在工业场景(如跑冒滴漏检测、异物入侵)中,传统的光流法或差分法极易受光照变化和背景扰动的影响。本文介绍了一种基于 YOLO11 主干的孪生分割网络(SiamYOLO-Seg) 。该方案利用 YOLO 强大的特征提取能力,配合孪生网络结构,有效解决了复杂背景下的微小变化检测难题。文章包含完整的模型架构设计、混合损失函数、显存优化策略(梯度累积)及完整训练代码。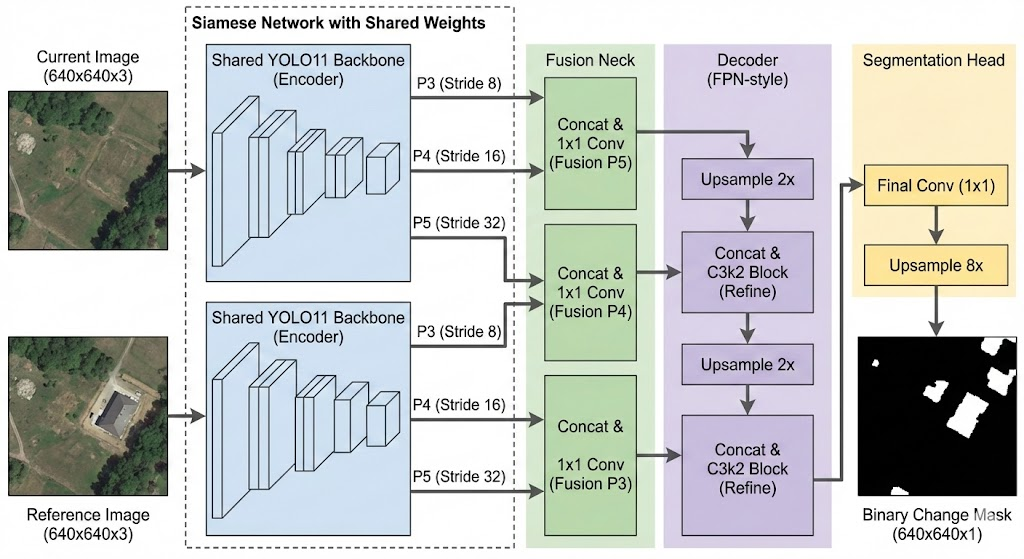
一、 背景与痛点
在工业现场(如化工厂、车间),我们需要检测地面是否有新增的水迹或油污。
-
难点 1:光照复杂 。白天阳光、夜晚灯光、阴影变化都会导致像素值剧烈波动,传统
Image A - Image B的差分法误报率极高。 -
难点 2:样本极少。真实的漏水样本很难收集,通常只有几百张。
-
难点 3:目标微小。漏水初期往往只有几十个像素,容易被 Down-sampling 丢失。
-
难点 4:硬件受限。通常需要在边缘端部署,显存有限(如 8G/10G)。
为了解决这些问题,我们采用了 Deep Learning Change Detection 的思路,并选择了当前 SOTA 的 YOLO11s 作为特征提取器。
二、 模型架构设计:SiamYOLO-Seg
我们的核心思想是:"不仅要看图,还要学会对比"。
1. 整体结构
模型采用标准的 Encoder-Decoder 结构,但由两部分组成:
-
Siamese Encoder (孪生编码器) :加载 YOLO11s 的预训练权重(COCO 或 自定义工业数据训练的权重)。两张图(当前图 Curr、参考图 Ref)共享同一个 Backbone,保证特征提取的一致性。
-
Fusion Neck (融合颈):将两张图在不同尺度(P3, P4, P5)的特征进行拼接(Concat)和融合。
-
Decoder (解码器):类似 FPN/UNet 结构,逐层上采样并融合浅层特征,最终输出 0/1 的二值 Mask。
2. 为什么选择 YOLO11?
