什么是词向量
词向量(Word Embedding)是将人类可读的文本词汇转化为机器可理解的低维稠密实数向量的技术,核心价值是解决传统文本表示(如 One-Hot 编码)的维度灾难和语义鸿沟问题。
其核心假设为 "上下文相似的词,语义也相似",通过模型学习词与上下文的映射关系,使语义相近的词在向量空间中距离更近,还具备 "国王 - 男人 + 女人 = 女王" 这类语义运算特性,为评论情感分类、主题聚类等 NLP 任务提供高质量特征输入。
在自然语言处理(NLP)领域,词向量(Word Embedding) 是将文本中的词语转换为数值向量的技术,它解决了传统文本表示方法的局限性,为机器学习模型理解语言语义提供了基础。
主流词向量模型
主流词向量模型可分为两大类,具体如下:
一、基于统计的模型
代表模型:LSA(潜在语义分析)
核心逻辑:通过对文本语料构建词-文档矩阵,再利用奇异值分解(SVD)降维,得到词的低维向量表示,核心是捕捉词与文档间的全局统计关联。
二、基于神经网络的模型(应用更广泛)
-
Word2Vec:工业界/学术界常用基础模型,核心假设"上下文相似的词语义相似",分Skip-Gram(给定中心词预测上下文,适配低频词多的数据集)和CBOW(给定上下文预测中心词,训练快、适配高频词多的大规模数据),通过负采样、层次Softmax优化训练效率。
-
GloVe:结合全局词频统计与局部上下文信息,语义表示更精准,适合大规模语料处理。
-
FastText:支持未登录词(OOV词)向量生成,通过子词(n-gram)信息提升泛化能力,适配口语化、新词多的评论类数据。
-
预训练语言模型向量(如BERT、RoBERTa):提取上下文相关向量,能捕捉词在不同语境下的多义性(如"苹果"的不同语义),是当前NLP任务的SOTA方案,无需手动构建词向量。
词向量转化的小例子
从特征提取库中导入向量转化模块儿, 自然语言 转换成 数据的形式,才能保证模型进行训练
1、基于统计的方法 统计每个单词在这句话中出现的次数
2、基于神经网络模型训练的方法
解释:ngram_range(1, 2):对词进行组合,文字进行频率的统计。基于整个文本库来进行统计。
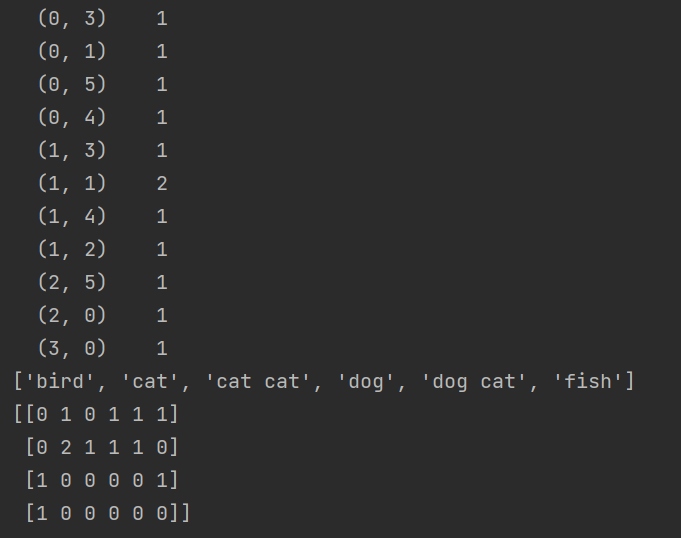
(1)本例组合方式:两两组合 #贝叶斯 模型,它只能识别数字, 传入模型,'bird', 'cat', 'cat cat', 'cat fish', 'dog', 'dog cat', 'fish', 'fish bird'
(2)如果ngram_range(1, 3),则会出现3个词进行组合 'bird', 'cat', 'cat cat', 'cat fish', 'dog', 'dog cat', 'dog cat cat','dog cat fish', 'fish', 'fish bird'
代码如下:
python
from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird", 'bird']
cont = []
#实例化一个模型
cv = CountVectorizer(max_features=6,ngram_range=(1,3)) #,统计每篇文章中每个词出现的频率次数
#训练此模型
cv_fit=cv.fit_transform(texts)#每个词在这篇文章中出现的次数
print(cv_fit)
# 打印出模型的全部词库
print(cv.get_feature_names())
#打印出每个语句的词向量
print(cv_fit.toarray())
# #打印出所有数据求和结果
# print(cv_fit.toarray().sum(axis=0))#运行结果:
评论判断项目案例(好评差评的判断)
现在需要用词向量的方法来训练一个好评差评的分析模型,
数据就用爬虫爬取的苏宁易购的数据
具体代码:
1、数据读取与处理
python
import pandas as pd
cp_content = pd.read_table(r".\差评.txt",encoding='gbk')
yzpj_content = pd.read_table(r".\优质评价.txt",encoding='gbk')2、使用jieba分词 jieba.lcut() 和jieba.cut()
对差评进行分词
python
import jieba#
cp_segments = []
contents = cp_content.content.values.tolist()#将content列数据取出并转化为list格式;目的是分别 jieba.lcut分词
for content in contents:
results = jieba.lcut(content)
if len(results) > 1 :#当分词之后,这条评论如果只有1个内容,
cp_segments.append(results) #将分词后的内容添加到列表segments中
cp_fc_results=pd.DataFrame({'content':cp_segments})
cp_fc_results.to_excel('cp_fc_results.xlsx',index=False)对好评进行分词
python
yzpj_segments = []
contents = yzpj_content.content.values.tolist()#将content列数据取出并转化为list格式。目的是分别 jieba.lcut分词
for content in contents:
results = jieba.lcut(content)
if len(results) > 1 :
yzpj_segments.append(results) #将分词后的内容添加到列表segments中分词结果储存在新的数据框中
python
yzpj_fc_results=pd.DataFrame({'content':yzpj_segments})
yzpj_fc_results.to_excel('yzpj_fc_results.xlsx',index=False)3、移除停用词
我们把所有的评论内容都进行jieba ,但是分词中有一些内容是无意义的,所以要移除这些停用词
