代码在自己的一个关于多模态大模型与Multi Agent的开源小项目 中,如果喜欢可以点个star~ https://github.com/xi029/Qwen3-VL-MoeLORA![]() https://github.com/xi029/Qwen3-VL-MoeLORA
https://github.com/xi029/Qwen3-VL-MoeLORA
上一篇那个MOELoRA的博客:MOELoRA
后来在一篇文章介绍大模型中MOE(混合专家)与MOT(混合 Token)方法的对比,我就去找 MOT 论文(论文链接在文末致谢)觉得可以把"跨样本混合 Token" 用到LoRA里顺便比较一下我写的MOELoRA和MOTLoRA哪个更厉害。
关于MOT论文里提到的token混合简单来说就是不用搞离散的专家选择(离散 MoE 的 Token 路由易导致训练不稳定、Token 丢弃),而是让 Token 连续混合后再经过专家处理,既避免了 MOE 的专家闲置问题,又能增强序列建模能力。 MOTLoRA就是把 Token 混合模块和 LoRA 增量结合起来,将MOT接在lora之后。
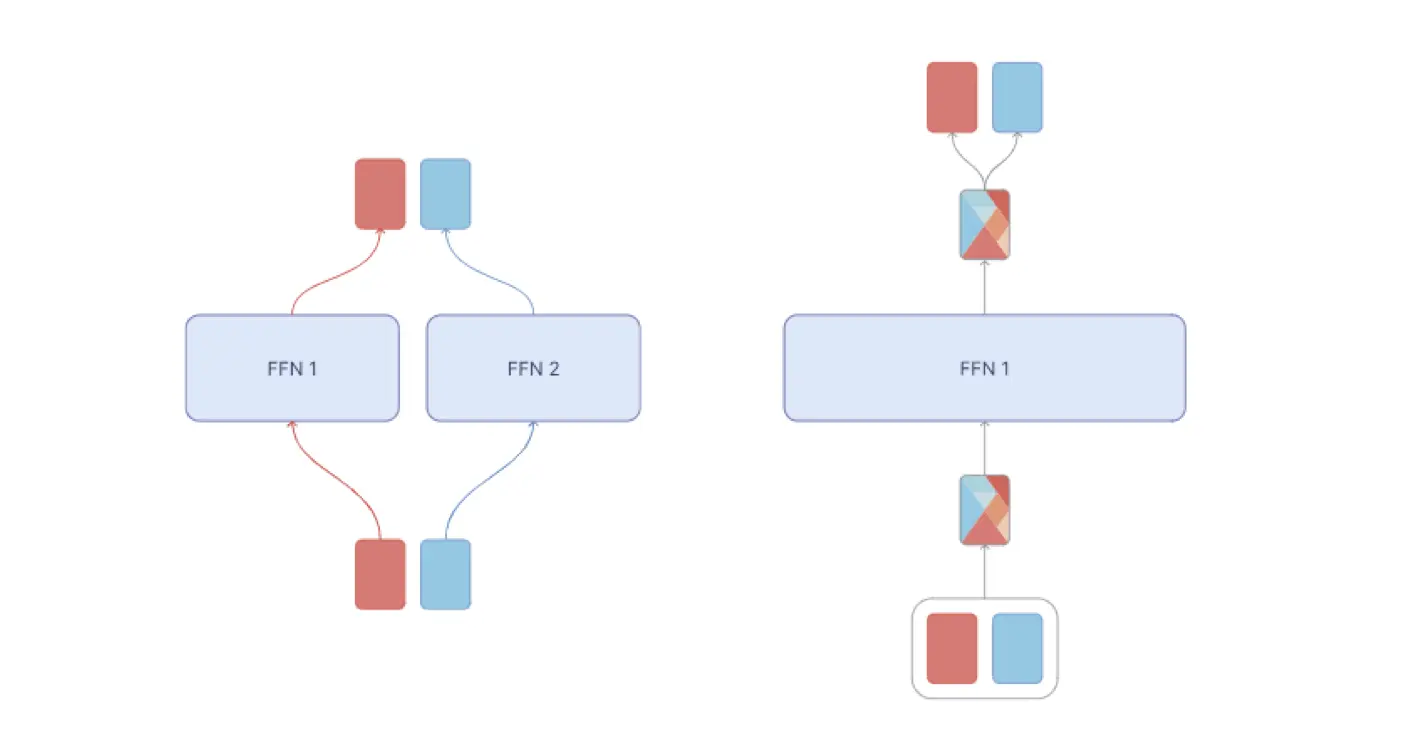
专家混合模型 ( MoE) 与Token混合模型 (MoT):在专家混合模型(左图)中,每个token都被路由到不同的专家前馈层。在tokem混合模型(右图)中,每个组内的token被混合,混合后的token由专家前馈层处理。
一、从 LoRA 到 MOE,再到 MOT
在切入 MOTLoRA 之前,我们先梳理下相关技术的核心方法与优缺点,理解 MOT 为什么能加入到LoRA中 :
1. LoRA:参数高效
LoRA 的核心是为预训练模型的注意力层(q/k/v/o_proj)新增低秩矩阵(A×B),冻结主干模型仅训练低秩参数,将微调参数量降至百万级。但 LoRA 本质是 "单一路径" 的适配,对于多模态这种图文特征高度耦合的任务,单一低秩矩阵难以捕捉复杂的模态交互模式(带入论文讲故事的思路了,不应该带这么大的帽子的,在业界普通LoRA已经很强了这里只是为了"提出问题"->"解决方法")。
2. MOE:多专家分工但存在一定固有缺陷
混合专家(MOE)通过 "路由 + 多专家" 机制让不同专家处理不同 Token,提升模型拟合能力,但存在问题:
**训练不稳定性:**该方法以离散的方式选择专家并将其与令牌进行匹配。这意味着控制器权重的微小变化可能会对控制器的决策产生不成比例的影响。
3. MOT:Token 级连续混合训练稳定
