Google 在 2025 年 6 月推出 Gemma 3n 时,技术圈的反响截然两极。
工程团队为其在移动端的极致轻量化折服------2GB 内存即可运行 80 亿参数模型,多模态推理流畅如常;而学术界却对 PLE(Per-Layer Embeddings)与 AltUp 等非传统设计心存疑虑,视其为为适配硬件而强行压缩的工程捷径。
直到半年后,2026 年 1 月,DeepSeek 连续发布 mHC与 Engram两篇奠基性论文。
深入剖析其核心------U 型 Scaling Law 与流形约束(Manifold Constraints)------我们清晰看到:
DeepSeek 通过数学推导得出的最优架构范式,竟与 Google 半年前凭直觉构建的 Gemma 3n 形成惊人共振。
Gemma 3n 的 PLE,其本质正是 DeepSeek 在 Engram 中证明高效的"条件记忆"机制:将静态知识嵌入低维可查表结构,剥离推理负担;
Gemma 3n 的 AltUp,则在实现层面构成了 mHC 理论中"宽残差流稀疏扩展"的一个具体实例:以非对称参数更新策略,在不增加显存开销的前提下,稳定扩展信息通路。
这绝非偶然的趋同,而是架构演进的必然交汇。DeepSeek 的理论,为 Gemma 3n 的工程选择提供了前所未有的数学合法性。
Google 用直觉踩中了最优解的脉搏,而 DeepSeek 用公式还原了它的证明。
本文将以 DeepSeek 的新理论为透镜,解构 Gemma 3n 的黑箱设计,揭示两个顶尖团队如何在不同时间、不同路径上,共同开辟了大模型架构的第三条道路------一条不依赖纯参数堆砌,而以"记忆分离"与"约束稳定"为支柱的高效之路。
01.静态记忆的Scaling Law
Gemma 3n 架构中最引人争议的创新,体现在其 Embedding 的实现机制上。
与传统 Transformer 仅在输入与输出端部署 Embedding 的设计不同,Gemma 3n 为每一层都配置了独立的静态 Embedding 表(本文将这一特性命名为 PLE,Per-Layer Embeddings)。
据 Google 的工程阐释,此举旨在协同 NPU/CPU 的异构计算能力,借助 Conditional parameter loading 技术,将超过 2B 的 PLE 参数动态卸载至系统内存,从而确保核心的 MLP 与 Attention 模块始终在 NPU 上保持高效运行。

图1. Gemma 3n 的参数分布与有效内存负载对比。
该图所示数据表明,借助 PLE 技术,模型能够将绝大部分参数迁移至系统内存,仅在计算单元中保留关键参数,从而达成卓越的参数利用效率。
