PCA的算法实现
数据准备
python
import numpy as np
import matplotlib.pyplot as plt
w,b = 1.8,2.5
np.random.seed(0)
x1 = np.random.rand(100)*4
noise = np.random.randn(100)
x2 = w * x1 +b +noise
## 纵向合并
x = np.vstack([x1,x2]).T零均值化
python
np.mean(x,axis=0)
x -=np.mean(x,axis=0)PCA实现
先把二维数据压缩成一维(只保留第 1 主成分),再用这一维信息把数据"投影还原"回二维,并和原始数据做对比
python
from sklearn.decomposition import PCA
# n_compontents:想要的主成分的个数
pca = PCA(n_components=1)
pca.fit(x)
x_pca = pca.transform(x)
# 逆变换:把一维点重新拉回二维空间
x_pca_inv = pca.inverse_transform(x_pca)
plt.scatter(x[:,0],x[:,1],s=10)
plt.scatter(x_pca_inv[:,0],x_pca_inv[:,1],s=10,c='r')
plt.show()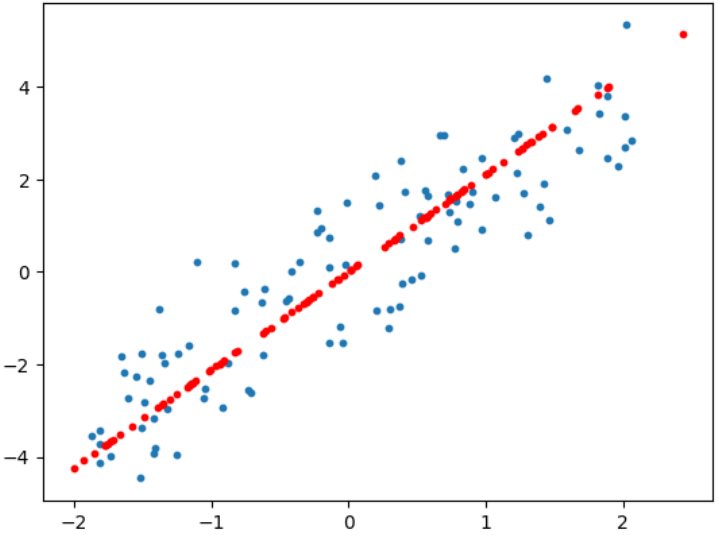
降维
数据准备
python
from sklearn.datasets import load_digits
digits = load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=233)PCA降维
python
from sklearn.decomposition import PCA
# 创建一个 PCA 模型,要求保留至少 90% 的数据方差信息
# 即:让模型自己决定降到多少维,但最后能保留 90% 的整体信息
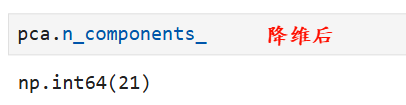
pca = PCA(0.9)
pca.fit(x_train)
## 生成一份降维后的新数据
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
模型训练
python
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(solver='saga',tol=0.001,max_iter=500,random_state=233)
%%time
clf.fit(x_train,y_train)
clf.score(x_test,y_test)
%%time
clf.fit(x_train_pca,y_train)
clf.score(x_test_pca,y_test)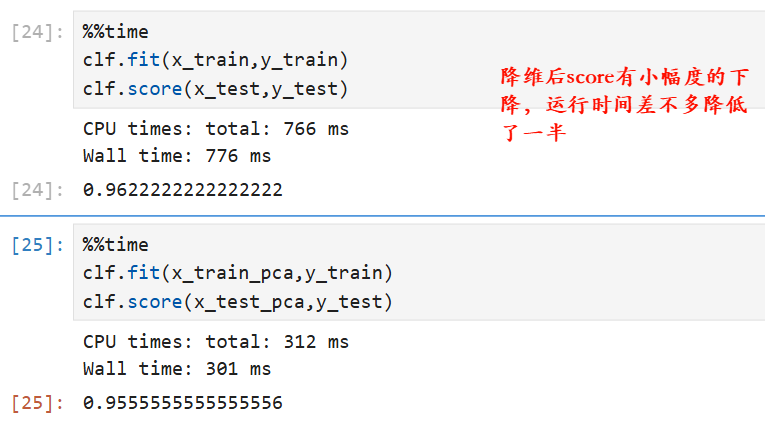
PCA在降噪中的使用
查看数据集图片
python
## 数据集同上,使用digits数据集
def plot_top20_digits(x):
for i in range(20):
# 绘制成一个4*5的图
plt.subplot(4,5,i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x[i].reshape(8,8),cmap=plt.cm.gray_r,interpolation='nearest')
plt.show()
plot_top20_digits(x)
添加噪声
python
# 添加噪声数据
np.random.seed(0)
# *3:扩大噪声的影响
x_noise = x + np.random.randn(x.shape[0],x.shape[1])*3
plot_top20_digits(x_noise)
PCA降噪
python
pca = PCA(0.5)
pca.fit(x_noise)
