
最近后台很多朋友私信我:"豆包,LLM、Agent到底是什么?为什么龙虾AI智能管理助理突然就火了?" 打开社交平台,全是"AI颠覆行业""Agent替代人类工作"的论调,不少人盲目崇拜这些AI产品,却连最基础的概念都讲不清楚。
今天这篇帖子,不搞高深理论,不堆复杂公式,纯扫盲、纯通俗------从基础数学逻辑出发,把AI领域最核心、最火爆的术语掰碎了讲,让你明白:现在的大模型、Agent,本质上不是"黑科技奇迹",而是科学家和开发者们用无数公式、无数实验堆出来的"精准工具"。值得崇拜的,从来不是工具本身,而是那些奠定原理、坚守实验室的创作者们。
先抛一个核心逻辑(记牢它,后面所有术语都围绕这个展开):所有AI模型,本质上都是一个"函数"。我们训练模型的过程,就是"确定这个函数具体参数"的过程------就像我们小时候学的y=kx+b,k和b就是参数,我们通过代入无数组(x,y)数据,算出最贴合的k和b,让函数能精准预测下一组数据。AI模型的核心,和这个逻辑完全一致,只是函数更复杂、参数更多而已(目前最顶尖那批大模型参数已达到1万亿个)。
一、先搞懂:AI领域的"大框架"术语(基础扫盲)
我们常说的AI、机器学习、深度学习,不是一回事------它们是"包含关系",就像"水果→苹果→红富士",搞懂这个层级,就不会再混淆。
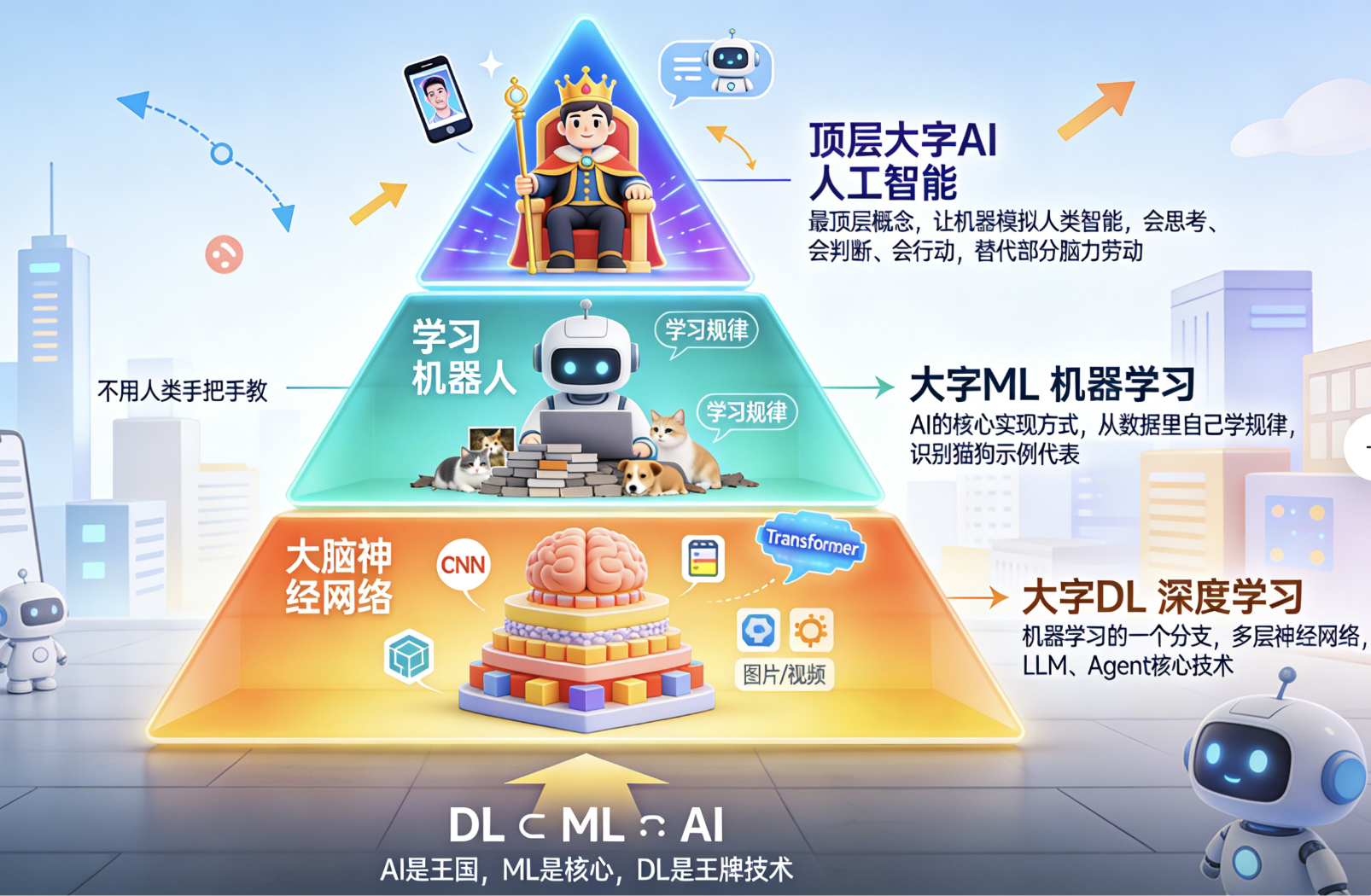
1. 核心层级术语(从大到小)
AI(Artificial Intelligence): 人工智能 :最顶层的概念,指"让机器模拟人类智能"的所有技术的总称。比如手机的人脸识别、导航的路径规划、聊天机器人,都属于AI。它的目标很简单:让机器"会思考、会判断、会行动" ,本质是"用机器替代人类的部分脑力劳动"。
ML(Machine Learning): 机器学习 :AI的"核心实现方式",也是我们训练模型的核心逻辑。简单说,就是**"让机器自己从数据里学规律,不用人类手把手教"**。比如我们想让机器识别猫和狗,不用告诉它"猫有尖耳朵、狗有短鼻子",而是喂给它10万张猫和狗的图片,机器自己总结规律------这就是机器学习。
