从零理解 MoE(Mixture of Experts)混合专家:原理、数学、稀疏性、专家数量影响与手写 PyTorch 实现
这篇博客面向已经有一定 Transformer / FFN 基础的读者。
我们会从 MoE 的核心思想 出发,解释它为什么能在"大参数量"和"可控计算量"之间取得平衡;然后介绍它的数学形式、稀疏路由、负载均衡,以及 专家数量对预训练的影响;最后基于一份教学版 PyTorch 代码,逐模块拆解,并给出对应的小例子和完整代码。
目录
- [什么是 MoE(Mixture of Experts)](#什么是 MoE(Mixture of Experts))
- [MoE 的核心数学形式](#MoE 的核心数学形式)
- 什么是稀疏性(Sparsity)
- [Router / Gate 在做什么](#Router / Gate 在做什么)
- 负载均衡为什么重要
- 专家数量对预训练有何影响
- [教学版 Sparse MoE 代码拆解](#教学版 Sparse MoE 代码拆解)
- [模块 1:单个 Expert](#模块 1:单个 Expert)
- [模块 2:Top-K Router](#模块 2:Top-K Router)
- [模块 3:SparseMoE 主体](#模块 3:SparseMoE 主体)
- [模块 4:负载均衡损失](#模块 4:负载均衡损失)
- [模块 5:demo 测试入口](#模块 5:demo 测试入口)
- 完整代码
- [完整例子:一次 forward 到底发生了什么](#完整例子:一次 forward 到底发生了什么)
- [MoE 的优点、问题与工程注意点](#MoE 的优点、问题与工程注意点)
- 总结
什么是 MoE(Mixture of Experts)
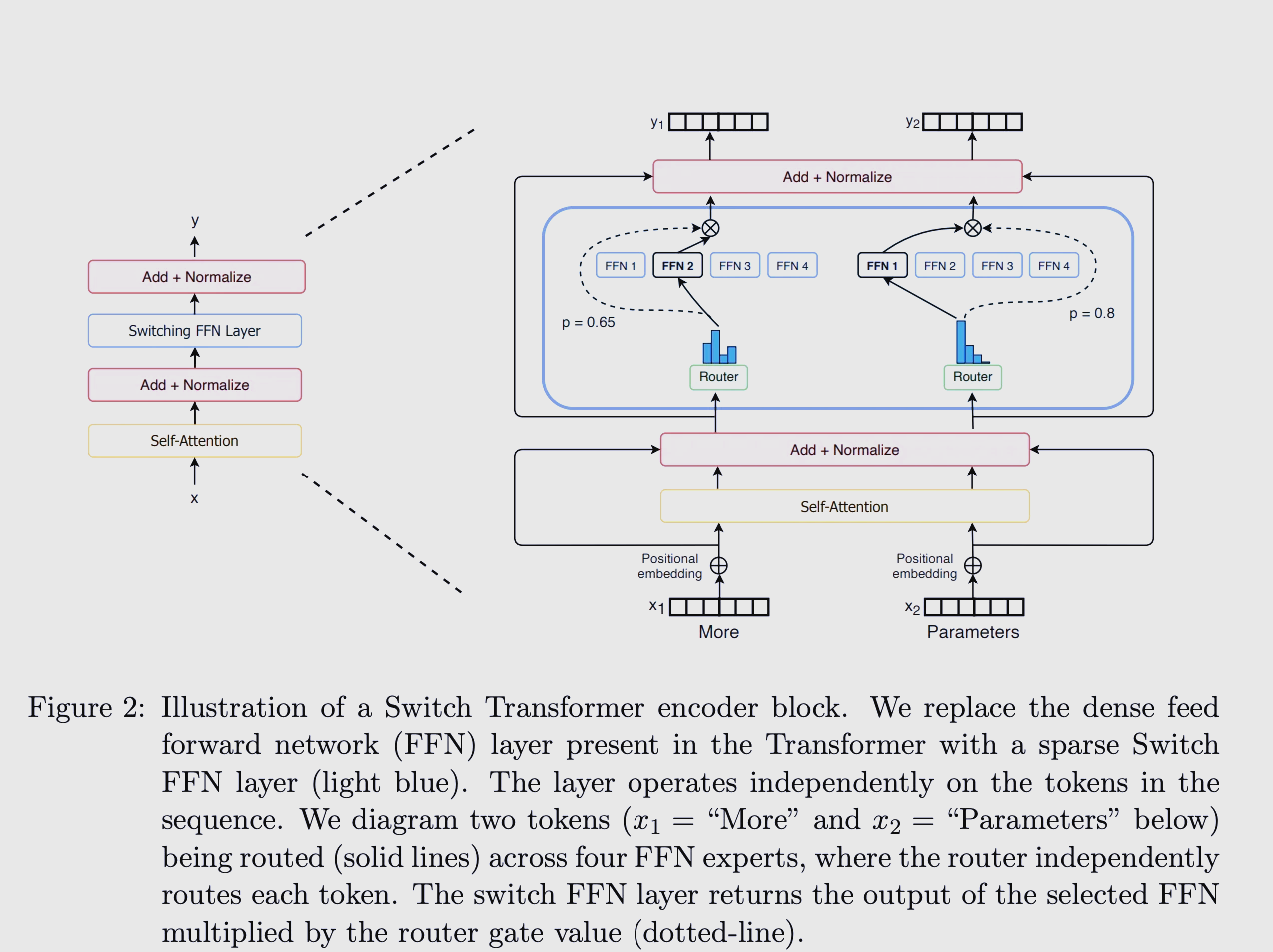
MoE,全称 Mixture of Experts,混合专家模型。
它的基本思想是:
- 不再让所有 token 都经过同一个 FFN;
- 而是准备多个"专家网络"(Experts);
- 对于每个 token,只激活其中少数几个 expert 来处理。
也就是说:
- 总参数量可以非常大,因为 expert 可以很多;
- 单次前向计算量不一定跟着线性变大,因为每个 token 只走 top-k 个 expert,而不是走全部 expert。
这和传统 Transformer 中的 FFN 不同:
- 传统 FFN:每个 token 都走同一个 MLP;
- MoE-FFN:每个 token 由路由器(Router)动态分给少量专家。
你可以把它想象成一个大型医院分诊系统:
- token 是病人;
- router 是分诊台;
- experts 是不同科室医生;
- 每个病人不需要看所有医生,只需要看最合适的几个。
MoE 的核心数学形式
先看最基本形式。
设输入 token 表示为:
x ∈ R d model x \in \mathbb{R}^{d_{\text{model}}} x∈Rdmodel
设有 N N N 个 expert:
E 1 , E 2 , ... , E N E_1, E_2, \dots, E_N E1,E2,...,EN
每个 expert 都是一个函数,通常是一个 FFN:
E i ( x ) E_i(x) Ei(x)
同时有一个 router,为每个 token 输出对各个 expert 的打分:
g ( x ) ∈ R N g(x) \in \mathbb{R}^{N} g(x)∈RN
经过 softmax 后得到概率分布:
p i ( x ) = exp ( g i ( x ) ) ∑ j = 1 N exp ( g j ( x ) ) p_i(x) = \frac{\exp(g_i(x))}{\sum_{j=1}^{N}\exp(g_j(x))} pi(x)=∑j=1Nexp(gj(x))exp(gi(x))
如果是 dense MoE,理论上可以写成:
y = ∑ i = 1 N p i ( x ) E i ( x ) y = \sum_{i=1}^{N} p_i(x)\,E_i(x) y=i=1∑Npi(x)Ei(x)
但这太贵,因为每个 token 都要跑完所有 expert。
稀疏 Top-K MoE
真正常用的是 稀疏路由 。
也就是只保留概率最高的前 k k k 个 expert。
记选出来的 expert 下标集合为:
TopK ( x ) \text{TopK}(x) TopK(x)
那么输出变成:
y = ∑ i ∈ TopK ( x ) p ~ i ( x ) E i ( x ) y = \sum_{i \in \text{TopK}(x)} \tilde{p}_i(x)\,E_i(x) y=i∈TopK(x)∑p~i(x)Ei(x)
其中 p ~ i ( x ) \tilde{p}_i(x) p~i(x) 是 只在 top-k 内重新归一化后的权重。
也就是说,原始 softmax 出来可能是:
0.48 , 0.11 , 0.12 , 0.29 \] \[0.48, 0.11, 0.12, 0.29\] \[0.48,0.11,0.12,0.29
