上一个系列讲了Spring AI得到反馈效果不错,有人私信我说这个和Langchain4j有什么区别。如果站在使用方面,都是基于Java的大模型应用研发的工具,本质上没太大区别。但是从细节层面来说还是有很多不同之处,所以索性借此机会,给大家分享一下Langchain4j框架。在本系列中会按照Spring AI系列的顺序来写Langchain4j,这样的好处是可以对比两者不同的细节。
注意 :由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是langchain4j-1.9.1,JDK版本使用的是19。另外本系列尽量使用Java原生态,尽量不依赖于Spring和Spring Boot。虽然langchain4j也支持Spring Boot集成,但是如果是使用Spring Boot框架,那为何不索性使用Spring AI。
本系列的所有代码地址: https://github.com/forever1986/langchain4j-study
目录
- [1 Retrieval](#1 Retrieval)
-
- [1.1 Retrieval Augmentor](#1.1 Retrieval Augmentor)
- [1.2 Query Transformer](#1.2 Query Transformer)
-
- [1.2.1 说明](#1.2.1 说明)
- [1.2.2 示例代码](#1.2.2 示例代码)
- [1.3 Query Router](#1.3 Query Router)
-
- [1.3.1 QueryRouter](#1.3.1 QueryRouter)
- [1.3.2 ContentRetriever](#1.3.2 ContentRetriever)
- [1.3.3 示例代码](#1.3.3 示例代码)
- [1.4 Content Aggregator](#1.4 Content Aggregator)
-
- [1.4.1 ContentAggregator](#1.4.1 ContentAggregator)
- [1.4.2 Content Injector](#1.4.2 Content Injector)
- [1.4.3 代码示例](#1.4.3 代码示例)
- [2 与Spring AI的比较](#2 与Spring AI的比较)
上一章讲解了Langchain4j 中RAG模块的Indexing功能,这一章将继续讲解RAG模块的另外一个功能:Retrieval
1 Retrieval
Retrieval通常在线进行,当用户提交应该使用索引文档回答的问题时。这个过程可以根据所使用的信息检索方法而变化。对于向量搜索,这通常涉及嵌入用户的查询(问题)并在嵌入存储中执行相似性搜索。然后将相关片段(原始文档的片段)注入提示并发送给LLM。
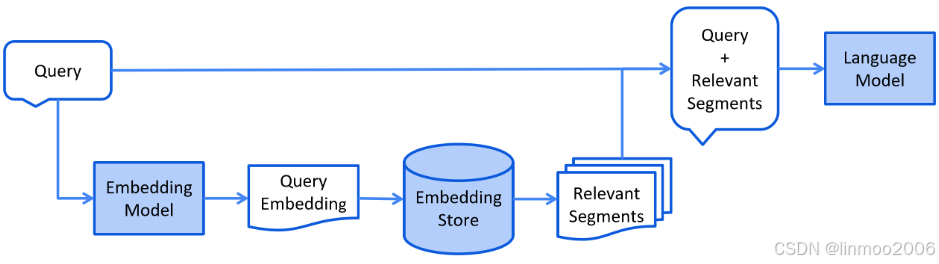
上图流程非常简单,就是将query进行embedding,然后在存储数据库(一般是向量数据库)中检索,最后将检索的结果结合query一起扔给大模型。但是在实际应用中可不是这么简单,为了提高检索最终的准确度,可能还需要做一些优化:
- 问题优化 :初始的问题可能对于查询结果不是很好,可能是因为问题表达模糊、语义与文档不一致等等,因此问题优化就是提高RAG准确率的关键节点。可以参考我之前写的RAG系列中《检索增强生成RAG系列4--RAG优化之问题优化》
- 语义路由 :在现实中,可能并非一个检索数据库就能解决问题,后台可能还存在关系型数据库等其它信息,因此需要对query进行判断,决定使用什么检索或者多个检索结合的方式。这时候就需要一个语义路由。可以参考我之前写的RAG系列中《检索增强生成RAG系列5--RAG提升之路由(routing)》
- 检索结果优化 :对于检索的结果,其实还可以进行重排、精简等操作,这样可以减少无用信息,提高准确率。可以参考我之前写的RAG系统中《检索增强生成RAG系列7--RAG提升之高级阶段》
1.1 Retrieval Augmentor
RetrievalAugmentor是Langchain4j 定义的RAG的管道的Retrieval入口点。它负责用从各种来源检索到的相关内容来扩充ChatMessage。默认中有一个DefaultRetrievalAugmentor实现类,该类在前面《Langchain4j 系列之十七 - RAG入门》中3.2 Retrieval:查询文档 分析其底层原理,主要是augment()方法,如下图:

说明:从上图中,主要分为3个模块
- queryTransformer:查询转换器,既可以将问题转换为多个问题,也可以让问题变得更合理
- process:process方法其实就是使用queryRouter进行路由得到问题的检索器
- contentAggregator:内容聚合器会将所有检索到的内容整合成一个最终的、按排名排列的列表。
下面就根据这三个模块进行一一说明
1.2 Query Transformer
1.2.1 说明
前面提到了RAG可能存在初始的问题可能对于查询结果不是很好,可能是因为问题表达模糊、语义与文档不一致等等,因此问题优化就是提高RAG准确率的关键节点。而Langchain4j 的QueryTransformer接口就是为了做这一部分使用。QueryTransformer将给定的查询转换为一个或多个查询,目标是通过修改或扩展原始查询来提高检索质量。一些已知的改进检索的方法包括:
- Query compression:查询压缩,使用大型语言模型将给定的查询和之前的对话压缩成一个独立的查询。
- Query re-writing:查询重写,可能问题存在不太符合查询要求或者对查询效果不是很好,对问题进行重写。