MOT(Mixed Token)是近年提出的改进型专家机制,核心思想是跨样本 Token 分组 + 连续门控混合,相比最初的MOE(注意不是DeepSeekv3的MOE) 做了两个关键优化:
- 摒弃离散 Top-k 路由,改用连续门控权重混合 Token,避免专家闲置;允许模型从所有标记-专家组合中学习,从而提高训练稳定性和专家利用率。
- 按序列位置跨样本分组(而非单样本内分组),既保证 Token 多样性,又避免同样本 Token 混合导致的信息泄露;
- MOT是一个完全可微的方法,这意味着它可以使用标准的基于梯度的方法进行训练。这避免了使用辅助损失或其他难以训练的技术,从而简化了训练和部署过程。
二、MOTLoRA 的核心实现(基于 Qwen3-VL)
MOTLoRA核心原理可概括为:以 LoRA 低秩矩阵(A×B)为基础增量路径,新增跨样本 Token 混合与轻量专家网络,既避免 MOE 离散路由的负载不均衡问题,又突破单路径 LoRA 的表达局限。
MOTLoRA 先按序列位置对跨样本 Token 分组(如不同样本的第 n 个 Token 归为一组),避免同序列 Token 混合导致的信息泄露;再通过门控网络学习每组内 Token 的连续混合权重,生成 Token 混合物后输入双专家 MLP、;专家输出按门控权重连续聚合(无离散 Top-k 选择),形成 MOT 增量,与 LoRA 增量叠加后融入预训练模型输出。整个过程无需额外负载均衡损失项,仅通过主任务梯度优化混合权重与专家参数。
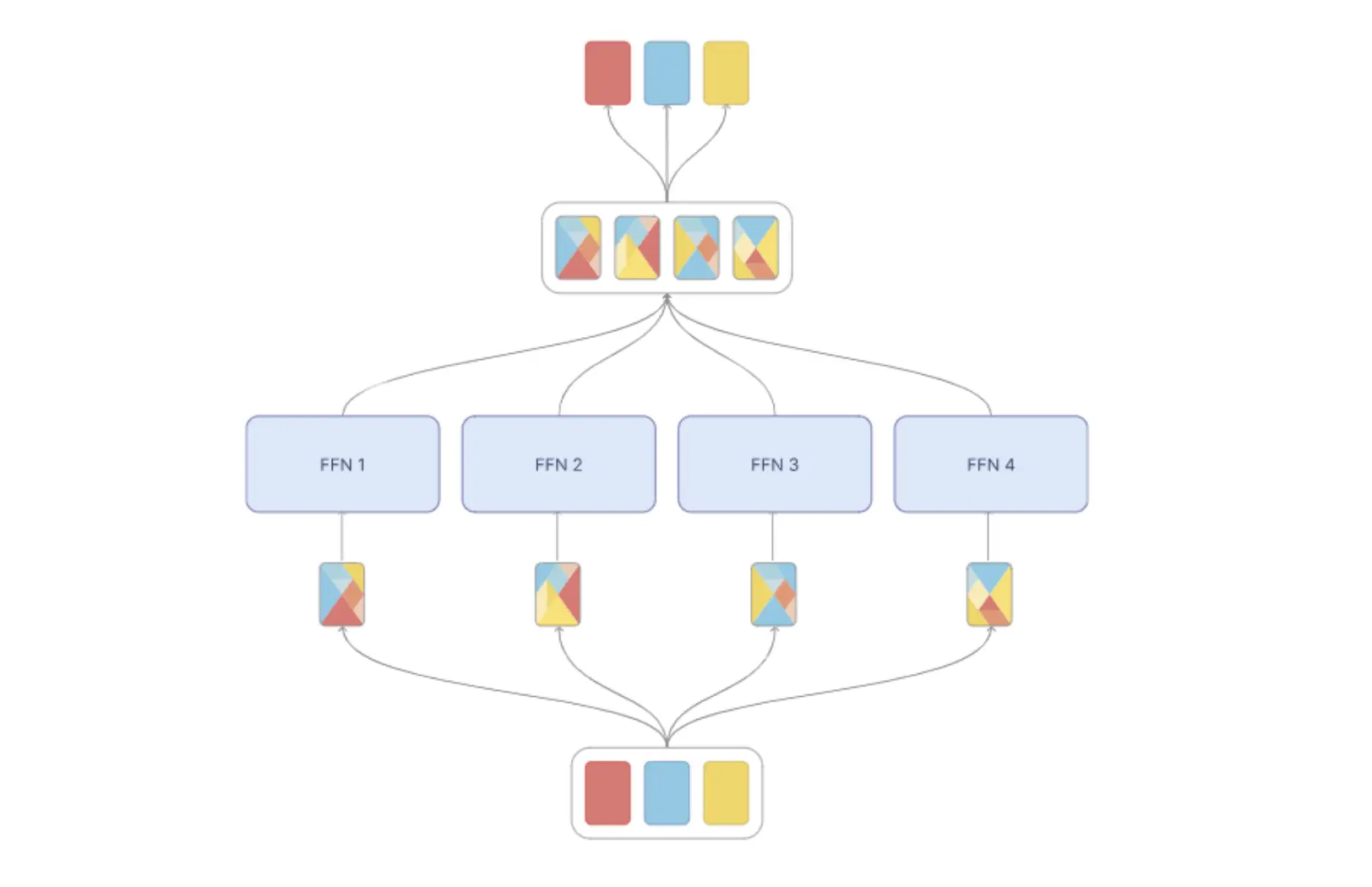
令牌混合*:*每个专家的token都是唯一混合的(混合权重由控制器决定和学习,为简单起见,此处省略),然后对每个混合物进行处理,并将其重新分配回原始令牌(使用与之前相同的权重)。
1. 配置类:MOT 专属参数定义
首先通过MotLoraConfig扩展 LoRA 配置,新增 MOT 核心参数:
python
@dataclass
class MotLoraConfig(LoraConfig):
group_size: int = field(default=8, metadata={"help": "跨样本Token分组大小,默认等于梯度累积后的有效batch size"})
gate_dropout: float = field(default=0.1, metadata={"help": "门控权重的dropout概率"})
num_experts: int = field(default=2, metadata={"help": "固定专家数量为2"})
