本文的参考:https://www.bilibili.com/video/BV1Et4y1i7pu
假设你没有见过犰狳和穿山甲。现在左边给了你四张图,并告诉你了左边两张是犰狳,右边两张是穿山甲。现在给你一张新的图,你可以仅通过已知的四张图判断,新的图是犰狳还是穿山甲吗? 大多数人可能分不清犰狳和穿山甲,但是只要给出四张图片,都能进行正确的分类。既然人只要四张图片就能做出分类,那计算机是否可以呢?这里的。数据集只有四张图片,每个类只有两张图片。这么小的数据集,不足以拿去训练一个完整的神经网络。而少样本学习,就是为了解决这样一个问题。

少样本学习(Few-Shot Learning,FSL)是机器学习的一个子领域 ,核心是让模型仅用极少量标注样本(通常 1~5 个) 完成新任务的学习,解决 "数据稀缺场景下的泛化问题"(比如罕见物种识别、医疗罕见病例诊断)。
为什么要少样本学习?
传统深度学习(如 ImageNet 分类)依赖大量标注数据,但现实中:
- 很多场景无法收集足够样本(比如新物种、工业缺陷的罕见类型);
- 标注成本极高(比如医疗影像、精细粒度分类)。少样本学习的目标是让模型具备 "类人学习能力"------ 像人类一样,看 1~2 张新事物的图片,就能识别它。
概念
这里是一些少样本学习的概念:
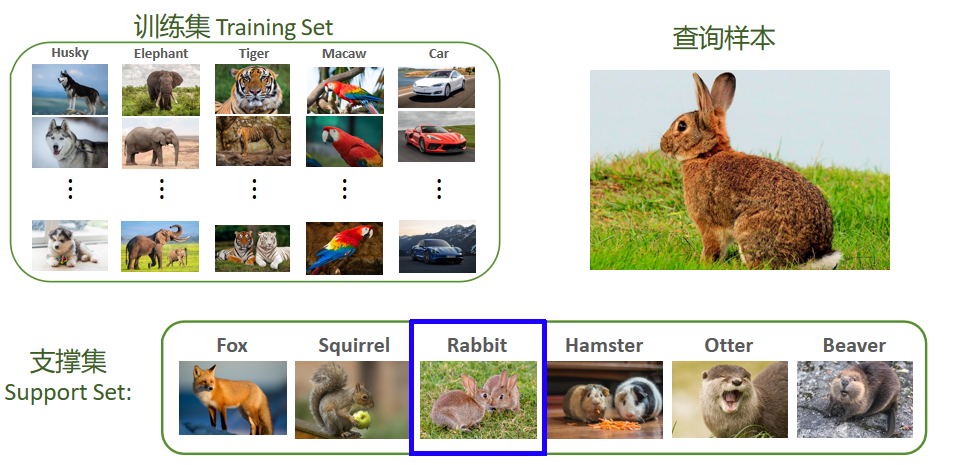
(1)训练集(Training Set)
- 模型预训练阶段使用的数据集,包含大量已知类别的样本
- 让模型学习 "通用特征提取能力"(比如学会识别动物的轮廓、纹理,车辆的形状等),但这些类别不包含后续要识别的新类别(比如图中的 Rabbit)。
(2)支撑集(Support Set)
- 测试 / 推理阶段 提供的 "少量样本",包含新类别,每个新类别只有 1~K 个样本
- 给模型提供 "新类别的参考特征",让模型知道 "Rabbit 长什么样"。
(3)查询样本(Query Sample)
- 需要识别的目标样本,属于支撑集中的某一个新类别,但模型需要自主判断它属于支撑集中的哪一类。
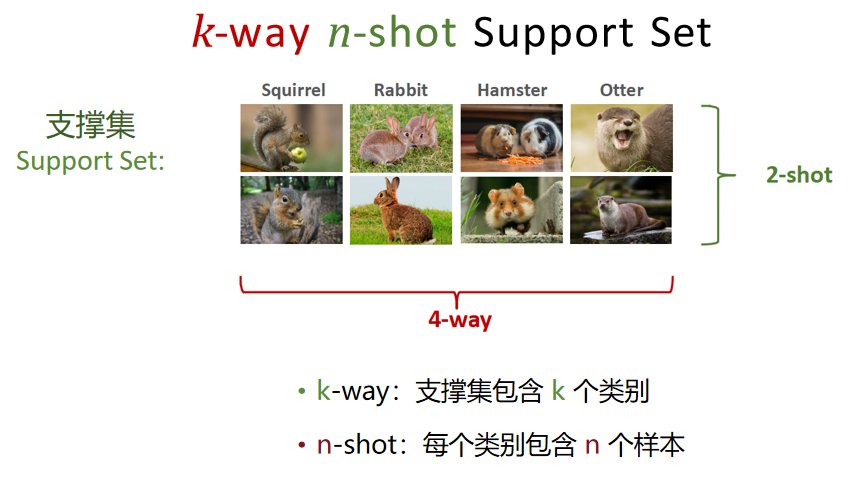
