MySQL 索引从入门到精通:核心概念、类型与实战优化
一、索引是什么?(核心概念)
可以把索引理解为数据库表的 "目录":
没有索引时,查询数据需要逐行扫描全表(全表扫描),就像找书中某段内容要逐页翻;
有了索引后,数据库会先查索引(目录),快速定位到数据所在位置,大幅提升查询效率。
索引的本质是一种排好序的数据结构(MySQL 中最常用的是 B+Tree),它存储了表中一列 / 多列的值,并指向对应数据行的物理地址。
二、MySQL 中常见的索引类型
1. 按 "数据结构" 分类(底层实现)
| 类型 | 特点 | 适用场景 |
|---|---|---|
| B+Tree 索引 | MySQL 默认索引类型,支持范围查询、排序,叶子节点存储数据地址 / 数据本身 | 绝大多数查询场景(主键、普通字段) |
| Hash 索引 | 基于哈希表实现,等值查询极快,但不支持范围查询、排序 | 仅 Memory 引擎支持,极少用 |
| 全文索引 | 针对文本内容的分词索引,支持模糊匹配(如 MATCH AGAINST) |
文章、评论等长文本检索 |
MySQL 官方的索引数量限制:
| 限制维度 | InnoDB 引擎(默认) | MyISAM 引擎 |
|---|---|---|
| 单表总索引数 | 最多 64 个(包含所有类型:主键、普通、唯一、复合等) | 最多 64 个 |
| 单个复合索引的字段数 | 最多 16 个 (比如 idx_abc(a,b,c...) 最多包含 16 个字段) |
最多 16 个 |
| 索引字段总长度 | 最多 3072 字节(所有索引字段的长度之和) | 最多 1000 字节 |
补充:MySQL 8.0+ 对部分限制(如索引长度)有小幅放宽,但 "单表 64 个索引" 是通用上限,且几乎不会用到。
中小型表(数据量 ≤ 100 万) :控制在 5~8 个 以内;
大型表(100 万 < 数据量 ≤ 1000 万) :控制在 8~12 个 以内;
超大型表(数据量 > 1000 万) :建议不超过 15 个 ,且优先用 "复合索引" 替代多个单字段索引(比如用
idx_age_gender(age, gender)替代idx_age+idx_gender)。
2. 按 "功能 / 创建方式" 分类(实际开发常用)
(1)主键索引(PRIMARY KEY)
特殊的唯一索引,一张表只能有一个主键索引;
主键字段值不能为 NULL,且必须唯一;
sql
-- 创建表时指定主键索引
CREATE TABLE user (
id INT NOT NULL,
name VARCHAR(20),
PRIMARY KEY (id) -- 主键索引(底层是B+Tree)
);(2)唯一索引(UNIQUE)
保证索引字段的值唯一,但允许 NULL(多个 NULL 不冲突);
一张表可以有多个唯一索引;
sql
-- 给user表的phone字段加唯一索引
CREATE UNIQUE INDEX idx_user_phone ON user (phone);(3)普通索引(INDEX)
最基础的索引,无唯一性、非空限制,仅用于提升查询速度;
sql
-- 给user表的name字段加普通索引
CREATE INDEX idx_user_name ON user (name);(4)复合索引(联合索引)
基于多个字段创建的索引,遵循 "最左前缀原则";
sql
-- 给user表的age+gender创建复合索引
CREATE INDEX idx_user_age_gender ON user (age, gender);
-- 最左前缀原则:能命中索引的查询是 age / age+gender,仅查 gender 则不命中补:左前原则:就是"最左前缀原则"