相比于老旧的 ResNet18/50,YOLO11s 具备以下优势:
-
C3k2 / C2f 模块:更高效的梯度流,特征提取能力更强。
-
PSA (Attention):引入注意力机制,能自动关注"反光"、"边缘"等关键特征。
-
SPPF:扩大感受野,利用环境上下文信息判断当前像素是否异常。
三、 核心代码实现
1. 自动对齐的 SiamYOLO 模型
为了适配不同版本的 YOLO(s/m/l),我们设计了自适应探测机制,无需手动硬编码通道数。
class SiamYOLO11_Seg(nn.Module):
def __init__(self, model_weight='yolo11s-seg.pt'):
super().__init__()
# 加载 YOLO 权重
yolo = YOLO(model_weight)
self.yolo_model = yolo.model.model
# 🔥 核心黑科技:自动探测层结构
# 跑一次假数据,自动找到 P3(80x80), P4(40x40), P5(20x20) 的层索引和通道数
self._profile_backbone()
# 动态构建融合层和解码器
c3, c4, c5 = self.channels['p3'], self.channels['p4'], self.channels['p5']
self.fuse_p5 = Conv(c5 * 2, c5, 1, 1) # 融合
# ... (解码器构建)
def forward(self, x_curr, x_ref):
# 孪生提取
f_curr = self.extract_features(x_curr)
f_ref = self.extract_features(x_ref)
# 特征拼接与融合
p5_fused = self.fuse_p5(torch.cat([f_curr[2], f_ref[2]], dim=1))
# ...
return logits2. 混合损失函数 (Hybrid Loss)
针对小目标(漏水占比 < 1%),单纯使用 BCE Loss 会导致模型倾向于预测全黑。我们引入 Dice Loss。
Loss = 0.5 BCE + 0.5 Dice
class HybridLoss(nn.Module):
def __init__(self):
super().__init__()
self.bce = nn.BCEWithLogitsLoss()
self.dice = DiceLoss(smooth=1)
def forward(self, inputs, targets):
return 0.5 * self.bce(inputs, targets) + 0.5 * self.dice(inputs, targets)四、 训练策略:如何在 10G 显存下训练大模型?
这是工程落地的关键。由于孪生网络显存占用翻倍,Batch Size 很难开大。我们采用了以下组合拳:
1. 显存碎片优化
在代码最开头设置环境变量,防止 OOM:
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"2. 梯度累积 (Gradient Accumulation)
通过小步快跑,攒够再发的策略,实现大 Batch 的效果。
-
物理 Batch: 4 (显存占用 7G,安全)
-
累积步数: 4
-
等效 Batch: 16 (保证 BN 层和梯度的稳定性)
伪代码逻辑
loss = criterion(preds, mask) / accumulate_step # Loss 标准化
scaler.scale(loss).backward() # 攒梯度if (i + 1) % accumulate_step == 0:
scaler.step(optimizer) # 更新参数
optimizer.zero_grad() # 清空梯度
3. 两阶段训练法 (Two-Stage Training)
针对小样本(<1000张),防止过拟合:
-
阶段一 (Finetune) :冻结 Backbone 。只训练 Decoder,学习率
1e-3。利用 YOLO 预训练的强大特征,快速学会找不同。 -
阶段二 (Full) :全量解冻 。加载阶段一权重,以极小的学习率
1e-5微调所有层,适应光照差异。
五、 完整源码
"""
工业级小样本变化检测 Baseline (基于 YOLO11 + 孪生网络)
Industrial Change Detection Baseline based on Siamese YOLO11
主要特性 (Features):
1. 孪生网络架构 (Siamese Architecture): 复用 YOLO11 强大的特征提取能力。
2. 显存优化 (Memory Optimization): 支持梯度累积 (Gradient Accumulation) 和碎片整理。
3. 自适应对齐 (Auto-Alignment): 自动探测 YOLO Backbone 的通道数,无需硬编码。
4. 混合损失 (Hybrid Loss): 结合 BCE 和 Dice Loss,优化小目标检测。
5. 两阶段训练 (Two-Stage Training): 支持冻结/解冻 Backbone,适应小样本场景。
Author: [YangLong]
Date: 2024-01-13
"""
import os
# ==============================================================================
# 🔥 [显存优化] 必须在 import torch 之前设置
# 开启 PyTorch 显存碎片整理功能,防止在显存充足时报 OOM (Out Of Memory)
# ==============================================================================
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
import cv2
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torch.cuda.amp import autocast, GradScaler
from tqdm import tqdm
from ultralytics import YOLO
from ultralytics.nn.modules import Conv, C3k2
