0901:概述
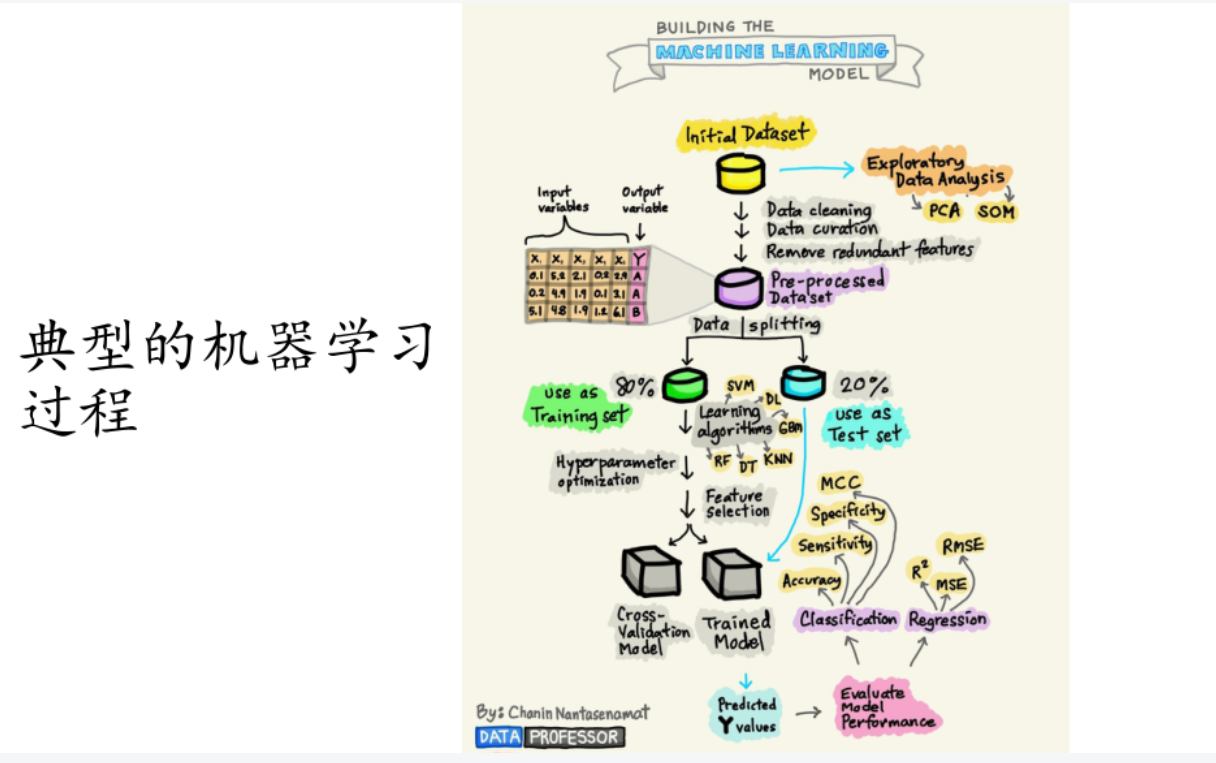
xx空间:所有xx一起张成的一个集合想·
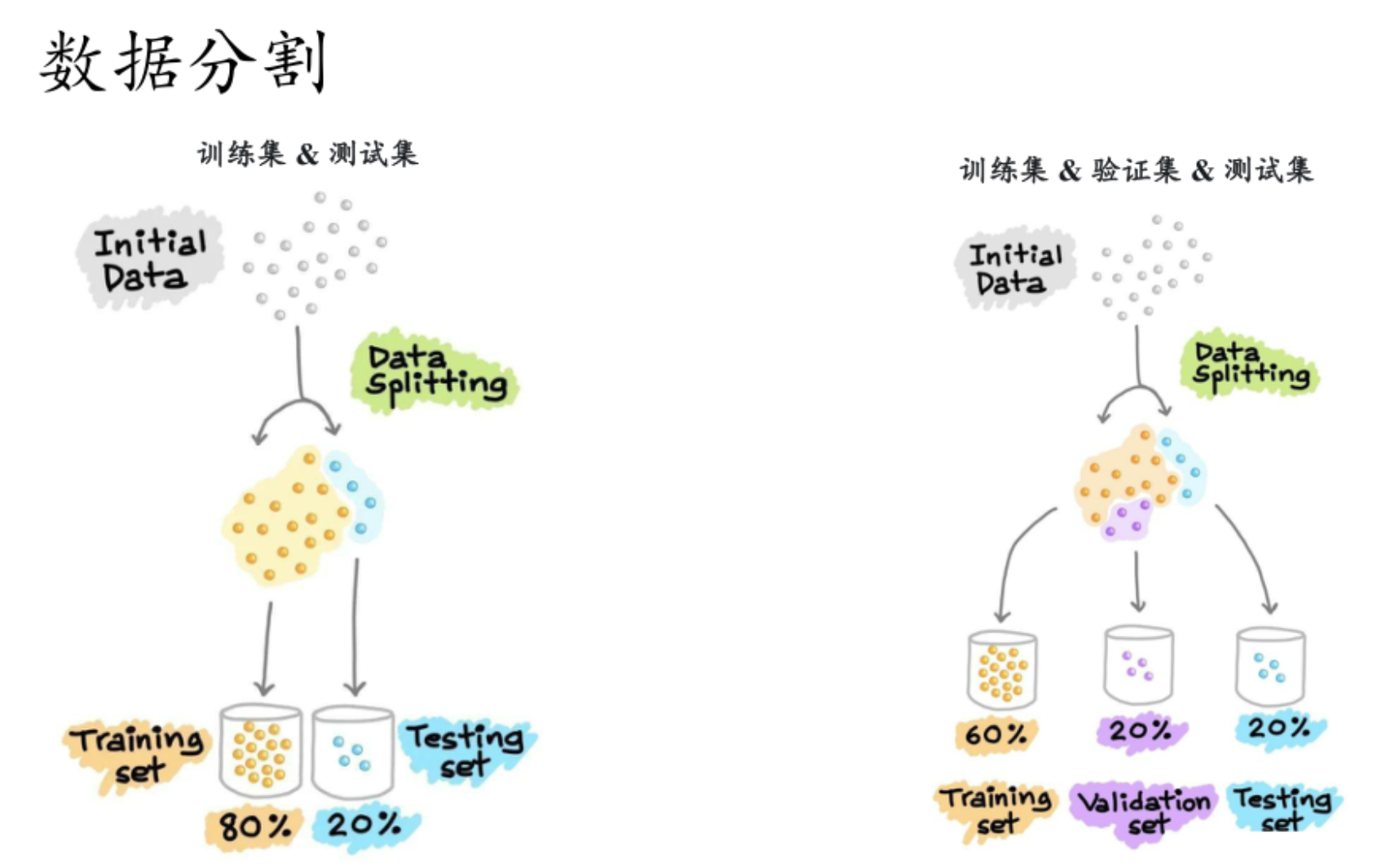
测试集只有最后模型出厂的时候才有,只能用一次,用完就得要要结项了。
验证集可以"用多次":训练-》验证-》调整参数等-》再训练
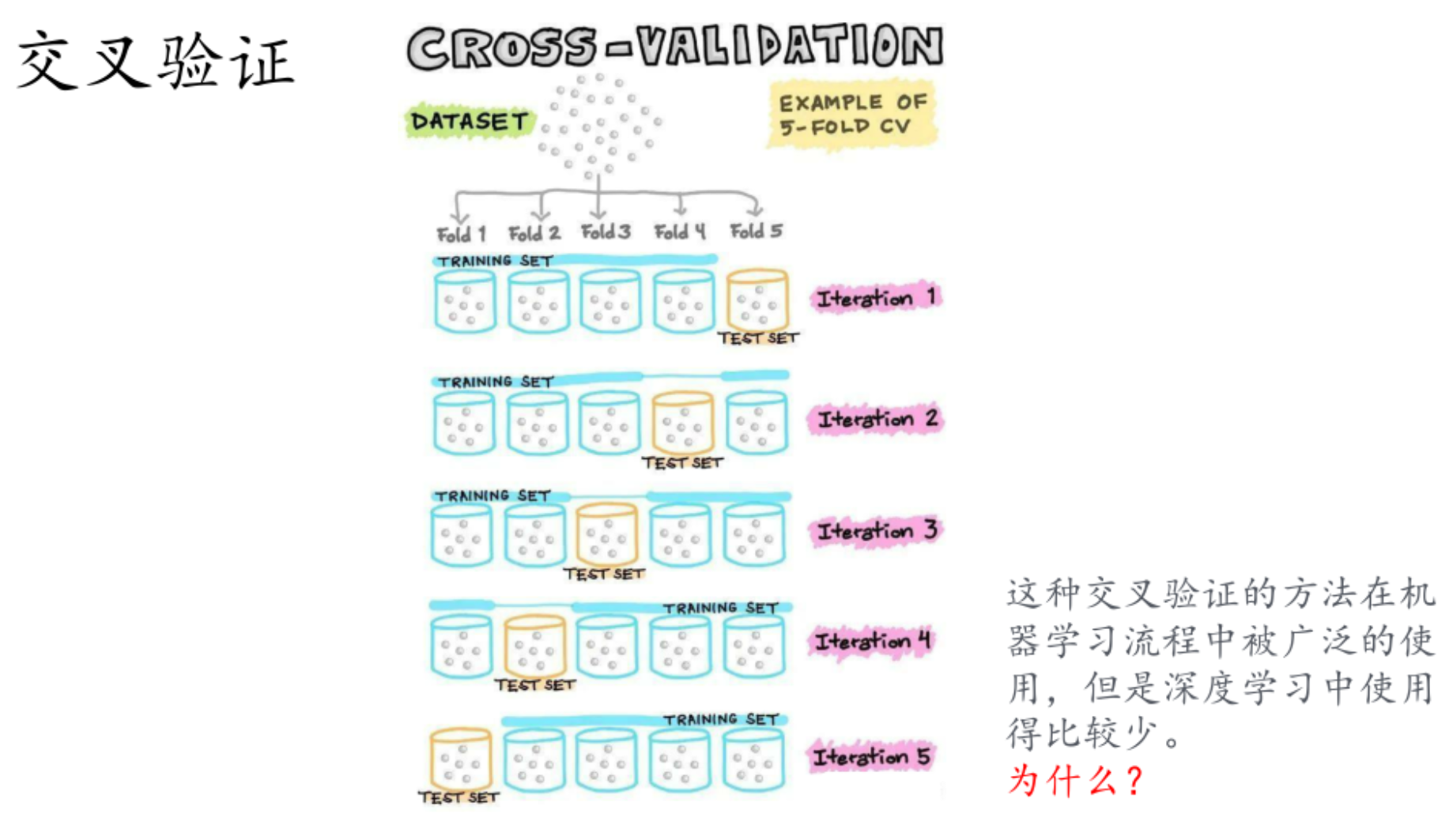
交叉验证的本质是通过 "多次划分训练 / 验证集、重复训练模型" 来评估模型泛化能力,但其设计前提是 "数据量小、模型训练快" ------ 而深度学习恰好相反,这导致交叉验证在深度学习中 "性价比极低"。但深度学习的应用场景大多满足 **"大数据假设",**无需交叉验证 "补精度"
