目标跟踪(Object Tracking)是计算机视觉核心技术,核心是在连续视频帧中持续定位并关联一个 or多个目标,输出位置、轨迹、状态等信息,适配光照、遮挡、形变等复杂场景,支撑多领域智能决策
为什么要目标跟踪?
如果目标跟踪和目标检测的任务相同的话,那直接用目标检测然后一帧一帧进行不就完了?为什么还要专门设置目标跟踪这个专题呢?
单帧检测缺乏稳定性和一致性
当检测失败时,用于对目标进行建模
- 被遮挡、视角/姿态变化
- 运动模糊或光照变化(可能只出现在视频序列的几个帧里)
- 背景杂乱等情况。 理解和推理动态场景,例如进行轨迹预测(比如判断一个行人是否要过马路)。
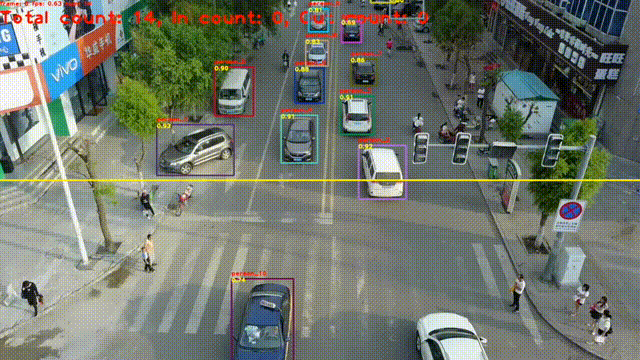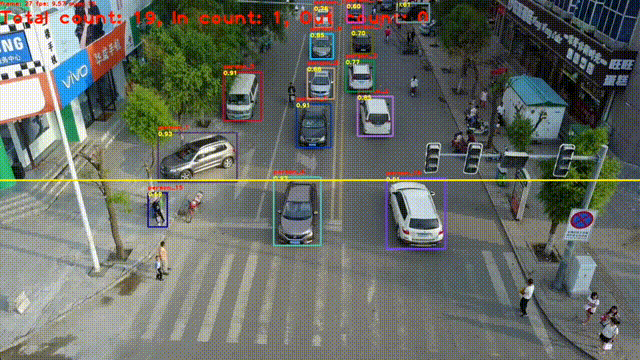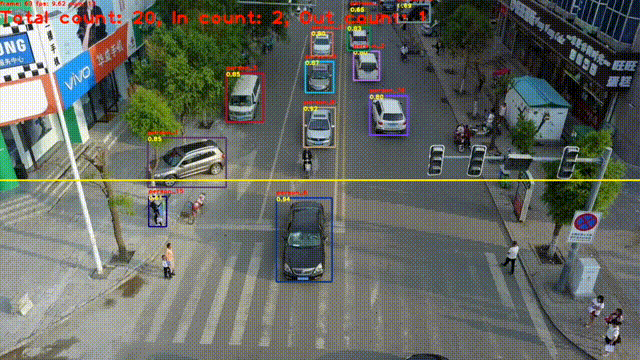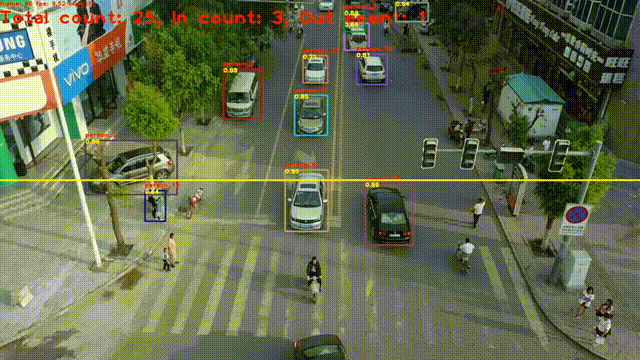
目标跟踪是指在连续的图像序列中,对特定感兴趣目标(如行人、车辆、动物、物体等)进行定位、识别,并持续追踪其位置、运动状态甚至形态变化,实现 "从一帧到多帧" 的目标关联。
应用场景:智能交通与自动驾驶、人机交互、医学影像
目标跟踪分类
|-------------------------------------------|---------------------------------------------------|
| 单目标跟踪 (Single Object Tracking, SOT) | 仅追踪视频中一个指定目标(通常由第一帧人工标注或自动检测确定),专注于 "如何稳定跟随单个目标"。 |
| 多目标跟踪 (Multiple Object Tracking, MOT) | 同时追踪视频中多个目标,需解决两个核心问题:① 单帧内多个目标的检测;②跨帧目标的身份匹配。 |
常见指标
-
MOTA: 同时考虑检测效果(虚警、漏检)和ID错误切换次数指标
-
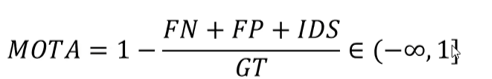
-