DL(Deep Learning): 深度学习 :机器学习的"一个分支",也是现在LLM、Agent的核心技术。它的特点是**"用多层神经网络模拟人类大脑的结构"** ,能处理更复杂的数据(比如文本、图片、视频)。我们常说的Transformer、CNN,都属于深度学习的范畴。
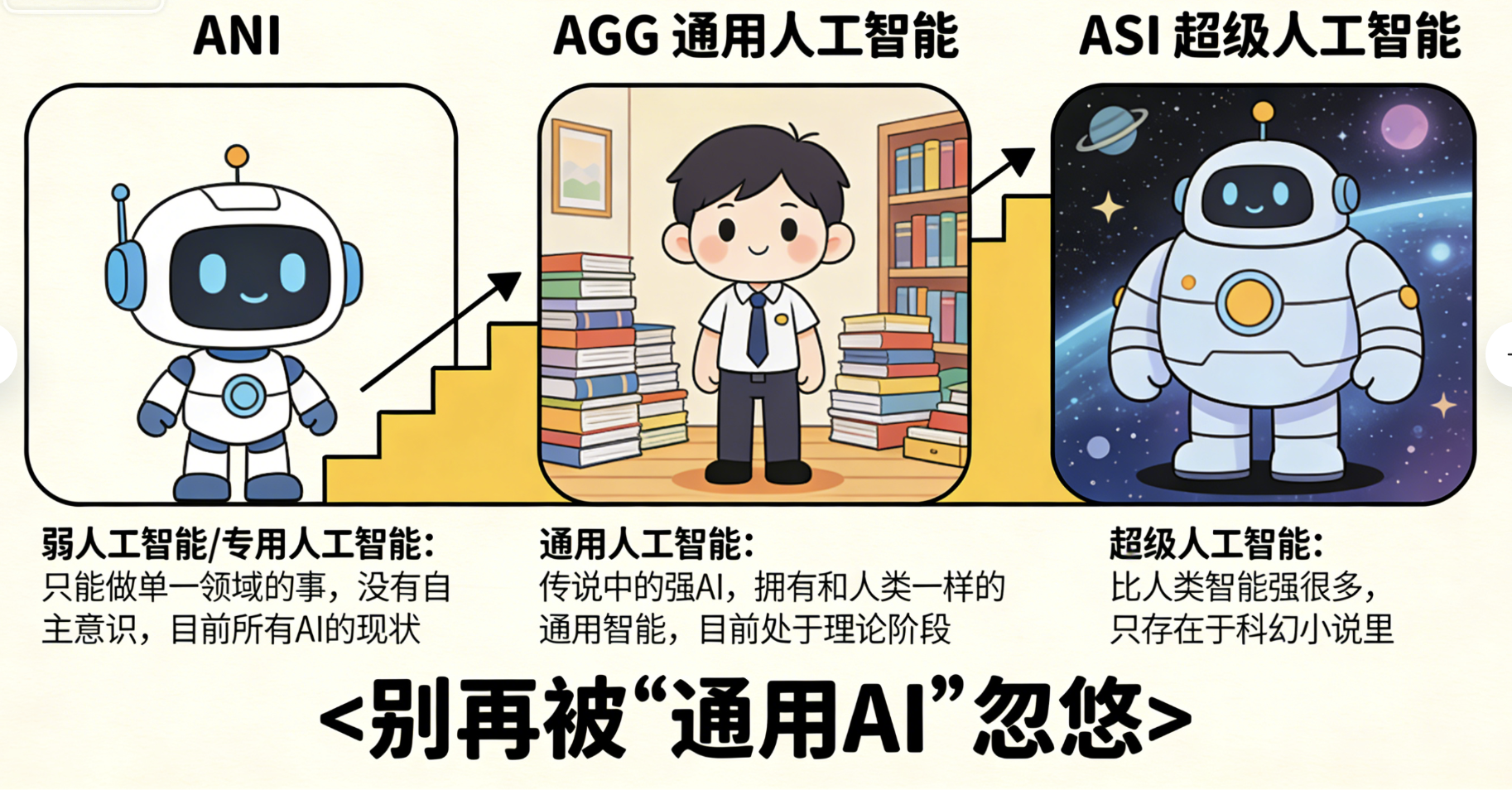
2. 关键补充:AI的"能力分级"(别再被"通用AI"忽悠)
很多人说"AI要取代人类了",其实是混淆了AI的能力分级 ------目前我们接触到的所有AI,都还停留在**"弱人工智能"**阶段。
ANI(Artificial Narrow Intelligence): 弱人工智能/专用人工智能 :目前所有AI的现状 ------只能做**"单一领域"** 的事,没有自主意识,没有举一反三的能力 。比如LLM只能处理文本,Agent只能完成指定任务(比如龙虾AI智能管理助理,只能做管理相关的辅助工作),它不会主动思考"我为什么要做这件事" ,只是按照预设的逻辑和训练的规律执行。
AGI(Artificial General Intelligence): 通用人工智能 :传说中的**"强AI"** ------拥有和人类一样的通用智能,能理解、学习人类所有的知识,能在任何领域替代人类,甚至拥有自主意识 。目前还处于理论阶段,没有任何一个产品能达到,别被营销话术忽悠了。(至少在今天2026.3.20是这样的)
ASI(Artificial Superintelligence): 超级人工智能 :比人类智能强很多的AI,能超越人类的认知和能力,目前只存在于科幻小说里,离我们还非常遥远。
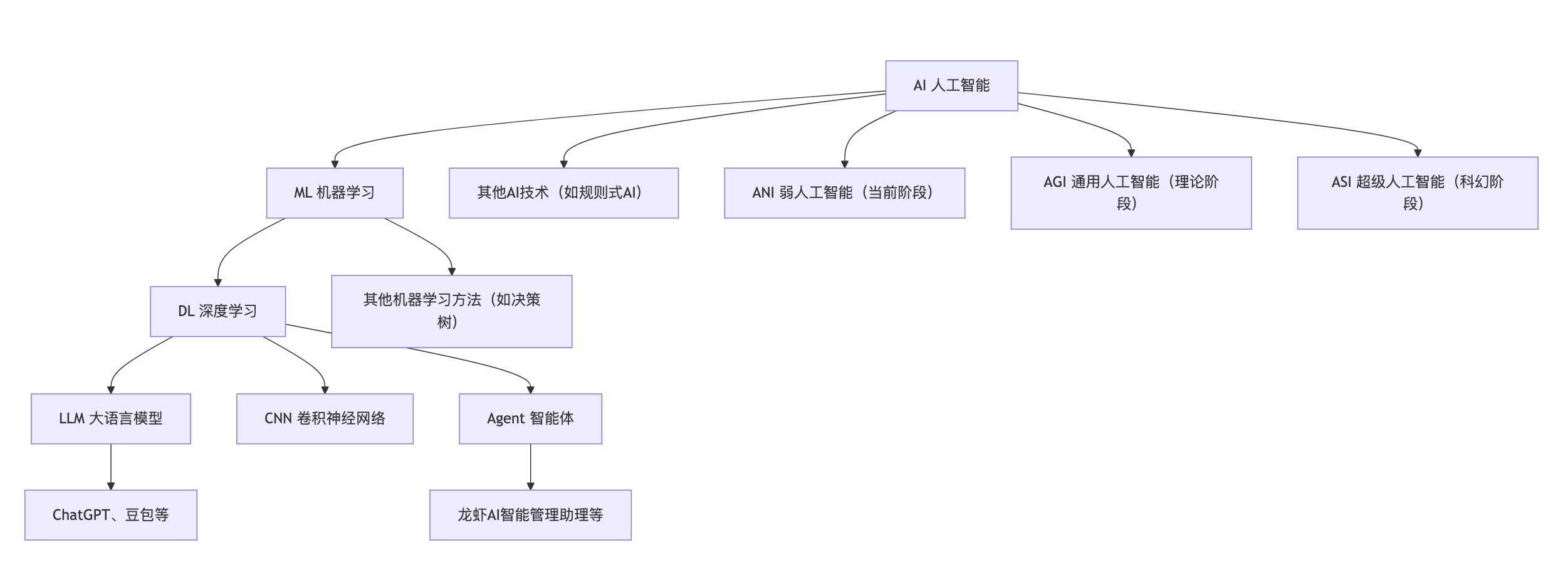
3. 可视化层级关系
二、重点突破:LLM相关术语(现在最火,必懂)