import albumentations as A
from albumentations.pytorch import ToTensorV2
from torch.utils.tensorboard import SummaryWriter
import time
import logging
# ==============================================================================
# 1. 配置区域 (Configuration)
# [注意] 请在使用前修改为你本地的实际路径
# ==============================================================================
CONFIG = {
# --- 数据集路径 ---
# 数据集结构要求:
# root/A (当前图), root/B (参考图), root/label (掩码图 0/255)
"train_root": "./dataset/train", # 👈 请修改为你的训练集路径
"val_root": "./dataset/val", # 👈 请修改为你的验证集路径
# --- 训练超参数 ---
"img_size": 640, # 输入图片尺寸
"epochs": 100, # 总训练轮数
"lr": 1e-5, # 学习率 (全量微调建议使用较小LR,如 1e-5)
# --- 显存/Batch优化策略 ---
# 显存不足时的黄金组合:小 Batch + 梯度累积
# 示例: batch_size=4, accumulate_step=4 => 等效 Batch Size = 16
"batch_size": 4, # 物理显存中的 Batch Size (根据显存大小调整)
"accumulate_step": 4, # 累积多少次梯度才更新一次参数
"num_workers": 2, # 数据加载线程数 (Windows建议设为0或2)
"device": "cuda", # 使用 'cuda' 或 'cpu'
# --- 权重与保存 ---
"save_dir": "./checkpoints/siam_yolo_v1", # 模型保存路径
# [基础权重]: 用于构建模型骨架 (Skeleton)
# 可以是官方 yolo11s-seg.pt,也可以是你自己训练过的 YOLO 分割模型
"yolo_weight": "./weights/yolo11s-seg.pt",
# [接力权重]: 用于断点续训或第二阶段训练 (Soul)
# 如果从头训练,请设为 None
"resume_checkpoint": None,
# --- 训练模式 ---
# "finetune": 冻结 Backbone,只训练解码器 (适合刚开始或极少样本)
# "full": 解冻所有层,全量训练 (适合追求高精度)
"train_mode": "full",
"finetune_lr": 1e-3, # 微调模式下通常使用较大的学习率
}
# 设置日志系统
os.makedirs(CONFIG["save_dir"], exist_ok=True)
logging.basicConfig(
filename=os.path.join(CONFIG["save_dir"], 'train_log.txt'),
level=logging.INFO,
format='%(asctime)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
console = logging.StreamHandler()
logging.getLogger('').addHandler(console)
def log_print(msg):
"""同时输出日志到控制台和文件"""
logging.info(msg)
# ==============================================================================
# 2. 模型定义: SiamYOLO11 (孪生网络)
# ==============================================================================
class SiamYOLO11_Seg(nn.Module):
"""
基于 YOLO11 Backbone 的孪生分割网络
原理:
1. 使用 YOLO11 提取两张图 (Current, Reference) 的特征 (P3, P4, P5)
2. 在特征层进行融合 (Fusion)
3. 通过解码器 (Decoder) 恢复分辨率并输出变化掩码 (Mask)
"""
def __init__(self, model_weight='yolo11s-seg.pt'):
super().__init__()
log_print(f"🏗️ 初始化 SiamYOLO11 (自适应模式)...")
# --- 1. 加载 YOLO 权重 (构建结构) ---
if not os.path.exists(model_weight):
log_print(f"❌ 错误:基础权重文件不存在: {model_weight}")
raise FileNotFoundError(f"Weight file not found: {model_weight}")
# 使用 ultralytics 库加载模型结构
yolo = YOLO(model_weight)
self.yolo_model = yolo.model.model
self.layers = self.yolo_model
# --- 2. 自适应探测 (Auto-Alignment) ---
# 自动跑一次假数据,探测 P3, P4, P5 层的索引和通道数
# 避免手动硬编码导致的模型不匹配问题
self.layer_indices = {}
self.channels = {}
self._profile_backbone()
c3, c4, c5 = self.channels['p3'], self.channels['p4'], self.channels['p5']
log_print(f"📊 自动对齐: P3={c3}ch, P4={c4}ch, P5={c5}ch")
# --- 3. 定义融合层与解码器 (Fusion & Decoder) ---
# 融合层: 将两张图的特征 Concatenate 后降维
self.fuse_p5 = Conv(c5 * 2, c5, 1, 1)