当你创建复合索引 (比如 idx_age_gender(age, gender))时,MySQL 会优先匹配索引中最左侧的字段,然后依次向右匹配 ------ 只有查询条件包含 "最左前缀",才能命中该复合索引;跳过左侧字段直接查右侧字段,索引会失效。
简单说:复合索引 (a, b, c) 的有效匹配顺序是 a → a+b → a+b+c,而 b、c、b+c 都无法命中该索引。

举个例子:
表结构为
sql
CREATE TABLE user (
id INT PRIMARY KEY,
age INT,
gender VARCHAR(2),
city VARCHAR(20)
);
-- 创建复合索引:age(左1)→ gender(左2)→ city(左3)
CREATE INDEX idx_age_gender_city ON user (age, gender, city);样例:
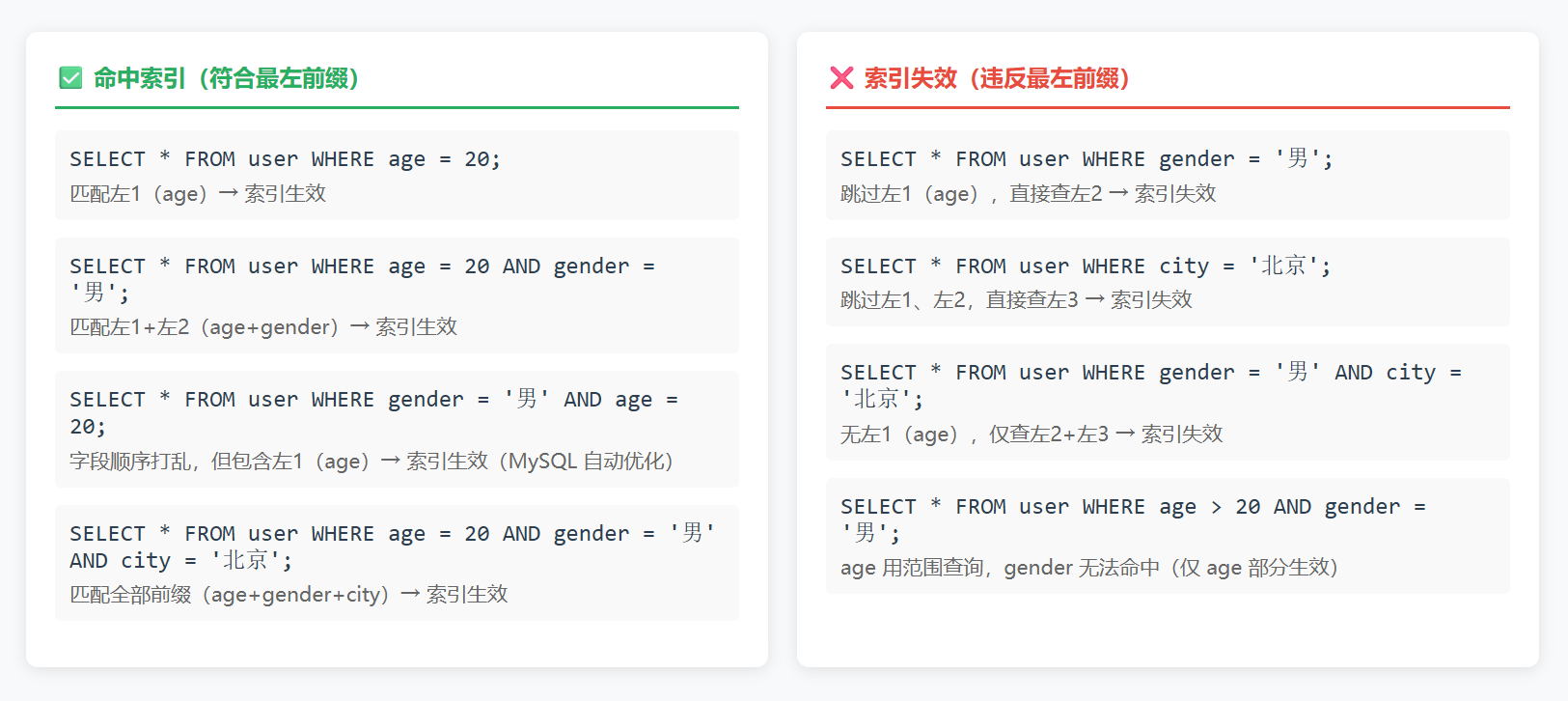
特殊情况:字段顺序不影响(只要包含最左前缀)
MySQL 会自动优化查询条件的字段顺序,只要包含最左前缀,即使顺序打乱也能命中:
sql
-- 条件字段顺序是 gender + age,但包含最左前缀 age → 仍命中索引
SELECT * FROM user WHERE gender = '男' AND age = 20;底层原因:
复合索引的 B+Tree 结构是先按左 1 字段排序,再按左 2 字段排序,最后按左 3 字段排序:
叶子节点先按 age 从小到大排,age 相同的再按 gender 排,gender 相同的再按 city 排;
如果没有 age 这个 "排序依据",数据库无法在索引树中定位到 gender 或 city 的数据,只能全表扫描。
避坑:
不要跳过左侧字段:比如复合索引 (a,b),别只查 b,要么加 a,要么给 b 单独建索引;
合理设计复合索引字段顺序:把查询频率最高、区分度最高的字段放在最左侧(比如 age 比 gender 区分度高,放左 1);
范围查询会中断后续匹配:如果左 1 字段用 >/</BETWEEN 等范围查询,右侧字段无法命中索引:
sql
-- age 用范围查询,gender 无法命中索引(仅 age 部分生效)
SELECT * FROM user WHERE age > 20 AND gender = '男';(5)前缀索引
针对字符串字段(如 VARCHAR、TEXT),仅对字段的前 N 个字符创建索引,节省存储空间;
示例:
sql
-- 给address字段的前10个字符创建前缀索引
CREATE INDEX idx_user_address ON user (address(10));三、索引的优缺点
优点
大幅提升查询效率(尤其是大数据量表);
加速排序、分组操作(ORDER BY/GROUP BY);
约束数据唯一性(主键 / 唯一索引)。
缺点
增加写操作开销(INSERT/UPDATE/DELETE 时,需要同步更新索引,耗时更长);
占用额外存储空间(索引文件会占用磁盘空间);
索引创建 / 维护需要成本(过多索引会拖慢数据库整体性能)。
四、索引使用
适合加索引的场景:
查询频繁的字段(如 WHERE 条件、JOIN 关联字段);
主键、唯一约束字段(必须加);
排序 / 分组字段(ORDER BY/GROUP BY)。
不适合加索引的场景:
数据量极小的表(全表扫描比查索引更快);
频繁更新的字段(写操作会频繁更新索引);
低基数字段(如性别(男 / 女),区分度太低,索引效果差);
NULL 值占比极高的字段。
避坑要点:
遵循复合索引的 "最左前缀原则";
避免索引失效(如 WHERE 中用函数操作索引字段:WHERE DATE(create_time) = '2026-01-13');
不要创建过多索引(一张表建议控制在 5-8 个以内)。
五、InnoDB引擎中的索引
这个时候就有老铁要问了,为什么要单独拎出来讲解InnoDB引擎的索引,
因为InnoDB 是 MySQL 默认且最常用的引擎,其索引设计(聚簇索引 + 二级索引)与 MyISAM 等其他引擎有本质区别,是可以帮助我们理解 MySQL 索引工作原理。
1、一级索引和二级索引
一级索引和二级索引是针对 InnoDB 引擎的索引分类方式(MyISAM 无此划分),核心区别是索引叶子节点存储的内容和在查询中的作用:
一级索引(Primary Index):就是聚簇索引,是 InnoDB 表的 "主索引",叶子节点直接存储完整的行数据;
二级索引(Secondary Index):也叫 "辅助索引",包括普通索引、唯一索引、复合索引、全文索引等所有非聚簇索引,叶子节点仅存储 "索引字段值 + 主键值",不存储完整行数据。
差异:
| 特征 | 一级索引(聚簇索引) | 二级索引(辅助索引) |
|---|---|---|
| 本质 | 聚簇索引 | 非聚簇索引(普通 / 唯一 / 复合 / 全文等) |
| 叶子节点内容 | 完整的行数据 | 索引字段值 + 主键值 |
| 表中数量 | 只能有 1 个 | 可以有多个 |
| 查询是否需回表 | 无需回表(直接拿数据) | 查完整数据需回表(通过主键查一级索引) |
| 默认创建 | 主键自动作为一级索引 | 需手动创建(除隐式主键外) |
(1)一级索引(聚簇索引):
一级索引的创建规则
InnoDB 会按优先级自动确定一级索引:
优先使用用户定义的 PRIMARY KEY(主键)作为一级索引;
若无主键,找第一个 "非空唯一索引(UNIQUE NOT NULL)" 作为一级索引;
若以上都没有,InnoDB 会隐式创建一个 6 字节的自增整型列(GEN_CLUST_INDEX)作为一级索引。
一级索引的查询逻辑
因为叶子节点直接存完整行数据,所以通过一级索引查询时,一步就能拿到所有需要的字段,无需任何额外操作。
示例(基于之前的 user 表,id 是主键 / 一级索引):
sql
-- 用一级索引(id)查询,直接从叶子节点拿数据,无回表
SELECT * FROM user WHERE id = 10;(2)二级索引(辅助索引)
二级索引的类型
所有手动创建的非主键索引都属于二级索引,比如:
sql
-- 普通索引(二级索引)
CREATE INDEX idx_user_name ON user (name);
-- 唯一索引(二级索引)
CREATE UNIQUE INDEX idx_user_phone ON user (phone);
-- 复合索引(二级索引)
CREATE INDEX idx_user_age_gender ON user (age, gender);
-- 全文索引(二级索引)
FULLTEXT INDEX idx_article_content ON article (content);二级索引的查询逻辑
二级索引的叶子节点只有 "索引字段 + 主键",所以查询时分为两种情况:
覆盖索引场景:查询字段仅包含 "索引字段 + 主键"→ 直接从二级索引拿数据,无需回表;
非覆盖场景:查询字段包含其他列 → 先查二级索引拿到主键,再用主键查一级索引(回表)。
示例 1(覆盖索引,无回表):
sql
-- 查询字段:name(索引字段) + id(主键),都在二级索引叶子节点