(1)k-way:"类别数量"
- 含义:支撑集(Support Set)中包含 k 个不同的新类别。
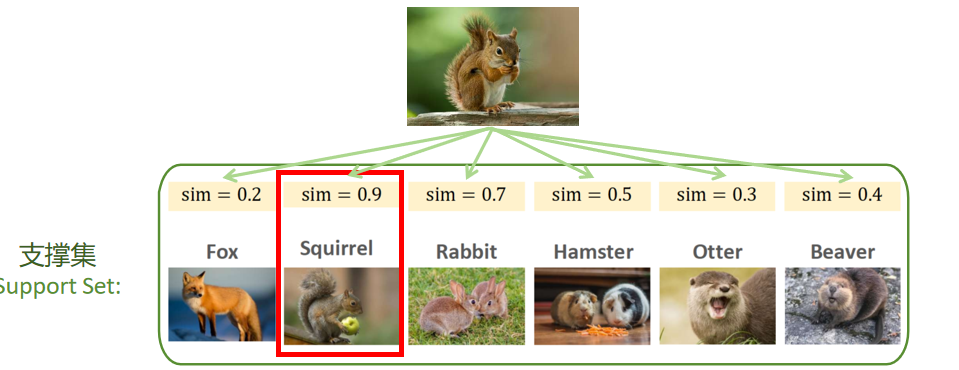
- 对应图:支撑集里有 Squirrel(松鼠)、Rabbit(兔子)、Hamster(仓鼠)、Otter(水獭),共 4 个类别 → 这是4-way。
(2)n-shot:"每个类别的样本数量"
- 含义:支撑集中的每个新类别,只提供 n 个标注样本。
- 对应图:每个类别(比如 Rabbit)有 2 张图片 → 这是2-shot。
元学习
下面来讲一下少样本学习和元学习都是什么。
少样本学习也是一种元学习。
元学习和传统的监督学习不一样,元学习的学习目标是"学会如何去学习 少样本学习的目的是为了让机器学会自己学习。
学习不是为了让神经网络去识别具体的东西,学习的目的是为了识别异同。学会区分不同的事物。
举个例子,如果训练集里面没有兔子,那模型可能并不认识兔子。但是,我们可以训练模型去指出输入的兔子图片和其他数据集的异同 用足够大的数据集去训练一个大的模型,比如深度神经网络。训练的目的是为了让模型知道事物之间的异同。然后再靠小样本提供的一点信息,模型就可以判断输入了。
基于度量学习
在少样本学习中,基于度量学习(Metric-Based Few-Shot Learning) 是最主流的思路之一,核心逻辑是:学习一个 "特征相似度度量规则",通过 "查询样本与支撑集样本的特征匹配" 完成分类,不需要修改模型参数,而是依赖 "特征间的距离 / 相似度" 做判断。
- 预训练特征提取器:用大量 "基类样本"(已知类别)训练一个通用的特征提取模型(比如 CNN、Transformer),让它能把不同样本映射到高维特征空间。
- 推理阶段的特征匹配 :
- 对支撑集(少量新类别样本),提取每个样本的特征;
- 对查询样本(待分类的目标),提取其特征;
- 用预定义的 "度量方式"(比如欧氏距离、余弦相似度),计算查询样本与支撑集样本的特征相似度,相似度最高的类别就是预测结果。
