More Images, More Problems? A Controlled Analysis of VLM Failure Modes
Authors: Anurag Das, Adrian Bulat, Alberto Baldrati, Ioannis Maniadis Metaxas, Bernt Schiele, Georgios Tzimiropoulos, Brais Martinez
Deep-Dive Summary:
更多图片,更多问题?对VLM故障模式的受控分析。
Anurag Das ( 1 ∗ ^{1*} 1∗) , Adrian Bulat ( 2 , 3 ^{2,3} 2,3) , Alberto Baldrati ( 2 ^{2} 2) , Ioannis Maniadis Metaxas ( 2 ^{2} 2) Bernt Schiele ( 1 ^{1} 1) , Georgios Tzimiropoulos ( 2 , 4 ^{2,4} 2,4) , Brais Martinez ( 2 ^{2} 2)
( 1 ^{1} 1) 马克斯普朗克信息学研究所,萨尔兰信息学园区
( 2 ^{2} 2) 三星人工智能,剑桥
( 3 ^{3} 3) 罗马尼亚雅西技术大学
( 4 ^{4} 4) 伦敦玛丽女王大学,英国
# 摘要
大型视觉语言模型(LVLM)展现出卓越的能力,但它们在理解和推理多张图片方面的熟练程度在很大程度上仍未被探索。尽管现有基准已经开始评估多图像模型,但对其核心弱点及其原因的全面分析仍然缺乏。在这项工作中,我们引入了 MIMIC(Multi-Image Model Insights and Challenges),这是一个新基准,旨在严格评估 LVLM 的多图像能力。利用 MIMIC,我们进行了一系列诊断实验,揭示了普遍存在的问题:LVLM 常常无法聚合跨图片的信息,并且难以同时跟踪或关注多个概念。为了解决这些失败,我们提出了两种新颖的互补补救措施。在数据方面,我们提出了一种程序化数据生成策略,将单图像标注组合成丰富、有针对性的多图像训练示例。在优化方面,我们分析了逐层注意力模式,并推导出了专为多图像输入定制的注意力遮罩方案。实验显著改善了跨图像聚合,同时提高了现有多图像基准的性能,在各项任务中均超越了以往的最新技术。数据和代码将在 https://github.com/anurag-198/MIMIC 上提供。
# 1 引言
当前的大型视觉语言模型(LVLM)展现了令人印象深刻的视觉语言理解能力。这些模型大多建立在预训练的视觉编码器和大型语言模型(LLM)之上。虽然早期的工作主要关注单张图片,但最近的研究已通过整合时间建模和调整位置嵌入(如 Li 等人,2024a;Wang 等人,2024b;Chen 等人,2023)将它们扩展到支持多张图片和视频。
尽管取得了成功,LVLMs 仍面临严峻挑战。识别和解决这些挑战的进展可以沿着两条主要途径进行:开发全面的评估基准,以及研究模型内部工作原理。迄今为止,这两个领域的研究主要集中在单图像设置。虽然早期努力已引入了多图像场景的基准,但仍缺乏全面、深入的分析来确定这些模型的真实效能并识别其局限性的根本原因。
在这项工作中,我们通过对多图像上下文中的 LVLMs 进行系统研究来解决这一空白。我们首先使用新提出的基准分析并表征常见的故障模式,然后寻求使用两种新颖的互补微调策略来缓解这些限制。我们的深入分析在新引入的 MIMIC(Multi-Image Model Insights and Challenges)基准上进行。MIMIC 基于 MSCOCO 构建,利用其边界框和类标签,通过利用每图像标注以程序化方式生成多图像序列,从而对信息传播、干扰项存在、对象实例分布、序列长度和查询复杂性进行细粒度控制,同时提供明确的真实答案,以便对模型的优缺点进行稳健、去相关分析。通过定量和定性评估,我们的研究揭示,当前最先进的 LVLMs 难以有效聚合多图像信息,无法同时跟踪/关注多个概念,同时易受干扰项影响。我们将这些缺点归因于多种因素,包括多图像序列建模的局限性、训练数据偏差、因因果注意力引起的图像间通信不良以及多图像推理任务固有的复杂性。
最后,为解决已识别的问题,我们提出了两种新的微调策略:(1) 一种以数据为中心的方法,生成有针对性的多图像训练示例,以提供源自 OpenImages 的丰富多图像监督;(2) 一种以优化为中心的方法,利用逐层注意力分析推导出专为多图像输入定制的注意力遮罩方案。我们提出的微调策略在所有场景中都带来了显著的性能提升。
总之,我们的主要贡献是:
我们引入了 MIMIC,这是一个用于多图像 LVLMs 的综合评估框架,通过受控和多样化的任务集来探究模型性能的各个方面。我们使用 MIMIC 对几种最先进的 LVLMs 进行了广泛评估,揭示了它们在多图像设置中的能力和局限性的关键见解。我们提出了一种新颖的以数据为中心的微调方法,利用合成生成的多图像数据,同时提出了一种以优化为中心的注意力遮罩策略,两者都显著提高了模型在多图像上下文中的性能。我们在现有多图像基准上取得了新的最先进结果,证明了我们所提出方法的有效性。