- Query expansion :查询扩展,让大模型基于用户的问题再生成多个不同角度句子语句,这些问题句子是从不同的视角来补充用户的问题。具体可以参考《检索增强生成RAG系列4--RAG优化之问题优化》中的1 Multi-Query。
- Step-back prompting :通过原始问题生成更抽象的Step-back问题,检索向量数据库得到的Step-back问题包含了原理和背景信息,基于Step-back问题得到的答案,推理得到了正确答案。具体可以参考《检索增强生成RAG系列4--RAG优化之问题优化》中5 Step-back prompting。
- Hypothetical document embeddings (HyDE) :使用大模型假设性回答问题,生成一个答案,再使用答案(注意:这里是使用大模型生成的答案,而非使用原始问题)去向量数据库中搜索相关性内容文档。《检索增强生成RAG系列4--RAG优化之问题优化》中的3 HyDE。
以上关于问题优化,大家可以参考我之前写的《检索增强生成RAG系列4--RAG优化之问题优化》这篇文章。另外也可以看看langchain4j的官方网站的这篇blog《Query Transformations》。而在Langchain4j 中是通过QueryTransformer接口来实现这个功能,该接口默认实现类如下:
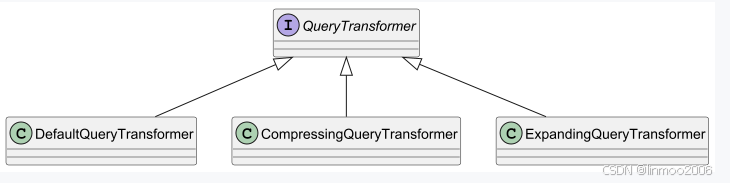
说明:
- DefaultQueryTransformer:这个是默认的query转换,并没有改变query,只是返回一个List
- CompressingQueryTransformer:利用聊天模型将给定的查询与聊天记忆(之前的对话历史记录)结合起来,将其压缩成简洁的查询。
- ExpandingQueryTransformer:使用聊天模型来扩展给定查询的查询,通过提示词生成 {{n}} 个不同的用户query版本
1.2.2 示例代码
代码参考lesson08子模块
1)在lesson08子模块下,新建QueryTransformerTest 类
java
package com.langchain.lesson08.retrieval;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.rag.query.Query;
import dev.langchain4j.rag.query.transformer.ExpandingQueryTransformer;
import dev.langchain4j.rag.query.transformer.QueryTransformer;
import java.util.Collection;
public class QueryTransformerTest {
public static void main(String[] args) {
// 1. 获取API KEY
String apiKey = System.getenv("ZHIPU_API_KEY");
// 2. 构建模型
ChatModel model = OpenAiChatModel.builder()
.apiKey(apiKey)
.baseUrl("https://open.bigmodel.cn/api/paas/v4")
.modelName("glm-4-flash-250414")
.build();
// 3. 扩展query
Query query = new Query("ChatGLM是哪个公司的大模型?");
QueryTransformer queryTransformer = new ExpandingQueryTransformer(model);
Collection<Query> queryList = queryTransformer.transform(query);
System.out.println("=========扩展结果===========");
for(Query q: queryList){
System.out.println(q.text());
}
}
}2)运行QueryTransformerTest 测试,结果如下:

1.3 Query Router
1.3.1 QueryRouter
QueryRouter负责将查询信息分发给相应的ContentRetriever 。之所以要实现一个查询路由,是由于在现实中,可能并非一个检索数据库就能解决问题,后台可能还存在关系型数据库等其它信息,因此需要对query进行判断,决定使用什么检索或者多个检索结合的方式。这时候就需要一个语义路由。可以参考我之前写的RAG系列中《检索增强生成RAG系列5--RAG提升之路由(routing)》,既可以简单的判断,也可以融入大模型进行路由。在Langchain4j 中,QueryRouter的默认实现类如下:
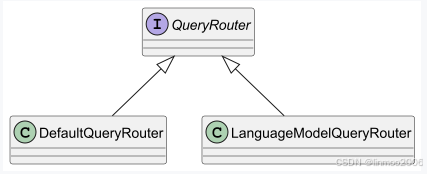
说明:
- DefaultQueryRouter:只是将注册的查询器都返回,让其查询所有结果
- LanguageModelQueryRouter: 利用 大语言模型来做出路由决策。在构造函数中提供的每个 ContentRetriever 都应附带描述,这有助于大语言模型决定将查询路由到何处
1.3.2 ContentRetriever
Langchain4j 中定义了一层抽象的查询器,会根据给定的查询从底层数据源中获取内容。底层数据源几乎可以是任何东西,比如embedding存储、全文搜索引擎、向量与全文搜索的混合体、网络搜索引擎、知识图谱、SQL 数据库等等。在Langchain4j 中ContentRetriever的默认实现类如下:
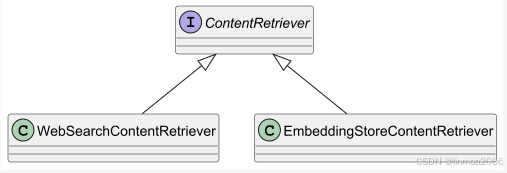
说明:
- WebSearchContentRetriever :网络搜索引擎从网络上检索相关的内容。需要一个网络搜索引擎:WebSearchEngine。目前Langchain4j 默认实现的WebSearchEngine有如下:
1)Google Custom Search:基于谷歌的搜索
2)SearchApi:是一个实时的搜索引擎结果页面API。可以使用它在谷歌、谷歌新闻、必应、必应新闻、百度、谷歌学术或任何其他能返回自然搜索结果的引擎中进行搜索操作
3)SearXNG:开源免费搜索引擎平台,提供来自 Google、Bing、Yahoo 等 70 多种各大视频、图片、搜索、磁力等网站搜索结果
4)Tavily:一个结合大型语言模型(LLMs)和检索增强生成(RAG)优化的搜索引擎,旨在提供高效、快速且持久的搜索结果
5)DuckDuckGo:互联网搜索引擎- EmbeddingStoreContentRetriever: 一个从embedding存储中检索内容的检索器。默认情况下,它会检索与提供的查询最相似的 3 个内容,且不进行任何筛选操作。需要提供embeddingStore存储和embeddingModel模型
1.3.3 示例代码
参考lesson08子模块
本次演示主要是加入Tavily检索器和embedding检索器,然后通过大模型根据不同query进行选择检索器
1)由于需要使用到Tavily检索,在Tavily官方网上获取API KEY
2)在lesson08子模块下,其pom配置增加如下插件
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-web-search-engine-tavily</artifactId>
</dependency>3)在lesson08子模块下,新建QueryRouterTest类
java
package com.langchain.lesson08.retrieval;
import dev.langchain4j.data.document.Metadata;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.rag.content.retriever.WebSearchContentRetriever;
import dev.langchain4j.rag.query.Query;
import dev.langchain4j.rag.query.router.LanguageModelQueryRouter;
import dev.langchain4j.rag.query.router.QueryRouter;
import dev.langchain4j.spi.model.embedding.EmbeddingModelFactory;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import dev.langchain4j.web.search.tavily.TavilyWebSearchEngine;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import static dev.langchain4j.spi.ServiceHelper.loadFactories;
public class QueryRouterTest {
public static void main(String[] args) {
// 1. 获取API KEY
String apiKey = System.getenv("ZHIPU_API_KEY");
// 2. 构建模型
ChatModel model = OpenAiChatModel.builder()
.apiKey(apiKey)
.baseUrl("https://open.bigmodel.cn/api/paas/v4")
.modelName("glm-4-flash-250414")
.build();
// 3. 构建查询器
// 3.1 查询器1:基于Tavily的网络搜索
ContentRetriever contentRetriever1 = new WebSearchContentRetriever(
TavilyWebSearchEngine.builder()
.apiKey(System.getenv("TAVILY_API_KEY"))
.build(), 3);
// 3.2 查询器2:基于Embeding存储的搜索
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingModel embeddingModel = loadEmbeddingModel();
String content1 = """
ChatGLM3是智谱公司和清华大学一起发布的大语言模型。
""";
embeddingStore.add(embeddingModel.embed(content1).content(), new TextSegment(content1, new Metadata()));
String content2 = """
ChatGLM3 是由清华大学技术成果转化企业智谱AI研发的支持中英双语的对话机器人,基于千亿参数基座模型GLM架构开发。该模型通过多阶段训练流程形成通用对话能力,具备问答交互、代码生成、创意写作等功能,其开源版本ChatGLM-6B自2023年3月启动内测以来已形成广泛影响力。\n
截至2024年3月,智谱AI通过该技术实现了2000多家生态合作伙伴的应用落地,并在多模态技术上持续突破,推出了视频生成等创新功能。清华大学是中国排名top2的学校。
""";
embeddingStore.add(embeddingModel.embed(content2).content(), new TextSegment(content2, new Metadata()));