self.fuse_p4 = Conv(c4 * 2, c4, 1, 1)
self.fuse_p3 = Conv(c3 * 2, c3, 1, 1)
# 解码器: 类似 FPN/UNet 结构,自顶向下上采样融合
self.up_p5_p4 = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
self.conv_p4 = C3k2(c5 + c4, c4, 1, shortcut=False)
self.up_p4_p3 = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
self.conv_p3 = C3k2(c4 + c3, c3, 1, shortcut=False)
# 输出头
self.final_up = nn.Upsample(scale_factor=8, mode='bilinear', align_corners=False)
self.final_conv = nn.Sequential(
Conv(c3, 64, 3, 1),
nn.Conv2d(64, 1, kernel_size=1) # 输出单通道 Mask
)
def _profile_backbone(self):
"""发送假数据探测 Backbone 结构"""
dummy = torch.zeros(1, 3, 640, 640)
detected_features = {}
# 遍历每一层,记录输出尺寸
for i, layer in enumerate(self.layers):
try:
dummy = layer(dummy)
_, c, h, w = dummy.shape
# 记录 80x80(P3), 40x40(P4), 20x20(P5) 的层索引
if h in [80, 40, 20] and h not in detected_features:
detected_features[h] = (i, c)
except Exception as e:
# 某些层可能不支持空输入,跳过
pass
# 映射
if 80 in detected_features: self.layer_indices['p3'], self.channels['p3'] = detected_features[80]
if 40 in detected_features: self.layer_indices['p4'], self.channels['p4'] = detected_features[40]
if 20 in detected_features: self.layer_indices['p5'], self.channels['p5'] = detected_features[20]
# 截断模型:只保留到 P5 为止,丢弃原本 YOLO 的检测头
if 'p5' in self.layer_indices:
max_idx = self.layer_indices['p5']
self.backbone_layers = self.layers[:max_idx+1]
else:
raise RuntimeError("Failed to detect P5 layer! Please check input model.")
def extract_features(self, x):
features = {}
for i, layer in enumerate(self.backbone_layers):
x = layer(x)
if i == self.layer_indices['p3']: features['p3'] = x
elif i == self.layer_indices['p4']: features['p4'] = x
elif i == self.layer_indices['p5']: features['p5'] = x
return [features['p3'], features['p4'], features['p5']]
def forward(self, x_curr, x_ref):
# 1. 孪生提取特征
f_curr = self.extract_features(x_curr)
f_ref = self.extract_features(x_ref)
# 2. 特征融合 (Concatenate -> Conv)
p5_fused = self.fuse_p5(torch.cat([f_curr[2], f_ref[2]], dim=1))
p4_fused = self.fuse_p4(torch.cat([f_curr[1], f_ref[1]], dim=1))
p3_fused = self.fuse_p3(torch.cat([f_curr[0], f_ref[0]], dim=1))
# 3. 解码上采样
x = self.up_p5_p4(p5_fused)
x = torch.cat([x, p4_fused], dim=1)
x = self.conv_p4(x)
x = self.up_p4_p3(x)
x = torch.cat([x, p3_fused], dim=1)
x = self.conv_p3(x)
# 4. 最终输出
x = self.final_up(x)
logits = self.final_conv(x)
return logits
def freeze_backbone(self):
"""冻结 Backbone,只训练 Decoder (用于微调阶段)"""
log_print("❄️ 冻结 Backbone 层...")
for param in self.yolo_model.parameters():
param.requires_grad = False
# 确保 Head 部分是可训练的
trainable_modules = [self.fuse_p5, self.fuse_p4, self.fuse_p3, self.conv_p4, self.conv_p3, self.final_conv]
for module in trainable_modules:
for param in module.parameters():
param.requires_grad = True
def unfreeze_all(self):
"""解冻所有层 (用于全量训练阶段)"""
log_print("🔥 解冻所有层,全量训练模式...")