# 2 相关工作
# 多图像大型视觉语言模型:
早期的 LVLM,如 Flamingo 和 PaLM-E,开创了将预训练视觉编码器与强大的 LLM 结合用于 VQA 和图像描述的先河。随后的模型引入了扩展的指令微调和多模态预训练技术。最近的进展包括 MiniGPT-5、Qwen2-VL、CogVLM2 和 InternVL3,它们通过扩大训练数据和模型容量,并采用更复杂的架构设计,进一步推动了该领域的发展。虽然早期的 LVLM 主要处理低分辨率的单图像输入,但后来的研究显著扩展了它们的范围。高分辨率图像通常通过将其分割成固定分辨率的块并将其视为图像序列来处理,而视频则通过从多图像输入中提取帧来表示。此外,模型已开始明确支持多图像上下文,从而能够跨多个视觉输入进行推理。多图像能力是通过在多图像指令微调数据上对单图像 LVLM 进行微调引入的,同时在很大程度上保留了原始模型架构和注意力机制。
LVLM 的评估:早期的评估工作集中在狭窄的领域,基准包括 MS-COCO、VQA、DocVQA、GQA 和 AI2D,主要评估单图像理解,并使用模板化问题,多样性有限。后来的工作引入了更全面的基准来评估更广泛的技能,例如 SEED-Bench、MMBench 和 MME,这些基准具有多样的问题类型并需要复杂的推理能力。同样,视频基准,如 MMVU 和 VideoMME,要求模型理解时间动态并跨多个帧进行推理。
与我们的工作更接近的是,已有一些专门针对多图像 LVLMs 提出的基准。MuirBench 引入了 12 个评估多图像理解的任务,包括图像比较和多图像推理。Blink 包含了 14 个对人类来说"容易"的任务,强调了 LVLMs 在真正理解多图像视觉内容方面的局限性。Visual Haystack 侧重于基于检索的任务,评估模型在长序列图像中查找特定概念的能力。
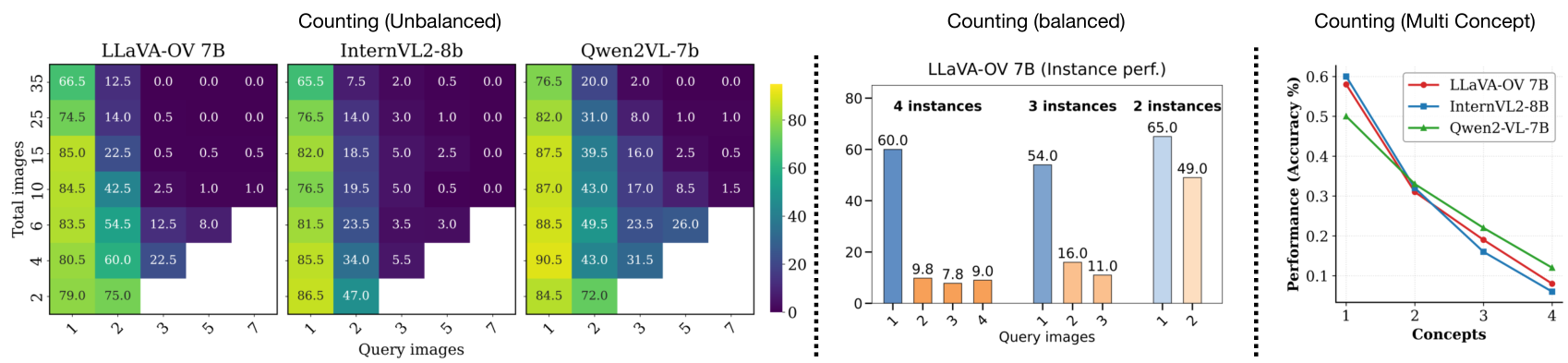
图 1:不同设置下的计数性能。左侧(不平衡):我们通过分析查询图像数量与图像总数(不控制实例数量)之间的权衡来比较不同的 LVLM。中间(平衡):我们将图像总数固定为 7,并将分布在查询图像中的对象实例总数固定为 4、3 和 2。在这两种设置中,当实例分散在多张图像中时,性能都会持续下降。右侧(多概念):我们通过在计数任务中添加更多类别(概念)来增加复杂性,并观察到性能急剧下降,表明多概念跟踪能力有限。
相反,我们提供了对模型性能在各种受控维度(如信息分布、查询复杂性和干扰物存在)上的更细粒度分析。此外,虽然以前的工作经常重新利用现有数据集,但我们从头开始设计任务,以实现选择性性能探索。这使我们能够精确找出当前模型中以前基准可能忽略的特定优点和缺点,并且重要的是,提供关于其根本原因的更深入可操作的见解。
LVLM 的分析:与基准的开发并行,人们对分析 LVLM 的内部机制越来越感兴趣,以更好地从数据和架构层面找出其局限性的根本原因。当前的研究已调查了幻觉、模态偏差和对输入措辞的敏感性等问题。这些工作通常涉及使用精心设计的输入来探测模型,以揭示其决策过程。直到最近,此类分析才扩展到多图像 LVLM。与我们的工作最接近的是 Wu 等人(Wu 等人,2025)的研究,该研究检查了多图像 LVLM 的检索能力随序列长度增加而变化的情况,表明在处理长序列时存在局限性。然而,他们的重点主要在于模型在图像集中定位特定项目的能力,并未控制混杂因素,也未寻求识别除数据稀缺之外的根本原因。
相反,我们系统地探究了多图像理解的额外维度,例如信息聚合和多概念跟踪。为了控制混杂因素,我们的评估旨在隔离多图像理解的特定单元方面,从而得出精确的结论并确定改进领域。此外,我们分析了内部模型的行为,并通过提出在数据和优化层面解决已识别挑战的解决方案来补充我们的分析。
3 多图像 LVLM 中的挑战与见解
在此,我们系统地研究了当前 LVLM 在多图像场景中的局限性,从六个互补维度进行分析:信息分布、查询复杂性、推理模式、对视觉干扰项的鲁棒性、随图像数量的扩展性以及多概念跟踪。为此,我们引入了 MIMIC,这是一个从 MSCOCO(Lin 等人,2014)的精选子集合成的受控测试平台。MIMIC 利用手动标注的边界框和标签,生成多图像序列,从而能够精确控制信息传播、干扰项存在、对象实例分布和序列长度。这种设计使得对模型行为进行去相关、细粒度分析成为可能。除了这些维度,我们的框架还审视了模型聚合和推理分布式视觉信息的机制。通过这种受控分析,我们旨在隔离具体的局限性,并为下一代视觉理解模型提供可操作的见解。
第 3.1 节描述了我们探测基准的任务设计和数据集构建。

图 2:MIMIC 基准:每个任务的示例。
第 3.2 节描述了对几个最先进的 LVLM 进行系统探测,以揭示它们在多图像理解方面的优点和局限性。
表 1:MIMIC 基准每个任务的统计数据。计数设置:平衡(Bal)和不平衡(Unbal)。
| 计数 | 通用 | 异类 | 列表 | 总计 | |||
|---|---|---|---|---|---|---|---|
| 平衡 | 不平衡 | ||||||
| 查询 | 5000 | 5800 | 1000 | 1000 | 1000 | 13800 | |
| 图像 | 5370 | 3761 | 3842 | 3726 | 4137 | 13145 | |
| 每个查询对象实例 | 44.3 | 132.1 | 26.1 | 20.7 | 27.9 | 77.0 | |
| 每个查询最小图像 | 7 | 2 | 3 | 4 | 2 | 2 | |
| 每个查询最大图像 | 7 | 35 | 8 | 6 | 8 | 35 | |
| 每个查询中位数图像 | 7.0 | 15.0 | 5.0 | 5.0 | 5.0 | 7 | |
| 每个问题平均单词 | 15.1 | 15.2 | 14.7 | 17.3 | 13.6 | 15.2 |
# 3.1 测试平台基准构建
我们通过程序化生成多图像、开放式问答任务来构建探测数据集,这些任务旨在针对跨图像推理的不同方面。为此,我们从 MS-COCO(Lin 等人,2014)中抽取了一个精选子集,通过过滤掉对象边界框小于图像 5 % 5\% 5% 的图像,以确保在常见的 LVLM 输入分辨率(例如 LLaVA-OV 的 384 × 384 p x 384 \times 384\mathrm{px} 384×384px)下具有视觉可识别性。为了最小化潜在类不平衡的影响,我们首先选择一个类池,然后从该池中进行采样,确保每个类以相同的概率被选择。这确保了在不同设置下类和实例的分布保持一致。
MIMIC 定义了四个核心任务:计数(Counting)、列表(Listing)、通用(Common)和异类(Odd-One),每个任务都针对多图像推理的一个独特方面。图 2 提供了一些定性示例,表 1 报告了数据集统计数据。所有任务都以开放式问答而非选择题的形式进行,以增加挑战性,避免固定选项集引入的捷径,并消除校准干扰项选择的需要。为了进一步减少提示偏差,我们为每个任务采用了多个模板化提示(参见附录获取模板列表)。下面,我们详细描述每个任务。
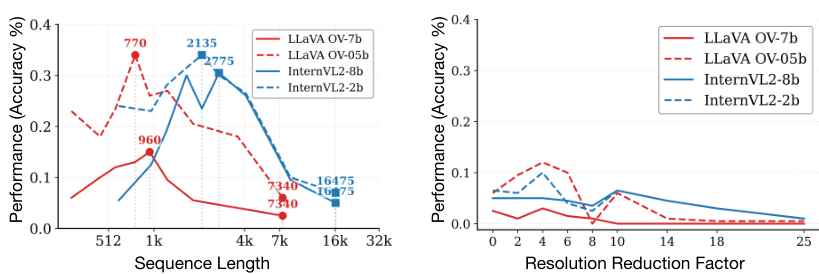
图 3:视觉 token 序列长度对性能的影响。左图:通过一维池化减少序列长度。方块表示原始序列长度。右图:通过像素空间池化减少信息,同时保持序列长度不变的对照实验。结果报告了使用 3 张查询图像和总共 10 张图像的计数任务。
计数(Counting):给定一组 N N N 张输入图像,以及包含 k k k 个对象类的查询,模型被要求计算每个类的实例总数。随着难度增加,我们改变对象实例在图像中的分布。例如,在最简单的设置中,所有实例可能集中在一张图像中,而在更具挑战性的情况下,实例分散在多张图像中。我们将其称为信息传播(information spread)。此外,我们引入了干扰项------不包含任何目标对象实例的图像------以评估模型关注相关信息的能力。总而言之,此任务提供以下可控维度:(1) 要计数的对象类数量 ( k k k);(2) 跨图像的信息传播 ( s s s);(3) 干扰图像的数量;(4) 图像总数。每个情况都探测不同的方面和潜在偏差。例如,增加对象类数量 k k k 考验模型的多概念跟踪能力,而改变信息传播则评估其跨图像聚合信息的能力。
为了解决自然图像中对象实例计数长尾分布可能导致模型偏爱较小计数的问题,我们设计了两种不同的设置:(1) 平衡(Balanced),其中对象实例总数固定,但分布在不同数量的图像中;(2) 不平衡(Unbalanced),其中对象实例总数随图像数量任意变化。选择的度量标准是二元准确率,即如果答案与真实计数完全匹配,则答案正确。
列表(Listing):向模型展示一组 N N N 张图像,并要求它列出所有属于给定类别(例如:动物、车辆等)的对象类,模型能够识别的。此任务评估模型从多张图像中密集地、穷尽地提取信息的能力。作为副产品,它还衡量了模型的视觉感知能力,即识别和分类多个对象的能力,以及将这些信息聚合为连贯列表的能力。与计数任务类似,我们改变图像数量和对象实例的分布,以评估模型在多图像理解中的鲁棒性。模型的响应根据列表的完整性和准确性进行评估,使用 F1 分数作为度量。有关对象类别和子类别的完整层次结构,请参阅附录。
通用(Common)和异类(Odd-One):这两个任务旨在评估模型识别多张图像中共享或独特元素的能力。重要的是,虽然之前的任务侧重于信息聚合,但这些任务需要跨图像进行比较推理,因此模型必须首先隐式识别所有对象,然后才能执行跨图像分析。在通用任务中,模型必须确定哪种对象类存在于所有提供的图像中,而在异类任务中,它必须识别存在于少数图像中的对象类。为简单起见,我们通过设计确保答案是唯一的。模型的答案根据其正确性进行评估,使用二元准确率作为度量。
3.2 经验分析