ContentRetriever contentRetriever2 = new EmbeddingStoreContentRetriever(embeddingStore, embeddingModel);
Map<ContentRetriever, String> map = new HashMap<>();
map.put(contentRetriever1, "它是一个基于互联网搜索的查询,具有实时性的数据可以根据它来检索");
map.put(contentRetriever2, "它是一个基于嵌入数据库的查询,关于智谱公司的内容可以根据它来检索");
// 4. 构建检索路由
QueryRouter queryRouter = new LanguageModelQueryRouter(model, map);
// 5. 测试结果
System.out.println("=======第一次查询===========");
Query query = new Query("智谱公司研发的大模型是哪个?");
Collection<ContentRetriever> contentRetrievers = queryRouter.route(query);
System.out.println("使用的检索器" + contentRetrievers);
System.out.println("本次检索结果" + contentRetrievers.iterator().next().retrieve(query));
System.out.println("=======第二次查询===========");
query = new Query("现在是哪年月?");
contentRetrievers = queryRouter.route(query);
System.out.println("使用的检索器" + contentRetrievers);
System.out.println("本次检索结果" + contentRetrievers.iterator().next().retrieve(query));
}
private static EmbeddingModel loadEmbeddingModel() {
Collection<EmbeddingModelFactory> factories = loadFactories(EmbeddingModelFactory.class);
if (factories.size() > 1) {
throw new RuntimeException("Conflict: multiple embedding models have been found in the classpath. "
+ "Please explicitly specify the one you wish to use.");
}
for (EmbeddingModelFactory factory : factories) {
EmbeddingModel embeddingModel = factory.create();
return embeddingModel;
}
return null;
}
}4)运行QueryRouterTest测试,测试结果如下:

说明:可以看到第一次大模型判断使用EmbeddingStoreContentRetriever,而第二次大模型判断使用WebSearchContentRetriever。(这个取决于大模型的判断能力,而且不一定每一次都是一样的,需要不断通过提示词提高或优化,或者直接使用微调过的模型)
1.4 Content Aggregator
1.4.1 ContentAggregator
ContentAggregator负责对于检索的结果,进行重排、精简等操作,这样可以减少无用信息,提高准确率。可以参考我之前写的RAG系统中《检索增强生成RAG系列7--RAG提升之高级阶段》。目前Langchain4j 的ContentAggregator实现类如下:
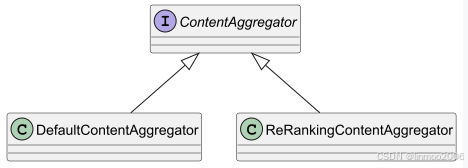
说明:
- DefaultContentAggregator :基于Reciprocal Rank Fusion重排名机制。具体参考我之前写的《检索增强生成RAG系列7--RAG提升之高级阶段》中1.1 RRF算法实现。
- ReRankingContentAggregator : 通过使用诸如 Cohere 这样的评分模型来进行重新排序。具体参考我之前写的《检索增强生成RAG系列7--RAG提升之高级阶段》中1.2 Cohere Rerank模型的实现
1.4.2 Content Injector
ContentInjector 负责将 ContentAggregator 返回的内容注入到 UserMessage 中。Langchain4j 中默认实现DefaultContentInjector类,其就是通过一个promptTemplate提示词模版,将用户的qurey和检索到的content组装在一起:

1.4.3 代码示例
代码参考lesson08子模块
本次演示,采用jina-reranker模型进行重新排序,并组装输出结果
1)在jina官方网站注册获得API KEY
2)在lesson08子模块下,其pom引入
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-jina</artifactId>
</dependency>3)在lesson08子模块下,新建ContentAggregatorTest 类
java
package com.langchain.lesson08.retrieval;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.jina.JinaScoringModel;