MOTP: 考虑回归的边界框的质量,以与真值边界框的欧氏距离度量距离度
-
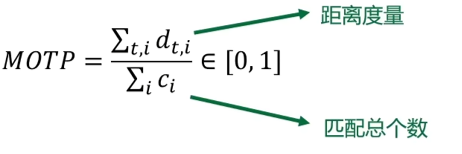
-
IDP(ID精度): 利用二部图匹配计算出预测ID与真值ID的映射关系
-
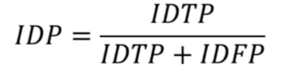
-
IDR(ID召回率)
-

-
IDF1(ID F1 score): 考虑回归的边界框的质量,以与真值边界框的欧氏距离度量距离度
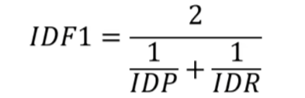
单目标跟踪
核心思想:首帧框选跟踪目标 bounding box,后续帧通过相似度计算确定目标位置,无需再检测匹配

GOTURN
GOTURN 是将深度学习引入单目标跟踪(SOT)领域的早期、非常成功的尝试之一。它开创性地将跟踪问题直接转化为一个回归问题
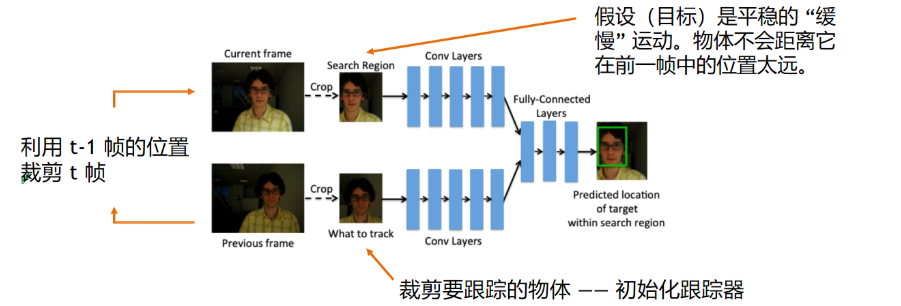
GOTURN 采用一个双流网络,接收两个输入:
- ①上一帧的目标图像:作为模板,告诉网络要追踪什么。
- ②当前帧的搜索区域:一个更大的区域,网络将在此处寻找目标。 这两张图像分别通过一个共享权重的卷积神经网络(CNN)来提取特征。提取出的特征向量被拼接(concatenate)在一起,然后输入到一个全连接层。 这个全连接层的作用是直接预测目标在当前帧的边界框坐标(x,y,w,h)。
整个过程是一个高效的前向传播,没有复杂的后处理或滤波器,使其能够达到实时跟踪的速度。
Siam 系列
Siamese Network(孪生网络)
然后介绍一下siam系列的算法。这个系列的算法是当今最主流的MOT。虽然看起来好像网络图和GOTURN有点像,但是实际上他们的底层逻辑完全不同。GOTURN 是回归算法,的双网络是用来直接预测目标新位置的。Siam系列的双网络是用来计算模板和搜索区域的相似度的,是一个相似性的学习。
siam系列模型,顾名思义就是孪生网络,用来衡量两个输入的相似程度。如上图,孪生神经网络有两个输入,将两个输入输入到两个神经网络,这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。最后通过Loss的计算,评价两个输入的相似度。 这其实是类似于人的视觉感官常识的,人在进行目标追踪的时候,前一秒记住该目标的一些特征(身高,长相,衣着等),后一秒在另一张视频帧中根据这些特征找到该目标。