设置: 我们评估了几种最先进的LVLM模型:LLaVA-OV (Li et al., 2024a)、Qwen2-VL (Wang et al., 2024b) 和 InternVL2 (Chen et al., 2024b)。我们使用了公开可用的检查点,并遵循官方的数据处理流程。对于测试数据,我们使用了在3.1节中描述的MIMIC基准,并选择了最能隔离我们旨在探索的维度任务和配置。
性能与序列长度和图像数量的关系: LLMs已知会表现出位置和序列长度偏差 (Ravaut et al., 2024),序列中靠前和靠后的token会受到更多关注。与LLMs不同,我们区分了序列长度增长的两个轴:(1) 增加图像数量,以及 (2) 增加输入图像分辨率。我们试图理解性能下降是由于模型处理长序列的能力不足,还是处理多张图像的能力不足。我们通过以下实验来解开这两个因素:(a) 直接增加图像数量,而不明确控制序列长度。在这种设置下,我们简单地改变提供给模型的图像数量,并测量计数任务的性能。正如图1(左)的结果所示,当图像总数从2增加到35时,所有模型的性能在所有设置中都一致下降。(b) 通过对原始多图像视觉token应用一维平均池化来减少视觉token序列长度。为了确保观察到的行为不是信息减少的假象,我们还进行了一个对照实验,其中我们通过在像素空间中对图像进行降采样然后重新采样,来类似地减少信息量,然后再将其传递给视觉编码器。这保留了初始序列长度,但减少了模型可用的视觉信息量。这使我们能够评估在(a)中观察到的性能下降主要是由于序列长度增加还是图像数量增加。
结果总结在图3中。左侧,我们绘制了通过一维池化减少视觉token数量时不同模型的性能变化。由于处理方式不同,每个模型为每张图像分配的token数量不同,因此我们标记了两个点------最右侧(不降采样)和使性能最大化的中心点。右侧,我们展示了对照实验,该实验在不减少序列长度的情况下人为地减少了像素空间中的信息。令人惊讶的是,我们发现通过一维池化以零样本方式将序列长度减少高达 4 − 8 × 4-8\times 4−8× 可以显著提高所有模型的性能。对照实验证实,性能提升是由于序列长度减少而不是信息减少。这表明模型主要是在理解长序列方面遇到困难,而不是在处理多个不同的图像方面。
发现1:多图像场景中的性能下降主要源于序列长度的增加,而非图像数量的增加。
此外,我们观察到,对于LLaVA-OV,当视觉序列长度大约相当于一到两张图像(即,一张 384 × 384 384 \times 384 384×384 图像/patch的视觉token数量)时,性能达到峰值。这表明模型有效地依赖于单图像上下文,并且实际的多图像整合能力有限;我们稍后将评估有针对性的微调如何缓解这一限制。
发现2:当前的LVLM主要表现为单图像模型:当视觉token序列长度与一到两张图像产生的序列长度匹配时,性能达到峰值。
跨图像信息聚合: 先前的基准测试很少控制信息如何在图像之间分布,这使得很难确定模型是否能有效聚合跨图像信息。为此,我们改变了计数任务中的信息分布,这定义了对象实例如何在图像之间分布。在图1(左和中)中,我们展示了将包含对象实例的图像数量从1增加到7的结果。我们观察到,即使在存在极少干扰项的情况下,准确率也会急剧下降并接近于0。这种趋势在所有测试模型中都是一致的,并且在平衡和不平衡计数设置中均表现出来。这表明模型可能依赖捷径,例如只关注单个或极小的图像子集,而不是有效地整合所有提供的图像信息。
发现3:当前的LVLM难以聚合跨多张图像的信息。
对视觉干扰项的鲁棒性: 在实际场景中,模型经常会遇到不相关或干扰性的信息。为了评估LVLM的鲁棒性,我们在输入序列中引入了数量不等的无关图像。如图1(左)所示,随着干扰项数量的增加,准确率会下降(例如:对于LLaVA-OV,1个查询图像从 79.0 % 79.0\% 79.0% 下降到 66.5 % 66.5\% 66.5% (1个干扰项与34个干扰项),两个查询图像从 75.0 % 75.0\% 75.0% 下降到 12.5 % 12.5\% 12.5% 等)。当包含感兴趣对象的图像数量增加时,性能下降尤其明显,这表明干扰项加剧了模型在聚合跨多图像信息方面的现有困难。
发现4:模型对视觉干扰项敏感,尤其是当信息分散时。
多概念跟踪: 同时跟踪和关注多个概念的能力对于多图像理解至关重要。为了探究这种能力,我们改变了模型需要计数的对象类别数量 k k k。如图1(右)所示,随着 k k k 的增加,模型性能急剧下降,表明其同时处理多个概念的能力有限。
发现5:LVLM在多概念跟踪方面表现出有限的能力,降低了它们在复杂多对象查询中的可靠性。
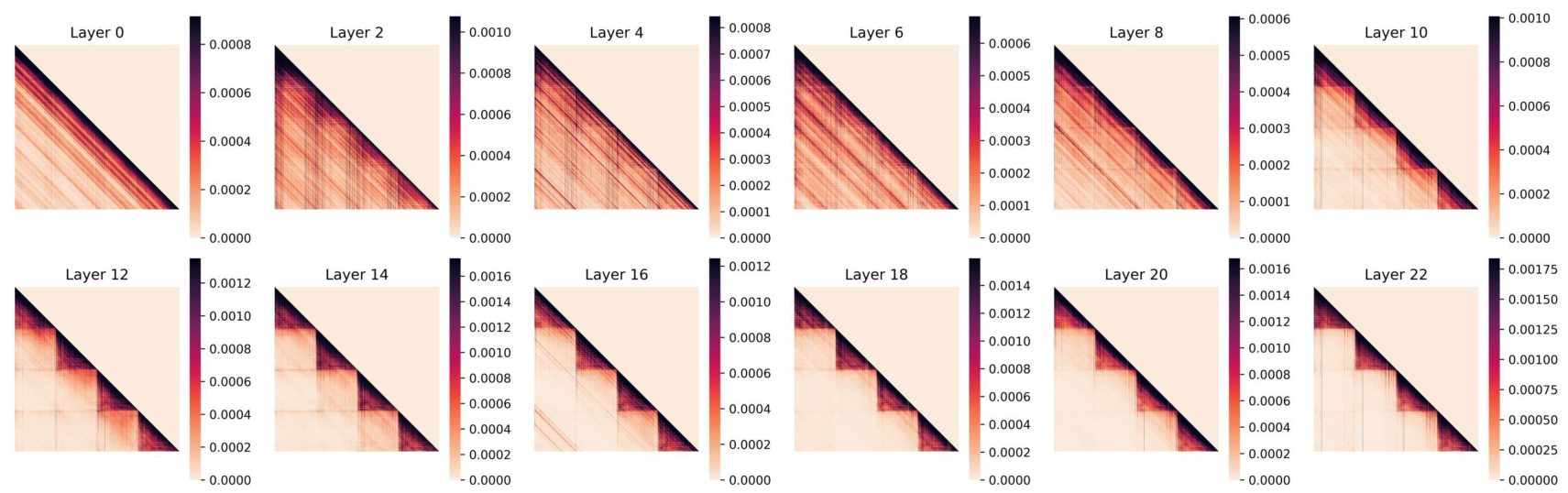
多图像交互: 为了探究视觉信息如何在token层面跨图像传播和整合,我们分析了多图像输入中视觉token之间的注意力模式。具体来说,我们计算了在50个样本子集上,每个视觉token对输入序列中所有其他视觉token的归一化注意力分数,并受到自回归注意力掩码的约束。图4总结了LLaVA-OV模型在多图像输入(包含4张图像)的几个感兴趣层的结果。我们发现:
Table 2: Performance comparison across different MuirBench (Wang et al., 2024a) subtasks. Ours (Masked): Our efficient model trained with LoRA and masked attention. Ours: Fully fine-tuned model. Due to computational constraints, we do not fully finetune LLaVA-7B model.
| Model | Geographic. | Counting | Action. | Grounding | Matching. | Ordering | Scene. | Difference. | Cartoon. | Diagram | Attribute. | Retrieval | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Random Choice | 25.0 | 21.0 | 23.4 | 25.0 | 24.1 | 22.8 | 25.0 | 23.2 | 25.0 | 29.6 | 20.0 | 21.3 | 24.0 |
| Human | 98.0 | 94.9 | 97.6 | 85.7 | 94.8 | 87.5 | 94.6 | 92.9 | 82.1 | 98.99 | 87.6 | 86.3 | 93.2 |
| GPT-4o (OpenAI, 2023) | 56.0 | 49.2 | 44.5 | 36.9 | 86.9 | 23.44 | 71.5 | 60.3 | 51.3 | 88.7 | 56.1 | 80.1 | 68.0 |
| Gemini Pro (Team et al., 2023) | 48.0 | 28.6 | 36.0 | 28.6 | 66.6 | 12.5 | 59.1 | 45.3 | 47.4 | 64.8 | 41.3 | 43.8 | 49.4 |
| Mantis-8b-Idfics2 (Jiang et al., 2024b) | 26.0 | 38.5 | 33.5 | 26.2 | 53.9 | 18.8 | 57.0 | 28.8 | 38.5 | 67.6 | 48.5 | 35.6 | 44.5 |
| Idfics-9B-Instruct (Laurençon et al., 2023) | 35.0 | 21.8 | 26.2 | 26.2 | 24.8 | 15.6 | 56.5 | 27.6 | 39.7 | 25.4 | 17.9 | 17.1 | 35.4 |
| Emu2-Chat(37B) (Sun et al., 2024) | 34.0 | 31.2 | 27.4 | 26.2 | 37.3 | 15.6 | 48.4 | 32.6 | 43.6 | 37.7 | 31.6 | 24.0 | 33.6 |
| VILA1.5-13B (Lin et al., 2024) | 31.0 | 19.7 | 28.7 | 25.0 | 40.9 | 10.9 | 56.5 | 24.7 | 30.8 | 42.7 | 24.5 | 30.1 | 33.1 |
| LLaVA-NeXT-34B (Liu et al., 2024b) | 12.0 | 36.3 | 26.2 | 33.3 | 37.9 | 21.9 | 54.3 | 22.1 | 41.0 | 38.2 | 38.3 | 25.0 | 33.3 |
| LLaVA-v1.5-7B (Liu et al., 2024a) | 20.0 | 23.1 | 27.4 | 14.3 | 23.5 | 23.4 | 35.0 | 20.0 | 24.4 | 25.1 | 23.0 | 19.9 | 23.5 |
| LLaVA-v1.5-13B (Liu et al., 2024a) | 20.0 | 25.2 | 29.3 | 14.3 | 20.3 | 20.3 | 36.6 | 20.0 | 25.6 | 31.7 | 23.0 | 20.9 | 24.4 |
| CogVLM (Wang et al., 2024c) | 13.0 | 14.1 | 26.2 | 16.7 | 21.3 | 12.5 | 41.4 | 19.7 | 41.0 | 19.6 | 16.3 | 15.8 | 20.9 |
| MiniGPT-4-v2 (Chen et al., 2023) | 13.0 | 12.0 | 14.0 | 25.0 | 17.0 | 18.8 | 14.5 | 20.0 | 21.8 | 21.6 | 17.4 | 14.7 | 17.4 |
| Qwen2-VL-7B (Wang et al., 2024b) | 12.0 | 38.9 | 42.7 | 28.5 | 57.5 | 10.9 | 75.3 | 32.9 | 38.5 | 49.2 | 46.4 | 26.7 | 43.0 |