如果取 top-2,对应 expert 0 和 expert 3,那么保留:
0.48 , 0.29 \] \[0.48, 0.29\] \[0.48,0.29
重新归一化后变成:
0.48 0.48 + 0.29 , 0.29 0.48 + 0.29 \] = \[ 0.623 , 0.377 \] \\left\[\\frac{0.48}{0.48+0.29}, \\frac{0.29}{0.48+0.29}\\right\] = \[0.623, 0.377\] \[0.48+0.290.48,0.48+0.290.29\]=\[0.623,0.377
这样最终只用两个 expert 的输出加权求和。
什么是稀疏性(Sparsity)
在 MoE 里,"稀疏性"通常指:
虽然系统里存在很多 expert,但每个 token 只激活其中极少数几个。
例如:
- 总共有 64 个 expert;
- 每个 token 只选 top-2 expert;
那么对于单个 token 来说,只有 2 个 expert 被激活,剩下 62 个 expert 完全不参与这个 token 的前向计算。
这就是稀疏。
稠密 vs 稀疏
稠密(Dense)
每个 token 都经过所有模块:
y = ∑ i = 1 N p i ( x ) E i ( x ) y = \sum_{i=1}^{N} p_i(x)E_i(x) y=i=1∑Npi(x)Ei(x)
特点:
- 计算量大;
- 所有 expert 都要算;
- 不适合大规模 expert 扩展。
稀疏(Sparse)
每个 token 只经过 top-k 个 expert:
y = ∑ i ∈ TopK ( x ) p ~ i ( x ) E i ( x ) y = \sum_{i \in \text{TopK}(x)} \tilde{p}_i(x)E_i(x) y=i∈TopK(x)∑p~i(x)Ei(x)
特点:
- 计算更省;
- 参数容量可以更大;
- 训练与并行更复杂。
为什么稀疏性重要
因为它带来了一个非常关键的性质:
参数量增长速度 > 单 token 计算量增长速度
这使得模型可以变得"很大",但不必让每个 token 的计算都同样"很贵"。
Router / Gate 在做什么
Router 就是一个小网络,用来决定每个 token 去哪个 expert。
在你的代码里,它非常简单:
python
self.gate = nn.Linear(d_model, num_experts)也就是说:
- 输入一个 token 表示
x; - 输出
num_experts维打分; - 再用
softmax变成概率; - 然后取
topk。
数学上:
router_logits = W g x + b g \text{router\_logits} = W_g x + b_g router_logits=Wgx+bg
router_probs = softmax ( router_logits ) \text{router\_probs} = \text{softmax}(\text{router\_logits}) router_probs=softmax(router_logits)
然后做:
( topk_probs , topk_indices ) = TopK ( router_probs , k ) (\text{topk\_probs}, \text{topk\_indices}) = \text{TopK}(\text{router\_probs}, k) (topk_probs,topk_indices)=TopK(router_probs,k)
最后把 topk_probs 再归一化:
p ~ ∗ i = p i ∑ ∗ j ∈ TopK p j \tilde{p}*i = \frac{p_i}{\sum*{j \in \text{TopK}} p_j} p~∗i=∑∗j∈TopKpjpi
负载均衡为什么重要
如果不加约束,router 很容易学出一种"偷懒"策略:
- 所有 token 都跑到少数几个 expert;
- 其余 expert 基本闲置。
这样会导致:
1. 专家利用率极不均衡
一些 expert 非常忙,另一些几乎不训练。
2. 容易出现 expert collapse
也就是"专家塌缩"------名义上有很多专家,实际上只有少数几个在工作。
3. 分布式训练会出问题
MoE 常常把 expert 分散在不同设备上。
如果流量极端不均衡,会造成:
- 某些 GPU 爆满;
- 某些 GPU 很闲;
- 吞吐下降;
- 通信开销异常。
代码中的负载均衡损失
先定义:
- f i f_i fi:第 i i i 个 expert 实际接收到的 token 比例;
- P i P_i Pi:router 对第 i i i 个 expert 的平均概率。
然后定义损失:
L balance = N ∑ i = 1 N f i P i L_{\text{balance}} = N \sum_{i=1}^{N} f_i P_i Lbalance=Ni=1∑NfiPi
如果路由比较均匀,那么这个量会比较合理;
如果路由极端偏向某些 expert,则会出现不平衡。
这不是唯一写法.