segments_clean:每一篇文章的分词结果
all_words:所有文章总的分词结果
导入停用词库
python
stopwords = pd.read_csv(r".\StopwordsCN.txt",encoding='utf8', engine='python',index_col=False)定义去除停用词函数
python
def drop_stopwords(contents, stopwords):
segments_clean = []
for content in contents:
line_clean = []
for word in content:
if word in stopwords:
continue
line_clean.append(word)
segments_clean.append(line_clean)
return segments_clean调用去除停用词函数
python
contents = cp_fc_results.content.values.tolist() # DataFrame格式转为list格式
stopwords = stopwords.stopword.values.tolist() # 停用词转为list格式
cp_fc_contents_clean_s = drop_stopwords(contents, stopwords)
contents = yzpj_fc_results.content.values.tolist() # DataFrame格式转为list格式
yzpj_fc_contents_clean_s = drop_stopwords(contents, stopwords)4、朴素贝叶斯分类
给每个数据添加数字标签
python
cp_train=pd.DataFrame({'segments_clean':cp_fc_contents_clean_s, 'label':1})#构建一个表格数据
yzpj_train=pd.DataFrame({'segments_clean':yzpj_fc_contents_clean_s, 'label':0})
pj_train = pd.concat([cp_train,yzpj_train])
pj_train.to_excel('pj_train.xlsx',index=False)数据切分
训练集特征、测试集特征、训练集标签、测试集标签
python
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = \
train_test_split(pj_train['segments_clean'].values,
pj_train['label'].values, random_state=0) #test_size使用默认值将所有的词转换为词向量
python
words = [] #转换为词向量CountVectorizer所能识别的列表类型
for line_index in range(len(x_train)):
words.append(' '.join(x_train[line_index]))
print(words)导入词向量转化库
python
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(max_features=4000,lowercase = False, ngram_range=(1,3))
#lowercase参数的功能:把所有的词是是否需要转换为小写。False。
#max_features:表示只提取前4000个词作为词库。
vec.fit(words)#传入训练集的所有文字,根据文字构建模型,要将训练集 的所有单词作为词库, 一会还有测试集的文本,导入朴素贝叶斯分类器
python
from sklearn.naive_bayes import MultinomialNB,ComplementNB
classifier = MultinomialNB(alpha = 0.1)#
classifier.fit(vec.transform(words), y_train)#54093*4000
train_pr = classifier.predict(vec.transform(words))#训练数据集的测试,
#训练集数据预测得分
from sklearn import metrics
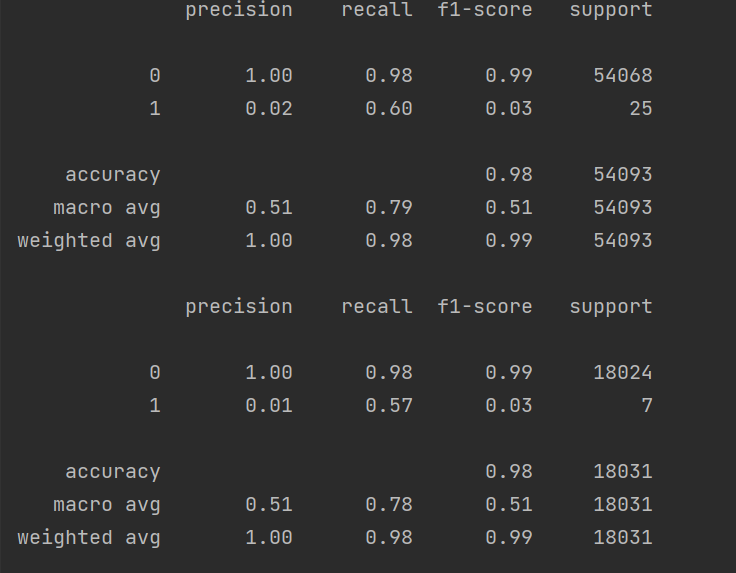
print(metrics.classification_report(y_train, train_pr))#分类结果。
#测试集数据进行分析
test_words = []
for line_index in range(len(x_test)):
test_words.append(' '.join(x_test[line_index]))
test_pr = classifier.predict(vec.transform(test_words))#基于 训练集的词库转换得到的词向量
#测试集数据预测得分
print(metrics.classification_report(y_test, test_pr))#分类结果。运行结果:
5、交互测试
python
while True:
text_something = input('请输入一段评价(输入exit退出):')
if text_something == 'exit':
break
seg_list = jieba.lcut(text_something)
seg_clean = [word for word in seg_list if word not in stopwords]
text_processed = [' '.join(seg_clean)]
text_vec = vec.transform(text_processed)
predict = classifier.predict(text_vec)
if predict[0] == 1:
print("预测结果:差评")
else:
print("预测结果:优质评价")运行结果:
