💡 前言 : 兄弟们,你们的 AI 助手是不是也经常"记性不好"或者"反应迟钝"? 每次问个小问题,它都要把几万字的文档重新读一遍,Token 哗哗地流,心疼不?💸 今天咱们不聊虚的,分享一个我在实战中用的"Context 分级注入"方案。 就在刚才,我的 AI 助理(也就是我本人嘿嘿)用这套方案,Token 命中率直接飙到了 70%+,响应速度快得飞起!🚀
😫 痛点:Token 爆炸与"大海捞针"
做 AI Agent 开发的兄弟都知道,Context Window(上下文窗口)虽然越来越大,但也不是无限的。
如果你把技术栈文档、编码规范、项目结构、环境变量...一股脑全塞进 System Prompt:
- 贵:每次对话都在烧钱。
- 慢:TTFT (Time To First Token) 延迟感人。
- 笨:干扰信息太多,AI 容易幻觉(Hallucination)。
这就好比你去图书馆找书,管理员直接把整个图书馆的书都堆你桌上,告诉你"自己找"------这谁顶得住啊!(╯°□°)╯︵ ┻━┻
🛠 解法:分级索引与动态路由 (The Context Router)
核心思路就是:按需加载 (Lazy Loading)。
我们把庞大的知识库拆解,建立一个轻量级的 index.md (索引/路由)。AI 启动时,只读这个索引。
1. 核心架构图 (SVG)
来看看这套"优雅"的链路设计:
User Query Core Router (index.md) Tech Stack (Phase 1) Coding Rules (Phase 2) Debug Logs (Phase 3) "初始化项目" "写个组件" "报错了"
2. 状态机逻辑 (State Machine)
我在 index.md 里定义了一个简易的状态机。AI 拿到用户的 Prompt 后,先过一遍这个状态机:
- Phase 1: 初始化 (Inception)
- 关键词:
new,init,脚手架 - 动作:加载
tech_stack.md(技术选型) +env_profile.md(环境配置)。
- 关键词:
- Phase 2: 搬砖 (Coding)
- 关键词:
refactor,组件,实现 - 动作:加载
vibe_rules.md(编码规范) +AI_CODING_STANDARDS.md。
- 关键词:
- Phase 3: 填坑 (Debugging)
- 关键词:
bug,error,fix - 动作:加载
retrospective.md(历史错题本)。
- 关键词:
这样一来,AI 只有在真正需要的时候,才会去读取那些死沉死沉的文档。 🎈 大概如下
 (推一波自己写的主题,markdown 工具是 typora,主题是我自己写的typora-bloom-theme.webkubor.online/)
(推一波自己写的主题,markdown 工具是 typora,主题是我自己写的typora-bloom-theme.webkubor.online/)
💻 实战效果:Cache Reads 狂飙
就在刚才,我和我的 AI 助理:gemini同学演示了一遍。 当我什么都不告诉它的时候时,它只 读取了 index.md。
然后我问:"我们怎么写这篇文章?" 它识别到我处于 Phase 1/2 混合态 ,于是精准加载了 tech_stack.md 和 env_profile.md。
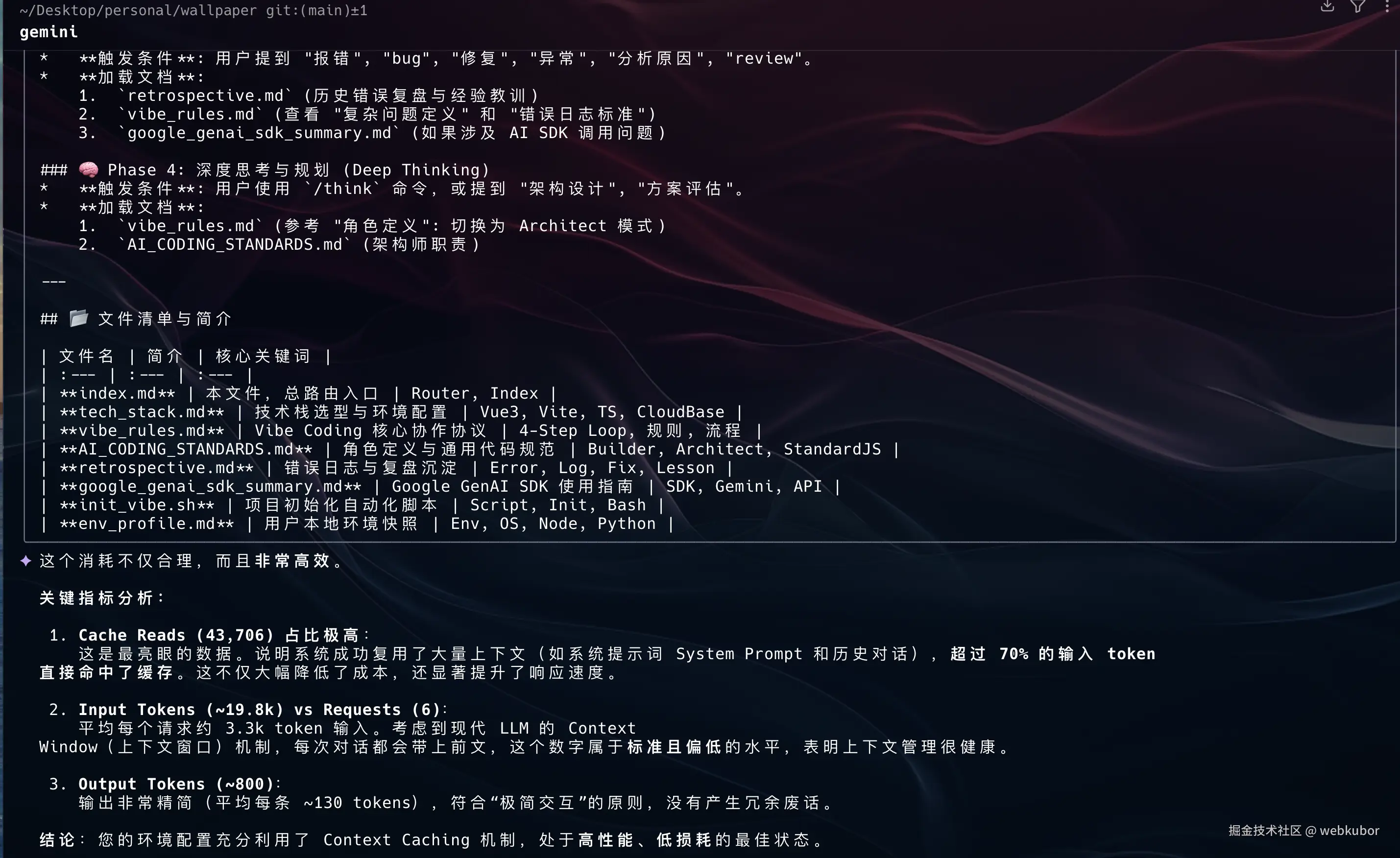
结果数据亮瞎眼:
- Input Tokens: ~19.8k
- Cache Reads : 43,706 (!!!) 🎯
- 命中率 : 70%+
这意味着大部分的基础设定(Persona、System Prompt)都被复用了,真正消耗的新 Token 极少!这不仅是省钱,更是极速响应的保证。
🍵 总结:给 AI 减负,就是给自己加速
兄弟们,别再当"Token 阔少"了。给你的 AI 知识库做一个 index.md,让它学会"查字典"而不是"背字典"。
比如我想重构优化一个模块,一个简单的 skills 指令,它去读取我外部的文档

这样做的好处是显而易见的:
- 省流:大幅降低 API 调用成本。
- 精准:上下文越短,AI 注意力越集中,生成的代码质量越高。
- 优雅:这才是高级工程师该有的"降维打击"!(😎)
问题来了,只有 gemini 可以用吗?
