前言
在上一篇中(源码Demo)大家都在说Agent,那么Agent到底是什么?,我们了解Agent的概念,并以代码 的形式介绍,这一篇将了解AI中的另外一个名词LangChain。
LangChain是什么
首先了解LangChain是什么.....
LangChain是一个用于构建大模型应用的开源框架。
它像乐高积木一样,由7个关键模块组成,各个模块负责相关的部分:
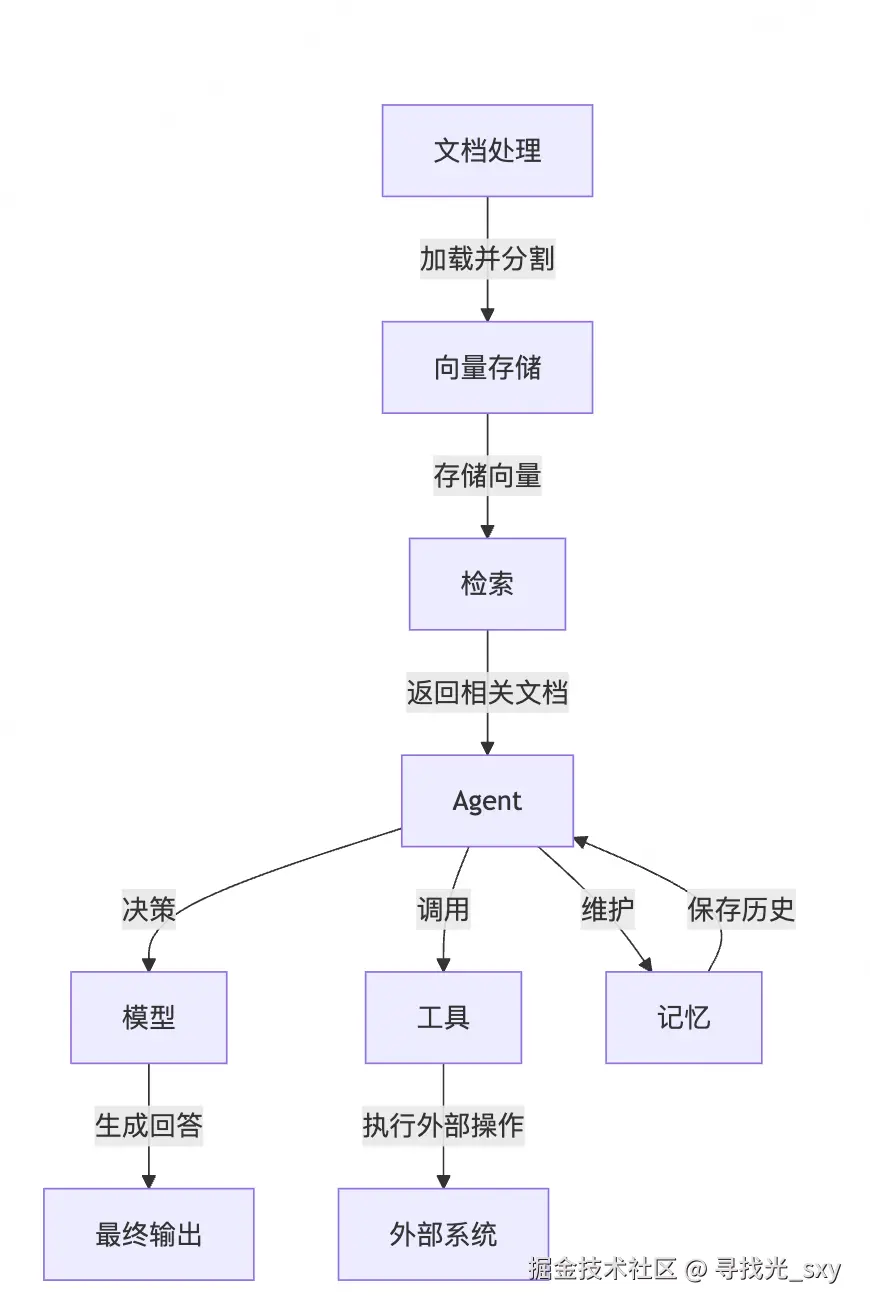
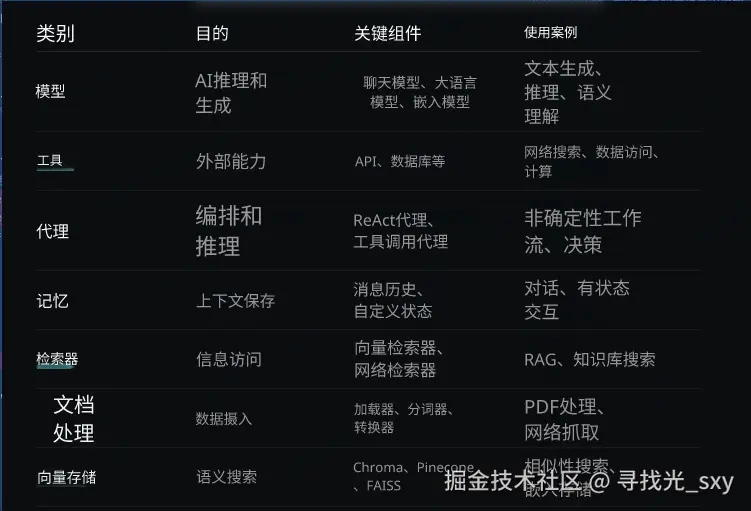
甩一张官方表格(中英对照):

1、Models
用于封装和调用各种大语言模型LLM,提供统一的接口和标准化的交互方式:
- 统一接口 : 解决不同模型提供商
API差异问题 - 参数管理 :集中管理
API密钥、temperature等参数 - 集成方便 :天然适配于
LangChain的一些别的组件和库 - 错误处理:内置重试、错误处理机制
py
def create_llm():
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
raise ValueError("请在 .env 文件中配置 DASHSCOPE_API_KEY")
llm = ChatOpenAI(
model="qwen-plus", # 通义千问模型
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.7, # 控制输出的随机性
)
return llm2、Tools
用于扩展AI能力的外部功能,使AI能够与外部系统交互
- 功能扩展 :扩展
AI的外部能力,如调用地图API、时间API等 - 系统交互:与外部的系统交互,访问数据库等
- 任务执行:执行计算任务等
除了上面tool本身要做的事之外,langChain还提供装饰器@tool去将普通函数转换为Agent可调用的工具,而不用去手写:
- 自动生成工具描述 :从函数文档字符串提取,供
Agent理解工具用途 - 自动生成工具
Schema:将函数签名转换为JSON Schema,供Agent去调用 - 工具注册 :将工具注册到
Agent的工具列表中
py
"""
工具模块包
包含数学工具和时间工具
"""
from .math_tools import add
from .time_tools import get_current_time
__all__ = [
"add",
"get_current_time",
]
py
"""
数学工具模块
用于执行数学运算
"""
from langchain.tools import tool
@tool
def add(a: int, b: int) -> int:
"""
计算两个整数的和。
Agent 会在需要进行加法运算时自动调用此工具。
Args:
a: 第一个整数
b: 第二个整数
Returns:
两个整数的和
"""
try:
# 处理字符串类型的输入(Agent 可能传递字符串格式的数字)
a = int(a) if isinstance(a, str) else a
b = int(b) if isinstance(b, str) else b
return a + b
except (ValueError, TypeError) as e:
return f"计算时发生错误: 无法将输入转换为整数 - {str(e)}"
except Exception as e:
return f"计算时发生错误: {str(e)}"
py
"""
时间工具模块
用于获取当前日期和时间
"""
from datetime import datetime
from langchain.tools import tool
@tool
def get_current_time() -> str:
"""
获取当前时间。
Agent 会在需要获取当前时间时自动调用此工具。
Returns:
当前时间(格式为 HH:MM:SS)
"""