专家数量对预训练有何影响
这是 MoE 里非常关键的问题。
一、专家数量变多,模型容量会上升
如果每个 expert 都是一个独立 FFN,那么专家数增加意味着:
- 参数量增加;
- 模型的函数空间更大;
- 能容纳更多模式和更复杂知识。
比如:
- 8 个 expert 比 4 个 expert 的总容量大;
- 64 个 expert 又比 8 个 expert 大得多。
所以从"容量"角度看,expert 越多,潜力越大。
二、但专家更多,不代表一定更好
MoE 的效果并不只取决于"专家数量多不多",还取决于:
- router 能不能学会合理分配;
- 每个 expert 是否有足够的数据训练;
- 是否有负载均衡;
- 并行系统是否能承受额外通信开销;
- top-k 是否合理;
- expert 的 hidden size 是否合适。
也就是说:
expert 数量增加带来的是"潜在上限",不是"自动收益"。
三、expert 太少时的问题
如果 expert 很少,例如 2 个、4 个:
- 模型分工能力有限;
- 容量提升不明显;
- 不同 token 类型可能仍然混在一起;
- MoE 相对 dense FFN 的优势不够明显。
四、expert 太多时的问题
如果 expert 很多,例如 64、128,甚至更多:
1. 单个 expert 分到的数据可能太少
因为每个 token 只选 top-k 个 expert。
如果 expert 数太多,而数据规模不够大,可能出现:
- 某些 expert 训练样本稀疏;
- 参数更新不充分;
- 专家 specialization 不稳定。
2. 路由更难训练
router 要在更大的 expert 空间里分配 token,难度上升。
3. 负载不均问题更严重
专家越多,越容易有一些 expert 被"饿死"。
4. 系统成本上升
虽然理论 FLOPs 可以不大幅增加,但实际工程里会增加:
- all-to-all 通信成本;
- 调度成本;
- 显存管理复杂度;
- 吞吐不稳定问题。
五、预训练时一个很现实的权衡
预训练中通常要平衡四件事:
- 总参数量
- 激活参数量(每 token 真正使用的参数量)
- 训练稳定性
- 硬件吞吐效率
因此专家数不是越多越好,而是要结合:
- 数据规模;
- 训练 token 总量;
- batch size;
- 并行方式;
- capacity factor;
- top-k;
- expert hidden size。
六、一个直观理解
假设你有两种方案:
方案 A:8 个 expert,每个 token 选 top-2
- 总容量适中
- 每个 expert 分到的样本较多
- 路由压力较小
- 训练更稳定
方案 B:128 个 expert,每个 token 仍选 top-2
- 总容量极大
- 单个 expert 平均被访问次数下降
- 更容易不平衡
- 更依赖大规模数据和强工程系统
所以只有在:
- 数据足够大;
- 训练足够久;
- 路由与并行做得足够好;
更多 expert 才可能真正变成收益。
七、一个常见误区
很多人会说:
"MoE 让参数量大很多,所以一定更强。"
这句话不完整。
更准确的说法应该是:
MoE 让模型在相近计算预算下拥有更大的参数容量,但是否转化成效果收益,取决于路由质量、专家利用率、训练数据规模与系统实现。
教学版 Sparse MoE 代码拆解
下面开始进入代码部分。
我这里按照模块来拆:
- 单个 Expert
- Router
- SparseMoE 主流程
- 负载均衡
- Demo
- 先写代码
- 再给属于那一部分的例子
- 每段拆开放在代码下面
模块 1:单个 Expert
代码
python
class FeedForwardExpert(nn.Module):
"""
单个 Expert,本质上就是一个标准两层前馈网络(MLP / FFN)。
输入:
x: [num_tokens_for_this_expert, d_model]
输出:
y: [num_tokens_for_this_expert, d_model]
"""
def __init__(self, d_model: int, d_hidden: int):
"""
参数:
d_model: 输入和输出的隐藏维度
d_hidden: Expert 内部中间层维度
"""
super().__init__()
# 第一层线性映射: [*, d_model] -> [*, d_hidden]
self.fc1 = nn.Linear(d_model, d_hidden)
# 第二层线性映射: [*, d_hidden] -> [*, d_model]
self.fc2 = nn.Linear(d_hidden, d_model)
# 激活函数,这里使用 GELU
self.act = nn.GELU()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
前向传播。
输入:
x: [num_tokens_for_this_expert, d_model]
输出:
out: [num_tokens_for_this_expert, d_model]
"""
# self.fc1:
# torch.nn.Linear
# 作用: 对最后一维做线性变换
# 输入维度: [num_tokens_for_this_expert, d_model]
# 输出维度: [num_tokens_for_this_expert, d_hidden]
x = self.fc1(x)
# self.act:
# torch.nn.GELU
# 作用: 非线性激活,提升表达能力
# 输入维度: [num_tokens_for_this_expert, d_hidden]
# 输出维度: [num_tokens_for_this_expert, d_hidden]
x = self.act(x)
# self.fc2:
# torch.nn.Linear
# 作用: 将中间维度映射回 d_model
# 输入维度: [num_tokens_for_this_expert, d_hidden]
# 输出维度: [num_tokens_for_this_expert, d_model]
out = self.fc2(x)
return out这一部分在做什么
每个 expert 本质上就是一个普通 FFN:
FFN ( x ) = W 2 σ ( W 1 x + b 1 ) + b 2 \text{FFN}(x) = W_2 \sigma(W_1 x + b_1) + b_2 FFN(x)=W2σ(W1x+b1)+b2
这里:
fc1:把维度从d_model映射到d_hiddenGELU:提供非线性表达能力fc2:再映射回d_model
所以 expert 并不神秘,它只是一个"专门服务于某些 token 的 FFN"。
例子 1:理解 nn.Linear
假设有一个输入张量:
python
x = torch.tensor([
[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0]
]) # shape = [2, 3]如果我们定义:
python
linear = nn.Linear(3, 4)那么它会把最后一维从 3 映射到 4:
- 输入 shape:
[2, 3] - 输出 shape:
[2, 4]
也就是:
python
y = linear(x)得到:
python
y.shape == (2, 4)本质上每一行都在做:
y = x W ⊤ + b y = xW^\top + b y=xW⊤+b
例子 2:理解 GELU
如果输入是:
python
x = torch.tensor([
[-1.0, 0.0, 1.0, 2.0]
])经过:
python
gelu = nn.GELU()
y = gelu(x)会发现:
- 小负数不会像 ReLU 一样直接截断成 0;
- 正数会被保留;
- 整体更平滑。
这也是 Transformer 家族里 FFN 常用 GELU 的原因。
例子 3:结合本代码理解 expert 的输入输出
在输出日志里,Expert 0 的输入是:
python
expert_input for expert 0
shape = (3, 8)说明:
- 当前有 3 个 token 被分给了 expert 0;
- 每个 token 维度是 8。
经过 fc1:
python
Expert 0 after fc1
shape = (3, 16)说明中间层扩大到了 16 维。
最后经过 fc2:
python
Expert 0 output
shape = (3, 8)又回到了 d_model=8,这样才能和其他 expert 的输出一起加权合并。
模块 2:Top-K Router
代码
python
class TopKRouter(nn.Module):
"""
Router / Gate 模块:
对每个 token 输出它应该去哪些 expert,以及对应的权重。
输入:
x: [num_tokens, d_model]
输出:
router_logits: [num_tokens, num_experts]
router_probs: [num_tokens, num_experts]
topk_indices: [num_tokens, k]
topk_probs: [num_tokens, k]
"""
def __init__(self, d_model: int, num_experts: int, k: int):
"""
参数:
d_model: token 表示维度
num_experts: expert 数量
k: 每个 token 选择前 k 个 expert
"""
super().__init__()
self.num_experts = num_experts
self.k = k
# gate:
# 线性层,将 token 向量映射到 expert logits
# 输入维度: [num_tokens, d_model]
# 输出维度: [num_tokens, num_experts]
self.gate = nn.Linear(d_model, num_experts)