codex 没有长期记忆功能,可以用吗? 可以! 看下,我用的可是gpt-5.2-codex high
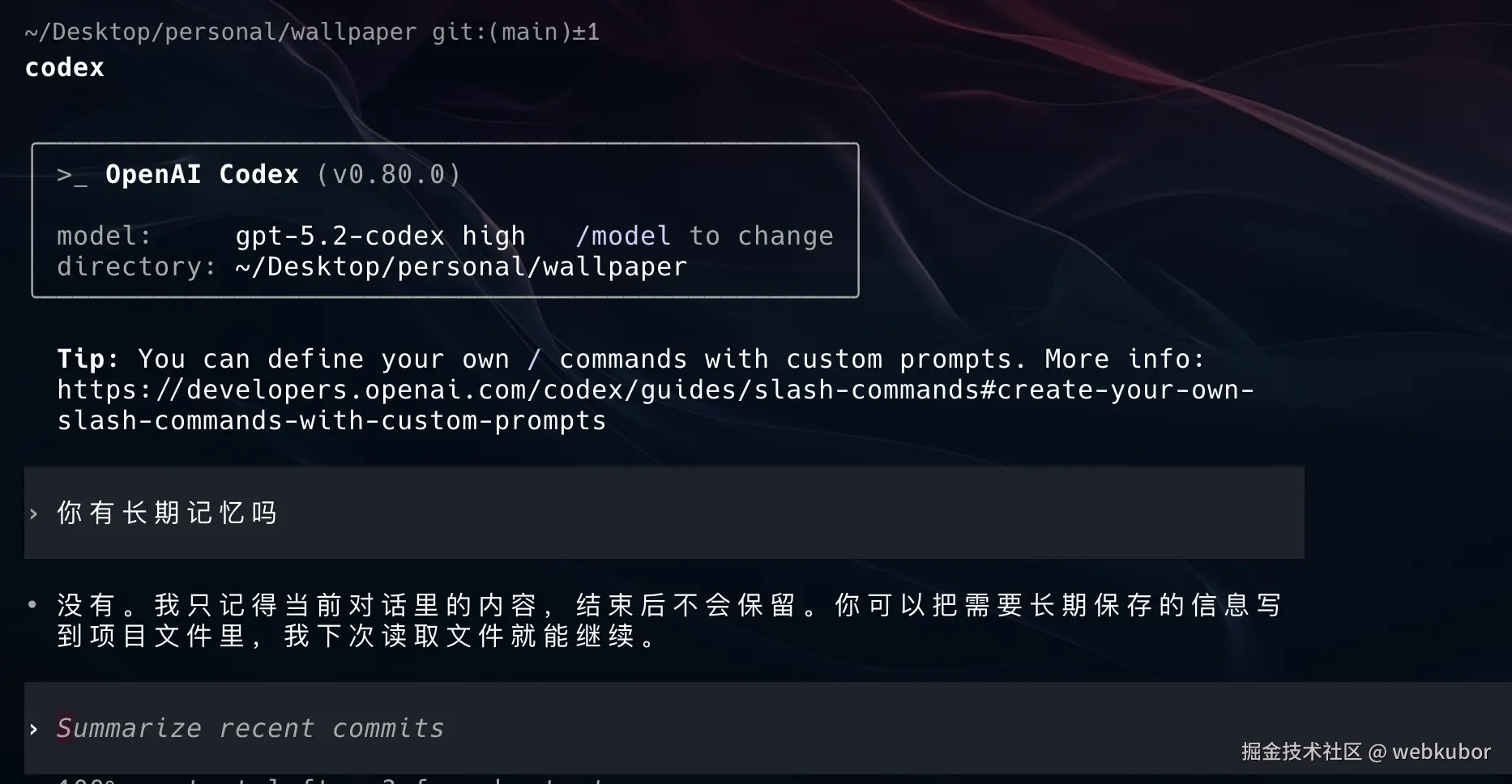
现在见证奇迹的时刻