# 重写属性:标识非prompt learning(PEFT库内部判断用)
@property
def is_prompt_learning(self):
return False
@property
def is_adaption_prompt(self):
return Falsegroup_size:跨样本分组大小,本文设为 8(与梯度累积后的有效 batch size 一致),保证每组有足够的 Token 多样性;num_experts:固定为 2,平衡拟合能力与显存开销;gate_dropout:门控权重的 dropout,防止门控网络过拟合。
2. 核心层 MotLoraLayer:LoRA+MOT 的融合
MotLoraLayer继承自 PEFT 的LoraLayer,在保留 LoRA 基础逻辑的同时,新增 MOT 的混合专家机制,其前向传播流程是核心:
python
class MotLoraLayer(LoraLayer):
def __init__(self, base_layer, config: MotLoraConfig):
super().__init__(base_layer, config)
# 1. 保留LoRA基础参数
self.in_features = base_layer.in_features
self.out_features = base_layer.out_features
self.r = config.r
self.scaling = config.lora_alpha / config.r
self.dropout = nn.Dropout(config.lora_dropout)
self.adapter_A = nn.Linear(self.in_features, self.r, bias=False)
self.adapter_B = nn.Linear(self.r, self.out_features, bias=False)
# 2. MOT核心:门控控制器+双专家网络
self.num_experts = config.num_experts
self.group_size = config.group_size
self.gate_dropout = nn.Dropout(config.gate_dropout)
self.gate = nn.Linear(self.in_features, self.group_size) # 门控:预测Token混合权重
self.experts = nn.ModuleList([ # 双专家(MLP结构)
nn.Sequential(