def forward(self, x: torch.Tensor):
"""
前向传播。
输入:
x: [num_tokens, d_model]
输出:
router_logits: [num_tokens, num_experts]
router_probs: [num_tokens, num_experts]
topk_indices: [num_tokens, k]
topk_probs: [num_tokens, k]
"""
# self.gate:
# torch.nn.Linear
# 作用: 生成每个 token 对每个 expert 的未归一化打分 logits
# 输入维度: [num_tokens, d_model]
# 输出维度: [num_tokens, num_experts]
router_logits = self.gate(x)
# F.softmax:
# torch.nn.functional.softmax
# 作用: 在 expert 维度上归一化,得到每个 token 对各个 expert 的概率分布
# dim=-1 表示对最后一维 num_experts 做 softmax
# 输入维度: [num_tokens, num_experts]
# 输出维度: [num_tokens, num_experts]
router_probs = F.softmax(router_logits, dim=-1)
# torch.topk:
# 作用: 取每个 token 概率最大的前 k 个 expert
# dim=-1 表示在 expert 维度上取 top-k
# topk_probs 维度: [num_tokens, k]
# topk_indices 维度: [num_tokens, k]
topk_probs, topk_indices = torch.topk(router_probs, k=self.k, dim=-1)
# top-k 概率重新归一化
# 因为只保留了前 k 个 expert,所以需要把这 k 个概率重新缩放到和为 1
# torch.sum(..., keepdim=True):
# 作用: 在最后一维求和,并保留维度,方便广播除法
# 输入维度: [num_tokens, k]
# 输出维度: [num_tokens, 1]
topk_probs = topk_probs / torch.sum(topk_probs, dim=-1, keepdim=True)
return router_logits, router_probs, topk_indices, topk_probs这一部分在做什么
Router 的任务就是回答:
这个 token 应该交给哪些 expert 来处理?
它做了四件事:
- 用线性层算出每个 expert 的打分
router_logits - 用 softmax 变成概率
router_probs - 取 top-k,找出最合适的 k 个 expert
- 重新归一化 top-k 概率,得到最终混合权重
例子 1:理解 softmax
假设某个 token 的 router logits 是:
python
logits = torch.tensor([2.0, 1.0, 0.0, -1.0])经过:
python
probs = F.softmax(logits, dim=-1)大概会得到:
python
tensor([0.6439, 0.2369, 0.0871, 0.0321])含义是:
- expert 0 概率最大;
- expert 1 次之;
- expert 2 和 expert 3 更不优先。
例子 2:理解 torch.topk
如果:
python
probs = torch.tensor([
[0.10, 0.40, 0.20, 0.30],
[0.60, 0.15, 0.05, 0.20]
])执行:
python
topk_probs, topk_indices = torch.topk(probs, k=2, dim=-1)会得到:
python
topk_probs =
tensor([
[0.40, 0.30],
[0.60, 0.20]
])
topk_indices =
tensor([
[1, 3],
[0, 3]
])意思是:
- 第 1 个 token 选 expert 1 和 3
- 第 2 个 token 选 expert 0 和 3
例子 3:理解 top-k 重新归一化
继续上面的例子。
第一个 token 原本 top-2 概率是:
python
[0.40, 0.30]总和是 0.70,重新归一化后:
python
[0.40 / 0.70, 0.30 / 0.70] = [0.5714, 0.4286]也就是说,在 保留下来的两个 expert 内部,它们的贡献比例重新变成和为 1。
例子 4:对应真实日志
日志里:
python
router_probs
shape = (8, 4)
tensor([[0.4782, 0.1074, 0.1190, 0.2954],
[0.1559, 0.3100, 0.1987, 0.3354],
...])对第一个 token:
python
[0.4782, 0.1074, 0.1190, 0.2954]取 top-2:
python
topk_indices = [0, 3]
topk_probs before renorm = [0.4782, 0.2954]归一化后:
python
topk_probs after renorm = [0.6182, 0.3818]这表示:
- 第一个 token 被送往 expert 0 和 expert 3;
- expert 0 占 61.82%;
- expert 3 占 38.18%。
模块 3:SparseMoE 主体
代码
python
class SparseMoE(nn.Module):
"""
教学版稀疏 MoE 层。
整体流程:
1. 把 [batch, seq, d_model] 拉平成 [num_tokens, d_model]
2. Router 计算每个 token 的 top-k experts
3. 按 expert 把 token 分组 dispatch
4. 每个 expert 单独处理自己的 token
5. 按 router 权重加权后 gather 回原 token 位置
6. 恢复形状为 [batch, seq, d_model]
额外输出:
aux_loss: 负载均衡损失
"""
def __init__(
self,
d_model: int,
d_hidden: int,
num_experts: int,
k: int = 2
):
"""
参数:
d_model: 输入输出隐藏维度
d_hidden: 每个 expert 内部 FFN 隐层维度
num_experts: expert 数量
k: 每个 token 选前 k 个 expert
"""
super().__init__()
self.d_model = d_model
self.d_hidden = d_hidden
self.num_experts = num_experts
self.k = k
# Router 模块
self.router = TopKRouter(d_model=d_model, num_experts=num_experts, k=k)
# nn.ModuleList:
# 作用: 存放多个子模块,并让 PyTorch 正确注册它们的参数
# 长度为 num_experts,每个元素都是一个专家网络
self.experts = nn.ModuleList(
[FeedForwardExpert(d_model=d_model, d_hidden=d_hidden) for _ in range(num_experts)]
)这一部分在做什么
这个类把整个 MoE 组装起来了:
- 有一个 router;
- 有很多个 expert;
- forward 时会执行 dispatch -> expert compute -> gather。
ModuleList 很重要,因为它会让 PyTorch 知道这些 expert 都是模型参数的一部分。
例子 1:理解 nn.ModuleList
假设:
python
experts = nn.ModuleList([
FeedForwardExpert(8, 16),
FeedForwardExpert(8, 16),
FeedForwardExpert(8, 16),
FeedForwardExpert(8, 16),
])那么它里面存着 4 个 expert。
你可以通过:
python
experts[0]
experts[1]
experts[2]
experts[3]访问它们。
MoE 前向时,会根据 token 被分配到哪个 expert,调用对应的那个 expert。
例子 2:为什么输入要先 flatten
输入原始形状是:
python
x.shape = [batch_size, seq_len, d_model]比如:
python
x.shape = [2, 4, 8]这里其实表示:
- batch 里有 2 个样本;
- 每个样本长度 4;
- 每个 token 表示 8 维。
但路由是"按 token 分配"的,所以先展平:
python
x_flat = x.reshape(batch_size * seq_len, d_model)得到:
python
x_flat.shape = [8, 8]现在每一行就是一个 token,方便逐 token 路由。
模块 4:负载均衡损失
代码
python
def compute_load_balance_loss(
self,
router_probs: torch.Tensor,
topk_indices: torch.Tensor
) -> torch.Tensor:
"""
计算一个简单的负载均衡损失。
输入:
router_probs: [num_tokens, num_experts]
每个 token 对全部 experts 的概率分布
topk_indices: [num_tokens, k]
每个 token 选中的 top-k expert 编号
输出:
balance_loss: 标量张量 []
"""
num_tokens = router_probs.size(0)
# expert_mask 初始为全 0
# torch.zeros_like:
# 作用: 创建与 router_probs 同 shape、同 device、同 dtype 的全 0 张量
# 维度: [num_tokens, num_experts]
expert_mask = torch.zeros_like(router_probs)
# scatter_:
# torch.Tensor.scatter_
# 作用: 按照 topk_indices 指定的位置,把值写入 expert_mask
# 这里写入 1.0,表示对应 token 被路由到了对应 expert
# topk_indices 维度: [num_tokens, k]
# 写入后 expert_mask 维度仍是 [num_tokens, num_experts]
expert_mask.scatter_(dim=1, index=topk_indices, value=1.0)
# f_i: 每个 expert 实际接收到的 token 比例
# torch.sum(..., dim=0):
# 作用: 沿 token 维求和,统计每个 expert 被选中的次数
# expert_mask 维度: [num_tokens, num_experts]
# 求和后维度: [num_experts]
# 再除以 num_tokens * k,得到比例
tokens_per_expert = torch.sum(expert_mask, dim=0) / (num_tokens * self.k)
# P_i: 每个 expert 的平均路由概率
# torch.mean(..., dim=0):
# 作用: 沿 token 维求平均
# 输入维度: [num_tokens, num_experts]
# 输出维度: [num_experts]
router_prob_per_expert = torch.mean(router_probs, dim=0)
# 负载均衡损失
# 元素乘法后仍是 [num_experts]
# 再 sum 得到标量
balance_loss = self.num_experts * torch.sum(tokens_per_expert * router_prob_per_expert)
return balance_loss这一部分在做什么
这里分三步:
第一步:构造 expert_mask
它记录:
- 每个 token 最终选中了哪些 expert。
如果有 4 个 expert,某个 token 选中了 [0, 3],那么这一行 mask 就是:
python
[1, 0, 0, 1]例子 1:理解 scatter_
假设:
python
topk_indices = torch.tensor([
[0, 3],
[1, 3],
[1, 2]
])表示 3 个 token 分别选中了:
- token 0 -> expert 0, 3
- token 1 -> expert 1, 3
- token 2 -> expert 1, 2
先构造:
python
expert_mask = torch.zeros(3, 4)得到:
python
tensor([
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]
])再执行:
python
expert_mask.scatter_(dim=1, index=topk_indices, value=1.0)得到:
python
tensor([
[1., 0., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 1., 0.]
])这一步非常关键,它把"索引形式的路由结果"变成了"显式 one-hot / multi-hot 标记"。
例子 2:理解 tokens_per_expert
继续用上面的 expert_mask:
python
tensor([
[1., 0., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 1., 0.]
])按列求和:
python
torch.sum(expert_mask, dim=0)得到:
python
tensor([1., 2., 1., 2.])表示:
- expert 0 被选中 1 次
- expert 1 被选中 2 次
- expert 2 被选中 1 次
- expert 3 被选中 2 次
如果共有 3 个 token,每个 token 选 2 个 expert,那么总共选中次数是:
python
3 * 2 = 6所以比例是:
python
[1/6, 2/6, 1/6, 2/6]例子 3:理解 torch.mean
假设:
python
router_probs = torch.tensor([
[0.50, 0.20, 0.10, 0.20],
[0.10, 0.50, 0.20, 0.20],
[0.20, 0.30, 0.40, 0.10]
])执行:
python
torch.mean(router_probs, dim=0)得到:
python
tensor([
(0.50+0.10+0.20)/3,
(0.20+0.50+0.30)/3,
(0.10+0.20+0.40)/3,
(0.20+0.20+0.10)/3
])也就是每个 expert 在 router 眼中的平均概率。
例子 4:对应真实日志
python
tokens_per_expert
shape = (4,)
tensor([0.1875, 0.3125, 0.1250, 0.3750])表示 4 个 expert 的实际接收比例分别是:
- expert 0:18.75%
- expert 1:31.25%
- expert 2:12.50%
- expert 3:37.50%
而:
python
router_prob_per_expert
shape = (4,)
tensor([0.2719, 0.2315, 0.2450, 0.2516])表示 router 的平均倾向。
最后:
python
balance_loss = 0.9932这个值反映了当前路由分布的均衡程度。
模块 3:SparseMoE forward 主流程
上面讲了构造;下面看真正的 forward 逻辑。
代码
python
def forward(self, x: torch.Tensor):
"""
前向传播。
输入:
x: [batch_size, seq_len, d_model]
输出:
output: [batch_size, seq_len, d_model]
aux_loss: []
"""
# 读取输入形状
batch_size, seq_len, d_model = x.shape
# 把 batch 和 seq 两个维度展平,方便把每个 token 单独路由
# x.reshape:
# 作用: 改变张量形状,不改变数据内容
# 输入维度: [batch_size, seq_len, d_model]
# 输出维度: [num_tokens, d_model]
# 其中 num_tokens = batch_size * seq_len
x_flat = x.reshape(batch_size * seq_len, d_model)
# Router 前向
# router_logits: [num_tokens, num_experts]
# router_probs: [num_tokens, num_experts]
# topk_indices: [num_tokens, k]
# topk_probs: [num_tokens, k]
router_logits, router_probs, topk_indices, topk_probs = self.router(x_flat)
# 初始化最终输出张量
# torch.zeros_like:
# 作用: 创建与 x_flat 同 shape 的全 0 张量
# 维度: [num_tokens, d_model]
output_flat = torch.zeros_like(x_flat)
# 遍历每个 expert,单独处理分配给它的 token
for expert_id in range(self.num_experts):
# -------- 第一步:找到哪些 token 被分配给当前 expert --------
# topk_indices == expert_id:
# 作用: 判断每个 token 的 top-k expert 中是否包含当前 expert
# 输出布尔张量维度: [num_tokens, k]
assigned_mask = (topk_indices == expert_id)
# assigned_mask.any(dim=-1):
# 作用: 看每个 token 的 k 个位置里,是否至少有一个位置等于当前 expert_id
# 输出维度: [num_tokens]
token_selected = assigned_mask.any(dim=-1)
# 如果当前 expert 没有分到任何 token,就跳过,避免无意义计算
if token_selected.sum() == 0:
continue
# torch.nonzero(..., as_tuple=False):
# 作用: 返回非零/True 元素的位置索引
# token_selected 维度: [num_tokens]
# 输出维度: [num_selected_tokens, 1]
token_indices = torch.nonzero(token_selected, as_tuple=False).squeeze(-1)