SELECT id, name FROM user WHERE name = '张三';示例 2(非覆盖场景,需回表):
sql
-- 查询字段包含age(不在idx_user_name叶子节点),需回表查一级索引
SELECT id, name, age FROM user WHERE name = '张三';(3)一级 / 二级索引的关联(查询流程示例)
为了让你更直观理解,我们拆解一个完整的二级索引查询流程:
假设 user 表中 id=10 的用户 name='张三'、age=25,执行 SELECT age FROM user WHERE name = '张三':
数据库先检索二级索引 idx_user_name,找到 name='张三' 对应的主键值 id=10;
再用 id=10 检索一级索引(聚簇索引),从叶子节点中拿到 age=25;
返回结果给用户。
这个过程中,第二步就是 "回表",本质是二级索引依赖一级索引才能获取完整数据。
2、聚簇索引:
(1)聚簇索引是什么?
聚簇索引(Clustered Index)可以理解为:索引的叶子节点直接存储了整张表的行数据,而非仅仅存储指向数据的指针。
打个更形象的比方:
普通索引(非聚簇索引)像书籍的 "目录",目录里只写了 "某章节在第 XX 页",需要先查目录,再翻到对应页码找内容;
聚簇索引则像书籍本身就是 "按目录排序的"------ 目录和内容合二为一,目录的最后一页就是内容的对应页,不需要二次查找。
注意:MySQL 的 InnoDB 引擎才支持聚簇索引,MyISAM 引擎没有聚簇索引的概念(MyISAM 所有索引都是非聚簇的)。
(2)聚簇索引的特点
一张表只能有一个聚簇索引
因为聚簇索引的叶子节点就是数据本身,数据行只能以一种物理顺序存储,所以 InnoDB 表最多只能有一个聚簇索引。
主键就是默认的聚簇索引
InnoDB 会优先将主键索引作为聚簇索引:
如果你给表定义了主键(PRIMARY KEY),InnoDB 就以这个主键创建聚簇索引;
如果你没定义主键,InnoDB 会找第一个非空唯一索引作为聚簇索引;
如果连非空唯一索引都没有,InnoDB 会隐式创建一个名为 GEN_CLUST_INDEX 的自增 6 字节整型列作为聚簇索引。
聚簇索引的结构(B+Tree)
以主键为聚簇索引的结构如下:
plaintext
根节点(主键范围)
/ \
分支节点1 分支节点2
/ \ / \
叶子节点1 叶子节点2 叶子节点3 叶子节点4
(存储完整行数据) (存储完整行数据)非叶子节点:存储主键值和指向子节点的指针;
叶子节点:按主键顺序存储完整的行数据,且叶子节点之间通过双向链表连接(方便范围查询)。
非聚簇索引(二级索引)依赖聚簇索引
InnoDB 中所有的普通索引、唯一索引、复合索引等,都属于 "二级索引",它们的叶子节点只存储索引字段值 + 主键值,而非完整行数据。
举个例子:
假设有 user 表,主键是 id(聚簇索引),给 name 加了普通索引(二级索引):
sql
CREATE TABLE user (
id INT PRIMARY KEY, -- 聚簇索引
name VARCHAR(20),
age INT
);
CREATE INDEX idx_user_name ON user (name); -- 二级索引当执行 SELECT * FROM user WHERE name = '张三' 时,InnoDB 会做两步操作:
- 先查
idx_user_name这个二级索引,找到name='张三'对应的主键值(比如id=10); - 再用这个主键值查聚簇索引,找到
id=10对应的完整行数据(回表查询)。
(3)聚簇索引的优缺点
优点
查询效率极高:主键查询时,直接从聚簇索引的叶子节点拿到完整数据,无需回表;