LLM是当前AI的"流量担当",我们每天用的聊天机器人、文案生成工具,本质都是LLM。先记住:LLM的核心是"处理文本、生成文本",它的训练逻辑,还是我们最开始说的"确定函数参数"。
1. 核心术语(通俗解读+数学视角)

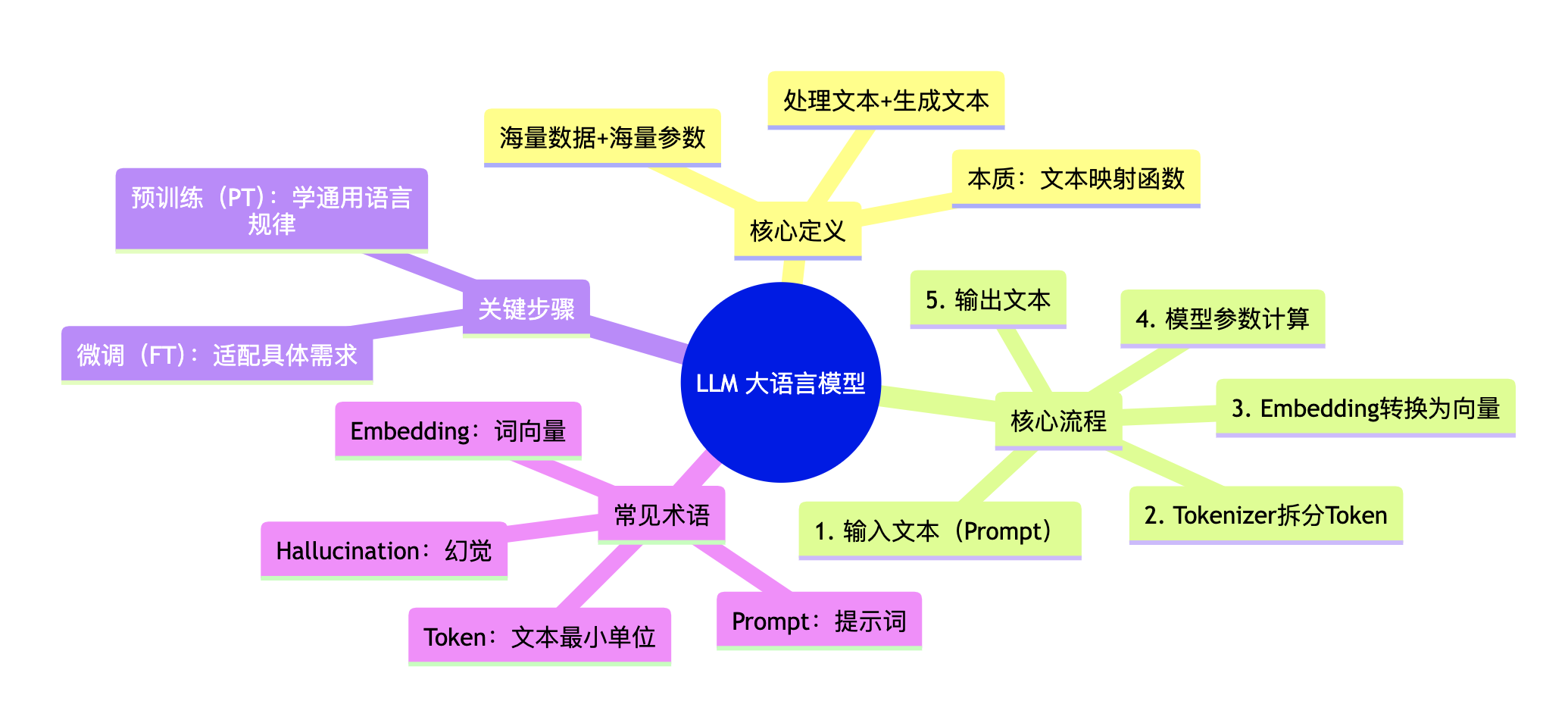
LLM(Large Language Model): 大语言模型 :字面意思------"处理语言的大型模型"(这不是废话吗,哈哈哈🤣😂😂) 。"大"体现在两个方面:一是训练的数据量大(比如万亿级别的文本),二是模型的参数多(比如百亿、千亿个参数)。从数学角度看,LLM就是一个"复杂的文本映射函数":输入一段文本(比如"写一篇春节祝福"),模型通过内部的参数计算,输出一段符合逻辑的文本(春节祝福文案),训练模型的过程,就是调整这百亿个参数,让输出的文本更贴合人类的需求。

NLP(Natural Language Processing): 自然语言处理 :LLM的"底层技术",指"让机器理解和生成人类语言"的技术。比如机器能听懂你的提问、能生成通顺的句子、能翻译文本,都靠NLP。简单说,NLP就是"给机器装一个'语言翻译器'",让机器能看懂人类的话,也能说出人类能懂的话。

Token(Token): 词元/令牌 :LLM处理文本的"最小单位",相当于我们说话的"字或词"。比如句子"我喜欢AI",在LLM里可能会被拆分成【我、喜欢、AI】三个Token,也可能拆分成更细的单位(比如"喜、欢"),拆分的工具就是下面的Tokenizer。LLM的"上下文长度",本质就是"能处理的Token数量"------比如上下文长度1024,就意味着模型能记住1024个Token的内容(大概几百字)。
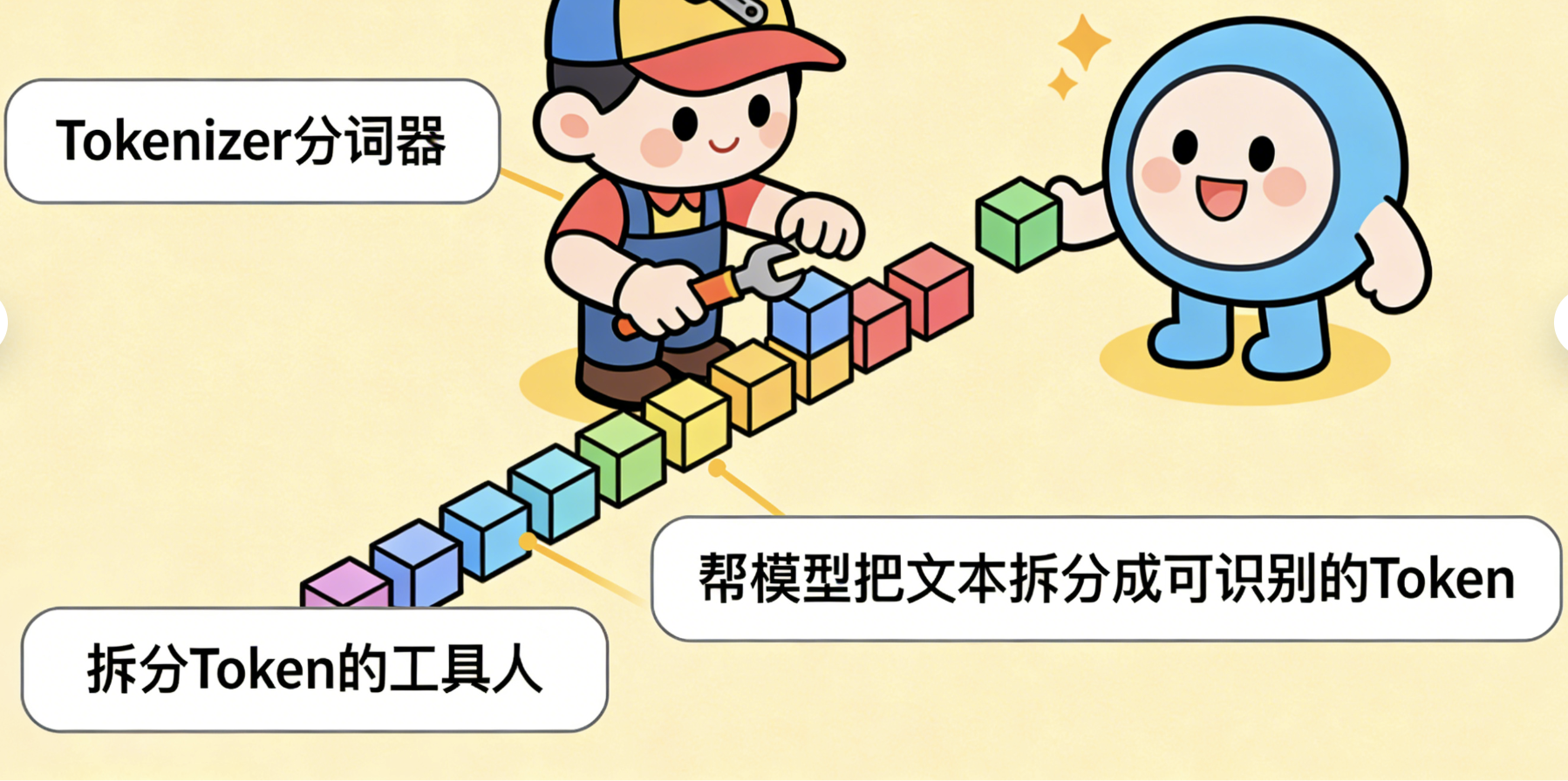
Tokenizer(Tokenizer): 分词器 :专门拆分Token的"工具人",核心作用是把人类的文本,拆分成模型能识别的Token。就像我们看书时,会把句子拆分成字和词来理解,Tokenizer就是帮模型做这件事的。