# 从 x_flat 中取出分给当前 expert 的 token
# x_flat[token_indices]:
# 高级索引
# 输入 x_flat 维度: [num_tokens, d_model]
# token_indices 维度: [num_selected_tokens]
# 输出 expert_input 维度: [num_selected_tokens, d_model]
expert_input = x_flat[token_indices]
# 当前 expert 处理这些 token
# 输出 expert_output 维度: [num_selected_tokens, d_model]
expert_output = self.experts[expert_id](expert_input)
# -------- 第二步:取出这些 token 分给当前 expert 的权重 --------
# assigned_mask[token_indices]:
# 取出当前这些 token 在 top-k 位置上是否命中了当前 expert
# 维度: [num_selected_tokens, k]
current_assigned_mask = assigned_mask[token_indices]
# topk_probs[token_indices]:
# 取出当前这些 token 的 top-k 权重
# 维度: [num_selected_tokens, k]
current_topk_probs = topk_probs[token_indices]
# 只保留属于当前 expert 的那些权重,其余位置变 0
# torch.where(condition, x, y):
# 作用: 按条件逐元素选择
# 输出维度: [num_selected_tokens, k]
current_expert_weights = torch.where(
current_assigned_mask,
current_topk_probs,
torch.zeros_like(current_topk_probs)
)
# 因为某 token 对某 expert 最多只出现一次,
# 所以在 k 维求和后就得到该 token 分给当前 expert 的最终权重
# torch.sum(..., dim=-1, keepdim=True):
# 输入维度: [num_selected_tokens, k]
# 输出维度: [num_selected_tokens, 1]
current_expert_weights = torch.sum(current_expert_weights, dim=-1, keepdim=True)
# -------- 第三步:把 expert 输出乘上路由权重,再加回总输出 --------
# 广播乘法:
# expert_output: [num_selected_tokens, d_model]
# current_expert_weights: [num_selected_tokens, 1]
# 结果维度: [num_selected_tokens, d_model]
weighted_expert_output = expert_output * current_expert_weights
# 累加回对应 token 的输出位置
# output_flat[token_indices] 维度: [num_selected_tokens, d_model]
output_flat[token_indices] += weighted_expert_output
# 计算负载均衡损失
# 输出是标量张量 []
aux_loss = self.compute_load_balance_loss(router_probs, topk_indices)
# 把输出恢复回 [batch_size, seq_len, d_model]
# output_flat 维度: [num_tokens, d_model]
# output 维度: [batch_size, seq_len, d_model]
output = output_flat.reshape(batch_size, seq_len, d_model)
return output, aux_loss这一部分在做什么
这是整个 Sparse MoE 的核心。
流程可以总结成:
- flatten 所有 token
- router 给每个 token 分配 top-k expert
- 遍历 expert
- 找出哪些 token 属于这个 expert
- 取出这些 token,喂给该 expert
- 根据路由权重做加权
- 把结果加回原 token 位置
- reshape 回 batch 形式
例子 1:理解 reshape
假设:
python
x = torch.randn(2, 4, 8)它表示:
- 2 个样本
- 每个样本 4 个 token
- 每个 token 8 维
执行:
python
x_flat = x.reshape(8, 8)就是把前两个维度合并了。
这并不是打乱 token 内容,只是把:
python
(batch_id, seq_id)合并成一个统一的 token 索引。
例子 2:理解 assigned_mask = (topk_indices == expert_id)
假设:
python
topk_indices = torch.tensor([
[0, 3],
[3, 1],
[1, 3],
[2, 1]
])如果当前:
python
expert_id = 1那么:
python
assigned_mask = (topk_indices == 1)得到:
python
tensor([
[False, False],
[False, True],
[ True, False],
[False, True]
])表示:
- token 0 的 top-k 中没有 expert 1
- token 1 有
- token 2 有
- token 3 有
例子 3:理解 .any(dim=-1)
继续上面的 assigned_mask:
python
tensor([
[False, False],
[False, True],
[ True, False],
[False, True]
])执行:
python
token_selected = assigned_mask.any(dim=-1)得到:
python
tensor([False, True, True, True])意思是:哪些 token 至少在 top-k 里包含当前 expert。
例子 4:理解 torch.nonzero
如果:
python
token_selected = torch.tensor([False, True, True, False, True])执行:
python
token_indices = torch.nonzero(token_selected, as_tuple=False).squeeze(-1)得到:
python
tensor([1, 2, 4])也就是当前 expert 实际需要处理的 token 下标。
例子 5:理解高级索引
假设:
python
x_flat = torch.tensor([
[10., 11.],
[20., 21.],
[30., 31.],
[40., 41.],
[50., 51.]
])
token_indices = torch.tensor([1, 3, 4])执行:
python
expert_input = x_flat[token_indices]得到:
python
tensor([
[20., 21.],
[40., 41.],
[50., 51.]
])这就是"把属于当前 expert 的 token 收集出来"。
例子 6:理解 torch.where
假设:
python
current_assigned_mask = torch.tensor([
[True, False],
[False, True],
[True, False]
])
current_topk_probs = torch.tensor([
[0.6, 0.4],
[0.7, 0.3],
[0.8, 0.2]
])执行:
python
current_expert_weights = torch.where(
current_assigned_mask,
current_topk_probs,
torch.zeros_like(current_topk_probs)
)得到:
python
tensor([
[0.6, 0.0],
[0.0, 0.3],
[0.8, 0.0]
])再执行:
python
current_expert_weights = torch.sum(current_expert_weights, dim=-1, keepdim=True)得到:
python
tensor([
[0.6],
[0.3],
[0.8]
])这就是"当前 expert 对这些 token 的最终路由权重"。
例子 7:理解广播乘法
假设:
python
expert_output = torch.tensor([
[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0]
]) # shape = [2, 3]
current_expert_weights = torch.tensor([
[0.2],
[0.8]
]) # shape = [2, 1]执行:
python
weighted_expert_output = expert_output * current_expert_weights得到:
python
tensor([
[0.2, 0.4, 0.6],
[3.2, 4.0, 4.8]
])因为第二个维度会自动广播。
例子 8:理解 output_flat[token_indices] += ...
