背景
由于备件编号文件是多个工序人员手动登记录入,而数据库没做重复校验,导致很多库存品的项目内容其实是重复的,会有重复购买,备件冗余等情况。使用python,读取 Excel 中的库存描述数据,通过字符串相似度算法找出每条记录最相似的前 3 条记录,最终将结果整理后重新保存到原 Excel 文件中,再人工确认内容。
一、代码核心功能
- 字符串相似度计算 :通过
difflib.SequenceMatcher的quick_ratio()方法计算两个字符串的相似度,转换为百分比并保留 2 位小数。 - Excel 读写与格式化 :读取
inventory data.xlsx的 Sheet1 数据,处理完成后将结果写回原文件,同时自动调整 Excel 列宽以适配内容。 - 相似记录筛选:对每条记录,遍历后续所有记录计算相似度,筛选出相似度最高的前 3 条,记录其相似度、行号、内容和 SID。
- 多进程并行处理 :使用
multiprocessing.Pool创建进程池,拆分数据任务进行并行处理,尝试提升大批量数据的处理效率。 - 进度可视化 :使用
tqdm创建进度条,展示进程处理进度和文件保存前的结果汇总进度。
二、代码
-
Excel 格式优化 :
saveexcel函数中自动检测日期类型列并转换为字符串,同时计算每列内容的最大长度(包含列名),自动调整 Excel 列宽(+4 预留缓冲),避免导出的 Excel 出现内容被遮挡的问题。 -
字符串相似度计算 :封装
string_similar函数,利用difflib内置的quick_ratio()方法快速计算相似度,兼顾简洁性和计算效率,适合批量字符串对比场景。 -
任务拆分 :动态设置进程池大小:自动适配 CPU 核心数,避免资源浪费。每个子进程仅接收拆分后的子数据(而非完整
DataFrame),使用iloc提取视图、values获取数组,提升遍历效率,处理完成后返回子结果DataFrame,最后在主进程汇总,使用numpy.argpartition快速提取前 N 大值,替代完整排序,大幅提升大数据量处理速度。。 -
多进程兼容性处理 :添加
mp.freeze_support(),解决 Windows 环境下使用multiprocessing打包或运行时可能出现的初始化错误,提升了代码的跨平台兼容性。import datetime
import difflib
import math
import multiprocessing as mp
import numpy as np
import pandas as pd
from pandas import read_excel
from tqdm import tqdm===================== 配置参数(可根据需求修改) =====================
EXCEL_INPUT_PATH = r"inventory data0.xlsx"
EXCEL_OUTPUT_PATH = r"inventory data0_result.xlsx" # 输出新文件,避免覆盖原数据
SHEET_NAME = "Sheet1"
ROWS_PER_PROCESS = 10 # 每个进程处理的批次大小(比原5条更高效)
TOP_SIMILAR_COUNT = 3 # 保留最相似的前N条记录
PROCESS_POOL_SIZE = None # 自动适配CPU核心数,手动设置可改为具体数字(如4、8)===================== 核心工具函数 =====================
def string_similar(s1, s2):
"""计算两个字符串的相似度(百分比,保留2位小数)"""
if not isinstance(s1, str) or not isinstance(s2, str):
return 0.00
return round(difflib.SequenceMatcher(None, s1, s2).quick_ratio() * 100, 2)def saveexcel(data, filename, sheetName, data2='', sheet2=''):
"""优化后的Excel保存函数,自动调整列宽,兼容日期类型"""
# 复制数据避免修改原数据
data_copy = data.copy()# 日期类型转换为字符串,避免Excel格式异常 for idx, col in enumerate(data_copy): if data_copy[col].dtypes == 'datetime64[ns]': data_copy[col] = data_copy[col].astype(str) # 初始化Excel写入器 try: writer = pd.ExcelWriter(filename, engine='xlsxwriter') except Exception as e: raise Exception(f"初始化Excel写入器失败:{str(e)}") # 写入第一个Sheet并调整列宽 data_copy.to_excel(writer, sheet_name=sheetName, index=None) worksheet = writer.sheets[sheetName] for idx, col in enumerate(data_copy): series = data_copy[col] # 计算列宽(内容最大长度 + 列名长度 + 4缓冲) max_len = max( series.astype(str).map(len).max() if not series.empty else 0, len(str(series.name)) ) + 4 worksheet.set_column(idx, idx, max_len) # 写入第二个Sheet(可选) if sheet2 != "" and not isinstance(data2, str) and not data2.empty: data2_copy = data2.copy() for idx, col in enumerate(data2_copy): if data2_copy[col].dtypes == 