- 用两个共享参数的神经网络,分别处理两个输入,然后比较它们的特征表示。
- 参数共享保证了"两个输入在同一度量空间下被表示"。
- 最终通过一个相似性度量函数(比如欧氏距离、余弦相似度、相关性等)判断两个输入是否"相似 / 匹配"。
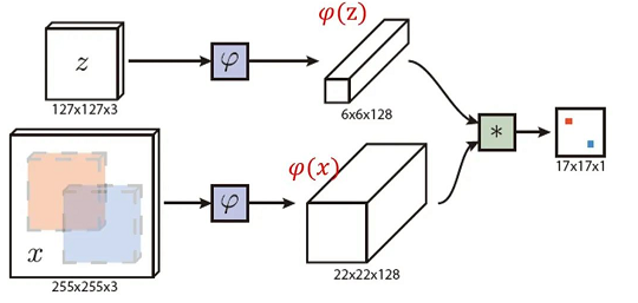
过程
- 首帧确定目标边界框,后续帧找其位置
- t 帧裁稍大搜索区,覆盖目标移动范围
- 用 Siamese 网络(共享权重双分支),提取模板与搜索区特征
- 以模板特征为 "核",和搜索区特征做相关匹配(如互相关 / 卷积等操作)
- 生成响应图(或含得分图、回归预测的多图 )
- 响应图取最大响应处为目标中心,可做尺度、偏移回归修正
代表性模型:SiamFC、SiamRPN、DaSiamRPN、SiamRPN++
多目标跟踪
多目标跟踪旨在将视频序列中感兴趣的目标检测出来,并赋予每个目标单独的编号,在整个序列中形成目标的轨迹。
存在的挑战:
- ①同类物体数量众多
- ②存在严重的遮挡情况
- ③物体外观往往极为相似

分类
Online tracking
只能利用当前时刻及之前的帧的信息来进行跟踪和数据关联,不能访问未来帧。
- 优点:实时性强
- 缺点:决策受限
- 应用场景:自动驾驶、智能视频监控、人机交互等
Offline tracking
可以利用整段视频的所有帧进行全局优化。
- 优点:全局视野
- 缺点:优化复杂
- 应用范围:视频后期处理、公共安全取证、行为分析等
在多目标的问题处理中,一般有两种类型,一种是online,一种是offline。现在主流的研究方向都是online,也就是只能利用当前时刻及之前的帧的信息来进行跟踪和数据关联。我们接下来介绍的方法也都是online的方法。
Tracking-by-Detection
对于MOT,最常应用的框架就是"Tracking-by-Detection"。现在主流的MOT都基于这个框架。这个框架的主要思想是先检测前后两帧的目标,然后通过算法将目标相互关联起来。