DeepSeek 的 Engram 论文不仅以实证验证了该架构可显著降低内存开销,更通过结构清晰的图示,系统性地阐明了其背后的理论原型。
1.1 机理还原
Engram 不是传统意义上的 N-gram 统计表,而是一个具备可微分特性的神经模块。
DeepSeek 在论文开篇即提出其核心思想:对经典的 N-gram 查表机制进行神经化重构,使其能够作为条件记忆(Conditional Memory)无缝嵌入深度神经网络架构之中。
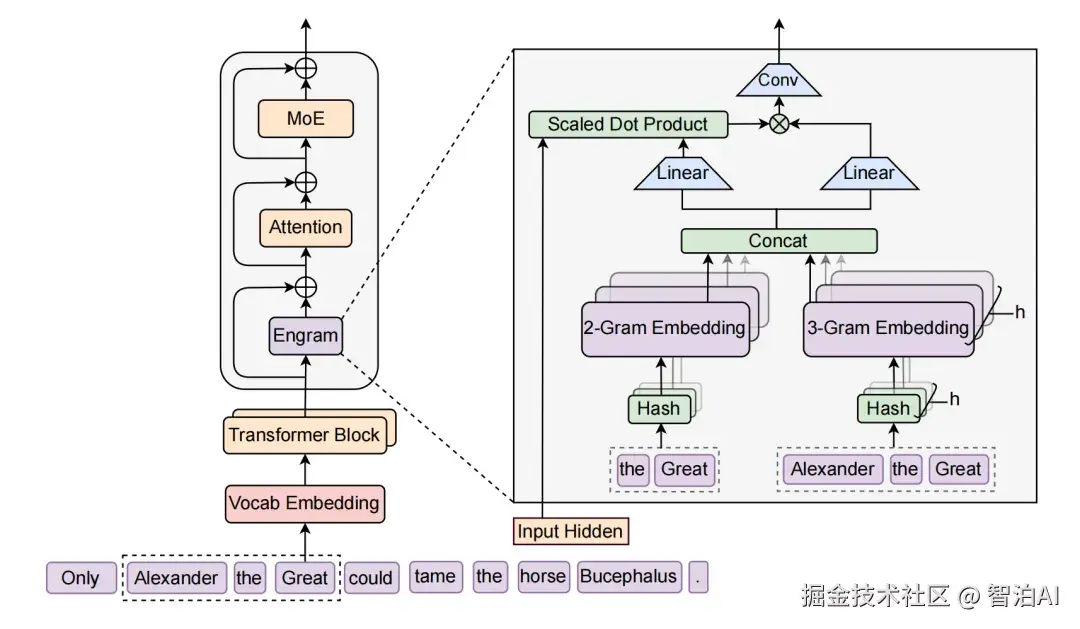
图2. Engram 的概念模型。它展示了如何将离散的 N-gram 统计信息转化为可微的 Embedding 查找操作,从而弥补 Transformer 在知识检索上的短板。


图3. Engram 模块的集成架构示意图。左侧为标准 Transformer 层(计算),右侧为 Engram 模块(存储)。
通过简单的查表(Lookup)和投影(Projection),静态记忆被无缝融入到神经网络的隐状态流中。这正是 Gemma 3n PLE 机制的数学解剖图。
1.2 寻找 Loss 的最低点:U 型曲线
在把握架构本质后,DeepSeek 进一步凝练出 Sparsity Allocation(稀疏分配)这一核心议题。
基于海量实验,DeepSeek 揭示:当模型总参数规模恒定时,静态记忆参数(Engram/PLE)与动态计算参数(MLP/Attention)之间的配比,成为左右模型表现的关键因子。
观测到的验证集 Loss 曲线,清晰呈现出典型的 U 型 Scaling Law,随静态参数比例上升而先降后升。
量化结果指出,最优静态参数占比并非零值,而是稳定收敛于 10% -- 30% 区间内(具体数值依总参数量而异)。
由此可得:将相当可观的参数资源投向"死记硬背"(查表)机制,非但未造成浪费,反而有效腾挪出神经网络的计算资源,使其更专注应对高阶逻辑推理任务。
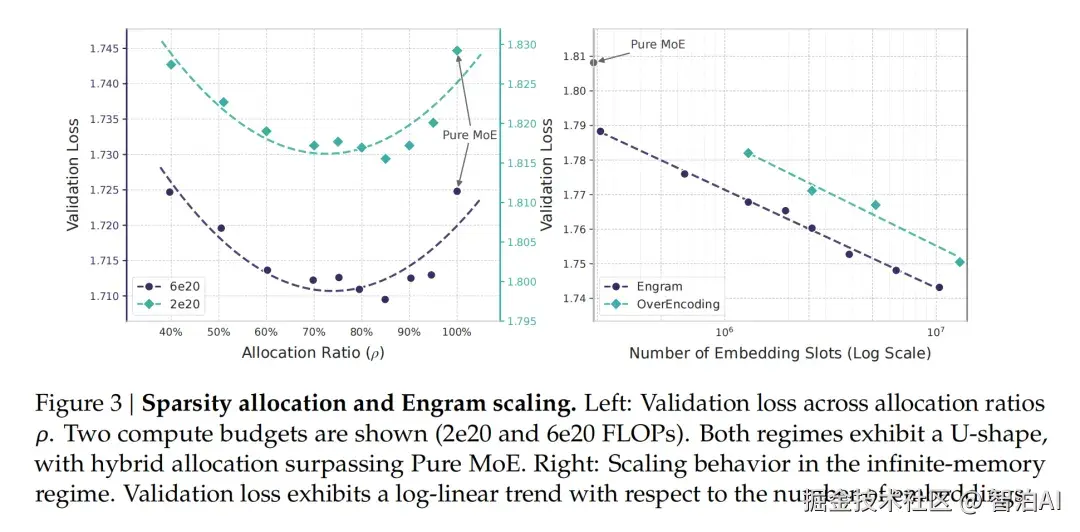
图4. 横轴为 Engram(静态参数)占比,纵轴为 Validation Loss。
可以看到曲线呈现清晰的 U 型,最低点并非纯 MLP 模型,而是混合架构。这从理论上背书了 Gemma 3n 分配大量参数给 PLE 的合理性。
1.3 层级化是关键
Gemma 3n 的 PLE 以分层挂载(Per-Layer)为核心设计,这一架构选择并非随意,而是源于 DeepSeek 在 Engram 论文中揭示的深层规律:他们不仅验证了可行性,更明确了实现的必要路径。