Emb(Embedding): 词嵌入/向量表示 :LLM理解文本的"核心方式"。机器看不懂文字,只能看懂"数字",Embedding就是把每个Token转换成一串数字(向量),比如把"AI"转换成【0.123, 0.456, 0.789】,这样模型就能通过计算向量之间的关系,理解文本的含义(比如"AI"和"人工智能"的向量很接近,模型就知道它们是同一个意思)。

PT(Pre-training): 预训练 :LLM的"第一次训练",也是最核心的训练步骤。简单说,就是用海量的文本数据(比如全网的文章、书籍、网页),让模型"先学一遍人类语言的规律"------比如中文的语法、常用搭配、逻辑关系。这一步就像我们小时候学说话,先听大人说,慢慢掌握语言的规律,预训练完成后,模型就有了"基础的语言能力"。

FT(Fine-tuning): 微调 :LLM的"二次训练",也是让模型"适配具体需求"的步骤。预训练后的模型,能力很通用,但可能不符合我们的具体需求(比如我们需要一个"写代码的LLM",预训练模型可能写不好代码)。微调就是用"特定领域的数据"(比如大量的代码文本),调整模型的部分参数,让模型专注于某个领域------这就像我们小时候学会说话后,再专门学习"写作文""说英语",针对性提升能力。

Prompt(Prompt): 提示词 :我们和LLM"沟通的方式",也是给LLM的**"输入指令"** 。比如"写一篇关于AI的科普文案""解释一下什么是LLM",这些都是Prompt。Prompt的好坏,直接影响LLM的输出效果------这就像我们跟人说话,指令越清晰,对方越能明白你的需求。

Hallucination(Hallucination): 幻觉 :LLM的"常见bug",指模型生成"看似合理,但实际错误"的内容。比如你问LLM"2026年的春节是哪一天",它可能会生成一个错误的日期,这就是幻觉。原因很简单:模型的参数是基于训练数据来的,如果训练数据里没有相关信息,或者有错误信息,模型就会"瞎编"------它不会判断"我是不是知道这个问题",只会根据参数计算,生成它认为"最合理"的答案。
2. LLM核心流程
三、热点解读:Agent智能体(最近爆火,一文搞懂)