nn.Linear(self.in_features, self.in_features * 2),
nn.GELU(),
nn.Linear(self.in_features * 2, self.out_features)
) for _ in range(self.num_experts)
])
def forward(self, x):
# 步骤1:原预训练层输出(冻结)
base_out = self.base_layer(x)
if self.merged or self.disable_adapters:
return base_out
# 步骤2:基础LoRA增量(保留原有逻辑)
lora_delta = self.adapter_B(self.dropout(self.adapter_A(x))) * self.scaling
# 步骤3:MOT核心------跨样本Token分组
batch_size, seq_len, hidden_dim = x.shape
grouped_x = x.permute(1, 0, 2) # (seq_len, batch_size, hidden_dim):按序列位置分组
# 步骤4:门控预测混合权重(连续归一化,无离散路由)
gate_logits = self.gate(grouped_x)
gate_weights = torch.softmax(gate_logits, dim=-1) # 组内权重归一化
gate_weights = self.gate_dropout(gate_weights) # 防止门控过拟合
# 步骤5:生成Token混合物(组内Token × 门控权重)
mixtures = torch.einsum("s g g, s g d -> s g d", gate_weights.unsqueeze(-1), grouped_x)
# 步骤6:双专家处理混合物(所有专家处理全部混合Token)
expert_outputs = []
for expert in self.experts:
expert_out = expert(mixtures)
expert_outputs.append(expert_out)
# 步骤7:连续聚合专家输出(无Top-k,权重加权求和)
mot_delta = 0.0
for expert_out in expert_outputs:
weighted_out = expert_out * gate_weights.unsqueeze(-1)
mot_delta += weighted_out