在 Engram 的消融实验中,插入位置被证明是性能的关键变量:
若将查表机制仅置于 Input Layer(Layer 0),如同传统 N-gram 模型那样,模型尚缺乏充分的语义上下文支撑有效门控(Gating),因而对整体性能的增益几乎可以忽略。
唯有将 Engram 置于网络中间层,借助深层架构所构建的 Context 来引导静态知识的精准检索与动态融合,方能显著压低 PPL(困惑度)。
这正是 Gemma 3n 必须将 PLE 复杂化、并分散部署于每一个 Transformer Block 的根本原因。
从计算机制上看,DeepSeek 强调 Engram 的本质优势在于上下文感知门控(Context-aware Gating)。
其采用了一种高效率的对数概率融合策略:直接将 Engram 查表所得的 Logits,经由门控权重加权后,线性叠加至神经网络输出的 Logits 上。
该设计彻底规避了繁琐的概率插值运算,与 Gemma 3n 在推理阶段"并行计算神经网络、实时查表、最终加权融合"的工程实践高度一致。

图5. Engram 门控机制的可视化。红色区域表示门控激活,意味着模型在处理特定词组(如实体名)时,会高度依赖静态记忆表的查表结果,而非神经网络的推理
02.宽度的边界
除了记忆之外,Gemma 3n 的另一显著特征是其"宽"性。为实现端侧的并行加速,业界普遍推测其采用了类似 AltUp (Alternating Updates) 的机制以拓展模型宽度。
尽管 DeepSeek 的 mHC 论文聚焦于更普适的超宽网络训练议题,其理论框架却精准刻画了 Gemma 3n 宽架构所遵循的设计边界。
2.1 什么是宽网络及其代价?
DeepSeek 在论文开篇定义了 Hyper-Connections (HC),这是一种打破传统残差网络(ResNet)宽度限制的架构。
通过极大地扩展残差流的宽度,模型可以获得极高的并行处理能力和容量。

图6. Hyper-Connections (HC) 架构与传统残差连接的对比。
HC 通过大幅拓宽残差层的宽度以提升模型容量,这一策略与 Gemma 3n 致力于端侧并行计算的架构理念高度契合。
但 DeepSeek 揭示,该设计潜藏一项关键缺陷:当宽度过度扩张时,将扰动恒等映射(Identity Mapping)所依赖的方差稳定性。
若缺乏有效约束,深层网络中的信号方差将迅速膨胀,进而引发 Jacobian 矩阵奇异值分布的全面失衡。
下图清晰展示了这种崩塌现象。

图7. 左图显示普通宽网络随着深度增加,训练 Loss 和梯度迅速发散;右图显示引入流形约束(Manifold Constraint)后,模型训练保持稳定。