| Qwen2-VL-2B (Wang et al., 2024b) | 14.0 | 27.8 | 35.4 | 26.2 | 34.3 | 10.9 | 51.1 | 19.4 | 39.7 | 21.4 | 31.1 | 15.4 | 27.2 |
| InternVL2-8B (Chen et al., 2024a) | 17.0 | 30.3 | 34.7 | 28.5 | 43.5 | 17.2 | 60.2 | 26.2 | 46.2 | 46.5 | 42.8 | 33.6 | 37.9 |
| InternVL2-2B (Chen et al., 2024a) | 17.0 | 21.8 | 26.8 | 26.2 | 31.7 | 10.9 | 52.2 | 17.4 | 35.9 | 21.6 | 16.8 | 13.7 | 24.3 |
| LLaVA-OV-0.5B (Li et al., 2024a) | 22.0 | 20.9 | 31.1 | 25.0 | 30.2 | 7.8 | 46.7 | 24.1 | 42.3 | 25.1 | 23.9 | 20.5 | 26.8 |
| Ours | 43.0 | 20.5 | 41.4 | 22.6 | 38.4 | 9.4 | 52.7 | 22.1 | 37.2 | 39.4 | 29.6 | 32.5 | 33.6 |
| Ours (Masked) | 31.0 | 17.5 | 40.8 | 33.3 | 37.3 | 14.1 | 53.8 | 21.5 | 42.3 | 34.9 | 28.1 | 32.9 | 32.5 |
| LLaVA-OV-7B (Li et al., 2024a) | 43.3 | 24.8 | 36.6 | 29.7 | 45.3 | 17.2 | 71.5 | 30.0 | 35.9 | 54.2 | 32.7 | 46.2 | 41.7 |
| Ours (Masked) | 44.0 | 35.9 | 51.2 | 42.9 | 59.9 | 12.5 | 71.0 | 43.5 | 38.5 | 62.1 | 52.0 | 48.6 | 51.3 |
在较早的层中,存在大量的图像间注意力,这表明模型正在尝试整合跨图像的信息。然而,随着我们进入更深层,注意力变得主要是图像内注意力。这个转折点大约发生在网络的中间部分。这种转变可能导致观察到的跨多图像信息聚合困难。从概念上讲,表征的构建过程似乎是从跨图像的广泛语义关联进展到更细粒度的、实例级别的整合。
这带来了一系列后果:(1) 早期图像间注意力可能会引入噪音或干扰,阻碍模型在后续层中关注相关信息;因此,早期跨图像交互中的错误更难纠正;(2) 在因果注意力机制下的跨图像交互可能导致错误传播,即属于后续图像的token会累积来自早期图像的错误信息,导致更多的噪音;这可能会降低模型对后续图像的视觉感知能力,并解释随着图像数量增加而出现的一些性能下降;(3) 架构和训练目标可能不足以鼓励跨图像整合,导致默认行为是独立处理图像;(4) 观察到的注意力模式可能反映了训练数据中固有的偏差,其中多图像任务不需要深层次的跨图像推理,导致模型学习优先处理单图像理解的捷径。
发现6:在LVLM的深层中,图像间注意力减弱,表明从跨图像整合转向了图像内关注。
4 方法
在上一节中,我们通过使用MIMIC基准进行零样本评估,确定了LVLM在多图像任务上的关键限制。在这里,我们研究了源于我们发现的、旨在提高多图像推理能力的有针对性的微调策略。具体来说,我们探索了两种互补的方法:一种是使用合成生成的多图像数据的数据中心微调策略,另一种是基于优化的注意力掩码策略。
多图像微调: 我们在统一的训练数据集上微调LLaVA-OV模型,该数据集由使用MIMIC管道(参见3.1节)程序化生成的样本以及原始的LLaVA-OV多图像指令微调数据(大约58万个样本)组成。与用于评估的MIMIC基准不同,我们的微调数据是从OpenImages构建的,并提供了明确的跨图像推理监督。它包含大约19.8万个样本,序列长度可达10张图像(参见附录),旨在使模型接触到更长的视觉token序列。所有四个MIMIC任务都被包含在内,以鼓励多样化的多图像推理行为。
注意力掩码: 我们的分析表明,图像间注意力在深层中减弱(参见图4)。受此启发,我们在微调期间应用了分层注意力掩码,限制视觉token在选定层中只关注来自同一图像的token,同时保持文本token注意力不变。这种设计提供了两个关键优势。首先,它减少了不必要的跨图像交互,从而产生了更高效的模型,降低了计算成本(参见附录中的表7和图7)。其次,它鼓励在深层中形成更清晰的图像局部表示,这在经验上提高了在多个基准测试上的性能。在这种设置下,我们采用基于LoRA的微调以进一步提高参数效率。有关实现细节,请参见附录。
Table 3: Comparisons on multi-image benchmarks: MuirBench, Blink, MMIU, MIRB, MMT, and NLVR2.