# 步骤8:恢复维度+缩放,与LoRA增量融合
mot_delta = mot_delta.permute(1, 0, 2) # 恢复(batch_size, seq_len, hidden_dim)
mot_delta = mot_delta * (self.scaling / self.num_experts) # 平衡LoRA与MOT的贡献
# 最终输出:原模型输出 + LoRA增量 + MOT增量
total_out = base_out + lora_delta + mot_delta
return total_out上述代码的核心设计可总结为 4 个关键点:
(1)跨样本分组,避免信息泄露
将输入张量从(batch_size, seq_len, hidden_dim)转为(seq_len, batch_size, hidden_dim),即按序列位置分组------ 每组包含所有样本的同一位置 Token(如第 10 个位置的 Token 组成一组)。这种方式避免了同一样本内 Token 混合导致的 "信息泄露"(比如 caption 生成中,后续 Token 提前看到前面的 Token),同时保证每组 Token 的多样性。
(2)连续门控,无离散路由
门控网络self.gate预测每个 Token 对组内其他 Token 的混合权重,通过softmax归一化后得到连续权重(而非 MOE 的离散 Top-k 选择)。所有专家都会处理混合后的 Token,不存在专家闲置问题,负载天然均衡。
(3)双专家 MLP,轻量化设计
专家网络采用 "线性层 + GELU + 线性层" 的轻量化 MLP 结构,且仅设置 2 个专家,相比 MOE 的多专家设计,显存开销几乎可忽略(结合 4-bit 量化后,8G 显存可轻松承载)。
(4)增量融合,兼容 LoRA
MOT 增量与 LoRA 增量独立计算后叠加到原模型输出上,既保留了 LoRA 的参数高效性,又通过 MOT 提升了拟合能力,且可通过scaling系数平衡两者的贡献。
3. 进行Qwen3-VL 的多模态微调
为让 MOTLoRA 适配 Qwen3-VL 的多模态任务,我们还做了以下工程优化(结合代码):
(1)NF4双量化,降低显存门槛
通过 BitsAndBytesConfig 启用 4-bit NF4 双量化,将 Qwen3-VL-4B 的显存占用降至 8G 以内:
python
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)(2)多模态数据预处理
