
如果你已经开始深入使用 PDF 内容流解析,迟早会遇到一种非常诡异、但又极其常见的现象:
内容流里能读出字符,但在原 PDF 页面上,你肉眼根本看不见它。
更糟糕的是:
- 这些字符位置、bbox 都"看起来很正常"
- 文本内容也不是乱码
- 排序、布局都没明显问题
- 但你把结果丢给下游 ------污染、错行、拼接异常,全来了
第一次遇到这事的时候,大多数人都会怀疑人生:
- 是我解析错了?
- 是渲染层的问题?
- 还是 PDF 被加密 / 混淆了?
后来你会发现一个很残酷的事实:
PDF 内容流 ≠ 页面最终可见结果
PDF 内容流描述的是:"画了什么" ,而不是:"你最后能看到什么" 。在 PDF 里,"被画出来" 和 "能被看见" ,是两件完全不同的事。而内容流解析,恰恰站在一个比人眼更早、也更诚实的阶段。
第一种情况:字符被后续内容覆盖了
这是最常见、也最容易被忽略的一类。
怎么出现的?
PDF 的绘制顺序是严格线性的:
- 先画的内容
- 后画的内容
- 后画的可以完全覆盖前画的
于是就会出现:
- 内容流里先画了一行文字
- 随后画了一个白色矩形 / 图片 / 底色块
- 文字在视觉上被完全盖住
- 但内容流里,那行文字是真实存在的
典型场景
- 表格背景色块覆盖文字
- 页眉页脚被整页白底遮住
- 扫描件上叠了一层"文本层",但被图片完全挡住
- 某些导出工具先画文字,再画背景

图:文字被后续内容覆盖示例
工程后果
内容流解析会非常"老实"地告诉你:
"这里有一行字。"
而你后面基于这些字做:
- 文本拼接
- 表格结构识别
- 语义分析
就会把根本不可见的内容一起算进去。
工程上的态度
这一类问题,本质上是:
内容流层面无法单独判断"是否被覆盖"。
除非你:
- 引入渲染层
- 或做复杂的绘制顺序 + 覆盖分析
否则在纯内容流路线中,这类字符只能通过后续策略兜底处理,而不是指望一次性判断干净。
第二种情况:字符颜色不可见(或近似不可见)
这是第二大类"幽灵字符"。
常见形式
- 文字颜色 = 白色,背景也是白色
- alpha = 0(完全透明)
- 灰度极浅,肉眼几乎不可见
- 使用了叠加 / 混合模式,结果被吃掉
但在内容流中:
- 字符依然有 fill color
- 依然有字体
- 依然有 bbox
- 完全合法

图:隐藏字符示例
为什么内容流不觉得这是问题?
因为从 PDF 的角度看:
颜色是绘制属性,不是语义属性。
PDF 并不关心"你看不看得见",它只关心"我有没有画"。
工程处理建议
这是少数可以在内容流阶段就过滤掉的情况之一:
- 读取字符的 fill color / stroke color
- 对明显不可见的情况直接丢弃
- alpha = 0
- RGB 全 1 且无背景反差(需谨慎)
- 或作为弱信号,降低该字符的可信度
但要注意一句话:
颜色判断永远是启发式,不是绝对正确。
第三种情况:字符"有位置,但没有尺寸"
这类问题非常隐蔽,但在一些工具导出的 PDF 里并不少见。
表现形式
- 字符 bbox 存在
- 但:
- width ≈ 0
- height ≈ 0
- 或 size = 0
- 或字体矩阵异常,导致几何信息退化
你会看到字符"在那儿",但理论上它是一个没有面积的点
它是怎么来的?
常见来源包括:
- 错误的字体矩阵
- 用字体当"标记"而非真实文本
- 导出工具 bug
- 特殊标注、不可见占位符
工程上的结论
这类字符:
- 几乎不可能对最终阅读有意义
- 但又很容易混入内容流
我的建议是非常直接的:
对 bbox 面积过小、size 异常的字符,直接忽略。
这是一个低风险、高收益的过滤点。
第四种情况:字符位置在 CropBox 之外
这是一个特别容易被忽略,但逻辑非常清晰的问题。
PDF 里有不止一个"页面框"
至少包括:
- MediaBox
- CropBox
- BleedBox
- TrimBox
- ArtBox
而真正决定"你看到什么"的,通常是 CropBox。
问题就出在这
内容流里的字符位置,可能:
- 落在 MediaBox 内
- 但在 CropBox 之外
于是结果就是:
- 内容流能读到字符
- 渲染时被裁掉
- 人眼永远看不见
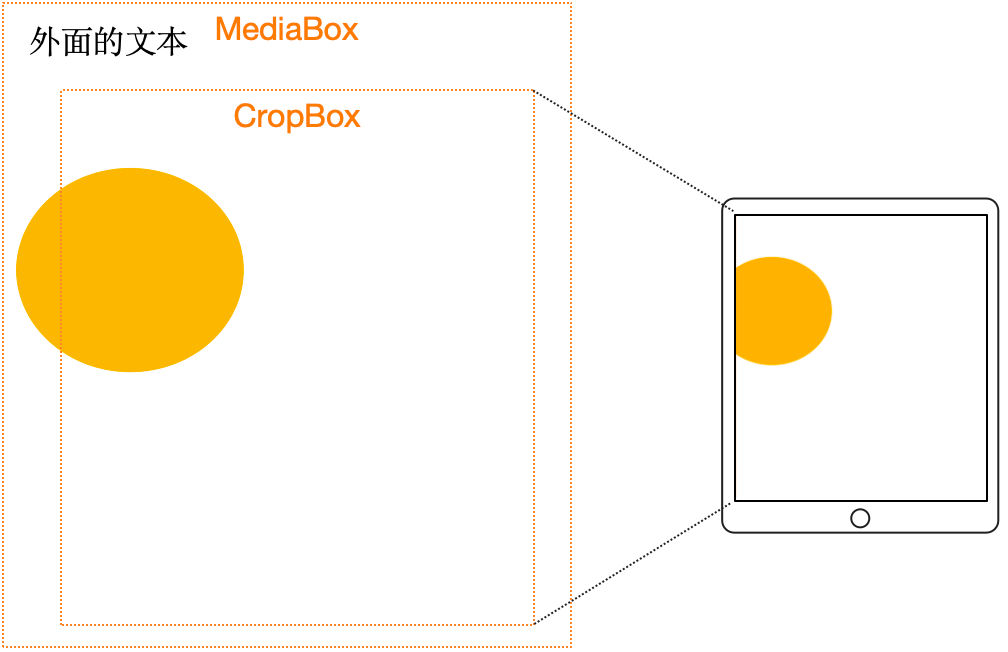
图:文本在CropBox外的示例
工程建议(非常重要)
所有内容流字符,在参与后续逻辑前,都应该先判断是否落在 CropBox 内。
这是一个:
- 非常确定
- 几乎没有副作用
- 但能显著减少幽灵字符的判断
第五种情况:字符本身就是"空白符"
这是一个看起来最无害、但在工程里最容易污染结果的情况。
在内容流解析中,你有时会读到这样的"字符":
text = " "(空格)text = "\t"text = "\n"- 或看起来像空白,但 unicode 并不直观
而且更迷惑的是:
- 它们有 bbox
- 有位置
- 甚至 size、font 都是正常的
- 完全符合"一个合法字符"的所有条件
但问题在于:
这些字符,从一开始就不是"内容",而是排版副产品。

