在HuggingFace的模型页面,点击Chat template选项:
会看到下图这样的内容:
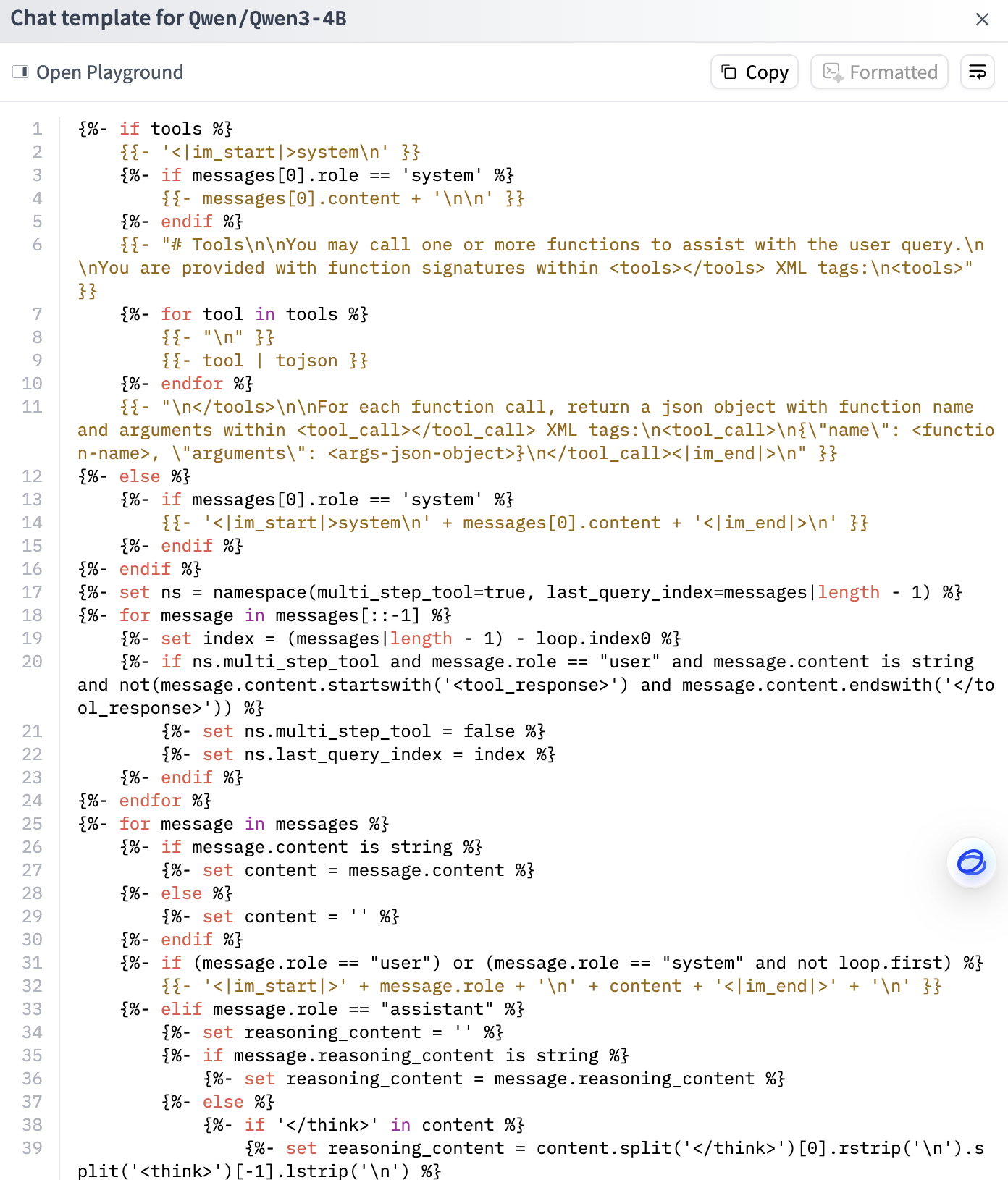
我第一次看到这样的写法时,完全不知道这是什么语言------既不像 Python,也不像 HTML。
查阅了一圈资料之后我才了解到:这里使用的是Jinja语法。Jinja 在大模型时代承担了一个重要角色------把结构化对话"编译"为模型真正看到的文本。这篇文章就从这个角度出发,把 Jinja 是什么、从哪儿来,以及它为什么会出现在 LLM 生态里,系统地梳理一遍。
Jinja 是什么?
Jinja(发音类似"金加",代表日语中"神社"的意思)是一个模板引擎(template engine),最早为 Python Web 框架(尤其是 Flask)设计。它解决的核心问题很简单:
如何把一份结构化数据,稳定、可控地填充进一段文本结构中。
最简单的例子:
jinja
Hello, {{ name }}!如果 name = "Alice",渲染结果就是:
Hello, Alice!Jinja 的威力不在于"变量替换",而在于它支持受限的控制结构:条件、循环、过滤器等。
jinja
<ul>
{% for item in items %}
<li>{{ item | upper }}</li>
{% endfor %}
</ul>当 items = ["apple", "banana"] 时,输出为:
html
<ul>
<li>APPLE</li>
<li>BANANA</li>
</ul>它看起来像代码,但并不是通用编程语言:
- 没有自由的 import
- 没有 I/O
- 没有任意副作用
你可以把它理解为一种:"用于描述文本拼接规则的 DSL(领域专用语言)"。
Jinja 从哪儿来?