将 MOT 问题分解为"检测 + 数据关联" 两个步骤。 每帧先用目标检测器检测所有目标,再将检测结果与上一帧的轨迹进行关联,形成目标轨迹。
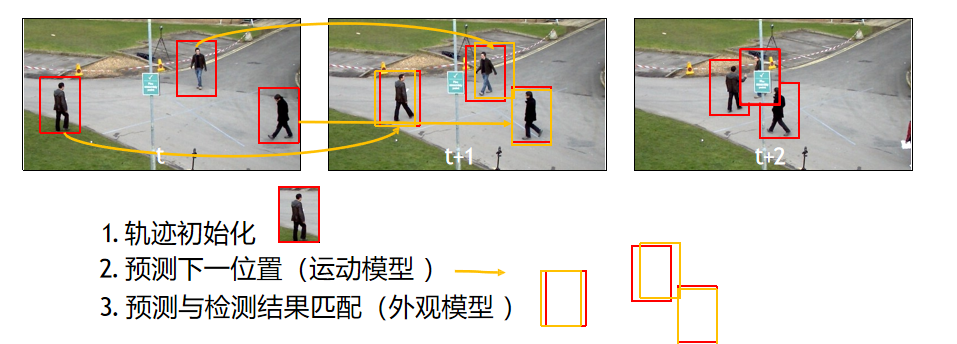
二分图匹配
Tracking-by-Detection方法的数据关联问题 通常可以建模为二分图匹配问题。 二分图匹配 ------ 在线跟踪里,用于关联 "预测结果(Predictions)" 和 "检测结果(Detections)" 的经典方法,把两者抽象成二分图的两个集合,通过计算距离找最优匹配。 其具体方式如图所示
计算预测结果和检测结果的"距离,寻找最优匹配
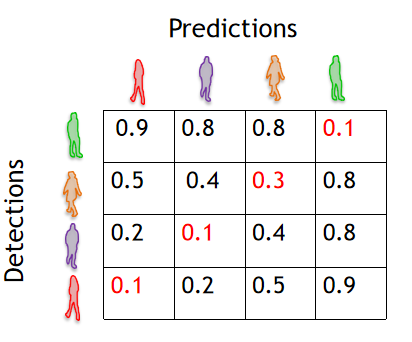
步骤
- ①定义框之间的距离
- eg:交并比:衡量两个检测框重叠程度
- 像素距离框:中心或顶点间的像素坐标距离
- ②找到一组一对一的匹配,使得总代价最小。
- ③距离值最小的为匹配结果
SORT系列
SORT 是一个非常有影响力的多目标跟踪MOT框架,它的成功在于其简洁、高效和实时性。SORT 系列主要包括两个模型:SORT 和 DeepSORT。
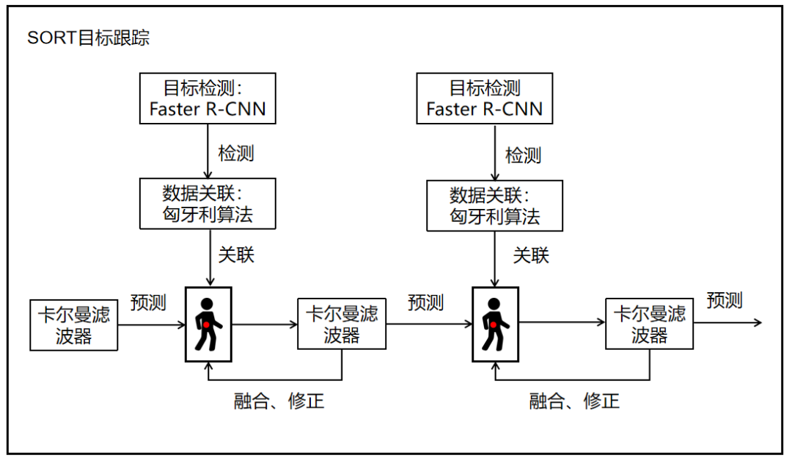
- 对每一帧使用目标检测器(如 Faster R-CNN、YOLO)检测目标 bounding box
- 使用滤波器预测每个轨迹下一帧的位置
- 计算预测轨迹与本帧检测框的距离
- 使用 Hungarian 算法找到最优匹配
- 轨迹管理、ID 分配
行人重识别(Re-ID)
行人重识别(Re-ID)是指利用计算机视觉技术,判断在不同时间段、不同监控下出现的行人图像是否属于同一人员的技术。
Re-ID(行人重识别)模块:将每个检测到的行人图像作为输入,输出一个高维度的特征向量。即使这个人在视频中的姿态、光线和背景发生变化,其特征向量也应保持相似。

DeepSort
DeepSort引入了Re-ID 模型来提取目标的外观特征。这使得算法在处理目标被遮挡或 ID 切换时,能通过"长相"来重新识别,极大地提升了跟踪的鲁棒性。