2.2 AltUp 的稀疏近似
面对"宽度扩展引发的训练崩塌"这一挑战,Google 在 AltUp 论文中提出了一种极具工程智慧的规避路径。
为同步缓解计算负担与训练不稳的双重困境,AltUp 引入了预测-校正(Predictor-Corrector)框架。
它并未直接执行超宽稠密矩阵的完整运算,而是将高维向量划分为若干 Block。在每轮推理中,先通过轻量预测模块锁定活跃 Block,再仅对这些子集进行实际计算。
这种刻意设计的稀疏性,在工程层面构成了对残差路径能量的物理约束,从而隐式抑制了方差爆炸。这正是"因算力受限而被迫精简,却意外达成稳定提升"的典型工程悖论式突破。
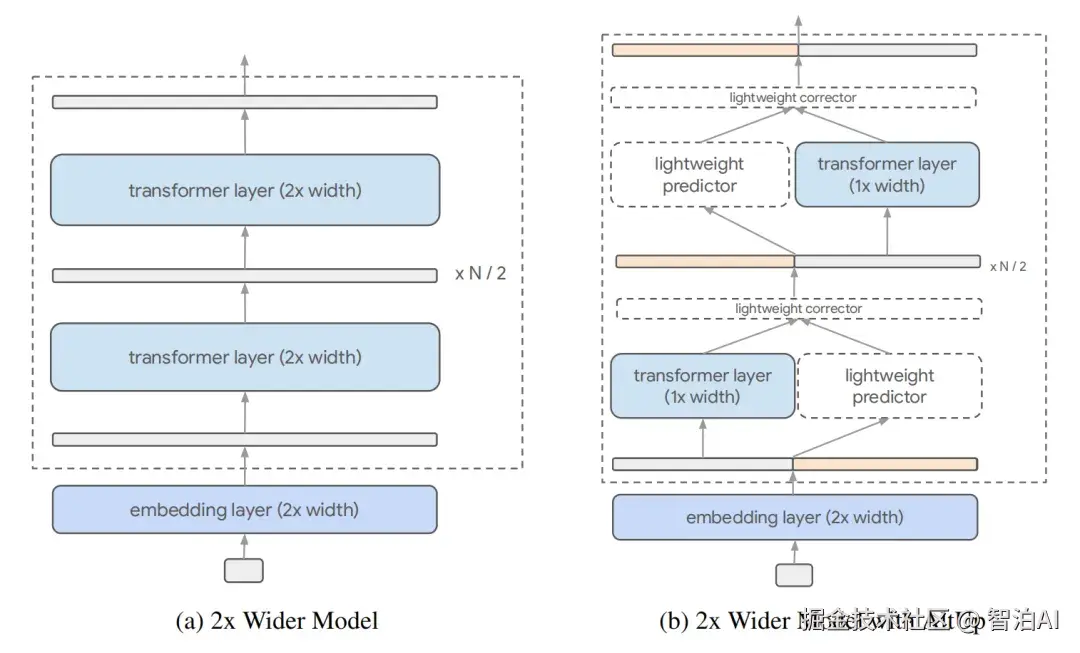
图8. AltUp 的 Predict-and-Compute 流程示意图。原本 d 维的宽向量被隐式操作,通过扩展算子(Up-projection)和稀疏修正来模拟宽网络的效果。
2.3 mHC 的流形约束
DeepSeek 主动迎向这一挑战。mHC 指出,若真欲训练稠密的超宽网络,势必要对权重矩阵施加流形约束。
其本质在于,将权重矩阵投影至 Stiefel 流形()或其它特定流形,以精准调控奇异值的分布形态。
在论文的方法论章节中,DeepSeek 对此过程进行了系统推演:每次参数更新后,均显式引入一步投影操作(如借助 Sinkhorn-Knopp 算法实施归一化),强制将权重矩阵拉回流形约束流形。
该机制主动重塑了权重矩阵的几何结构,使 Jacobian 矩阵的奇异值被约束于 1 附近,从根本上重建了宽网络的恒等映射能力,显著提升训练过程的收敛稳定性。
DeepSeek 的洞见极具前瞻视野:AltUp 实质上是"宽网络"框架下的一种稀疏变体,而 mHC 则构建了操控"宽网络"的普适数学范式。
未来,我们或可彻底摒弃 AltUp 所依赖的复杂稀疏掩码机制,转而直接训练出极宽、极浅、推理效率极高的主干网络。
03.弹性推理的终局
Gemma 3n 的核心技术收官之作,正是 MatFormer。
根据 Gemma 3n Model Overview 文档 ,Google 清晰揭示了其"套娃"架构:E4B 模型完整继承了 E2B 模型的所有参数。
这一架构的理论根基,源自 MatFormer 论文所提出的 Matryoshka(俄罗斯套娃)范式------在训练过程中,不再聚焦于单一规模的模型,而是协同优化一个包含多层次嵌套子模型的超网络。