| Model | MuirBench | Blink | MMIU | MIRB | MMT (val) | NLVR2 | Avg. |
|---|---|---|---|---|---|---|---|
| GPT-4V | 62.3 | 54.6 | - | 53.1 | 64.3 | - | - |
| InternVL2-Llama3-76B | 51.2 | 56.8 | 44.2 | 58.2 | 67.4 | - | - |
| LLaVA-v1.5-7B | 20.0 | 37.1 | 19.2 | 28.5 | - | - | - |
| InternVL2-2B | 24.3 | 16.3 | 13.6 | 25.0 | 46.7 | 18.9 | 24.1 |
| InternVL2-8B | 37.9 | 23.4 | 36.8 | 48.6 | 57.9 | 8.7 | 35.6 |
| Qwen2VL-2B | 27.2 | 12.7 | 38.7 | 45.9 | 51.9 | 41.6 | 36.3 |
| Qwen2VL-7B | 43.0 | 17.7 | 52.6 | 60.8 | 61.7 | 41.5 | 46.2 |
| LLaVA-OV-0.5B | 26.8 | 40.4 | 34.2 | 31.8 | 41.1 | 61.2 | 39.3 |
| Ours | 33.6 | 38.9 | 37.2 | 32.8 | 45.6 | 68.0 | 42.7 |
| Ours (masked) | 32.5 | 39.1 | 36.3 | 28.5 | 45.9 | 65.1 | 41.2 |
| LLaVA-OV-7B | 41.7 | 50.4 | 45.0 | 47.2 | 56.6 | 84.2 | 54.2 |
| Ours (masked) | 51.3 | 51.9 | 45.5 | 51.0 | 55.3 | 87.3 | 57.1 |
Table 4: Comparisons on our benchmark. We report model's accuracy for Odd-one, Common and Counting whereas f1 score for listing benchmark.
| Model | Common | Counting | Odd-one | Listing | Avg. |
|---|---|---|---|---|---|
| Mantis-8B-llama3 (Jiang et al., 2024b) | 13.0 | 19.9 | 10.9 | 17.0 | 15.2 |
| InternVL2-2B (Chen et al., 2024a) | 25.6 | 11.7 | 9.6 | 19.6 | 16.6 |
| InternVL2-8B (Chen et al., 2024a) | 45.2 | 18.9 | 30.2 | 29.8 | 31.0 |
| Qwen2VL-2B (Wang et al., 2024b) | 41.9 | 21.7 | 30.2 | 23.8 | 29.4 |
| Qwen2VL-7B (Wang et al., 2024b) | 58.6 | 35.7 | 35.9 | 23.4 | 38.4 |
| LLaVA-OV-0.5B (Li et al., 2024a) | 44.7 | 29.7 | 8.3 | 22.8 | 26.4 |
| Ours | 68.5 | 37.8 | 41.0 | 34.5 | 45.5 |
| Ours (masked) | 68.9 | 35.8 | 50.9 | 42.0 | 49.4 |
| LLaVA-OV-7B (Li et al., 2024a) | 71.5 | 29.7 | 58.1 | 56.6 | 54.0 |
| Ours (masked) | 75.5 | 51.2 | 72.1 | 55.0 | 63.8 |
5 结果
5.1 与最先进模型的比较
现有多图像基准测试: 我们首先在表2中报告了MuirBench (Wang et al., 2024a) 及其子任务的结果。在所有模型尺寸中,我们的方法始终优于相应的LLaVA-OV基线。值得注意的是,对于7B模型,我们的掩码注意力变体将总体分数从41.7提高到 51.3 % 51.3\% 51.3%。对于较小的0.5B变体,我们也观察到类似的趋势,表明改进在不同模型尺寸中是稳健的。有趣的是,我们的方法很好地推广到域外子任务,包括地理、动作和图表理解,这表明我们的数据构建策略教会模型多图像处理概念,而不是对象感知,后者我们认为在单图像训练阶段就已经发展起来。
接下来,我们将评估扩展到其他多图像基准测试,包括Blink (Fu et al., 2024b)、MMIU (Meng et al., 2024)、MIRB (Zhao et al., 2024)、MMT (Ying et al., 2024) 和NLVR2 (Suhr et al., 2019)。我们的方法在所有变体中均实现了持续改进。如表5所示,我们的掩码注意力微调策略即使在可训练参数很少的情况下,也比基线获得了显著的收益,在某些情况下甚至优于完全微调(例如,LLaVA-OV 0.5B)。
MMIC基准测试: 我们在表4中报告了结果。除非另有说明,计数子任务的所有结果均对应于平衡分割。我们的方法在所有四个任务上均显著优于LLaVA-OV。对于0.5B模型,平均分数从26.4提高到49.4;而对于7B模型,掩码微调将性能从54.0提高到63.8。在"共同点"和"找不同"任务上的收益最为显著,突显了信息聚合和跨图像多概念推理能力的提高。
5.2 消融研究和分析
跨任务泛化: 在此实验中,我们对单个子任务(例如,计数、共同点、找不同和列表)进行模型训练,以分析它们的互补作用并评估跨任务泛化。表5(左)显示了结果。我们观察到,在"共同点"任务上进行训练可以很好地泛化到"计数"和"列表"任务,但不能泛化到"找不同"任务;在"找不同"任务上进行训练也观察到类似的趋势。这种行为是符合预期的,因为这两个任务在性质上是互补的:"共同点"需要聚合跨多张图像的信息,而"找不同"则强调在单张图像内定位独特的证据。"列表"任务的训练始终能提高所有其他任务的性能,而"计数"任务的训练主要有利于"找不同"任务。