最近龙虾AI智能管理助理、各种Agent工具爆火,很多人说"Agent是下一个AI风口",但其实Agent不是"新东西",而是"基于LLM的延伸"------简单说,Agent就是"给LLM装了'手脚'和'脑子',让它能主动完成任务"。
1. 核心术语(通俗解读,结合实际应用)
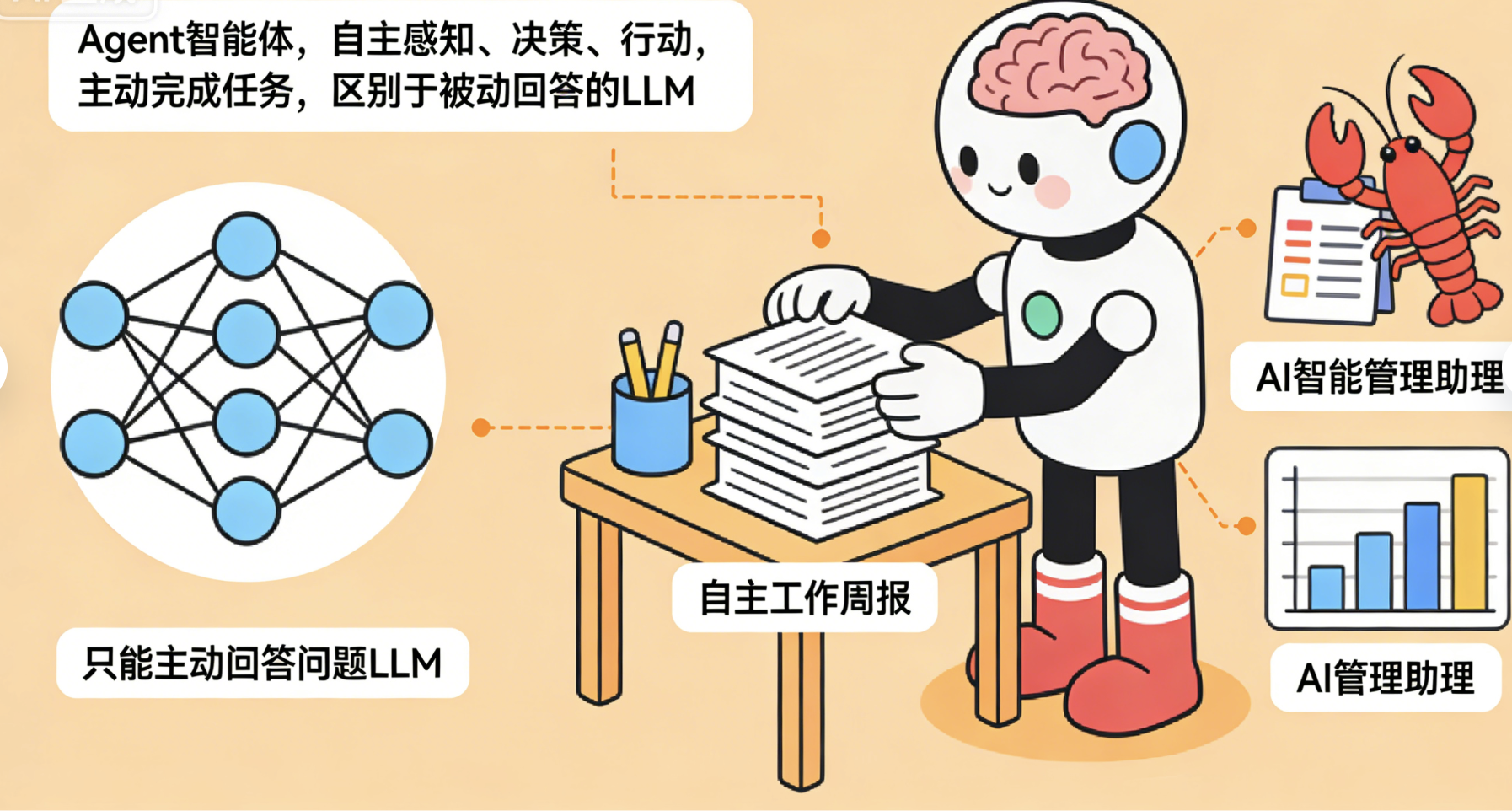
Agent(Agent): 智能体 :核心定义------"能自主感知、自主决策、自主行动的AI系统"。和LLM相比,LLM只能"被动回答问题"(你问它才说),而Agent能"主动完成任务"(比如你让它"整理一周的工作周报",它会主动找数据、整理内容、生成周报,不用你一步步指挥)。龙虾AI智能管理助理,就是一个"管理领域的Agent",能主动处理管理相关的任务(比如日程安排、数据统计)。
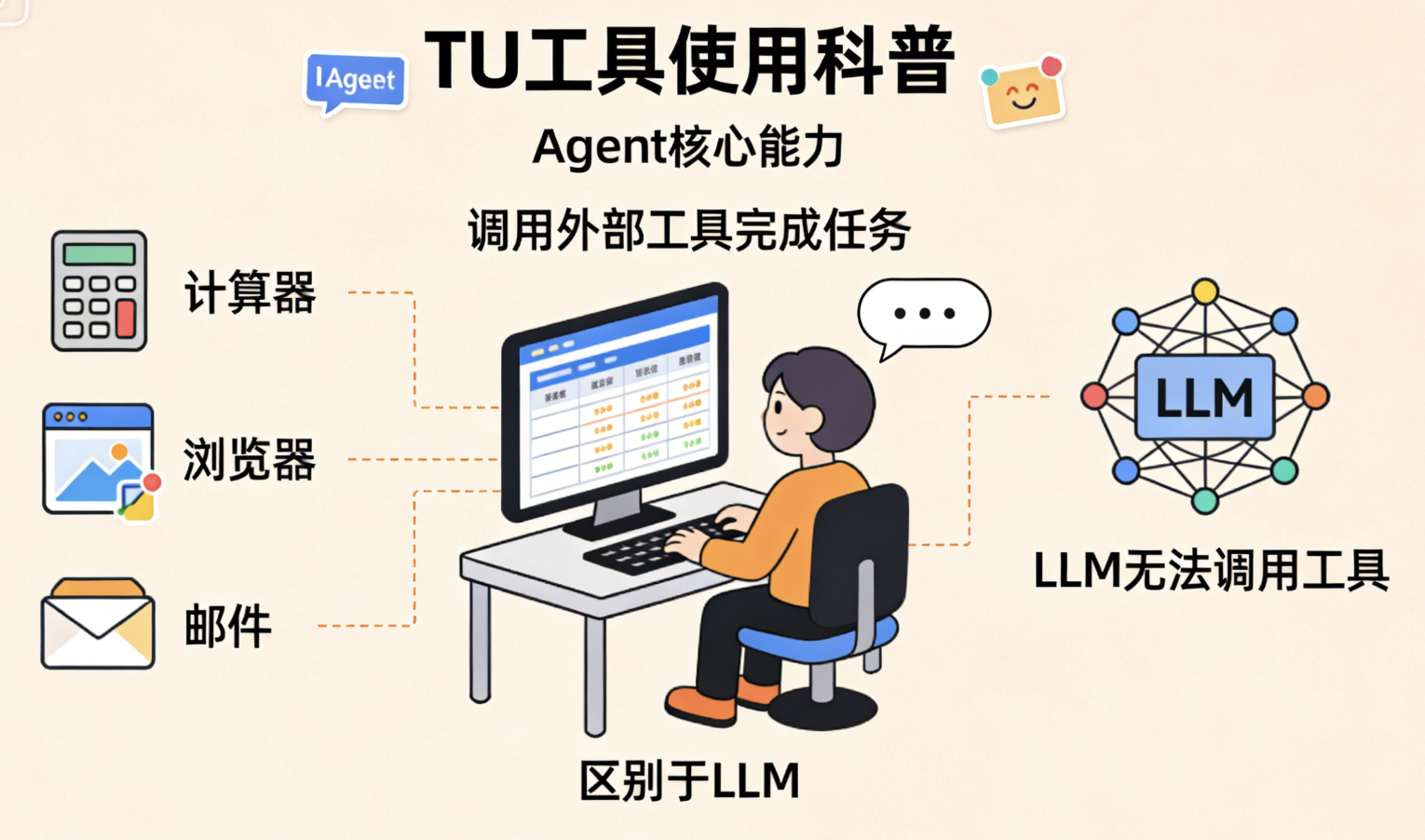
TU(Tool Use): 工具使用 :Agent的"核心能力",也是它和LLM的最大区别。Agent能调用外部工具(比如计算器、Excel、浏览器、邮件),来完成自己做不到的事情。比如你让Agent"计算公司这个月的营收",它会调用Excel工具,导入数据、计算结果,再把结果整理成文本告诉你------这就像人类做事,会用工具辅助自己,Agent也是一样。
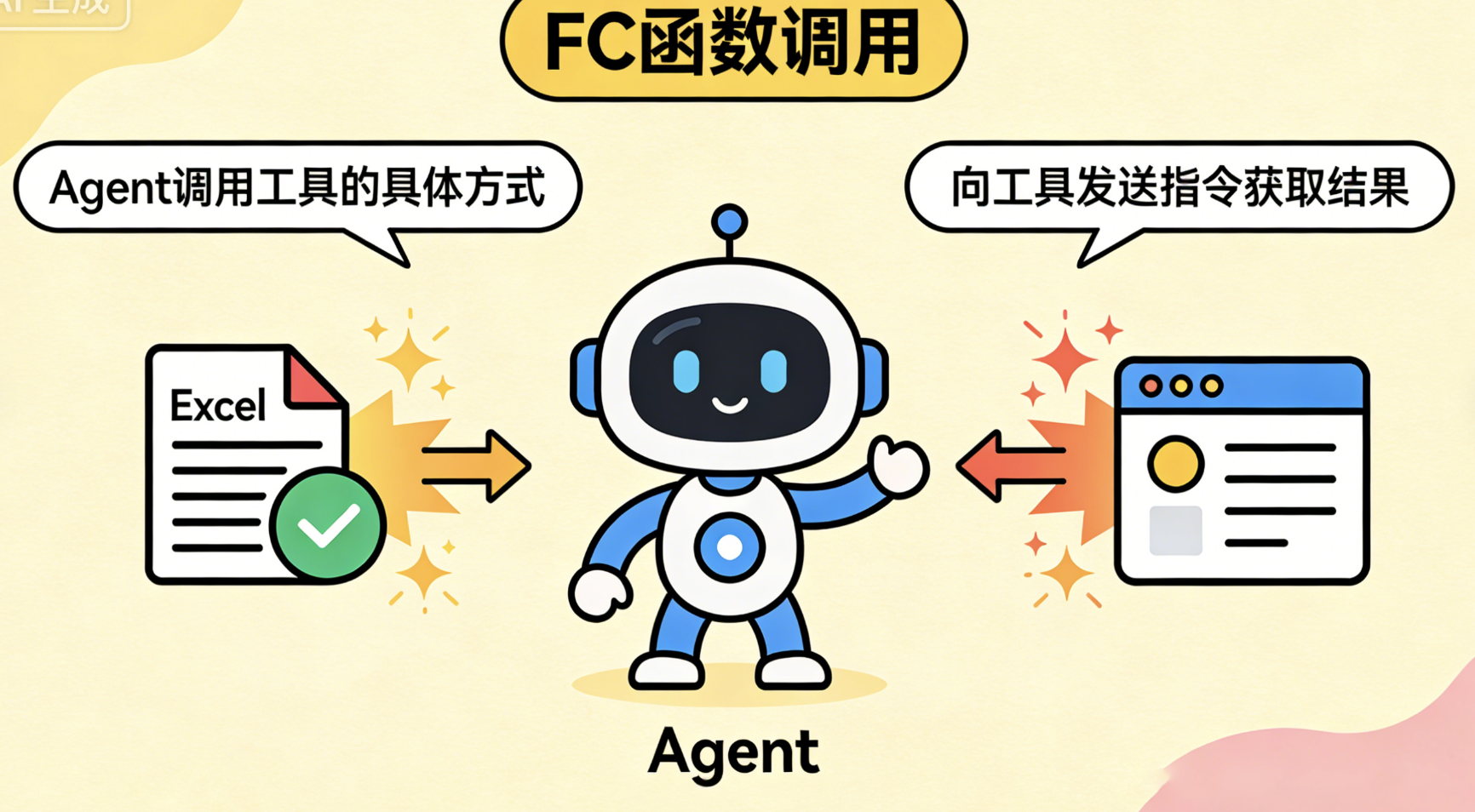
FC(Function Calling): 函数调用 :Agent调用工具的"具体方式"。简单说,就是Agent通过"调用函数",来控制外部工具------比如调用Excel的"计算函数"、浏览器的"搜索函数"。函数调用的本质 ,就是"Agent给工具发指令,工具执行后返回结果,Agent再根据结果继续行动"。