MatFormer 的突破性贡献,在于对 Transformer Block 内部结构的重构:它引入了嵌套前馈网络(Nested FFN),使单个模块可动态适配不同参数规模,实现高效多粒度推理与训练。
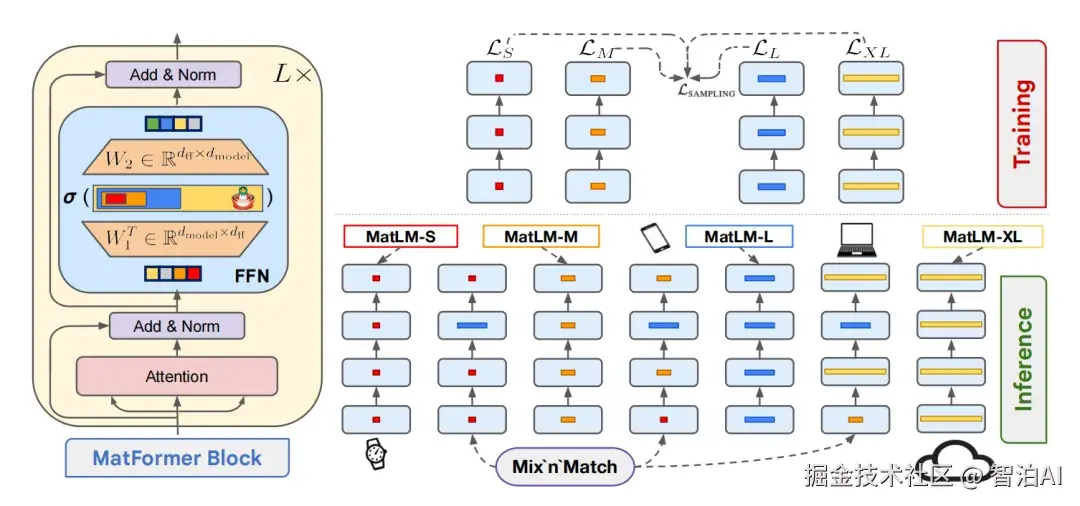
图9. MatFormer 的架构原理图。左侧展示了 MatFormer Block 内部的嵌套 FFN 设计,权重矩阵被物理划分为多个层级;右侧展示了训练和推理时的"Mix'n'Match"机制,即不同层级的小模型可以直接从大模型中提取出来使用。

为了让套娃结构中的每一层都能高效运作,MatFormer 在训练中设计了一种独特的联合优化策略。
训练过程中,系统会随机抽取不同的子模型,并针对每个被选中的子网络单独计算损失函数。这一机制的本质,是同步最小化所有嵌套子模型(Sub-models)的总体损失。
该训练范式迫使模型将最基础的通用表征压缩至核心参数区域(如前数百个神经元),而将高维细节信息分配至扩展参数维度。
这也正是 Gemma 3n 能够实现 "Select parameters and assemble models in intermediate sizes",并在 2B 至 4B 参数区间内达成平滑性能伸缩的根本原因。
DeepSeek 的 mHC、Engram 与 Google 的 Gemma 3n,虽诞生于不同阶段,却各自独立破解了端侧 AI 不可能三角的瓶颈。
容量(Capacity):DeepSeek mHC 通过流形约束,成功训练出超宽线性层,并结合 Google AltUp 的稀疏计算架构,化解了大容量需求与有限算力之间的冲突。
记忆(Memory):DeepSeek Engram 展现了静态查表机制的极致效率,协同 Google PLE 的显存卸载方案,突破了海量知识存储与有限显存的限制。
适应性(Adaptability):MatFormer 以嵌套权重结构与联合优化机制,实现了单一模型在异构硬件环境中的动态适配,弥合了模型统一性与硬件碎片化之间的鸿沟。
04.总结
DeepSeek mHC 与 Engram 的问世,为行业划下了一道清晰的分水岭:参数规模的无脑扩张,正逼近其边际收益的极限。
Google 于 2025 年在 Gemma 3n 上实证了"计算与存储分离"在工程落地层面的可行性;而 DeepSeek 在 2026 年初,则以严谨的数学推演揭示:这条路径不仅可行,更蕴含更高的运算效率。
二者异曲同工,共同指向一个趋势------端侧模型的架构正经历根本性重构。它将不再依附于封闭的端到端神经网络,而是蜕变为"逻辑核心(NPU)+ 静态知识库(RAM)"这一高度协同的精密系统。