'datetime64[ns]': data2_copy[col] = data2_copy[col].astype(str) data2_copy.to_excel(writer, sheet_name=sheet2, index=None) worksheet2 = writer.sheets[sheet2] for idx, col in enumerate(data2_copy): series = data2_copy[col] max_len = max( series.astype(str).map(len).max() if not series.empty else 0, len(str(series.name)) ) + 4 worksheet2.set_column(idx, idx, max_len) # 保存文件 try: writer.close() except Exception as e: raise Exception(f"保存Excel文件失败:{str(e)}")===================== 多进程处理函数 =====================
def proceed(threadNo, full_data, start, end):
"""
单个进程的处理逻辑:计算指定区间内每条记录的前N条相似记录
优化点:避免数据完整拷贝,仅处理指定区间,返回处理后的子DataFrame
"""
# 修正边界,防止超出数据长度
end = min(end, len(full_data))
if start >= end:
return pd.DataFrame()# 提取当前进程需要处理的子数据(视图,非完整拷贝) sub_data = full_data.iloc[start:end].copy() full_desc = full_data['Long Description'].values full_sid = full_data['STOCK # \nSID#'].values total_rows = len(full_data) # 为子数据添加结果列 for i in range(1, TOP_SIMILAR_COUNT + 1): sub_data[f'top{i}-rate'] = 0.00 sub_data[f'top{i}-cell'] = 0 sub_data[f'top{i}-data'] = "" sub_data[f'top{i}-SID'] = "" # 遍历当前进程的每条记录 for sub_idx, orig_idx in enumerate(range(start, end)): # 存储当前记录与其他所有记录的相似度 similarity_list = [] # 遍历所有后续记录(避免重复计算) for j in range(orig_idx + 1, total_rows): sim_score = string_similar(full_desc[orig_idx], full_desc[j]) similarity_list.append([j, sim_score]) # 快速提取前N条最高相似度(使用numpy优化,避免完整排序) if len(similarity_list) > 0: # 转换为numpy数组提升效率 sim_np = np.array(similarity_list, dtype=object) if len(sim_np) >= TOP_SIMILAR_COUNT: # 快速分区提取前N大值,效率高于sorted sim_scores = sim_np[:, 1].astype(float) top_n_indices = np.argpartition(sim_scores, -TOP_SIMILAR_COUNT)[-TOP_SIMILAR_COUNT:] top_n_items = sim_np[top_n_indices] else: top_n_items = sim_np # 对前N条结果排序(从高到低) top_n_sorted = sorted(top_n_items, key=lambda x: float(x[1]), reverse=True) # 填充结果到子数据中 for rank in range(min(len(top_n_sorted), TOP_SIMILAR_COUNT)): j, score = top_n_sorted[rank] j = int(j) score = float(score) col_prefix = f'top{rank + 1}-' sub_data.iloc[sub_idx, sub_data.columns.get_loc(col_prefix + 'rate')] = score sub_data.iloc[sub_idx, sub_data.columns.get_loc(col_prefix + 'cell')] = j + 2 # 对应Excel行号 sub_data.iloc[sub_idx, sub_data.columns.get_loc(col_prefix + 'data')] = full_desc[j] sub_data.iloc[sub_idx, sub_data.columns.get_loc(col_prefix + 'SID')] = full_sid[j] return sub_data===================== 回调函数(进度条更新) =====================
def progress_callback(*args):
"""多进程回调函数,用于更新进度条"""
global pbar
if pbar is not None:
pbar.update(1)===================== 主程序入口 =====================
if name == 'main':
# 初始化多进程兼容(Windows环境必备)
mp.freeze_support()