图:空白字符和隐藏字符示例
它们是怎么来的?
在 PDF 世界里,空白不是一个统一的概念。
常见来源包括:
- 显式绘制的空白字符
- PDF 内容流里直接画了
" " - 比如为了控制字距、对齐、占位
- PDF 内容流里直接画了
- 字体编码映射后的"空白字形"
- 某些 font / cmap 中
- glyph 本身就是"不可见占位"
- 排版技巧
- 用空白字符当作"软分隔"
- 而不是依赖坐标关系
- 导出工具的保守策略
- 为了保持版面结构
- 宁可多画空白,也不信任自动换行
从内容流角度看,这些字符都是合法、真实存在的绘制指令。
为什么它们会成为问题?
因为一旦你开始做:
- 文本拼接
- 行合并
- 段落构建
- 表格单元格内容提取
这些"本来只是排版用途"的空白字符,会突然变成:
- 连续多个空格
- 行首莫名其妙的缩进
- 段落中间断裂
- 表格单元格里多出一堆不可见字符
更糟的是:
它们和"你算法主动插入的空白"混在了一起。
你很快就分不清:
- 哪些空格是 PDF 本来就画的
- 哪些是你为了"模拟阅读"而插的
工程上的处理原则
我对这一类字符的态度非常明确:
内容流里的"空白字符",不应该被当作等价于阅读意义上的空白。
更具体一点:
在字符级别,先区分"原生空白"和"结构空白"。
如果你直接处理的是一些库布局分析后的结果,比如pdfminer。则:
LTChar(text=" "):这是 PDF 主动画的LTAnno(" "):这是算法为了拼接主动插的
这两者在语义上完全不同,但很多系统在后续阶段直接把它们混为一谈。
如果你打算做任何文本重建工作:
一定要在一开始就区分清楚它们的来源。
对连续空白字符,尽早做去重 / 折叠
在大多数工程场景中:
- 连续多个空白字符
- 几乎不提供额外信息
但它们会:
- 扰乱字符间距判断
- 干扰"是否需要插空格"的逻辑
- 放大排版噪声
一个非常稳妥的工程做法是:
在字符层面就做"连续空白折叠"。
而不是等到字符串拼完再处理。
空白字符是"空间关系推断"的一个重要参考
如果你深入研究基于内容流的布局计算算法。这些用于排版的空白字符可能是文本间空间关系的一个重要参考,可以用于辅助判断:
- 两个视觉上看上去有一定距离的字符实际上有空间关联/属于同一行。
- 几行文本是列表的形式,
- 上下两行应该插入空格
- ......
一个很现实的工程结论
写到这里,其实你已经能看到一个趋势了:
PDF 内容流里的很多"字符",并不是为"被读"而存在的。
它们是:
- 排版的工具
- 布局的副产品
- 绘制层面的痕迹
而不是语言的组成部分,但是在更高级的布局算法里头,却可以用作重要的参考。
和前面几种情况放在一起看
你会发现:
| 类型 | 本质问题 |
|---|---|
| 被覆盖字符 | 绘制顺序 ≠ 可见性 |
| 不可见颜色 | 视觉属性 ≠ 语义 |
| 零尺寸字符 | 几何存在 ≠ 阅读意义 |
| CropBox 外字符 | 页面逻辑 ≠ 画布范围 |
| 空白字符 | 排版符号 ≠ 文本内容 |
它们有一个共同点:
内容流是"怎么画",而不是"怎么读"。
小结:这些字符不是 bug,而是 PDF 的真实一面
如果你在内容流里看到了"幽灵文字",请先不要急着骂库、骂模型、骂自己。
因为:
- PDF 允许这样画
- 内容流如实记录了它
- 只是你之前从没意识到,它们并不等价
理解这一点之后,你会发现:
内容流不是不可靠,它只是比你以为的,更加"不替人类做决定"。