import dev.langchain4j.rag.content.Content;
import dev.langchain4j.rag.content.DefaultContent;
import dev.langchain4j.rag.content.aggregator.ReRankingContentAggregator;
import dev.langchain4j.rag.content.injector.ContentInjector;
import dev.langchain4j.rag.content.injector.DefaultContentInjector;
import dev.langchain4j.rag.query.Query;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class ContentAggregatorTest {
public static void main(String[] args) {
// 1. 获取API KEY
String apiKey = System.getenv("JINA_API_KEY");
// 2. 用户的却容易
UserMessage chatMessage = new UserMessage("ChatGLM3有哪些模型?");
// 3. 模拟查询得到的数据
Map<Query, Collection<List<Content>>> queryToContents = new HashMap<>();
String str1 = """
ChatGLM3 是北京智谱华章科技有限公司和清华大学 KEG 实验室联合发布的对话预训练模型。
""";
String str2 = """
ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。
""";
String str3 = """
ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
""";
String str4 = """
除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。以上所有权重对学术研究完全开放 ,在填写 问卷 进行登记后亦允许免费商业使用
""";
queryToContents.put(new Query(chatMessage.singleText()), List.of(List.of(
new DefaultContent(str1), new DefaultContent(str2), new DefaultContent(str3), new DefaultContent(str4))));
// 4.调用ReRankingContentAggregator进行重新排序
ReRankingContentAggregator aggregator = new ReRankingContentAggregator(JinaScoringModel.builder().apiKey(apiKey).modelName("jina-reranker-v3").build());
// 5. 输出结果
List<Content> results = aggregator.aggregate(queryToContents);
System.out.println("========重排结果=========");
for(Content content : results){
System.out.println(content);
}
ContentInjector contentInjector = DefaultContentInjector.builder().build();
ChatMessage newChatMessage = contentInjector.inject(results, chatMessage);
System.out.println("========组装最后的query=========");
System.out.println(((UserMessage)newChatMessage).singleText());
}
}4)运行ContentAggregatorTest 测试,结果如下:

说明:可以看到,其文档的顺序进行了重排,并最终输出组装后的结果。
2 与Spring AI的比较
到这里,关于Langchain的RAG功能就讲得差不多,虽然后面还会做一个综合示例。不过在这里就可以跟前面的Spring AI系列《Spring AI 系列之九 - RAG-入门》做一下比较:
- 使用:RAG主要的两个模块Indexing和Retrieval,在Spring AI中叫ETL和Retrieval,但无论怎么叫,其RAG的流程基本上一致。在细节上面比如RAG的Query Transformer只能是一个转换,而Spring AI的QueryTransformer则可以支持多个的链路式转换。因此在实现的细节上Spring AI 更优。
- 生态:在文档处理方面,则是Langchain4j更为丰富一下,比如支持的文档分割就比Spring AI多。因此生态这方面Langchain4J更优
结语:本章讲述了Langchain4j的RAG模块中,关于Retrieval的所有功能,并通过几个示例演示如何使用这些内容。可见Langchain4j已经很好给封装了RAG模块的流程,并提供诸多可扩展的接口供自定义流程。下一章将通过一个综合示例,对RAG进行一次总结演示
Langchain4j 系列上一章:《Langchain4j 系列之十八 - RAG之Indexing》
Langchain4j 系列下一章:《Langchain4j 系列之二十 - RAG综合案例》