他们的关键区别是什么,一句话概括:
- 有监督学习利用带标签数据学习输入输出关系
- 无监督学习从无标签数据中探索模式规律
- 强化学习通过与环境交互并依据奖励优化动作序列。
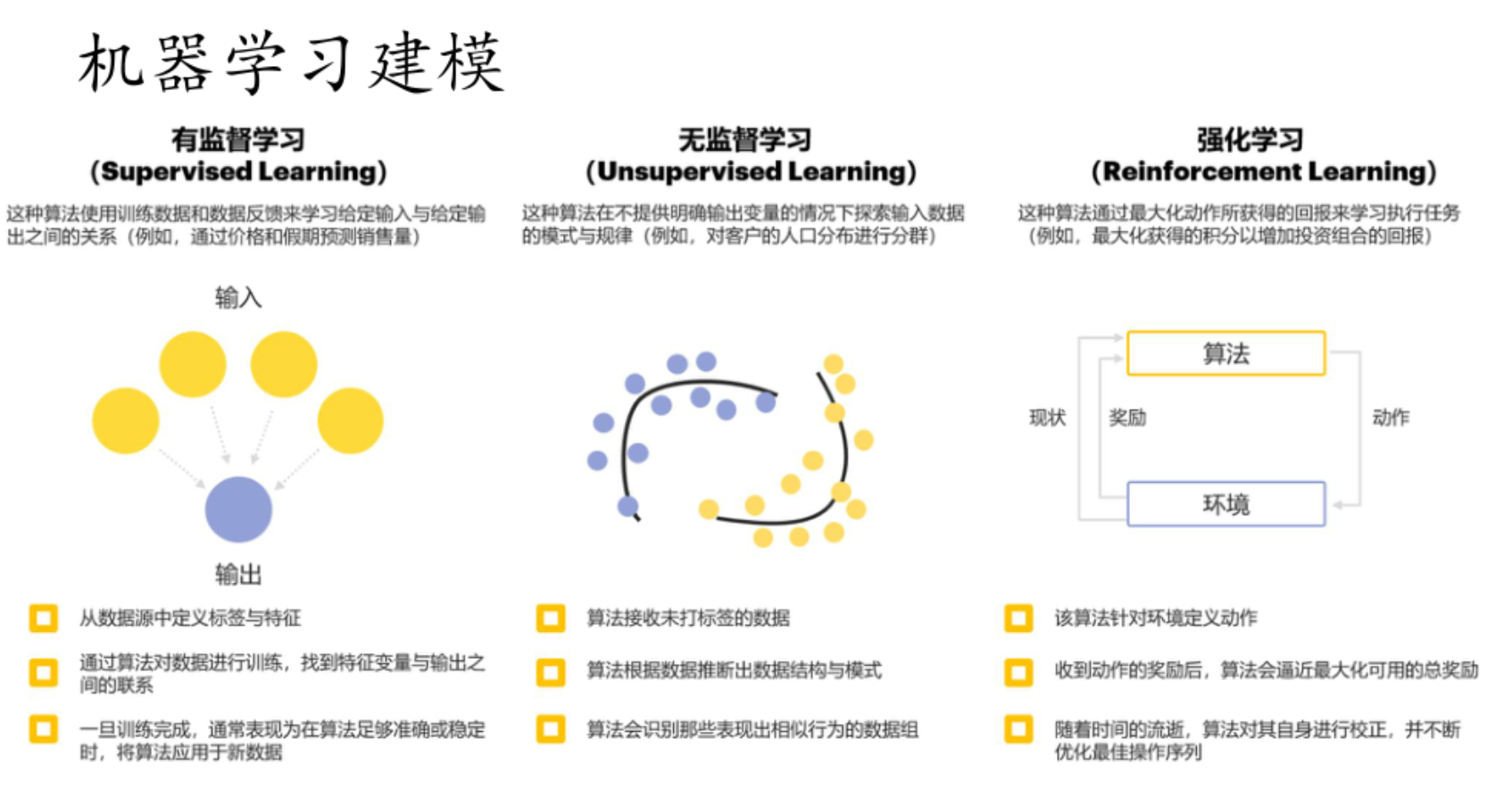
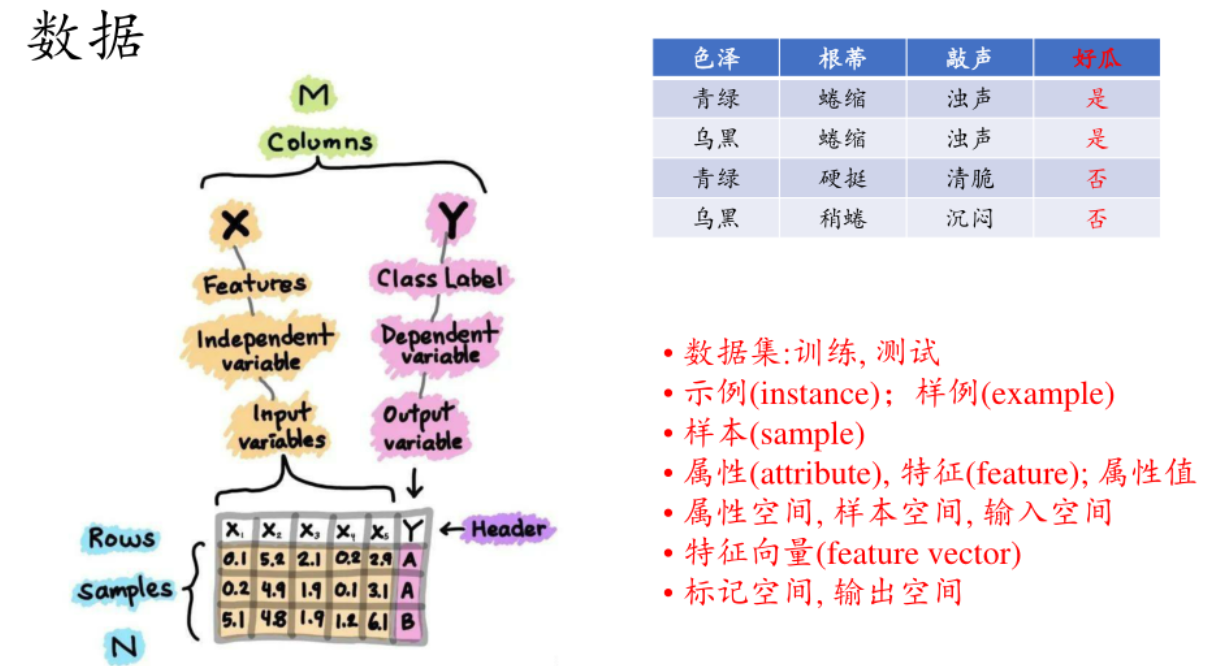
**"打了标签的数据"**指的是为数据添加了明确目标信息的数据 ,这些目标信息能反映数据的类别、属性或者期望得到的输出结果等。以下为你详细解释并举例:
- 图像分类:在一个猫狗图像分类任务中,会收集大量的猫和狗的图像。打标签就是明确指出每张图像里的动物是猫还是狗。比如有一张图像,我们给它打上 "猫" 这个标签,这样带有 "猫" 标签的图像数据,就属于打了标签的数据。