x_noise_pca = pca.transform(x_noise)
x_noise_inv = pca.inverse_transform(x_noise_pca)
# 相比噪声数据去除掉了很多的噪点
plot_top20_digits(x_noise_inv)
PCA在人脸识别中的使用
数据准备
**fetch_lfw_people**是一个用于人脸识别与人脸表示学习的经典数据集,包含多位名人的灰度人脸图片,尺寸统一(常见是 62×47),data.target_names表示ID->人名的映射,包含5749人的照片
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
lfw = fetch_lfw_people()
x = lfw.data
y = lfw.target
# 样本数量,高度,宽度
n_samples,h,w = lfw.images.shape
查看数据集图片
python
def plot_faces(data,h,w,n_row=3,n_col=4):
plt.figure(figsize=(1.8*n_col,2.4*n_row))
for i in range(n_row*n_col):
plt.subplot(n_row,n_col,i+1)
plt.xticks(())
plt.yticks(())
plt.imshow(data[i].reshape((h,w)),cmap = plt.cm.gray)
plt.show()
plot_faces(x,h,w)
数据集处理
在使用 PCA 实现人脸识别之前,首先需要对人脸数据进行加载、筛选、划分以及标准化处理。
筛选:
min_faces_per_person=70: 只保留至少包含 70 张人脸图片的人物,用于减少类别不平衡问题,提高识别任务的稳定性。resize=0.4: 将原始人脸图像按比例缩小,降低像素维度,从而减少计算量并加快 PCA 训练速度
标准化:
- 将每个像素特征变换为:均值为 0 方差为 1
- 保证不同像素维度在 PCA 中具有同等重要性
- 只在训练集上
fit,再用同一变换作用于测试集,避免信息泄露
python
# min_faces_per_person:筛选每人至少包含70张图片的数据
# resize=0.4:降低分辨率,减少维度,加快 PCA
lfw_people = fetch_lfw_people(min_faces_per_person=70,resize=0.4)
x = lfw_people.data
y = lfw_people.target
n_sanples,h,w = lfw_people.images.shape
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.75,random_state=42)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)PCA实现
生成的是 PCA 学到的特征脸(Eigenfaces),它们不是具体的人脸,而是描述人脸数据集中主要变化模式的基向量,是人脸降维与识别的核心表示
python
from sklearn.decomposition import PCA
pca = PCA(n_components=150,random_state=42)
pca.fit(x_train)
# 特征脸图
plot_faces(pca.components_,h,w)
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
模型训练
python
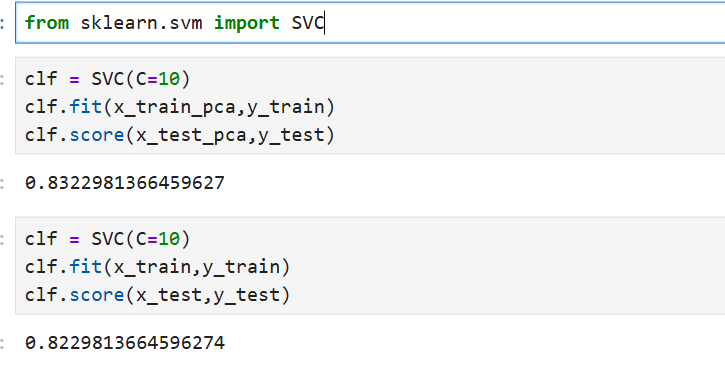
from sklearn.svm import SVC
clf = SVC(C=10)
clf.fit(x_train_pca,y_train)
clf.score(x_test_pca,y_test)
clf = SVC(C=10)
clf.fit(x_train,y_train)
clf.score(x_test,y_test)