效率分析: 表5(中)表明,我们的掩码注意力变体以显著降低的计算成本实现了卓越的性能,与普通注意力相比。在0.5B主干网络上,掩码微调将FLOPs减少了约 81 % 81\% 81%,同时优于完全微调。这证实了选择性地限制图像间注意力既有效又高效。有关FLOPs估算的详细信息,请参见附录。
注意力掩码策略: 表5(右)展示了注意力掩码应用于哪些层的消融研究。仅对深层(12-23层)进行掩码操作可获得最佳性能,而对早期层进行掩码操作则会显著降低准确率。这些结果表明,早期层对于有效的跨图像信息聚合至关重要。
定性分析: 图5可视化了"计数"示例的"答案-到-图像"注意力。基线模型未能关注第三张图像中的相关对象,导致计数不正确。相比之下,我们的模型在所有图像中都表现出平衡且语义上合理的注意力,从而导致了正确的预测。这一定性证据证实了我们的定量改进。

Figure 5: Answer-to-Image Attention: The baseline LLaVA OV (top row) fails to attend to the potted plant in the third image, whereas our method (bottom row) correctly focuses on the relevant object. Visualization is shown at the 15th layer of the LLM.
| Layers masked | Comm. | Count. | Odd. | List. | Avg. |
|---|---|---|---|---|---|
| No mask. | 70.0 | 32.0 | 37.9 | 44.5 | 46.1 |
| 0-23 | 64.5 | 36.1 | 20.9 | 29.2 | 37.7 |
| 0-11 | 62.5 | 27.3 | 28.8 | 33.6 | 38.1 |
| 12-23 | 68.9 | 35.8 | 50.9 | 42.0 | 49.4 |
6 结论
我们通过MIMIC,一个旨在隔离特定单元行为的新型基准,系统地研究了LVLM在多图像上下文中的能力。我们的分析揭示,当前最先进的模型本质上表现出"单图像行为",难以聚合跨输入的信息或在存在视觉干扰项的情况下跟踪多个概念。为了解决这个问题,我们引入了一种以数据为中心的合成微调策略和一种以优化为中心的注意力掩码机制。这些贡献不仅解决了关键的失败模式,还建立了新的最先进结果,为未来多图像理解研究奠定了坚实的基础。
7 局限性
尽管我们的工作为多图像LVLM提供了严谨的分析和有效的解决方案,但我们注意到本研究的以下边界:
- 基准领域: 我们使用MS-COCO构建了MIMIC,以保持对混淆变量(例如,物体数量、遮挡水平)的精确控制。虽然这种设计能够对模型推理进行精确的"单元测试",但将这种受控方法扩展到专业领域(如密集文档或医学影像)仍然是未来研究的一个令人兴奋的方向。
- 分辨率权衡: 我们的分析表明,减少序列长度通过缓解上下文过载来改善多图像推理。虽然对于语义理解和计数非常有效,但需要对极小细节进行像素级感知的任务可能受益于自适应分辨率策略,这不在本研究的范围之内。
- 架构范围: 我们提出的分析侧重于开源权重模型。虽然我们预计结论也适用于闭源模型,但额外的验证(这会带来预算限制)可能有助于强化我们的发现。
Original Abstract: Large Vision Language Models (LVLMs) have demonstrated remarkable capabilities, yet their proficiency in understanding and reasoning over multiple images remains largely unexplored. While existing benchmarks have initiated the evaluation of multi-image models, a comprehensive analysis of their core weaknesses and their causes is still lacking. In this work, we introduce MIMIC (Multi-Image Model Insights and Challenges), a new benchmark designed to rigorously evaluate the multi-image capabilities of LVLMs. Using MIMIC, we conduct a series of diagnostic experiments that reveal pervasive issues: LVLMs often fail to aggregate information across images and struggle to track or attend to multiple concepts simultaneously. To address these failures, we propose two novel complementary remedies. On the data side, we present a procedural data-generation strategy that composes single-image annotations into rich, targeted multi-image training examples. On the optimization side, we analyze layer-wise attention patterns and derive an attention-masking scheme tailored for multi-image inputs. Experiments substantially improved cross-image aggregation, while also enhancing performance on existing multi-image benchmarks, outperforming prior state of the art across tasks. Data and code will be made available at https://github.com/anurag-198/MIMIC.
PDF Link: 2601.07812v1
部分平台可能图片显示异常,请以我的博客内容为准