**特征:**将某个量给统计与量化,形成特征
- 词袋模型(Bag of Words)特征:把文本中出现的所有单词提取出来,构建一个词汇表。对于每一封邮件,统计词汇表中每个单词在该邮件中出现的次数,这些次数就构成了特征。比如词汇表中有 "促销""免费""点击" 等单词,某封邮件中 "促销" 出现 3 次,"免费" 出现 2 次,"点击" 出现 1 次 ,那么 3, 2, 1 等这样的数值组合就代表了这封邮件在词袋模型下的特征。
0903:数据
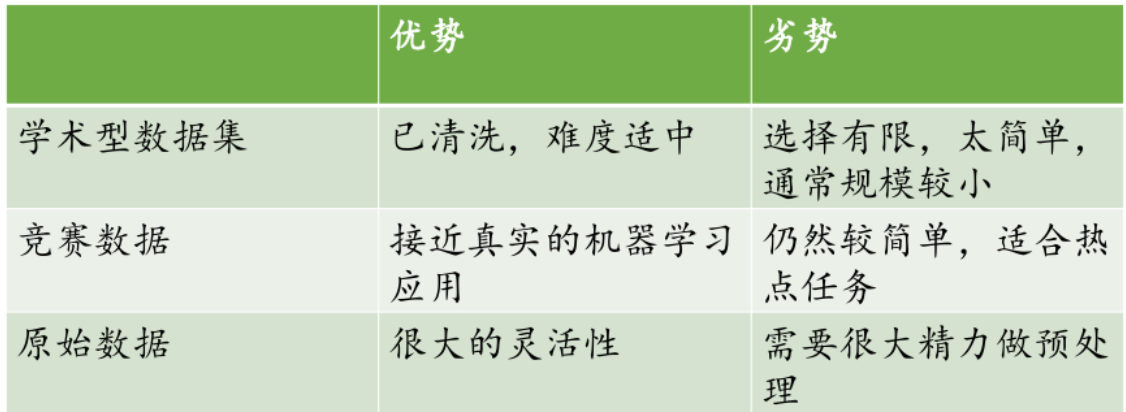
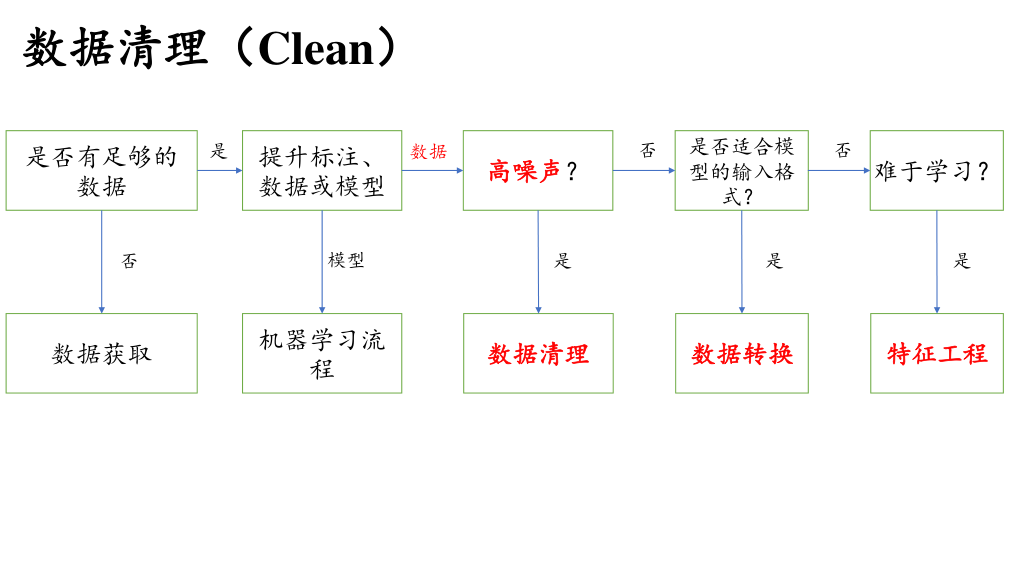
数据不够?找!