Jinja 最早由 Armin Ronacher 在 2006 年左右开发。2008 年他对其进行了彻底重写 ,并命名为 Jinja2。此后,早期的 Jinja 版本逐步被弃用。
本文后文中提到的 Jinja,均指 Jinja2。
Jinja2 的设计深受 Django 模板系统影响,但在表达力和扩展性上更强,也更偏向"工程工具"而不是"展示模板"。
在前后端尚未分离的 Web 时代,服务器需要动态生成 HTML 页面返回给浏览器,于是就需要一种:
"HTML 为骨架,数据由后端注入"的机制。
Jinja 正是为此而生。
python
from flask import render_template
return render_template("profile.html", username="Bob")
jinja
<h1>Welcome, {{ username }}!</h1>随着 React / Vue 等前端框架兴起,服务器端模板逐渐淡出主流视野,但 Jinja 本身并没有消失,而是作为一个成熟、稳定的文本模板工具,被保留在了 Python 生态中。
为什么大模型要用 Jinja?
进入大模型时代后,一个新的工程问题出现了:如何把"多轮对话"转换成模型真正接受的那一串 token?
用户看到的是:
json
{
{"user":"你好!"},
{"assistant":"你好呀!"}
}模型看到的却可能是:
<|user|>你好!<|assistant|>你好呀!而且,不同模型的输入格式完全不同:
- LLaMA 系列:
[INST] ... [/INST] - Mistral:
<s>[INST] ... [/INST] - ChatGLM:
[Round 1]\n问:...\n答:... - ChatML:
<|im_start|>user\n你好!\n<|im_end|>\n<|im_start|>assistant\n你好呀!\n<|im_end|>
为什么不同模型的输入格式不同?
根本原因在于 不同模型的训练数据格式不同,而推理输入格式必须和训练输入格式一致,如果输入格式和训练时不一致,模型可能无法区分角色或出现输出粘连,所以 chat template 必须复刻训练数据的 token 结构
这直接导致一个现实问题: 如果我写一个通用的推理/微调/评测框架,难道要为每个模型手写一套 prompt 拼接逻辑吗?
Hugging Face 给出的解决方案是:聊天模板(Chat Template)。
它的核心思想是:把"对话 → 输入文本"的规则,写成一个 Jinja 模板,并作为模型元数据随 tokenizer 一起发布。
例如(简化后的 LLaMA 风格示例):
jinja
{% for message in messages %}
{% if message.role == 'user' %}
[INST] {{ message.content }} [/INST]
{% elif message.role == 'assistant' %}
{{ message.content }}</s>
{% endif %}
{% endfor %}给定:
python
messages = [
{"role": "user", "content": "你好!"},
{"role": "assistant", "content": "你好呀!"},
{"role": "user", "content": "今天天气怎么样?"}
]渲染后得到:
[INST] 你好! [/INST]你好呀!</s>[INST] 今天天气怎么样? [/INST]这正是模型期望的输入格式。
在实际使用transformers库时,只需调用tokenizer.apply_chat_template(),即可生成模型对应的输入格式文本。
从工程视角看,这一步更像是:把 prompt 构造过程,从代码里"外包"给了一个可配置、可序列化的模板系统。
一个类比
可以这样理解:
- 用户传来的
messages:结构化的中间表示,通常使用json格式区分不同角色 - Jinja chat template:编译规则
- 渲染结果:模型实际接收的 token 流
Jinja 并不是在"生成文本",而是在确定性地编译文本。这一点对于 LLM 推理尤为重要。
谁选择了 Jinja?为什么偏偏是它
Chat Template 并不是自然形成的,而是 Hugging Face Transformers 在 2023 年正式引入的一项设计。
Transformers 要解决的问题是:
"如何让不同模型、不同 prompt 格式,在同一套推理与训练代码中被统一处理?"
他们最终决定:
- Chat Template 作为 tokenizer 的一部分存在
- 模板语言统一使用 Jinja2(事实标准)
这是当时发布的博客原文链接:https://huggingface.co/blog/zh/chat-templates
这并非因为 Jinja"最时髦",而是因为它在工程上刚好满足约束条件。
模型只需要在tokenizer_config中定义以下内容即可使用tokenizer.apply_chat_template()转换输入格式
json
{
"chat_template": "{% for msg in messages %}...{% endfor %}"
}这意味着:
模型作者只需写一次模板,全世界的工具链都能自动适配。
vLLM、TGI、FastChat 等推理框架随后选择了"兼容 Hugging Face",Jinja 也就被放大成了事实标准。
总结
- Jinja 本质是一个文本模板 DSL
- Chat Template 是 prompt 构造规则的配置化与标准化表达;
- 在 LLM 系统中,Jinja 扮演的是一个确定性的 prompt 编译前端。
当你理解了这一点,再看到 {``{ }} 和 {% %},就不再神秘了------它只是把结构化数据,稳定地编译成模型能读懂的 token 序列。
附录A 阅读chat template时的实用建议
阅读模型的 chat template 时,优先问三个问题:
- 模型是如何区分角色的?
- 一轮对话在 token 层面如何结束?
- 这个结构是否和模型的训练数据一致?
附录B 为什么不是其他模板语言?
除了Jinja以外,还存在其他模板语言,为什么最终选择了Jinja呢?下面做一个简要分析:
- Mako:模板几乎等同于 Python,能力过强,安全边界难以控制
- Django Template:表达力偏弱,且生态心智负担更重(虽可独立使用,但并非其主要定位)
- Mustache:逻辑能力不足,无法处理真实对话所需的条件与循环
而 Jinja:
- 表达力刚好够用(for / if / filter)
- 默认无副作用、易沙箱化
- Python 生态极其成熟
- 模板本身就是字符串,可直接放进 JSON 配置