假设:
python
output_flat = torch.zeros(5, 3)
token_indices = torch.tensor([1, 4])
weighted_expert_output = torch.tensor([
[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6]
])执行:
python
output_flat[token_indices] += weighted_expert_output得到:
python
tensor([
[0.0, 0.0, 0.0],
[0.1, 0.2, 0.3],
[0.0, 0.0, 0.0],
[0.0, 0.0, 0.0],
[0.4, 0.5, 0.6]
])这就是 gather 回原 token 位置。
如果一个 token 同时属于多个 expert,那么它会被多次累加,最终形成:
y = ∑ i ∈ TopK p ~ i E i ( x ) y = \sum_{i \in \text{TopK}} \tilde{p}_i E_i(x) y=i∈TopK∑p~iEi(x)
例子 9:对照真实日志看 expert 0
expert 0:
python
token_indices for expert 0
shape = (3,)
tensor([0, 4, 5])这说明 expert 0 处理第 0、4、5 号 token。
对应权重:
python
current_expert_weights after sum for expert 0
tensor([[0.6182],
[0.6868],
[0.5215]])说明这 3 个 token 分别给 expert 0 的权重是:
- token 0 -> 0.6182
- token 4 -> 0.6868
- token 5 -> 0.5215
于是 expert 输出再乘上这些权重,累加回 output_flat。
例子 10:为什么 token 会有多个 expert 结果相加
看 token 0:
- 被分给 expert 0 和 expert 3
所以最后 token 0 的输出来自:
y 0 = 0.6182 ⋅ E 0 ( x 0 ) + 0.3818 ⋅ E 3 ( x 0 ) y_0 = 0.6182 \cdot E_0(x_0) + 0.3818 \cdot E_3(x_0) y0=0.6182⋅E0(x0)+0.3818⋅E3(x0)
这正是 MoE 的"混合专家"之处。
模块 5:demo 测试入口
代码
python
def demo():
"""
演示如何实例化和调用这个教学版 SparseMoE。
"""
# 设置随机种子,保证结果可复现
torch.manual_seed(42)
# 假设:
# batch_size = 2
# seq_len = 4
# d_model = 8
batch_size = 2
seq_len = 4
d_model = 8
# 每个 expert 的隐藏层维度
d_hidden = 16
# expert 数量
num_experts = 4
# 每个 token 选择 top-2 个 expert
k = 2
# 构造输入张量
x = torch.randn(batch_size, seq_len, d_model)
# 实例化模型
moe = SparseMoE(
d_model=d_model,
d_hidden=d_hidden,
num_experts=num_experts,
k=k
)
# 前向传播
output, aux_loss = moe(x)
# 打印结果形状
print("input shape :", x.shape)
print("output shape:", output.shape)
print("aux_loss :", aux_loss.item())
if __name__ == "__main__":
demo()这一部分在做什么
它只是一个最小可运行测试。
配置如下:
batch_size = 2seq_len = 4d_model = 8d_hidden = 16num_experts = 4k = 2
意味着:
- 一共有
2 × 4 = 8个 token; - 每个 token 8 维;
- 总共有 4 个 expert;
- 每个 token 只走 2 个 expert。
例子 1:为什么设置随机种子
python
torch.manual_seed(42)这样做是为了让:
- 输入张量初始化一致;
- 线性层参数初始化一致;
- 每次运行结果可以复现。
对于写教学博客或调试很重要。
例子 2:最终输出为什么 shape 不变
输入:
python
x.shape = [2, 4, 8]输出:
python
output.shape = [2, 4, 8]虽然中间经历了:
- flatten
- route
- dispatch
- gather
但最终还是恢复到和输入一样的 shape。
因为从 Transformer 模块角度看,MoE 只是替代 FFN 的一个层,它不应该改变 token 表示维度。
完整代码
下面给出完整代码,方便直接复制运行。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class FeedForwardExpert(nn.Module):
"""
单个 Expert,本质上就是一个标准两层前馈网络(MLP / FFN)。
输入:
x: [num_tokens_for_this_expert, d_model]
输出:
y: [num_tokens_for_this_expert, d_model]
"""
def __init__(self, d_model: int, d_hidden: int):
"""
参数:
d_model: 输入和输出的隐藏维度
d_hidden: Expert 内部中间层维度
"""
super().__init__()
self.fc1 = nn.Linear(d_model, d_hidden)
self.fc2 = nn.Linear(d_hidden, d_model)
self.act = nn.GELU()
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.fc1(x)
x = self.act(x)
out = self.fc2(x)
return out
class TopKRouter(nn.Module):
"""
Router / Gate 模块:
对每个 token 输出它应该去哪些 expert,以及对应的权重。
"""
def __init__(self, d_model: int, num_experts: int, k: int):
super().__init__()
self.num_experts = num_experts
self.k = k
self.gate = nn.Linear(d_model, num_experts)
def forward(self, x: torch.Tensor):
router_logits = self.gate(x)
router_probs = F.softmax(router_logits, dim=-1)
topk_probs, topk_indices = torch.topk(router_probs, k=self.k, dim=-1)
topk_probs = topk_probs / torch.sum(topk_probs, dim=-1, keepdim=True)
return router_logits, router_probs, topk_indices, topk_probs
class SparseMoE(nn.Module):
"""
教学版稀疏 MoE 层。
"""
def __init__(
self,
d_model: int,
d_hidden: int,
num_experts: int,
k: int = 2
):
super().__init__()
self.d_model = d_model
self.d_hidden = d_hidden
self.num_experts = num_experts
self.k = k
self.router = TopKRouter(d_model=d_model, num_experts=num_experts, k=k)
self.experts = nn.ModuleList(
[FeedForwardExpert(d_model=d_model, d_hidden=d_hidden) for _ in range(num_experts)]
)
def compute_load_balance_loss(
self,
router_probs: torch.Tensor,
topk_indices: torch.Tensor
) -> torch.Tensor:
num_tokens = router_probs.size(0)
expert_mask = torch.zeros_like(router_probs)
expert_mask.scatter_(dim=1, index=topk_indices, value=1.0)
tokens_per_expert = torch.sum(expert_mask, dim=0) / (num_tokens * self.k)
router_prob_per_expert = torch.mean(router_probs, dim=0)