SORT只利用了几何上的信息,或者说物体的运动信息,而没有利用物体的外观信息。Deepsort做了改进
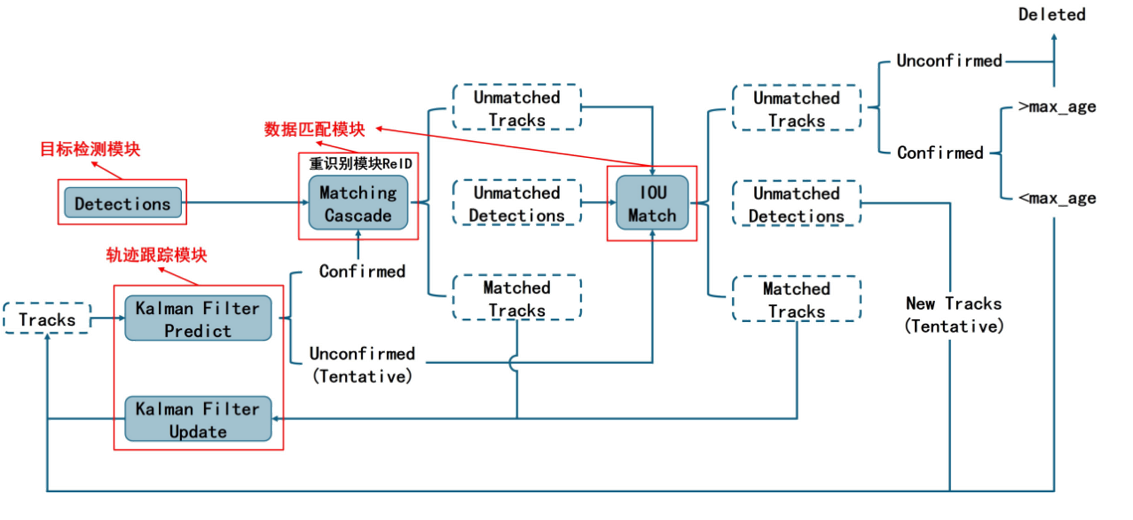
其具体步骤:
- 目标检测:首先用目标检测器找到所有目标。
- 特征提取:用一个 Re-ID(行人重识别)模型提取每个目标的外观特征,这就像目标的"视觉指纹"。
- 分阶段匹配:这是最关键的一步。它会分两次进行匹配:
- 第一步:用外观特征和运动信息(由卡尔曼滤波器预测)共同进行匹配。
- 第二步:对于第一步中没有匹配成功的轨迹,主要用外观特征来尝试重新匹配那些被短暂遮挡的目标。
- 轨迹管理:成功匹配的轨迹得到更新,没有匹配的则被视为新目标或已离开画面。
ByteTrack
ByteTrack 是由中国科学院、字节跳动等机构于 2021 年提出的算法。由于其取得了非常优异的性能,并且设计思想非常简洁高效,在MOT领域因此轰动。
它的核心思想可以用一句话概括:"让每一个检测框都有其用武之地。"
在传统的基于检测的跟踪(Tracking-by-Detection)算法中,通常会设定一个置信度阈值。只有高于这个阈值的检测框才会被用于跟踪。然而,很多被部分遮挡或模糊的目标,它们的检测置信度会低于这个阈值,从而导致跟踪丢失(ID Switch)。ByteTrack 发现,这些被丢弃的**"低置信度"**检测框,其实包含着非常有价值的信息。

创新:即便检测框置信度低,也不轻易丢弃。通过分层匹配(high-score 和 low-score 分开匹配),减少了目标被遗漏的情况。
意义:显著减少 ID 丢失和跟踪中断,尤其是目标遮挡或检测器漏检时。
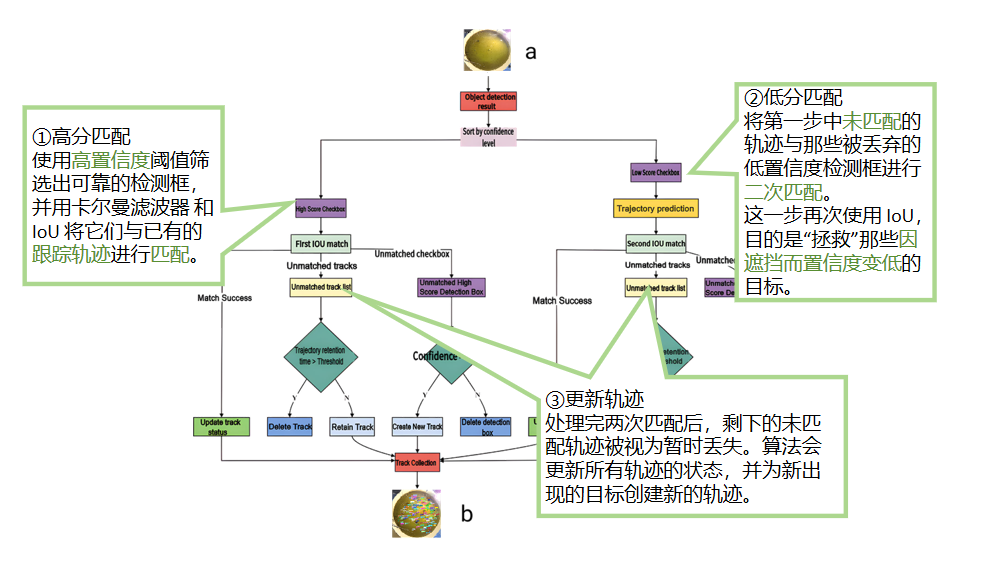
其步骤为:
- 检测目标(分高分/低分)。
- 卡尔曼滤波预测轨迹。
- 两阶段匹配:阶段一:高分检测框 → 更新轨迹。 阶段二:低分检测框 → 补充更新轨迹
- 更新轨迹 / 新建轨迹 / 删除轨迹。
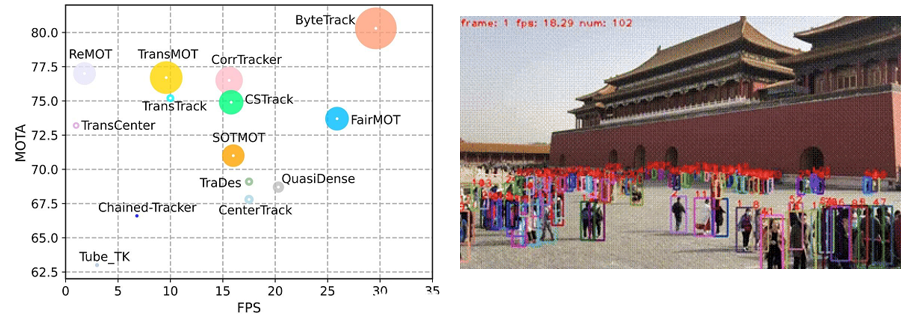
效果展示:
左图是论文中对于ByteTrack效果的评估展示。横轴(FPS)是帧数 ,反映运行速度。纵轴(MOTA)身份保持精度指标 ,半径是IDF,身份识别精度,半径越大精度越高 可以看出,ByteTrack:MOTA、FPS 均处于较高水平,且圆半径大,说明在跟踪精度、速度、身份识别上综合表现优异,是性能均衡的强算法。 右边的动图是一个实际的视频测试。可以看见,该方法的检测目标非常非常多,连远处墙角下的游客都能检测到。说明其身份识别的精度之高。
更多模型和应用
Track Anything 目标分割+目标跟踪
基于Segment Anything开发的项目。虽然创新点没啥,但是实用性拉满。可以在视频中实现动态的目标分割与跟踪。可以在视频中消除特定的目标。 想象一下你是一个电视台的剪辑人员,这几天你收到任务,要将某艺人从最新拍摄的综艺里消除......
三维目标跟踪
某项目参考了 Hinterstoisser 等人(2012)提出的基于梯度与边缘信息的 3D 物体检测与姿态估计算法(Line2D 思路) 以及 Stoiber 等人(2021)提出的稀疏区域 3D 物体跟踪方法 SRT3D。实现三维目标的跟踪。
Tracking Any Point:点跟踪
Tracking Any Point(TAP)是 Google DeepMind 在 2023 年的项目,内容是开发用于视频中任意点跟踪的模型及配套任意点跟踪的模型及配套数据集,包含 TAP-Vid 和 TAPVid-3D 数据集、TAPIR 模型及 RoboTAP 扩展。取得的成果有 TAPIR 模型在 TAP-Vid 基准测试中超越所有先前方法,RoboTAP 实现机器人通过极少量示例学习新操纵技能,项目还提供预训练模型权重并支持 Jax 和 PyTorch,推动点跟踪技术在机器人、视频分析等领域的应用。
Multi-View 3D Point Tracking:在三维点云空间里做目标点跟踪
除了二维的动态可以进行跟踪,三维的点云也可以做跟踪任务。 MVTracker由苏黎世联邦理工学院在2025年提出。其使用的模型将来自所有摄像头的信息直接融合成一个三维点云。该模型首次提出了一种数据驱动(Data-Driven)的解决方案,能够利用少量相机(例如4个)在动态场景中对任意三维点进行鲁棒、长程的跟踪。