找不到了,自己生成
两种数据生成的方法:【了解】
数据增强 是指对已有的真实数据进行一系列变换操作,从而扩充数据集的规模和多样性,提升模型的泛化能力,让模型在不同的数据形态下都能学习到更稳健的特征。这种方法主要用于图像、语音、文本等多种类型的数据
合成数据 生成是利用算法和模型,基于一定的规则或模式,创造出全新的、模拟真实世界的数据。它可以在真实数据不足、获取成本高或涉及隐私等情况下,为模型训练提供补充数据。常见的合成数据生成方式如下:
- 基于生成模型 :
- 生成对抗网络(GAN):由生成器和判别器组成,生成器负责生成模拟数据(如生成逼真的人脸图像、手写数字图像等),判别器判断数据是真实数据还是生成数据,二者相互对抗、不断优化,最终生成器可以生成高质量的合成数据。
- 变分自动编码器(VAE):通过对输入数据进行编码和解码操作,学习数据的潜在分布,然后从潜在分布中采样生成新的数据。比如在医学影像数据稀缺的情况下,VAE 可以学习已有影像数据的特征分布,生成新的类似医学影像。
- 规则模拟生成:在一些结构化数据场景中,依据业务规则和统计特性来生成数据。例如,在金融领域模拟客户的交易数据,根据平均交易金额、交易时间间隔等统计特征,结合业务规则(如单笔交易金额上限等),生成模拟的交易流水数据 。
数据标注

流形假设认为,这些高维的数据实际上是在一个低维的流形上分布的。也就是说,数据的内在复杂性比我们最初看到的高维数据所呈现的要低。