pbar = None # 全局进度条变量try: # 1. 读取Excel数据并做合法性校验 print(f"[{datetime.datetime.now()}] 开始读取Excel文件:{EXCEL_INPUT_PATH}") try: Rawdata0 = read_excel( EXCEL_INPUT_PATH, sheet_name=SHEET_NAME, header=0, keep_default_na=False ) except FileNotFoundError: raise Exception(f"Excel文件未找到,请确认路径正确:{EXCEL_INPUT_PATH}") except KeyError: raise Exception(f"指定Sheet不存在,请确认Sheet名称:{SHEET_NAME}") except Exception as e: raise Exception(f"读取Excel失败:{str(e)}") # 校验必要列是否存在 required_columns = ["Long Description", "STOCK # \nSID#", "NO"] missing_columns = [col for col in required_columns if col not in Rawdata0.columns] if missing_columns: raise Exception(f"Excel缺失必要列:{', '.join(missing_columns)}") print(f"[{datetime.datetime.now()}] 数据读取成功,总条数:{len(Rawdata0)}") # 2. 初始化多进程参数 total_rows = len(Rawdata0) # 计算任务数(按每个进程处理ROWS_PER_PROCESS条数据拆分) task_count = math.ceil(total_rows / ROWS_PER_PROCESS) # 自动设置进程池大小(不超过CPU核心数和任务数) if PROCESS_POOL_SIZE is None: cpu_core_count = mp.cpu_count() pool_size = min(cpu_core_count, task_count) else: pool_size = min(PROCESS_POOL_SIZE, task_count) print(f"[{datetime.datetime.now()}] 初始化进程池,进程数:{pool_size},任务数:{task_count}") # 3. 启动多进程处理 pool = mp.Pool(processes=pool_size) pbar = tqdm(total=task_count, desc='多进程处理进度') job_list = [] for task_id in range(1, task_count + 1): start_idx = (task_id - 1) * ROWS_PER_PROCESS end_idx = task_id * ROWS_PER_PROCESS # 提交异步任务,绑定回调函数更新进度条 job = pool.apply_async( func=proceed, args=(task_id, Rawdata0, start_idx, end_idx), callback=progress_callback ) job_list.append(job) # 等待所有进程完成 pool.close() pool.join() pbar.close() print(f"[{datetime.datetime.now()}] 所有多进程任务处理完成") # 4. 汇总所有进程的结果 print(f"[{datetime.datetime.now()}] 开始汇总处理结果") result_list = [] tbar = tqdm(job_list, desc="结果汇总进度") for job in tbar: sub_result = job.get() if not sub_result.empty: result_list.append(sub_result) tbar.close() # 拼接所有子结果 if not result_list: raise Exception("未获取到任何处理结果,数据可能为空") final_result = pd.concat(result_list, ignore_index=True) # 5. 按NO列排序,保持数据原有顺序 final_result = final_result.sort_values(by="NO", ascending=True, ignore_index=True) # 6. 保存结果到新Excel文件 print(f"[{datetime.datetime.now()}] 开始保存结果到Excel:{EXCEL_OUTPUT_PATH}") saveexcel(final_result, EXCEL_OUTPUT_PATH, SHEET_NAME) print(f"[{datetime.datetime.now()}] 全部流程完成!结果已保存至:{EXCEL_OUTPUT_PATH}") except Exception as e: print(f"[{datetime.datetime.now()}] 程序运行出错:{str(e)}")
三、运行说明
- 确保已安装依赖库:
pip install pandas xlsxwriter tqdm numpy - 将原 Excel 文件命名为
inventory data0.xlsx,与代码放在同一目录(或修改EXCEL_INPUT_PATH配置绝对路径) - Excel 中必须包含
Long Description、STOCK # \nSID#、NO三列(与原代码要求一致) - 运行后,结果会保存为
inventory data_result.xlsx,不会修改原文件 - 大批量数据(如 1000 + 条)可适当调大
ROWS_PER_PROCESS(如 20、50),提升处理效率
四、结果确认

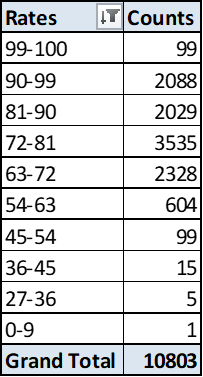
10803条中,重复度大于99%的数据有99条,经复核确实是重复建立了。90-99的也有部分重复。