for param in self.parameters():
param.requires_grad = True
# ==============================================================================
# 3. 数据集定义
# ==============================================================================
class CD_Dataset(Dataset):
def __init__(self, root_dir, img_size=640, is_train=True):
self.root = root_dir
self.img_size = img_size
# 寻找 A 目录下的图片
self.ids = [f for f in os.listdir(os.path.join(root_dir, 'A')) if f.endswith(('.jpg', '.png'))]
# 定义增强流 (Albumentations)
# 关键点: 对 Image0 (参考图) 和 Mask 必须应用完全相同的几何变换
if is_train:
self.transform = A.Compose([
A.Resize(img_size, img_size),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.Rotate(limit=15, p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.Normalize(),
ToTensorV2()
], additional_targets={'image0': 'image', 'mask': 'mask'})
else:
self.transform = A.Compose([
A.Resize(img_size, img_size),
A.Normalize(),
ToTensorV2()
], additional_targets={'image0': 'image', 'mask': 'mask'})
def __len__(self): return len(self.ids)
def __getitem__(self, idx):
try:
fname = self.ids[idx]
p_curr = os.path.join(self.root, 'A', fname)
p_ref = os.path.join(self.root, 'B', fname)
# 兼容 png 和 jpg 格式的 mask
p_mask_png = os.path.join(self.root, 'label', os.path.splitext(fname)[0] + '.png')
p_mask_jpg = os.path.join(self.root, 'label', fname)
p_mask = p_mask_png if os.path.exists(p_mask_png) else p_mask_jpg
img_curr = cv2.imread(p_curr)
img_ref = cv2.imread(p_ref)
mask = cv2.imread(p_mask, cv2.IMREAD_GRAYSCALE)
if img_curr is None or img_ref is None or mask is None:
raise ValueError(f"Image load failed: {fname}")
img_curr = cv2.cvtColor(img_curr, cv2.COLOR_BGR2RGB)
img_ref = cv2.cvtColor(img_ref, cv2.COLOR_BGR2RGB)
_, mask = cv2.threshold(mask, 127, 1.0, cv2.THRESH_BINARY)
aug = self.transform(image=img_curr, image0=img_ref, mask=mask)
return aug['image'], aug['image0'], aug['mask'].float().unsqueeze(0)
except Exception as e:
# 遇到坏图自动跳过,防止训练中断
log_print(f"⚠️ Error loading {fname}: {e}, skipping...")
return self.__getitem__((idx + 1) % len(self.ids))
# ==============================================================================
# 4. 混合损失函数 (Hybrid Loss)
# ==============================================================================
class DiceLoss(nn.Module):
"""
Dice Loss 专注于区域重叠度,解决小目标像素占比极少导致的不平衡问题
"""
def __init__(self, smooth=1):
super(DiceLoss, self).__init__()
self.smooth = smooth
def forward(self, inputs, targets):
inputs = torch.sigmoid(inputs).view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + self.smooth)/(inputs.sum() + targets.sum() + self.smooth)
return 1 - dice
class HybridLoss(nn.Module):
"""
组合 BCE Loss (像素分类) 和 Dice Loss (区域重叠)
"""
def __init__(self):
super().__init__()
self.bce = nn.BCEWithLogitsLoss()
self.dice = DiceLoss()
def forward(self, inputs, targets):
# 权重可调,通常 1:1 效果不错
return 0.5 * self.bce(inputs, targets) + 0.5 * self.dice(inputs, targets)
# ==============================================================================
# 5. 训练主程序
# ==============================================================================
def train():
writer = SummaryWriter(log_dir=os.path.join(CONFIG["save_dir"], 'logs'))
device = torch.device(CONFIG["device"])
# --- 1. 构建结构 (Skeleton) ---
model = SiamYOLO11_Seg(CONFIG["yolo_weight"]).to(device)
# --- 2. 加载接力权重 (Soul) ---
checkpoint_path = CONFIG.get("resume_checkpoint")
if checkpoint_path and os.path.exists(checkpoint_path):
log_print(f"🔄 正在加载检查点: {checkpoint_path}")
try:
state_dict = torch.load(checkpoint_path, map_location=device)
model.load_state_dict(state_dict)
log_print("✅ 权重加载成功!开始接力训练...")
except Exception as e:
log_print(f"❌ 权重加载失败: {e}")
raise e
else:
log_print("⚠️ 未发现 Resume Checkpoint,使用 YOLO 初始权重开始训练...")