范围查询快:叶子节点是有序的双向链表,按主键范围查询(如 id BETWEEN 10 AND 20)时,只需遍历链表即可;
数据物理存储有序:行数据按主键物理排序,减少磁盘 I/O。
缺点
插入速度受主键顺序影响大:
如果主键是自增整型(如 id INT AUTO_INCREMENT),新数据会追加到叶子节点末尾,插入效率高;
如果主键是无序值(如 UUID),插入时需要移动数据来维持有序性,会导致大量磁盘 I/O,性能下降。
更新主键代价高:更新主键会改变数据的物理存储位置,同时所有二级索引的主键值也需要同步更新;
页分裂问题:当一个叶子节点存满数据,插入新数据时会触发页分裂,增加额外开销。
(4)四聚簇索引 vs 非聚簇索引(核心区别)
| 维度 | 聚簇索引(InnoDB 主键) | 非聚簇索引(二级索引 / MyISAM 索引) |
|---|---|---|
| 叶子节点存储内容 | 完整的行数据 | 索引字段值 + 指向数据的指针(InnoDB 是主键值,MyISAM 是物理地址) |
| 表中数量 | 只能有 1 个 | 可以有多个 |
| 查询是否需要回表 | 主键查询无需回表 | 查完整数据需要回表(InnoDB) |
| 数据物理顺序 | 按索引顺序存储 | 数据物理存储与索引无关 |
3、什么是回表?
(1)先明确:什么是回表?
回表是 InnoDB 引擎特有的操作,本质是:
当你通过非聚簇索引(二级索引,如普通索引、唯一索引) 查询数据时,如果需要的字段不在该二级索引的叶子节点中 ,数据库会先查二级索引拿到主键值 ,再用主键值去聚簇索引中查找完整行数据的过程。
简单说:回表 = 查二级索引(拿主键) + 查聚簇索引(拿完整数据),是两次索引查询的组合。
(2)回表发生的核心条件
回表的发生需要同时满足两个条件:
- 查询依赖的是二级索引(不是聚簇索引);
- 查询需要的字段不全在二级索引的叶子节点中(叶子节点只有 "索引字段 + 主键")。
(3)回表发生的具体场景(附示例)
以下所有示例均基于这个表结构(InnoDB 引擎):
sql
CREATE TABLE user (
id INT PRIMARY KEY, -- 聚簇索引(叶子节点存完整行数据)
name VARCHAR(20),
age INT,
gender VARCHAR(2),
phone VARCHAR(11)
);
-- 创建二级索引:普通索引
CREATE INDEX idx_user_name ON user (name); -- 叶子节点:name + id
CREATE INDEX idx_user_age_gender ON user (age, gender); -- 叶子节点:age + gender + id场景 1:查询字段包含非索引字段(最常见)
sql
-- 条件用二级索引字段name,但查询字段包含age(不在idx_user_name的叶子节点)
SELECT id, name, age FROM user WHERE name = '张三';第一步:查 idx_user_name 二级索引,找到 name='张三' 对应的主键 id;
第二步:用 id 查聚簇索引,拿到 age 字段 → 触发回表。
场景 2:查询 *(所有字段)且条件用二级索引
sql
-- 查询所有字段,条件用二级索引字段age
SELECT * FROM user WHERE age = 20;* 包含 phone 等不在 idx_user_age_gender 叶子节点的字段,必须回表查聚簇索引才能拿到完整数据 → 触发回表。
场景 3:复合索引不满足 "覆盖",需额外字段
sql