CoT(Chain of Thought): 思维链 :Agent的"思考过程"。比如你让Agent"规划一次出差行程",它不会直接给出行程,而是会一步步思考:"用户要去哪个城市?什么时候出发?需要订机票还是高铁?住哪里?要不要安排会议?"------这个思考过程,就是思维链 。LLM也能有思维链(比如你让它"解一道数学题",它会一步步给出解题步骤),但Agent的思维链更侧重"任务拆解和行动规划"。
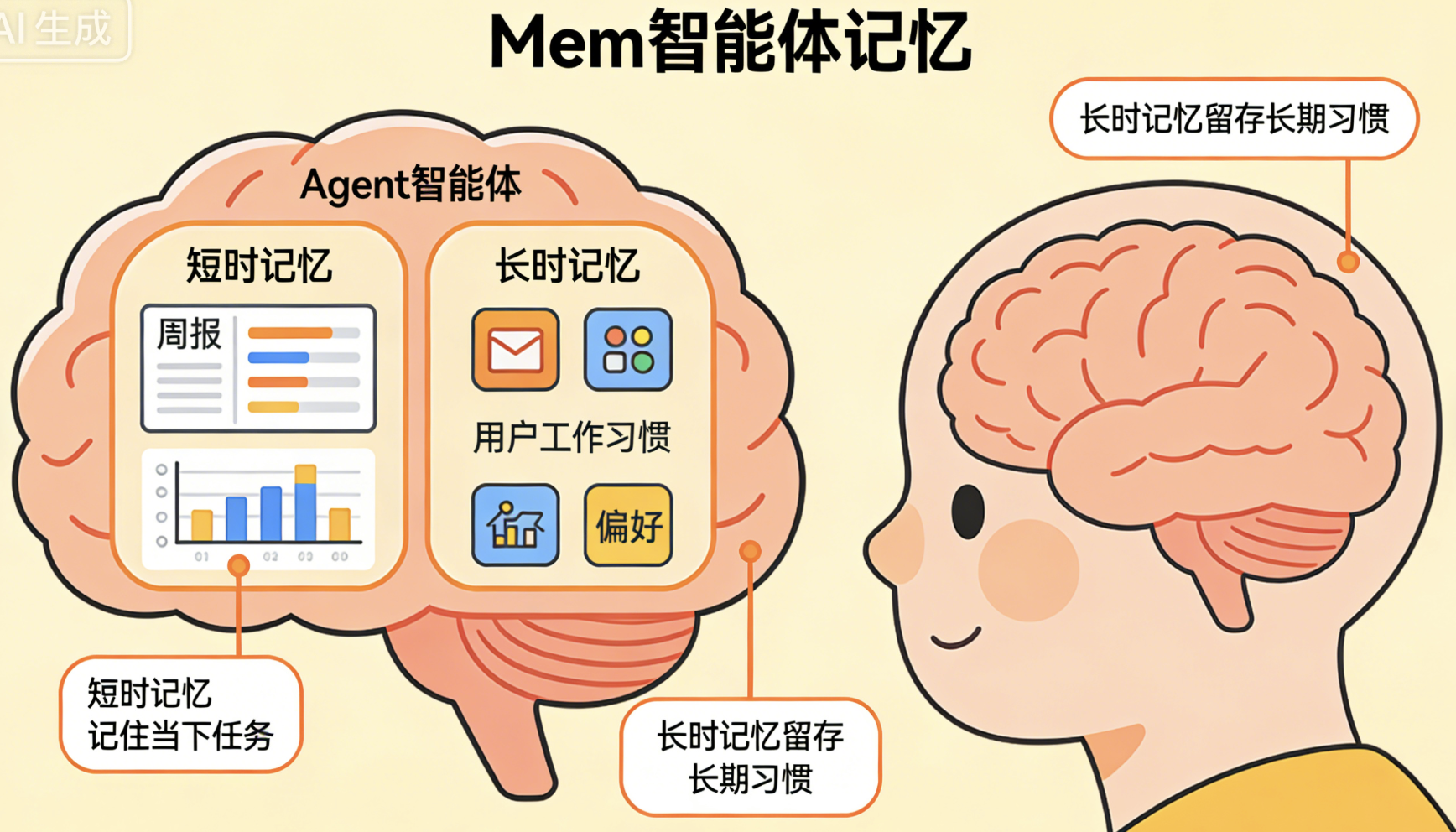
Mem(Memory): 智能体记忆 :Agent的"记忆力",分为长时记忆和短时记忆。短时记忆(STM):记住当前任务的信息(比如你让它整理周报,它会记住你要的周报格式、数据范围);长时记忆(LTM):记住长期的信息(比如你平时的工作习惯、偏好,下次你让它整理周报,它会自动按照你的偏好来)。这就像人类的记忆力,能记住当下要做的事,也能记住长期的习惯。