# --- 3. 设置训练模式 (冻结/解冻) ---
if CONFIG.get("train_mode") == "finetune":
model.freeze_backbone()
lr = CONFIG.get("finetune_lr", 1e-3)
else:
model.unfreeze_all()
lr = CONFIG["lr"]
log_print(f"📊 训练配置: Batch={CONFIG['batch_size']} | Accum={CONFIG['accumulate_step']} | LR={lr}")
# 数据加载器
train_ds = CD_Dataset(CONFIG["train_root"], CONFIG["img_size"], is_train=True)
val_ds = CD_Dataset(CONFIG["val_root"], CONFIG["img_size"], is_train=False)
train_loader = DataLoader(train_ds, batch_size=CONFIG["batch_size"], shuffle=True,
num_workers=CONFIG["num_workers"], pin_memory=True)
val_loader = DataLoader(val_ds, batch_size=CONFIG["batch_size"], shuffle=False,
num_workers=CONFIG["num_workers"], pin_memory=True)
optimizer = optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=CONFIG["epochs"])
criterion = HybridLoss()
scaler = GradScaler()
best_f1 = 0.0
start_time = time.time()
log_print(f"🚀 开始训练! Epochs: {CONFIG['epochs']}")
optimizer.zero_grad()
for epoch in range(CONFIG["epochs"]):
model.train()
epoch_loss = 0
# 进度条优化显示
pbar = tqdm(train_loader, desc=f"Ep {epoch+1}", unit="img",
ascii=True, ncols=100,
bar_format='{l_bar}{bar}| {n_fmt}/{total_fmt} [{elapsed}<{remaining}] {postfix}')
# 🔥🔥🔥 梯度累积循环 (Gradient Accumulation Loop) 🔥🔥🔥
for i, (curr, ref, mask) in enumerate(pbar):
try:
curr, ref, mask = curr.to(device), ref.to(device), mask.to(device)
with autocast():
preds = model(curr, ref)
loss = criterion(preds, mask)
# 关键: Loss 需要除以累积步数,进行标准化
loss = loss / CONFIG["accumulate_step"]
# 反向传播 (此时只累积梯度,不更新参数)
scaler.scale(loss).backward()
# 记录显示的 Loss (乘回去以便观察)
current_batch_loss = loss.item() * CONFIG["accumulate_step"]
epoch_loss += current_batch_loss
# 达到累积步数,执行一次参数更新
if (i + 1) % CONFIG["accumulate_step"] == 0:
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
pbar.set_postfix({'L': f"{current_batch_loss:.3f}"})
except Exception as e:
log_print(f"❌ Error: {e}")
torch.cuda.empty_cache()
continue
# 处理 Epoch 结束时剩余的梯度 (不足一个 accumulate_step 的部分)
if (i + 1) % CONFIG["accumulate_step"] != 0:
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
avg_loss = epoch_loss / len(train_loader)
writer.add_scalar('Train/Loss', avg_loss, epoch)
scheduler.step()
# --- 验证环节 ---
f1, iou, precision, recall = validate(model, val_loader, device)
writer.add_scalar('Val/F1', f1, epoch)
time_elapsed = time.time() - start_time
log_msg = (f"✅ Ep {epoch+1} | Loss:{avg_loss:.4f} | "
f"F1:{f1:.4f} | IoU:{iou:.4f} | "
f"P:{precision:.4f} | R:{recall:.4f} | "
f"T:{time_elapsed/60:.1f}m")
log_print(log_msg)
# 保存最佳模型
if f1 > best_f1:
best_f1 = f1
torch.save(model.state_dict(), os.path.join(CONFIG["save_dir"], "best_model.pth"))
log_print(f"💾 Best F1 Updated: {best_f1:.4f}")
torch.save(model.state_dict(), os.path.join(CONFIG["save_dir"], "last_model.pth"))
def validate(model, loader, device):
"""
验证函数: 计算 F1, IoU, Precision, Recall
"""
model.eval()
tp, fp, fn = 0, 0, 0
torch.cuda.empty_cache()
with torch.no_grad():
for curr, ref, mask in loader:
curr, ref, mask = curr.to(device), ref.to(device), mask.to(device)
preds = model(curr, ref)
preds = torch.sigmoid(preds)
preds = (preds > 0.5).float()
# 全局像素级统计
tp += (preds * mask).sum().item()
fp += (preds * (1-mask)).sum().item()
fn += ((1-preds) * mask).sum().item()
epsilon = 1e-7
precision = tp / (tp + fp + epsilon)
recall = tp / (tp + fn + epsilon)
f1 = 2 * precision * recall / (precision + recall + epsilon)
iou = tp / (tp + fp + fn + epsilon)
return f1, iou, precision, recall
if __name__ == "__main__":
torch.backends.cudnn.benchmark = True
try:
train()
except Exception as e:
log_print(f"🔥 Critical Error: {e}")修改代码上端的参数,然后直接开始训练就可以了;