-- 条件用复合索引的age,但查询字段包含phone(不在索引中)
SELECT id, age, phone FROM user WHERE age = 20;复合索引 idx_user_age_gender 的叶子节点只有 age + gender + id,没有 phone → 触发回表。
(4)不会发生回表的场景(对比理解)
场景 1:直接用聚簇索引(主键)查询
sql
-- 条件用主键(聚簇索引),无论查什么字段都不回表
SELECT * FROM user WHERE id = 10;聚簇索引的叶子节点直接存完整行数据,一步就能拿到所有字段 → 无回表。
场景 2:查询字段仅包含 "二级索引字段 + 主键"(覆盖索引)
sql
-- 查询字段:name(索引字段) + id(主键),都在idx_user_name的叶子节点
SELECT id, name FROM user WHERE name = '张三';无需查聚簇索引,直接从二级索引拿到所有需要的字段 → 无回表(这就是 "覆盖索引" 的核心价值)。
场景 3:复合索引覆盖所有查询字段
sql
-- 查询字段:age + gender + id,都在idx_user_age_gender的叶子节点
SELECT id, age, gender FROM user WHERE age = 20;复合索引的叶子节点包含所有查询字段 → 无回表。
(5)如何避免回表?(实用优化方案)
回表会增加一次索引查询,大数据量下会显著降低性能,可通过以下方式避免:
使用覆盖索引(最推荐):
调整查询语句,只查 "二级索引字段 + 主键",不查额外字段;
或创建包含所需字段的复合索引(比如将常用查询字段加入复合索引):
sql
-- 原查询需要name + age,给name和age建复合索引
CREATE INDEX idx_user_name_age ON user (name, age);
-- 此时查询 SELECT id, name, age FROM user WHERE name = '张三' 无需回表优先用主键查询:如果业务允许,先通过其他方式拿到主键,再用主键查数据(比如先查 name 拿到 id,再用 id 查 *)。
合理设计索引:将高频查询的字段加入复合索引,让索引覆盖更多查询场景。
总结
索引是 MySQL 提升查询效率的核心手段,本质是 "有序数据结构(B+Tree 为主)",可类比为 "表的目录";
常用索引类型包括主键索引、唯一索引、普通索引、复合索引,其中复合索引需遵循 "最左前缀原则";
,大数据量下会显著降低性能,可通过以下方式避免:
使用覆盖索引(最推荐):
调整查询语句,只查 "二级索引字段 + 主键",不查额外字段;
或创建包含所需字段的复合索引(比如将常用查询字段加入复合索引):
sql
-- 原查询需要name + age,给name和age建复合索引
CREATE INDEX idx_user_name_age ON user (name, age);
-- 此时查询 SELECT id, name, age FROM user WHERE name = '张三' 无需回表优先用主键查询:如果业务允许,先通过其他方式拿到主键,再用主键查数据(比如先查 name 拿到 id,再用 id 查 *)。
合理设计索引:将高频查询的字段加入复合索引,让索引覆盖更多查询场景。
总结
索引是 MySQL 提升查询效率的核心手段,本质是 "有序数据结构(B+Tree 为主)",可类比为 "表的目录";
常用索引类型包括主键索引、唯一索引、普通索引、复合索引,其中复合索引需遵循 "最左前缀原则";
索引并非越多越好,要平衡查询效率和写操作开销,仅给高频查询、低更新的字段加索引。