return datetime.now().strftime("%H:%M:%S")3、Agents
用于初始化Agent,并封装了循环管理 、工具调用 、 短期记忆 、错误处理 、迭代控制 、日志输出等相关逻辑,不再需要手写:
- 初始化
Agent:构建一个采用ReAct模式的Agent,由LLM驱动,配备工具列表和提示词 - 循环管理 :执行
Agent循环逻辑,自动管理ReAct循环 - 工具调用 :根据
Agent决策调用工具并获取结果 - 短期记忆 :封装
memory模块,用于记忆多轮对话 - 错误处理:处理解析错误和工具执行异常
- 迭代控制:限制最大迭代次数,防止无限循环
- 日志输出 :
verbose=True时,显示详细执行过程
py
def create_agent_executor(llm, tools, memory): # 创建Agent执行器
prompt_template = """你是一个友好的 AI 助手。你可以使用工具来回答问题。
你可以使用的工具:
{tools}
使用以下格式:
Question: 需要回答的问题
Thought: 你应该思考要做什么
Action: 要采取的行动,应该是 [{tool_names}] 中的一个
Action Input: 行动的输入
Observation: 行动的结果
... (这个 Thought/Action/Action Input/Observation 可以重复 N 次)
Thought: 我现在知道最终答案了
Final Answer: 对原始问题的最终答案
{chat_history}
Question: {input}
Thought: {agent_scratchpad}"""
prompt = PromptTemplate.from_template(prompt_template) # 创建提示模板
agent = create_react_agent(llm=llm, tools=tools, prompt=prompt) # 创建Agent
agent_executor = AgentExecutor(
agent=agent, # Agent实例
tools=tools, # 工具列表
memory=memory, # 记忆模块
verbose=True, # 是否打印详细信息
handle_parsing_errors=True, # 处理解析错误
max_iterations=5, # 最大迭代次数
)
return agent_executor4、Memory
用于记忆多轮对话,使Agent可以更自然、更智能的多轮对话,而不是单次问答:
- 上下文连贯 :
Agent能理解多轮对话的上下文 - 信息持久化:在单次会话中记住用户提供的信息
- 智能对话:支持需要多轮交互的复杂任务
- 自动管理:无需手动维护对话历史列表
py
def create_memory(): # 创建记忆模块
memory = ConversationBufferMemory(
memory_key="chat_history", # 在 prompt 中使用的变量名
return_messages=False, # 返回字符串格式,适合字符串模板
)
return memory5、Retrieval
实现RAG(检索增强生成),让Agent具备查阅文档的能力,可以基于实际的文档内容回答问题,使AI应用从"猜答案"变为"查资料+回答":
- 检索:从知识库中找到与用户查询最相关的文档片段
- 增强:将检索结果与查询结合,构建增强提示
- 生成 :
LLM基于增强提示生成准确回答
py
def demo_rag_with_vectorstore(vectorstore): # 演示结合向量存储的 RAG 模块
api_key = os.getenv("DASHSCOPE_API_KEY")
llm = ChatOpenAI(
model="qwen-plus",
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.7,