针对 Qwen3-VL 的图文输入格式,设计process_func函数,将图片路径转为pixel_values,并构建自回归训练的序列(指令部分设为 - 100 不计算损失,仅输出部分计算):
python
# 构建labels:指令部分设为-100(不计算损失),仅输出部分计算损失
labels = (
[-100] * len(instruction["input_ids"][0])
+ response["input_ids"]
+ [tokenizer.pad_token_id]
)(3)训练与推理适配
训练时禁用模型缓存、启用梯度检查点进一步降低显存;推理时设置inference_mode=True,禁用 dropout 保证结果稳定:
python
val_config = MotLoraConfig(
inference_mode=True, # 推理模式:禁用dropout,固定参数
# 其他配置与训练一致
)三、MOT vs MOE:核心差异
| 维度 | MOE(传统混合专家) | MOT(混合 Token) |
|---|---|---|
| 路由机制 | 离散 Top-k 路由(Token 分配给固定专家) | 连续门控混合(所有专家处理混合 Token) |
| 专家负载 | 易不均衡(部分专家闲置) | 天然均衡(无专家闲置) |
| 计算开销 | 随专家数线性增加 | 固定 2 个专家,开销可控 |
| 显存占用 | 高(多专家 + 路由网络) | 低(双专家 + LoRA 轻量化) |
| 适配场景 | 大模型分布式训练(多卡 / 多机) | 单卡小显存微调(8G/16G 显存) |
| 信息泄露风险 | 单样本内分组,风险较高 | 跨样本按位置分组,风险低 |
从对比可看出,MOT 是 MOE 的 "轻量化适配版"------ 牺牲了部分极致拟合能力,但大幅降低了计算和显存开销,完美适配单卡微调场景;而 MOE 更适合千亿级大模型的分布式训练,通过多专家提升模型上限。
四、实验效果
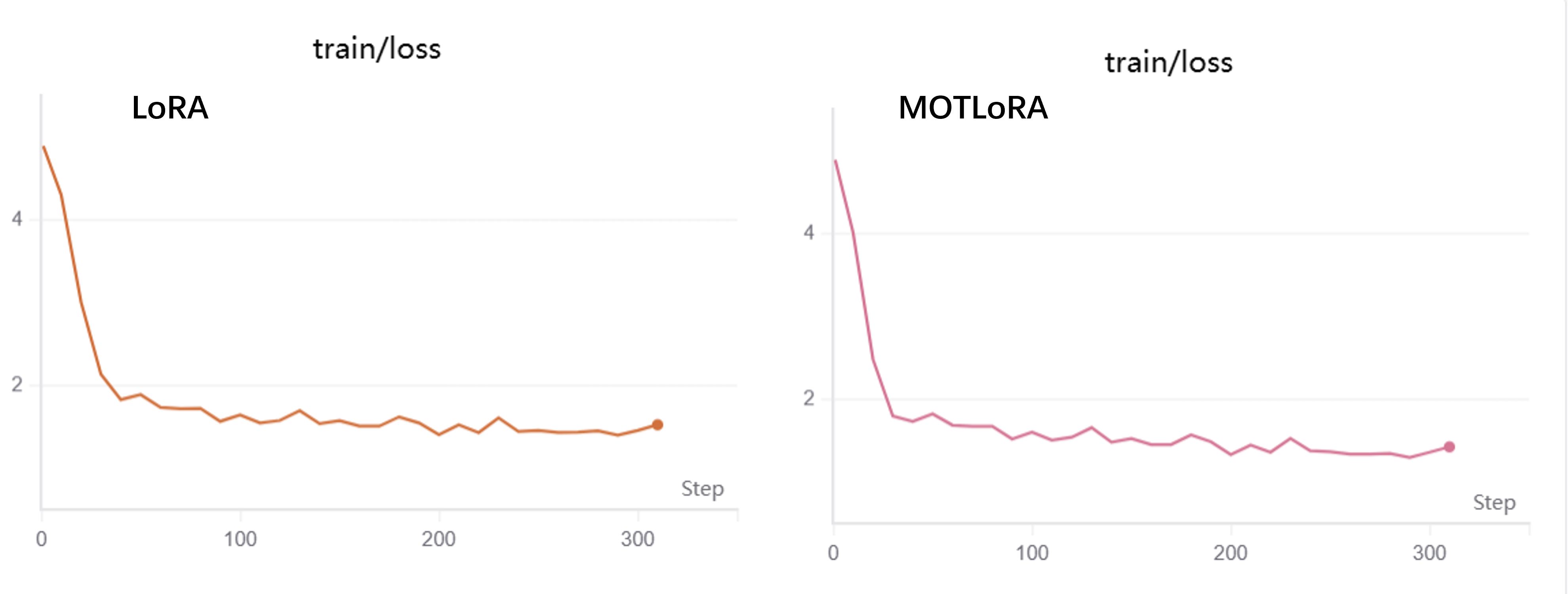
在Qwen3-vl-4B的微调实验中普通LoRA损失为1.3971 ,而我设计的MOELoRA的损失为1.2944(略微小于MOELoRA的1.2964) ,有所提升,Win!
五、总结
MOTLoRA 通过将 MOT 的 Token 混合思想与 LoRA 结合,既保留了 LoRA 的参数高效性,又通过连续混合的双专家网络提升了多模态任务的适配能力,是单卡小显存场景下多模态大模型微调的优秀方案。MOTLoRA 的核心代码已开源,可直接适配 Qwen3-VL、LLaVA 等多模态模型,希望能为多模态大模型的轻量化微调提供新的思路。