balance_loss = self.num_experts * torch.sum(tokens_per_expert * router_prob_per_expert)
return balance_loss
def forward(self, x: torch.Tensor):
batch_size, seq_len, d_model = x.shape
x_flat = x.reshape(batch_size * seq_len, d_model)
router_logits, router_probs, topk_indices, topk_probs = self.router(x_flat)
output_flat = torch.zeros_like(x_flat)
for expert_id in range(self.num_experts):
assigned_mask = (topk_indices == expert_id)
token_selected = assigned_mask.any(dim=-1)
if token_selected.sum() == 0:
continue
token_indices = torch.nonzero(token_selected, as_tuple=False).squeeze(-1)
expert_input = x_flat[token_indices]
expert_output = self.experts[expert_id](expert_input)
current_assigned_mask = assigned_mask[token_indices]
current_topk_probs = topk_probs[token_indices]
current_expert_weights = torch.where(
current_assigned_mask,
current_topk_probs,
torch.zeros_like(current_topk_probs)
)
current_expert_weights = torch.sum(current_expert_weights, dim=-1, keepdim=True)
weighted_expert_output = expert_output * current_expert_weights
output_flat[token_indices] += weighted_expert_output
aux_loss = self.compute_load_balance_loss(router_probs, topk_indices)
output = output_flat.reshape(batch_size, seq_len, d_model)
return output, aux_loss
def demo():
"""
演示如何实例化和调用这个教学版 SparseMoE。
"""
torch.manual_seed(42)
batch_size = 2
seq_len = 4
d_model = 8
d_hidden = 16
num_experts = 4
k = 2
x = torch.randn(batch_size, seq_len, d_model)
moe = SparseMoE(
d_model=d_model,
d_hidden=d_hidden,
num_experts=num_experts,
k=k
)
output, aux_loss = moe(x)
print("input shape :", x.shape)
print("output shape:", output.shape)
print("aux_loss :", aux_loss.item())
if __name__ == "__main__":
demo()完整例子:一次 forward 到底发生了什么
下面结合你给出的输出日志,串起来解释一次完整前向传播。
第一步:输入张量
原始输入:
python
x.shape = (2, 4, 8)说明:
- batch size = 2
- seq length = 4
- hidden size = 8
总共有:
2 × 4 = 8 2 \times 4 = 8 2×4=8
个 token。
第二步:展平
python
x_flat.shape = (8, 8)现在每一行对应一个 token。
第三步:Router 打分
python
router_logits.shape = (8, 4)
router_probs.shape = (8, 4)因为:
- 一共有 8 个 token
- 一共有 4 个 expert
所以每个 token 都会得到对 4 个 expert 的概率分布。
第四步:选 top-k
你设置的是:
python
k = 2因此:
python
topk_indices.shape = (8, 2)
topk_probs.shape = (8, 2)例如第一个 token:
python
router_probs = [0.4782, 0.1074, 0.1190, 0.2954]
topk_indices = [0, 3]
topk_probs(after renorm) = [0.6182, 0.3818]含义是:
- token 0 -> expert 0 和 expert 3
- 两者贡献比例分别是 0.6182 和 0.3818
第五步:dispatch 给不同 expert
以 expert 0 为例:
python
token_indices for expert 0 = [0, 4, 5]说明它负责 3 个 token。
以 expert 1 为例:
python
token_indices for expert 1 = [1, 2, 3, 6, 7]说明它负责 5 个 token。
以 expert 2 为例:
python
token_indices for expert 2 = [3, 7]说明它负责 2 个 token。
以 expert 3 为例:
python
token_indices for expert 3 = [0, 1, 2, 4, 5, 6]说明它负责 6 个 token。
注意:
这些数字加起来超过 8,并不矛盾,因为每个 token 会去 两个 expert。
第六步:expert 独立处理
例如 expert 0:
python
expert_input.shape = (3, 8)先经过:
python
fc1 -> shape = (3, 16)
GELU
fc2 -> shape = (3, 8)得到 expert 输出。
其他 expert 同理。
第七步:用路由权重加权
例如 expert 0 对应三个 token 的权重:
python
current_expert_weights =
tensor([[0.6182],
[0.6868],
[0.5215]])于是 expert 0 输出会乘以这些权重。
例如 token 0 在 expert 0 这里的加权输出是:
python
[-0.1489, -0.0794, -0.0141, 0.0033, -0.0469, 0.0786, 0.0319, -0.1390]第八步:多个 expert 的结果相加
例如 token 0 还会经过 expert 3,得到另一份加权输出:
python
[-0.0764, 0.0891, -0.0338, -0.1175, -0.1100, 0.0063, -0.0057, -0.0060]两者相加后,token 0 的最终输出变成:
python
[-0.2253, 0.0096, -0.0479, -0.1142, -0.1570, 0.0849, 0.0262, -0.1450]这非常符合公式:
y = p ~ 0 E 0 ( x ) + p ~ 3 E 3 ( x ) y = \tilde{p}_0 E_0(x) + \tilde{p}_3 E_3(x) y=p~0E0(x)+p~3E3(x)
第九步:计算负载均衡损失
你日志中的:
python
tokens_per_expert = [0.1875, 0.3125, 0.1250, 0.3750]
router_prob_per_expert = [0.2719, 0.2315, 0.2450, 0.2516]
balance_loss = 0.9932说明:
- expert 3 实际收到最多 token;
- expert 2 收到最少;
- 当前路由不是完全均匀,但也没有极端塌缩;
- 辅助损失会推动训练过程中分配更平衡。
第十步:恢复输出形状
最后:
python
output.shape = (2, 4, 8)恢复成和输入一致的三维结构,方便作为 Transformer 下一层的输入。
MoE 的优点、问题与工程注意点
优点
1. 用较低激活计算实现更大参数容量
这是 MoE 最大价值。
2. 专家可以形成分工
不同 expert 学到不同类型模式。
3. 更适合继续横向扩模型
比纯 dense 模型更适合堆大参数。
问题
1. 训练不稳定
router 很容易偏向少数 expert。
2. 负载不均衡
需要额外 balance loss、capacity 控制。
3. 工程实现复杂
真实大规模训练里最难的不是数学,而是:
- token dispatch
- all-to-all 通信
- capacity overflow
- expert parallel
4. 吞吐不一定理想
理论 FLOPs 省了,但真实系统可能被通信瓶颈抵消。
总结
MoE 的关键思想可以概括成一句话:
用路由器把不同 token 动态分给少量专家处理,从而在不显著增加单 token 计算量的情况下,获得更大的总参数容量。