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 2}) # 创建检索器
# 自定义提示词模板
prompt_template = """基于以下上下文信息回答问题。如果上下文中没有相关信息,请说明无法从提供的文档中找到答案。
上下文:
{context}
问题:{question}
请用中文回答:"""
PROMPT = PromptTemplate( # 创建提示词模板
template=prompt_template, input_variables=["context", "question"]
)
test_question = "LangChain 有哪些核心概念?"
docs = retriever.get_relevant_documents(test_question) # 检索相关文档
context = "\n\n".join([doc.page_content for doc in docs]) # 构建上下文
prompt = PROMPT.format(context=context, question=test_question)
response = llm.invoke(prompt)
print(f"\n ✓ 答案生成成功:")
print(f" {response.content if hasattr(response, 'content') else str(response)}")
print(f"\n 参考文档来源:")
for i, doc in enumerate(docs, 1):
source = os.path.basename(doc.metadata.get("source", "未知"))
print(f" [{i}] {source}")
print()6、Document processing
从文档中自动提取、理解、分类和处理信息,将非结构化文档转换为可搜索、可分析、可集成的结构化数据:
- 文档加载 :从各种来源加载文档(
PDF、图像、扫描件) OCR引擎:识别文档中的印刷体和手写文本NLP模型:理解文档内容并提取关键信息- 分类:识别文档类型并进行分类
- 数据输出:将提取出的信息导出到数据库、系统或工作流
py
def demo_document_processing(): # 演示文档处理模块
# 创建示例文档
sample_docs = [
{
"filename": os.path.join(DOCUMENTS_DIR, "langchain_intro.txt"),
"content": """LangChain 简介
LangChain 是一个用于构建 LLM 应用的框架。
核心概念:
1. Chains(链):将多个组件连接起来
2. Agents(代理):能够自主决策和执行任务
3. Memory(记忆):维护对话历史
4. Tools(工具):扩展 LLM 的能力
5. Document Processing(文档处理):加载和预处理文档
6. Vector Stores(向量存储):存储和检索文档向量
主要功能:
- 文档加载和预处理
- 向量数据库集成
- 检索增强生成(RAG)
- 工具调用和 Agent 构建
使用场景:
- 构建智能问答系统
- 文档检索和分析
- 自动化任务处理
- 知识库构建
""",
},
{
"filename": os.path.join(DOCUMENTS_DIR, "python_basics.txt"),
"content": """Python 基础语法
Python 是一种高级编程语言,具有简洁明了的语法。
变量和数据类型:
- 整数:x = 10
- 浮点数:y = 3.14
- 字符串:name = "Python"
- 列表:numbers = [1, 2, 3]
控制流:
- if/else 语句用于条件判断
- for 循环用于遍历序列
- while 循环用于重复执行
函数定义:
def greet(name):
return f"Hello, {name}!"