ReAct(Reasoning + Acting): 推理+行动范式 :Agent的"核心工作模式"------先推理(思考"要做什么、怎么做"),再行动(调用工具、执行任务),然后根据行动结果,再推理、再行动,直到完成任务。比如龙虾AI智能管理助理,接到"统计部门月度业绩"的任务后,会先推理("需要找哪些数据?用什么工具统计?怎么整理成报表?"),再行动(调用Excel导入数据、计算业绩),最后整理成报表反馈给你。
2. Agent vs LLM(核心区别,一看就懂)
| 对比维度 | LLM(大语言模型) | Agent(智能体) |
|---|---|---|
| 核心能力 | 处理文本、生成文本(被动响应) | 自主决策、调用工具、完成任务(主动行动) |
| 工作模式 | 你问我答,没有自主意识 | 推理→行动→反馈→优化,循环完成任务 |
| 依赖条件 | 依赖Prompt(你必须给指令) | 只需给目标,自主拆解任务、执行 |
| 实际例子 | 豆包、ChatGPT(你问它才回答) | 龙虾AI智能管理助理(你给目标,它主动完成) |
四、延伸补充:其他高频术语(不用死记,理解即可)
除了LLM和Agent,还有一些高频术语,在刷文章、看报道时经常遇到,这里用最通俗的话解释,不用死记硬背,知道大概意思就行。
1. 模型训练相关
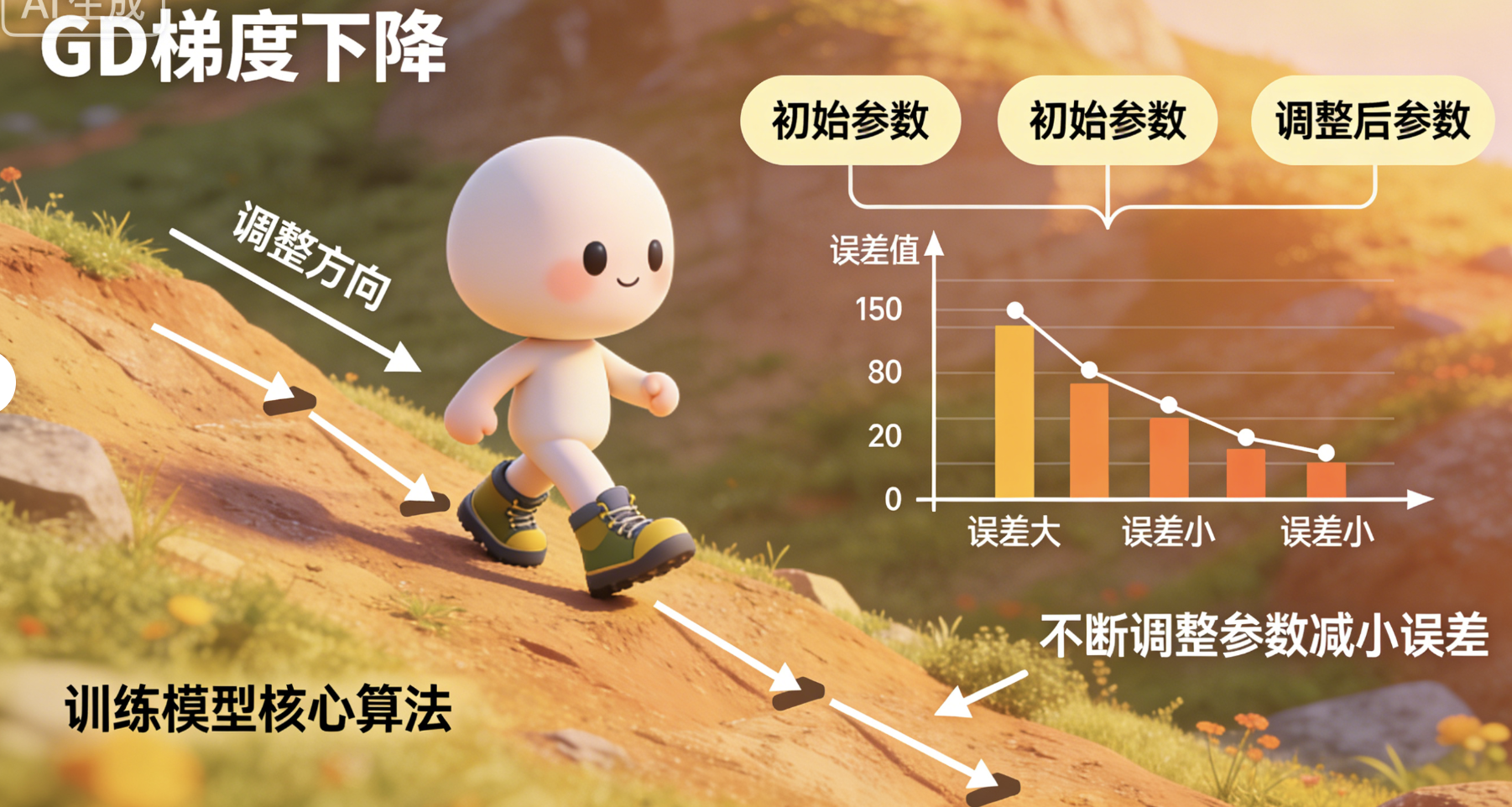
GD(Gradient Descent): 梯度下降 :训练模型的"核心算法",本质是"不断调整参数,让模型的误差越来越小" 。就像我们走路找最低点,一步一步调整方向,直到走到最低处------梯度下降就是帮模型"找到最优的参数",让模型的输出更准确。
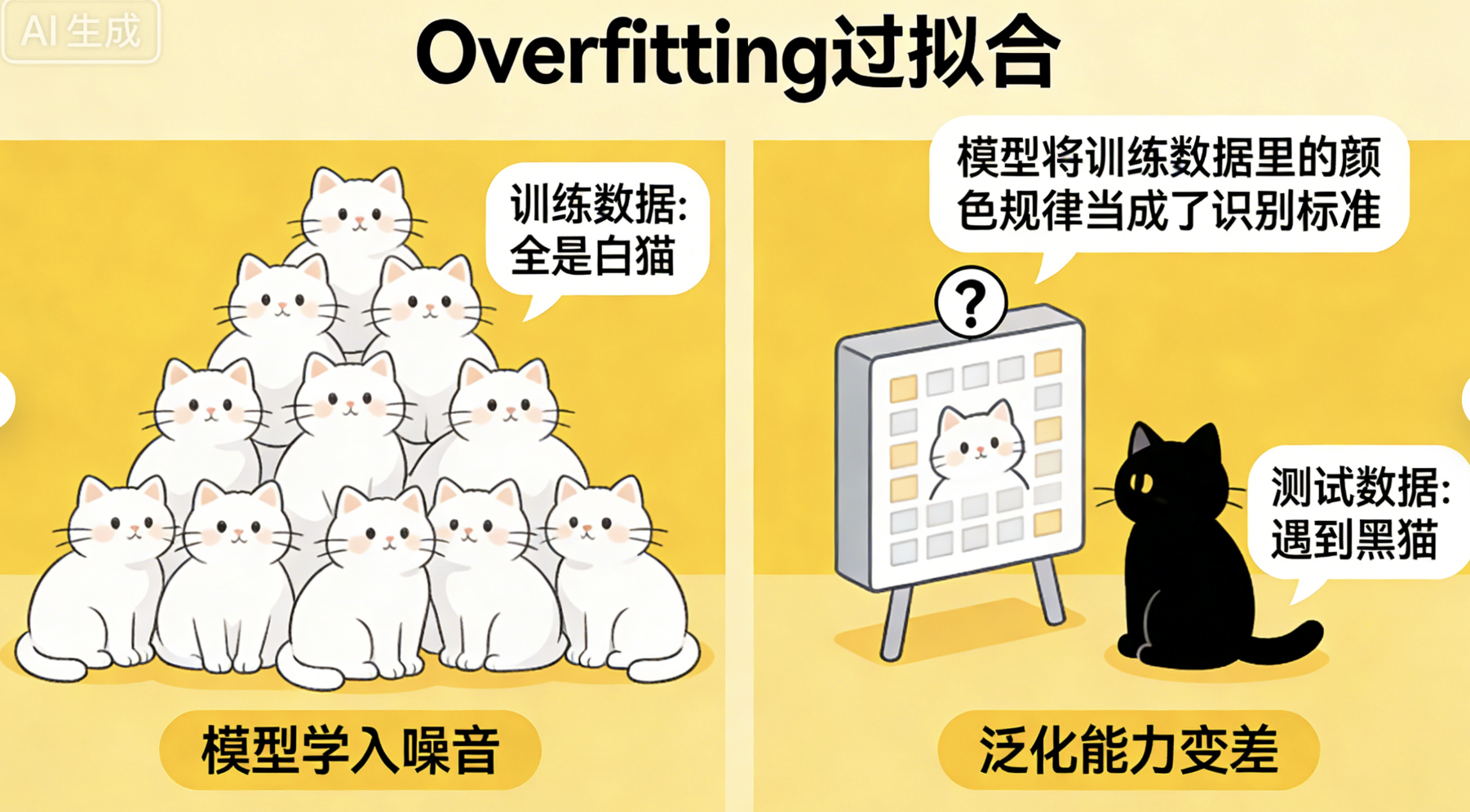
Overfitting(OF): 过拟合 :模型的"学傻了"------把训练数据里的"噪音"(比如错误的数据、偶然的规律)也学进去了,导致模型在训练数据上表现很好,但在新数据上表现很差。比如你教模型识别猫,训练数据里的猫都是白色的,模型就会认为"白色的才是猫",遇到黑色的猫就识别不出来,这就是过拟合。