基于这个假设,我们可以使用降维的方法,比如将高维数据映射到二维或三维空间进行可视化。通过这种方式,我们可以更清晰地观察到数据的结构和分布情况。
主动学习+自训练
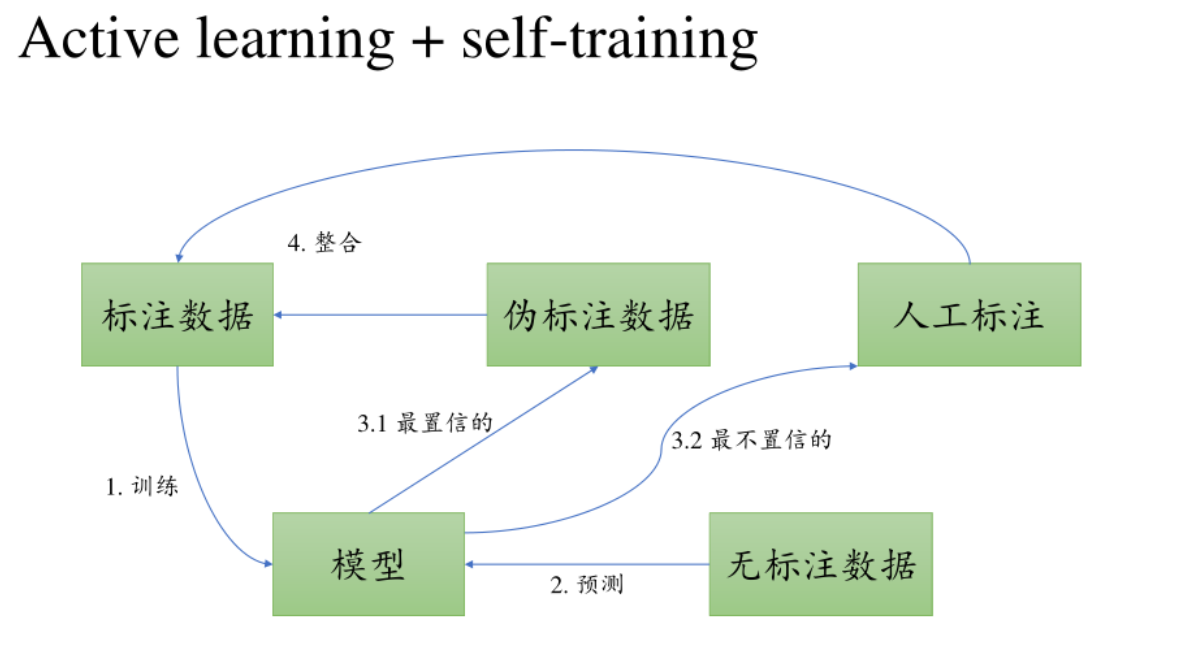
标注的数据训练模型,用模型给没标注的做标注,保留执行度高的标注数据,整合到标注数据的数据集里;置信度低的人工来做
白化处理【p40】
特征的相关性越低,说明特征之间表征的意思相近,可以适当去除重复的
白化后留下的特征之间的关联性降低
特征工程这一块已经相对比较少了,一般用神经网络来提取特征
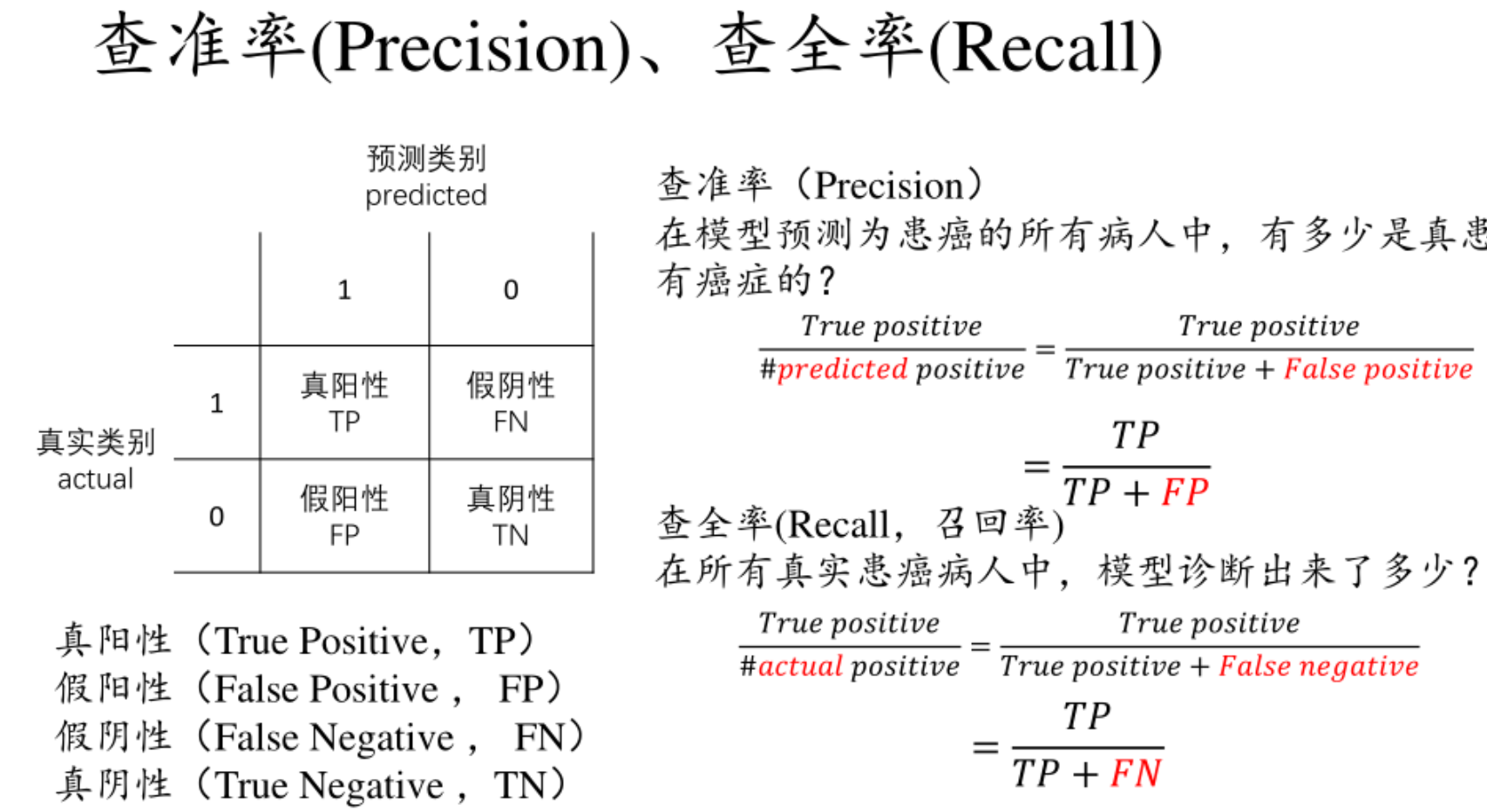
评估【精确率&召回率】
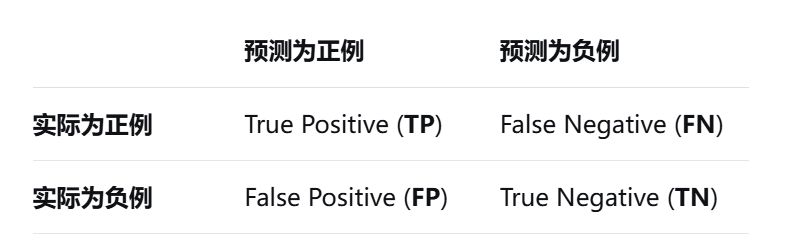
- 筛出来的是重要消息(对的,留下了)→ 叫 "真阳性"(TP);
- 筛出来的是无关消息(错了,误留了)→ 叫 "假阳性"(FP);
- 没筛出来,但其实是重要消息(错了,漏掉了)→ 叫 "假阴性"(FN);
- 没筛出来,确实是无关消息(对的,滤掉了)→ 叫 "真阴性"(TN);
记忆:分子都是TP,分母都是TP+
1. 精确率:"筛出来的,到底有多准?"【左边第一列】
精确率关注的是 ------你筛选出来的结果里,真正有用的比例有多少。比如你筛出了 10 条 "重要消息",但里面有 3 条其实是广告(假阳性),只有 7 条是真的重要消息(真阳性)。那精确率就是:「真阳性 ÷ (真阳性 + 假阳性)」= 7÷10=70%。通俗说就是 "别把垃圾当宝贝"------ 精确率低,说明你留了太多无关信息,比如手机里堆了一堆误判的广告,还得手动删,麻烦。