Python 的特点:
- 语法简洁,易于学习
- 丰富的标准库和第三方库
- 跨平台支持
- 广泛用于 Web 开发、数据科学、人工智能等领域""",
},
]
os.makedirs(DOCUMENTS_DIR, exist_ok=True) # 确保文档目录存在
documents = []
for doc_info in sample_docs:
filepath = doc_info["filename"]
os.makedirs(os.path.dirname(filepath), exist_ok=True)
with open(filepath, "w", encoding="utf-8") as f: # 写入文档内容
f.write(doc_info["content"])
loader = TextLoader(filepath, encoding="utf-8") # 使用 TextLoader 加载文档
loaded_docs = loader.load() # 加载文档
documents.extend(loaded_docs) # 将加载的文档添加到 documents 列表中
# 在循环外部创建文本分割器并分割文档
text_splitter = (
RecursiveCharacterTextSplitter( # 使用 RecursiveCharacterTextSplitter 分割文档
chunk_size=200, # 每个片段的最大字符数
chunk_overlap=50, # 片段之间的重叠字符数
length_function=len,
)
)
splits = text_splitter.split_documents(documents) # 分割文档
return splits # 返回分割后的文档片段7、Vector Stores
用于连接语言模型与实际应用数据的关键桥梁,存储和检索文本的嵌入向量,为实现语义搜索和RAG(检索增强生成)系统提供基础支持:
- 存储嵌入向量:将非结构文本转换为数值向量并存储
- 高效语义搜索:基于向量相似度而非关键词匹配进行搜索
- 为
RAG提供检索能力 :通过vectorstore.as_retriever()方法将向量存储转换为检索器 - 提供统一
API接口 :轻松切换不同的向量数据库(FAISS、Chroma、Pinecone)
py
def demo_vector_stores(splits, embeddings): # 演示向量存储模块
vectorstore = Chroma.from_documents( # 创建向量数据库
documents=splits,
embedding=embeddings,
persist_directory=CHROMA_DB_DIR, # 持久化目录
)
test_queries = [
"LangChain 有哪些核心概念?",
"Python 的基本数据类型有哪些?",
"文档处理的作用是什么?",
]
for query in test_queries:
print(f" 查询: {query}")
results = vectorstore.similarity_search(query, k=2) # 返回最相似的2个片段
print(f" ✓ 检索到 {len(results)} 个相关片段:")
for i, doc in enumerate(results, 1):
source = os.path.basename(doc.metadata.get("source", "未知"))
content_preview = doc.page_content[:80].replace("\n", " ")
print(f" [{i}] 来源: {source}")
print(f" 内容: {content_preview}...")
print()
query = "LangChain 的核心功能"
results_with_scores = vectorstore.similarity_search_with_score(
query, k=2
) # 返回最相似的2个片段及其相似度分数
for i, (doc, score) in enumerate(results_with_scores, 1): # 遍历结果
source = os.path.basename(doc.metadata.get("source", "未知"))
content_preview = doc.page_content[:80].replace("\n", " ")
print(f" [{i}] 相似度分数: {score:.4f}")
print(f" 来源: {source}")
print(f" 内容: {content_preview}...")
print()
return vectorstore总结
本文介绍了LangChain的7个组成部分,并且分别以伪代码的形式展示出相关demo,希望能对你有所帮助!!!!