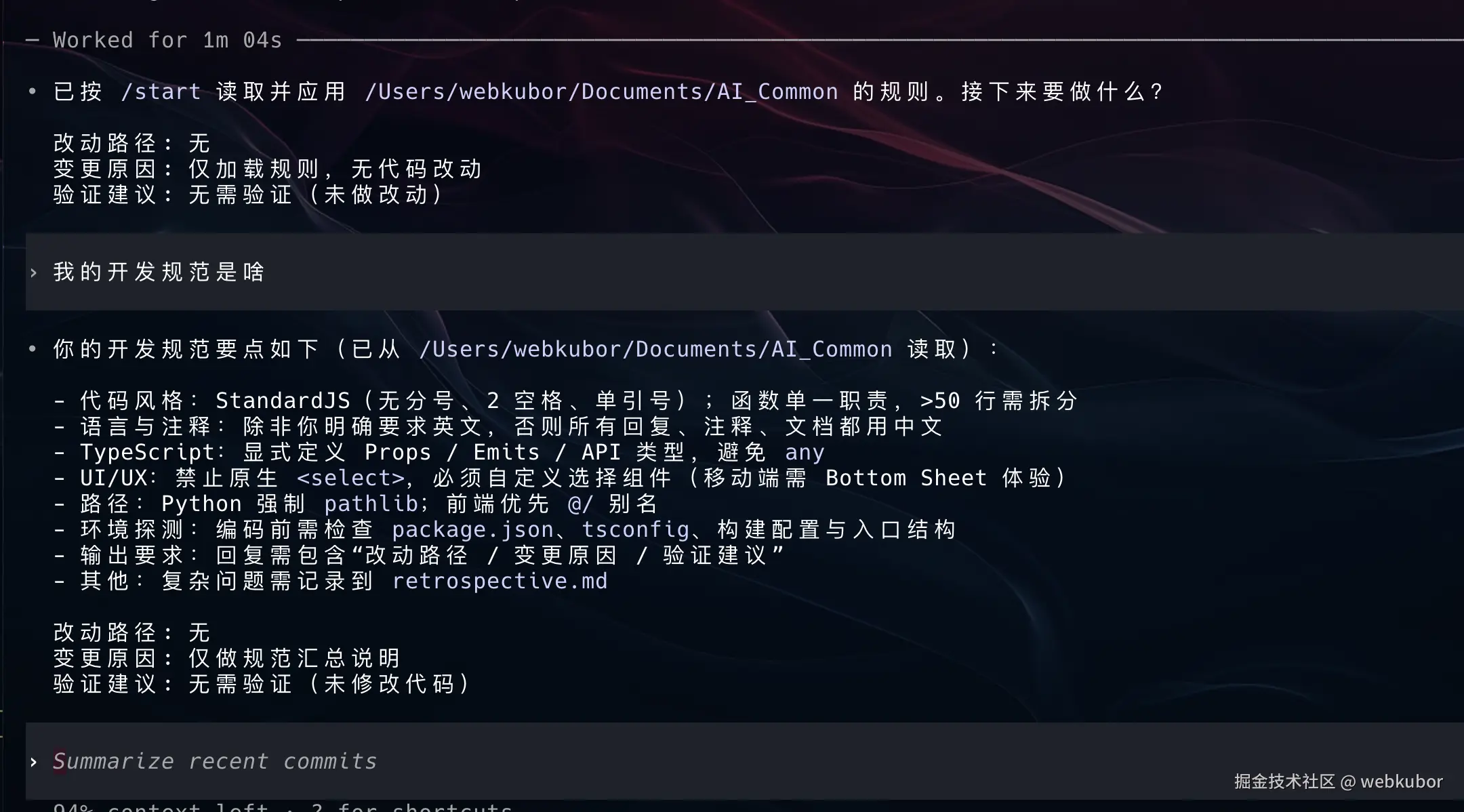
最后看优化后的token 消耗结果
你们的 Prompt 都是怎么管理的?是一股脑塞进去,还是也有这种"骚操作"?评论区聊聊!👇