2. 召回率:"该找的,到底找全了没?"【上面第一行】
召回率关注的是 ------所有真正有用的东西里,你成功找出来的比例有多少。比如手机里其实有 15 条重要消息,但你的筛选规则只筛出了 7 条(真阳性),还有 8 条没筛出来(假阴性,比如有的重要消息没带 "会议" 关键词)。那召回率就是:「真阳性 ÷ (真阳性 + 假阴性)」=7÷15≈47%。通俗说就是 "别把宝贝当垃圾扔了"------ 召回率低,说明你漏了很多重要信息,比如错过关键会议通知,要出问题。
3. 一句话总结区别:
- 精确率:"宁缺毋滥"------ 比如筛选 "必须回复的紧急消息",要尽量少误判(精确率高),哪怕漏几条不紧急的也没关系;
- 召回率:"宁滥勿缺"------ 比如筛选 "可能涉及项目的消息",要尽量多找(召回率高),哪怕多留几条无关的,也不能漏了关键信息。
0908:训练
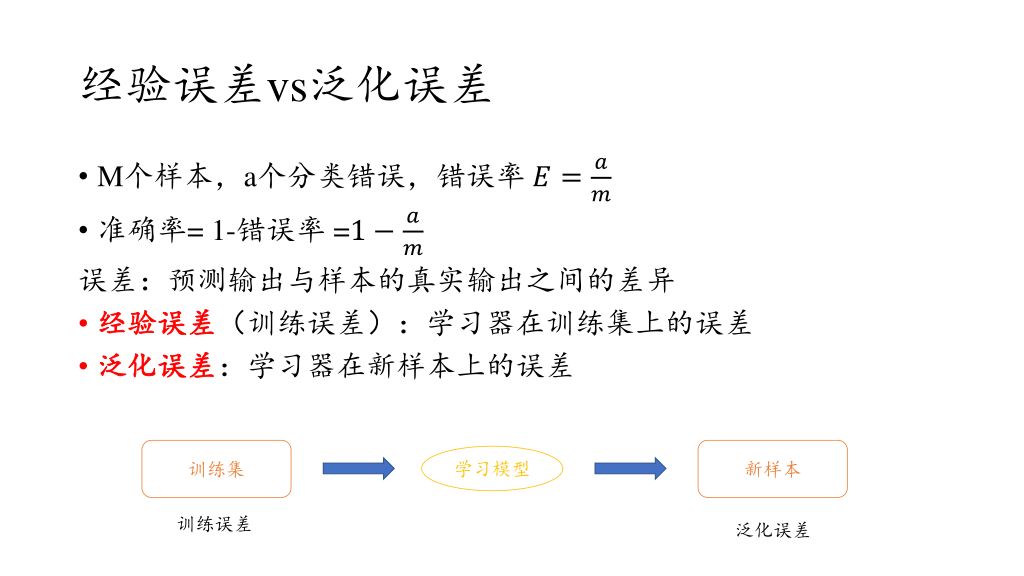
经验误差=训练误差【学习器在训练数据上的预测误差】
泛化误差【对于新样本的预测误差】
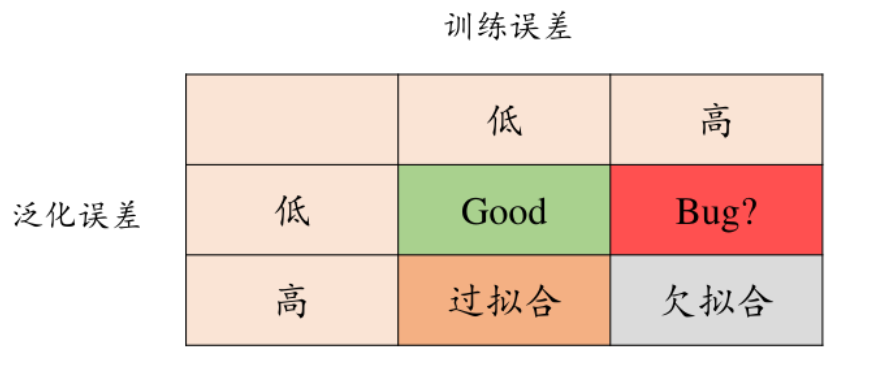
过拟合& 欠拟合
Gerneralization Error:泛化误差
Optimal model:最佳模型【泛化误差最低的时候】
【下图是在同一数据集下的情况】