Quant(Quantization): 量化 :让模型"变轻、变快"的技术。模型的参数都是高精度的数字(比如小数点后8位),量化就是把这些高精度数字转换成低精度数字(比如小数点后2位),这样模型的体积会变小,运行速度会变快,能在手机、电脑上流畅运行------我们手机里的AI工具,大多都经过了量化。
2. 多模态&AIGC相关(现在很火,简单了解)

AIGC(AI Generated Content): 人工智能生成内容 :指AI生成的所有内容,比如LLM生成的文案、AI生成的图片(文生图)、AI生成的视频(文生视频),都属于AIGC。我们平时刷到的AI绘画、AI写的小说,都是AIGC的应用。

MM(Multi-modal): 多模态 :指模型能处理"多种类型的数据",比如同时处理文本、图片、语音。比如你给模型一张图片,再问它"这张图片里有什么",模型能看懂图片,还能生成文本回答你------这就是多模态模型,比如GPT-4、豆包多模态版,都属于多模态模型。
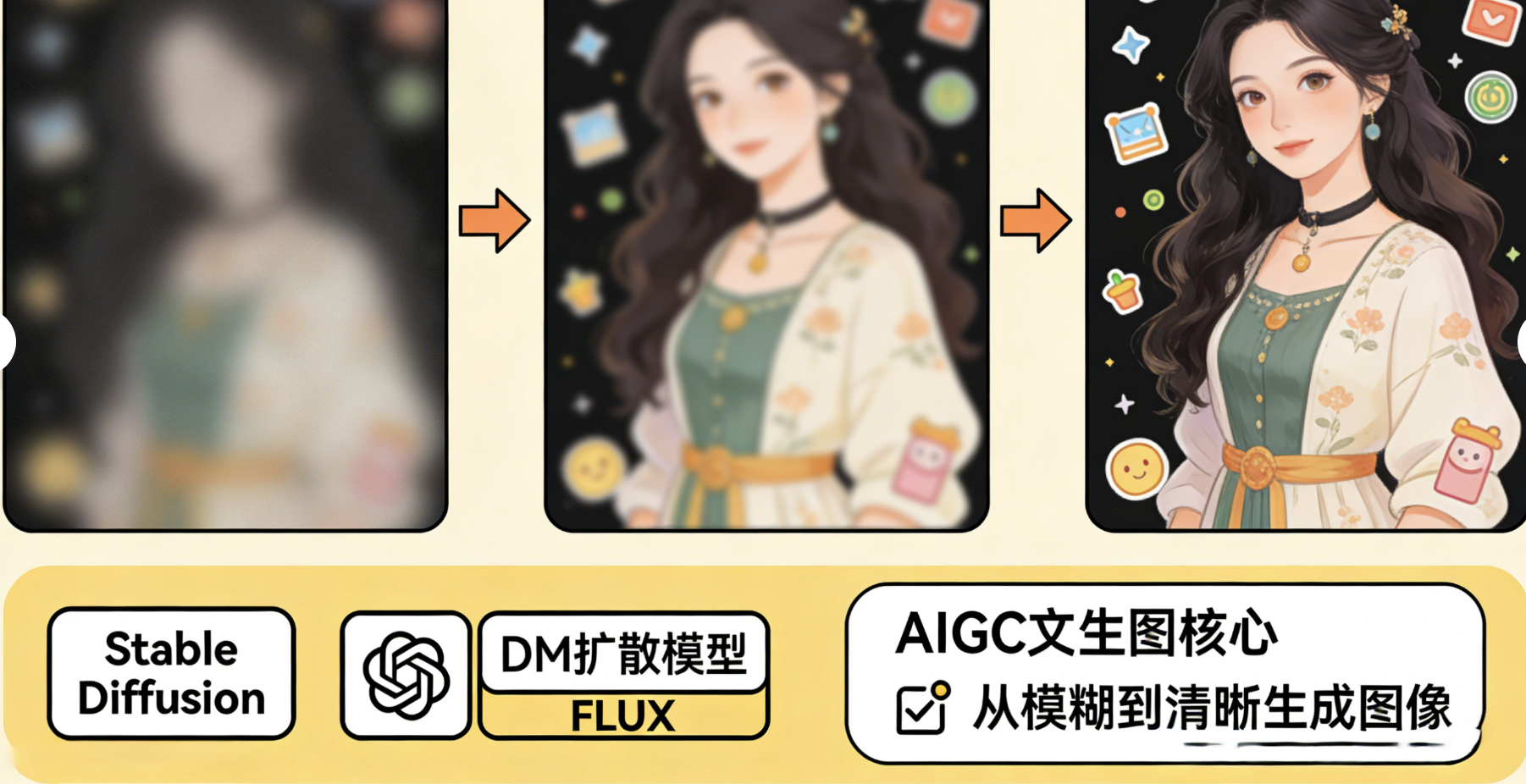
DM(Diffusion Model): 扩散模型 :AIGC(尤其是文生图)的核心模型,比如Stable Diffusion(稳定扩散)、FLUX,都是扩散模型。简单说,它的原理是"从一张模糊的图片,一步步变得清晰",就像我们画画,从轮廓开始,慢慢添加细节,最终生成一张清晰的图片。
五、最后:我们该以什么样的心态看待AI?
写这篇帖子,不是为了让大家"懂多少术语",而是希望大家能"理性看待AI"------
现在的LLM、Agent,本质上都是"工具",和我们平时用的Excel、计算器、手机一样,只是更智能、更强大而已。它们的核心原理,离不开最基础的数学逻辑(函数、参数、梯度下降),离不开科学家们几十年前奠定的理论基础(比如神经网络、机器学习算法),离不开开发者们日日夜夜在实验室里的调试、优化。
我们可以惊叹AI的强大,可以享受AI带来的便利,但不必盲目崇拜AI产品本身------值得我们崇拜的,是那些深耕AI领域、奠定原理基础的科学家,是那些熬夜优化模型、解决技术难题的开发者,是那些用AI技术创造价值、改善生活的人。
AI的迭代很快,新的术语、新的产品会不断出现,但核心逻辑不会变------只要我们掌握了这些基础概念,就能看透AI的本质,不被营销话术忽悠,真正用好AI这个工具。
最后,留一个小问题:你平时用得最多的AI工具是什么?遇到过哪些不懂的AI术语?欢迎在评论区留言,我们一起交流、一起扫盲~
觉得有用的话,点赞+收藏,关注我,后续持续更新AI基础扫盲内容,帮你轻松看懂AI!