行tokenization,添加[CLS]/[SEP],padding,生成input_ids, attention_mask, token_type_ids
features = convert_examples_to_features(examples, label_list, 64, tokenizer) # max_seq_length固定为64
# 5.3 将特征列表转换为PyTorch Tensor,并移动到指定设备
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long).to(device)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long).to(device)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long).to(device)
# 5.4 模型推理(不计算梯度,节省内存)
with torch.no_grad():
model = model.to(device) # 确保模型在正确的设备上
# 前向传播,获取未归一化的logits
logits = model(all_input_ids, all_attention_mask, all_token_type_ids)[0]
logging.info(logits)
# 5.5 后处理:将logits转换为概率分布
# 先移至CPU并转为numpy数组,然后计算softmax
logits = softmax(np.array(logits.cpu())) # `softmax`是项目内部定义的函数
# 5.6 计算情感得分:正面概率 - 负面概率
# 该得分提供了情感的强度和方向,比单纯的三分类更细致
sentiment_score = pd.Series(logits[:, 0] - logits[:, 1])
# 5.7 获取预测标签(概率最大的类别)
predictions = np.squeeze(np.argmax(logits, axis=1))
# 5.8 组装当前批次的临时结果
batch_result = {'sentence': batch,
'logit': list(logits), # 存储完整的概率向量
'prediction': predictions, # 存储预测的类别索引
'sentiment_score': sentiment_score}
batch_result = pd.DataFrame(batch_result)
# 5.9 将当前批次结果追加到总结果中
result = pd.concat([result, batch_result], ignore_index=True)
# 6. 最终处理:将数字预测索引映射回可读的文本标签
result['prediction'] = result.prediction.apply(lambda x: label_dict[x])
# 7. 可选:将结果写入CSV文件
if write_to_csv:
result.to_csv(path, sep=',', index=False)
# 8. 返回包含所有分析结果的DataFrame
return result函数亮点与不足分析:
- 亮点 :
- 完整的工业级预测流程: 集成了文本分句、批处理、设备管理、推理、后处理全链路。
- 情感得分量化 : 提供了
positive_prob - negative_prob的连续型情感得分,便于排序和阈值化分析,比单一分类更具实用性。 - 内存友好 : 通过
chunks函数支持批处理,能预测任意长度的文档。
- 不足与风险点 :
- 固定序列长度64 :
max_seq_length=64是硬编码的,过长的句子会被截断 (具体逻辑在convert_examples_to_features中:取前1/4和后3/4)。这可能损失重要信息。在生产中需根据实际文本长度分布调整。 - 依赖旧版库 : 使用
pytorch_pretrained_bert,与现代transformers库的 API 不兼容,增加了维护和集成成本。 - Tokenizer 不一致 : 代码中
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')写死,理论上应与加载的 FinBERT 模型本身的 tokenizer 保持一致,从模型目录加载更稳妥。
- 固定序列长度64 :
总结:FinBERT 项目是一个经典的领域自适应 NLP 应用案例。它清晰地展示了如何通过"通用预训练 -> 领域适应 -> 任务微调"的三段式方法,解决垂直领域中的 NLP 问题。尽管其代码实现基于较旧的库,但其架构设计、对抗灾难性遗忘的技术(渐进解冻、判别式学习率)以及提供的完整工具链(训练、预测、数据预处理)仍具有很高的学习和参考价值。对于希望在金融、法律、医疗等领域应用 BERT 类模型的开发者而言,FinBERT 提供了一个切实可行的技术蓝图。