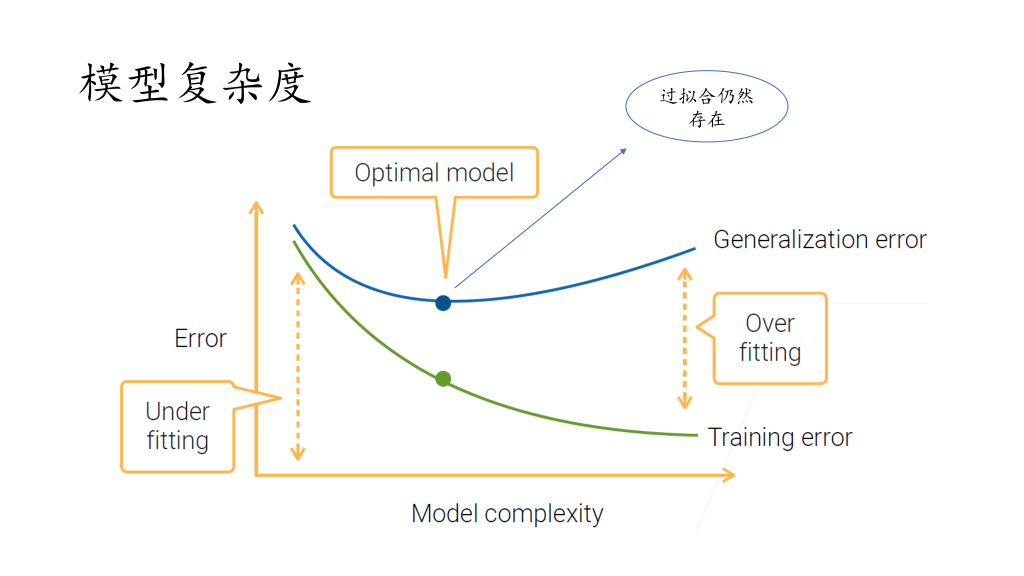
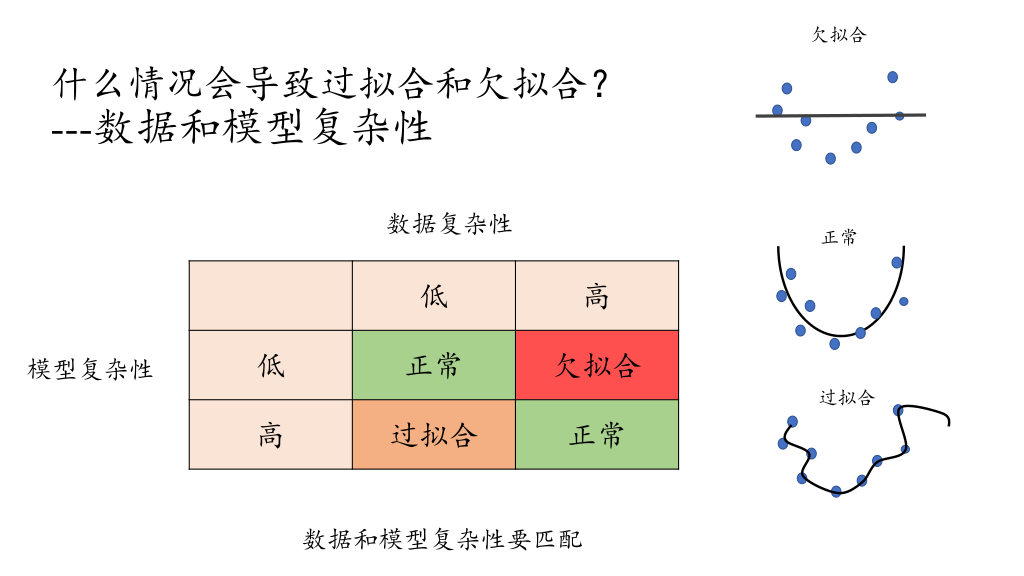
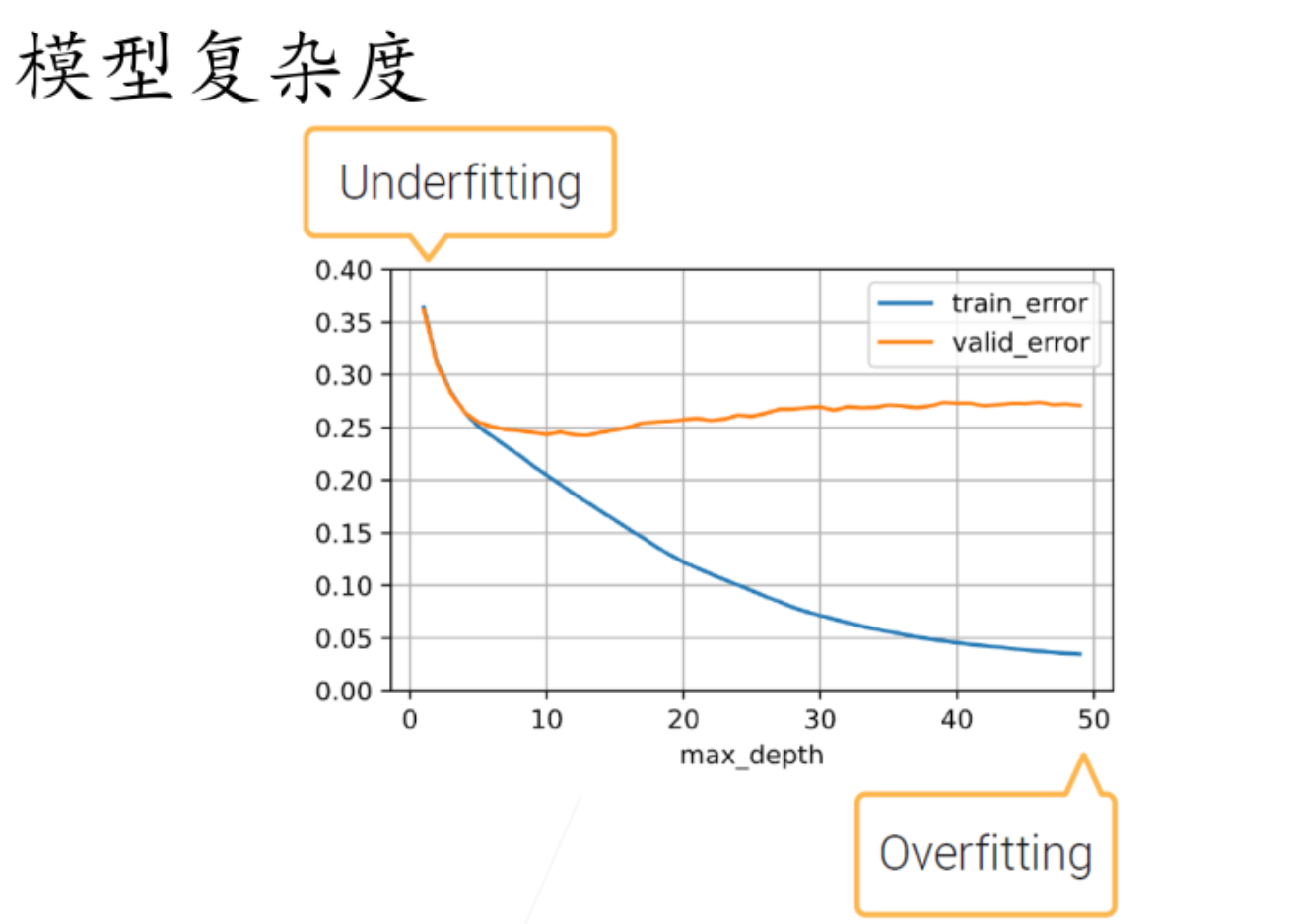
max_depth 反映模型复杂度
valid_error(验证误差)是指模型在**验证集(Validation Set)**上的误差?是不是应一定程度反映泛化误差
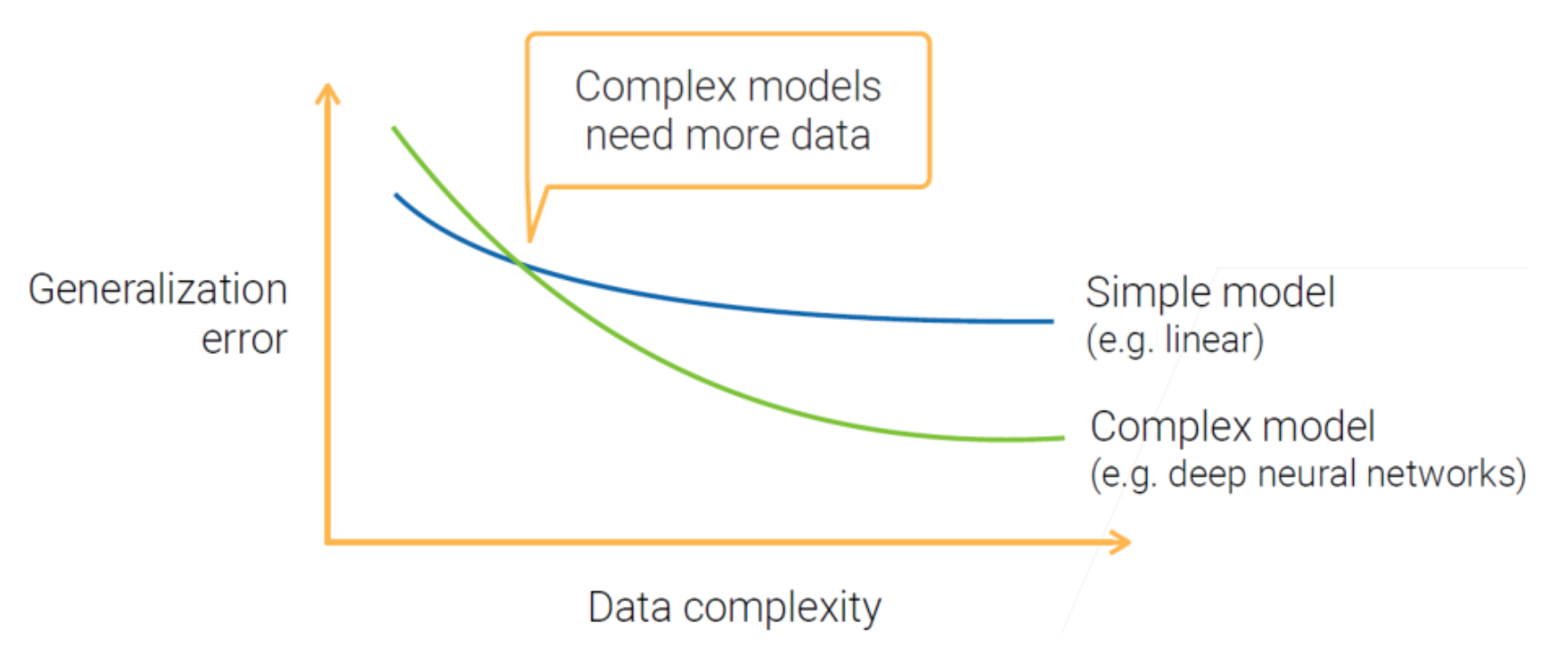
模型复杂度要和数据复杂度匹配
得到训练集的方法
常见问题:
测试集中有和训练集中元素近似或相关的数据,会影响测试的可信度【比如随机划分,那可能数据并非独立同分布】【比如数据之间可能存在关联(比如时序性,不同时间的同一事物),被划分到训练& 测试集中】
【数据充足时:优先用"留出法""交叉验证法"】
留出法:
训练前就划分出一部分作为测试集,甚至再划分一部分作为验证集
P次k折交叉验证
- 基本概念
- "k折"指的是将数据集随机划分为k个大小相近的互斥子集(或称为折,fold)。在每一次验证过程中,使用其中的k - 1个子集作为训练集来训练模型,剩下的1个子集作为验证集来评估模型的性能。
- "P次"表示重复进行k折交叉验证的次数为P次。每次重复时,数据集会被重新随机划分成k个子集,这样可以减少由于数据划分不同而导致的评估结果的偶然性,使模型性能的评估更加稳定和可靠。
交叉验证的每一次之间是什么关系:相互独立,最终训练出了P个模型,统一的方法:选择其中效果比较好的m个模型,分别输出一个结果,然后对m个结果(比如向量,求平均)
PS:竞赛中,数据特别少的情况下,可以选一个效果最好的模型,最终用全部数据再训练一次再提交模型
留一法 (Leave - One - Out,LOO)是k折交叉验证的一种特殊情况,当k等于数据集中样本的数量n时,就变成了留一法。也就是说,每次只留下一个样本作为验证集,其余的n - 1个样本作为训练集。【训练次数多/ 训练集接近整个数据集、不容易出现污染(测试集中有和训练集中元素近似或相关的数据)】【留一法不受随机划分缺点(概率不均)的影响】
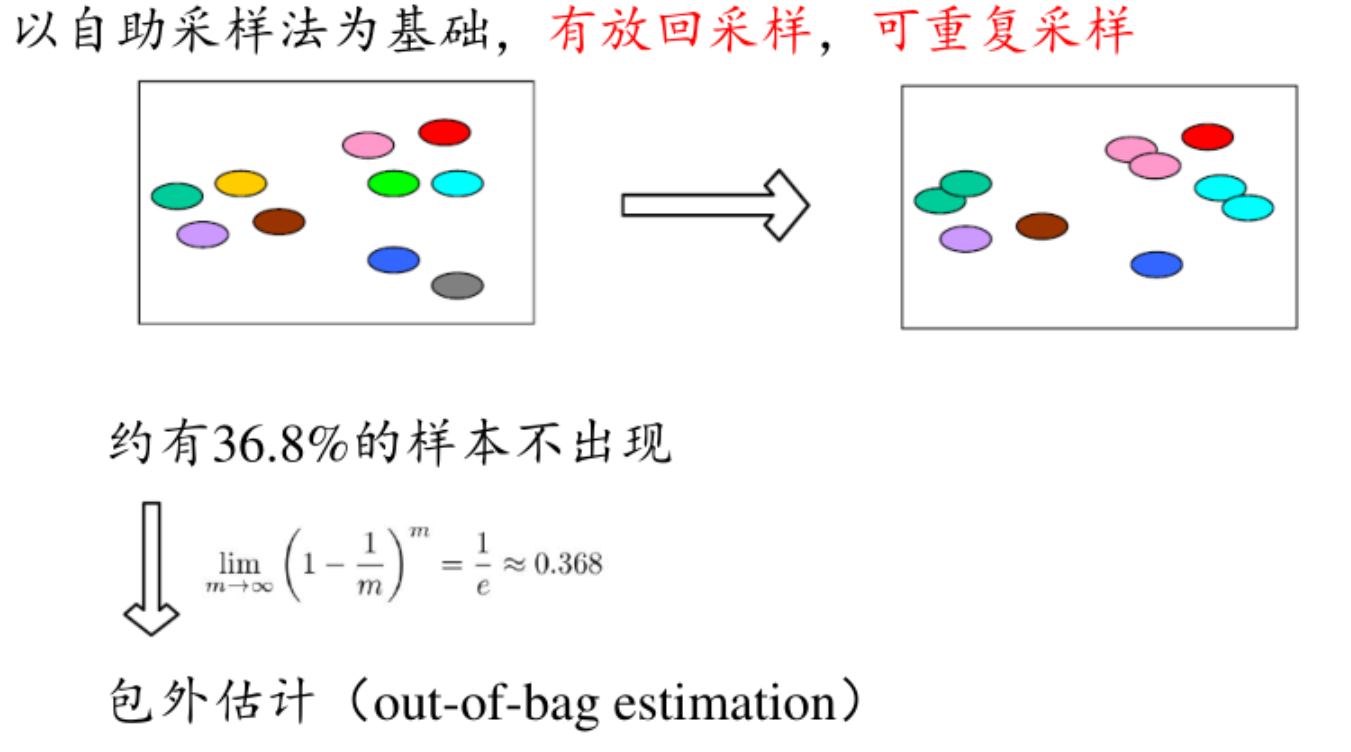
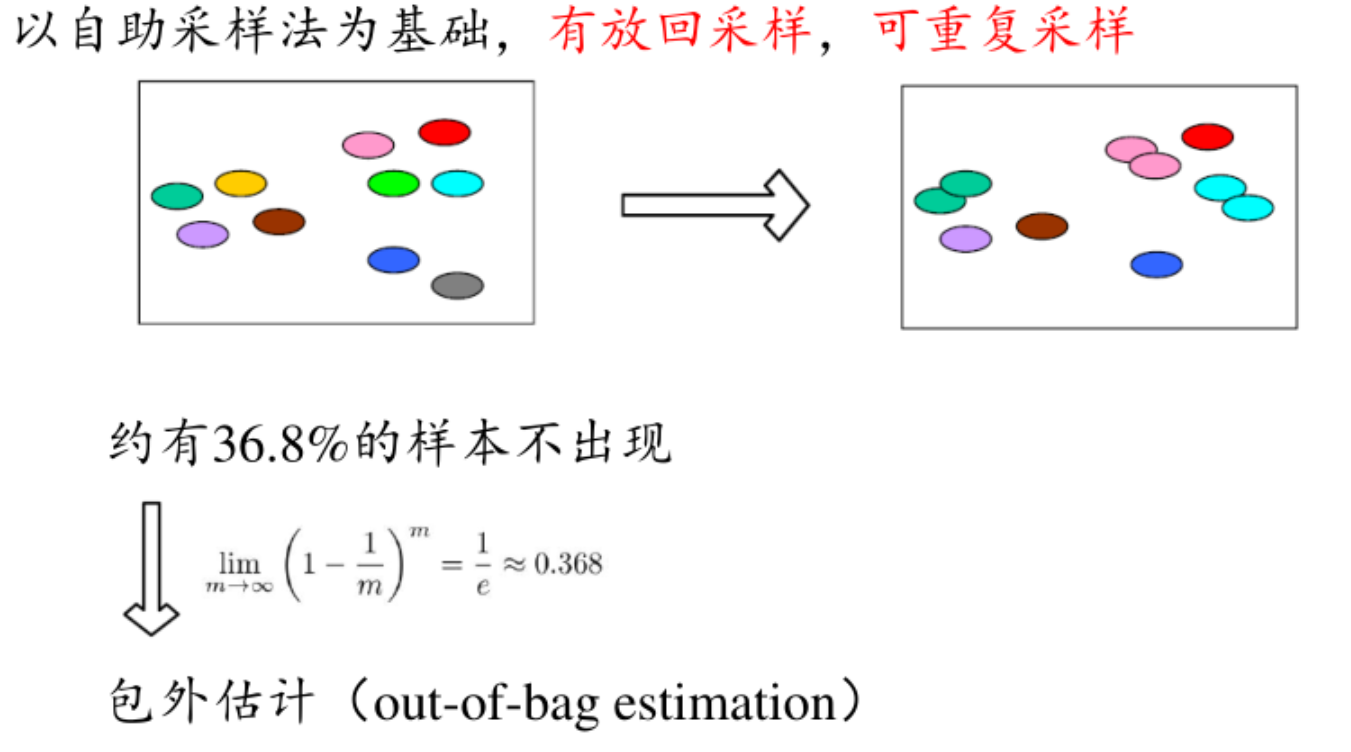
自助法(bootstrap)【对小数据集有优势】
- 抽样过程:假设原始训练集包含n个样本。每次从原始训练集中随机抽取一个样本,将其复制并放回原始训练集中,使得该样本在下一次抽样时仍有可能被选中。重复这个抽样过程n次,这样就得到了一个自助样本集,该样本集也包含n个样本。
- 重复抽样:重复上述抽样过程多次,比如B次,从而得到B个不同的自助样本集。
优势:从概率上讲,此时的训练集就相当于是整个数据集,对数据集比较小的情况友好
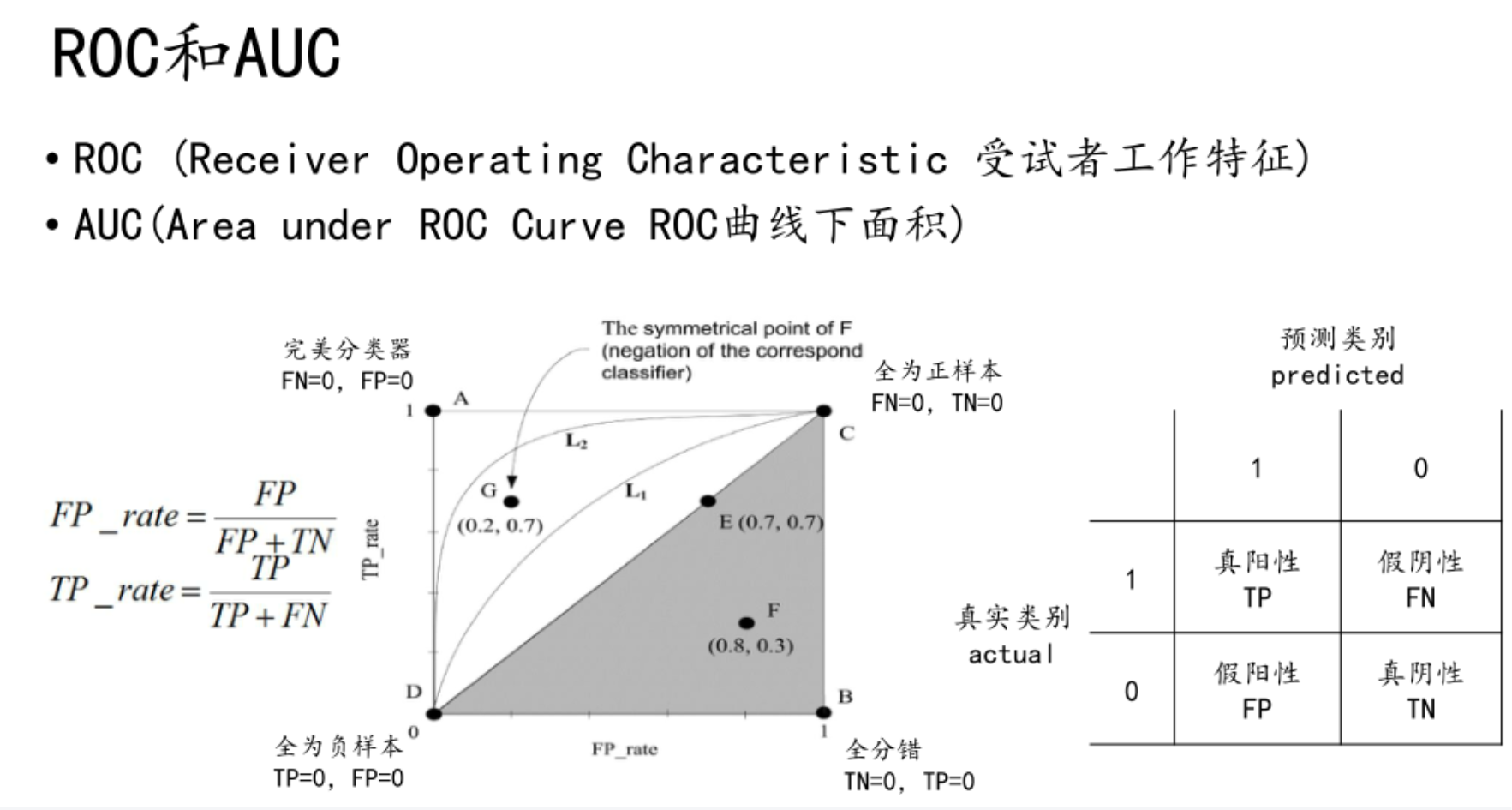
F score

比较检验,ppt38页