训练这个神经网络要用一个大的数据集,数据集俩面有很多标注,每个类里面都有很多样本 我们训练的时候需要正样本和负样本。
正样本呢负责找寻样本之间的关联,负样本需要找寻类与类之间的区别。正样本的找寻方式是,随机抽取一张图片,从同一类中随机抽取另一张图片,把标签这支撑1 。用同样的方法,负样本相反,随机抽取一张图片,再抽取另一类的样本,标签设置为0

打一个卷积神经网络用来提取特征。这个网络有很多层,输入为图片,输出特征向量,记为fx
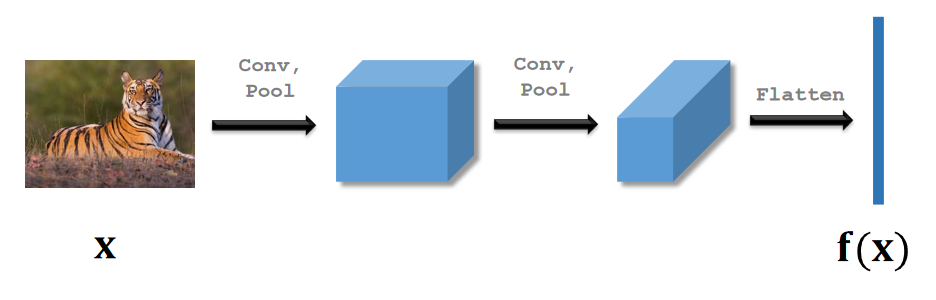
把这两张正样本输入神经网络,把两个图的特征向量记为h1和h2,注意,只有一个神经网络,这两个f指的是同一个神经网络。然后计算h1和h2计算距离,设为z,表示两个向量的区别。最后用全连接层进行处理,输出一个标量。这个标量是一个介于0-1之间的数字。然后进行反向传播,更新权重。如果两个图片是同一个类别,输出应该接近1,如果是不同的类别,输出应该接近0
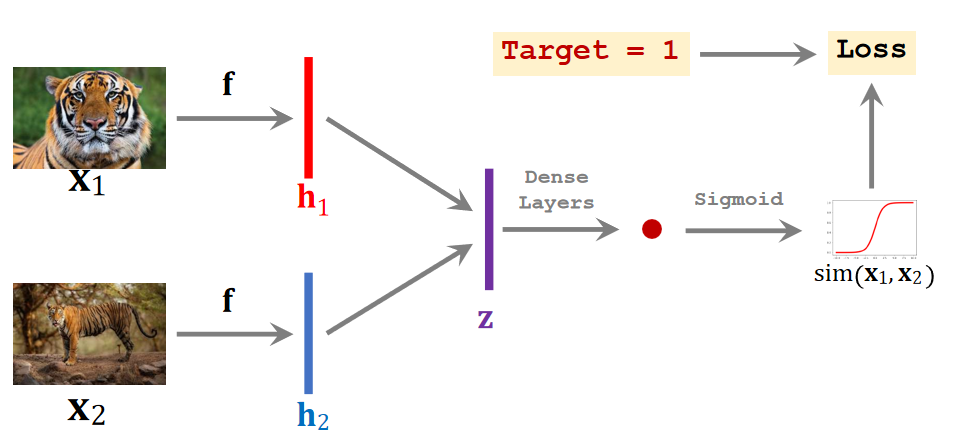
等训练好之后,用来做少样本的预测预测。刚刚是用大数据的数据集做的训练,现在我们少样本数据集里的6类都不在刚刚的训练集里面。
以这个例子为例,支撑集是一个6way 1shot的数据集,每个类里面只有一个样本。分别拿这些样本与查询样本做对比,计算查询样本与这些图片的相似度。这6类都不在训练集里面。这就是少样本学习的困难之处。现在来了一个quary,现在做六选一。具体做法就是注逐一对比里面的图片,把quary和里面的图片进行逐一对比。
算出quary与所有图片的相似度,查找相似度最高的,判断quary到底是什么。最后,选出相似度最高的,作为最后的分类结果。当每一类的数量大于1时,一般选用sim的平均值作为这一类的sim。
三元组网络
现在讲另一种训练的方法,
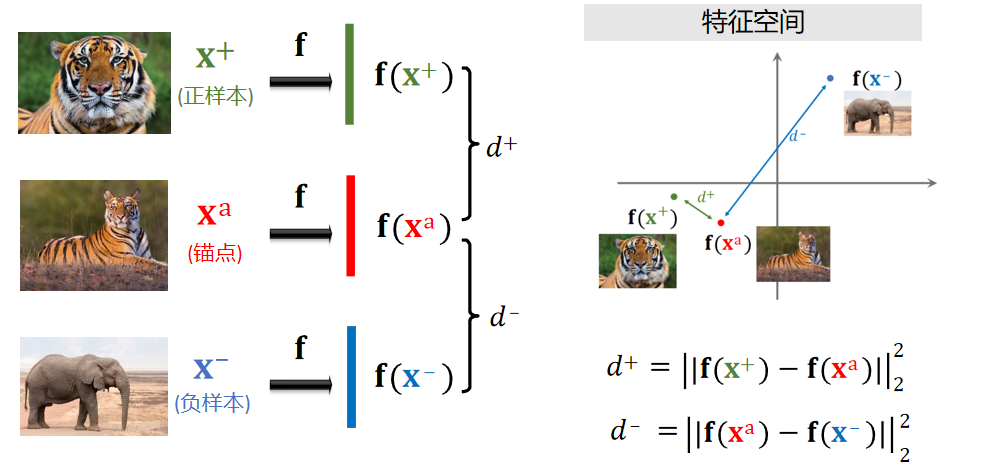
在少样本学习的基于度量学习思路中,** 三元组网络(Triplet Network)** 是一种经典的 "样本对" 类模型,核心是通过 "三元组样本(锚点样本 + 正样本 + 负样本)" 来学习更具区分度的特征空间,让同一类样本的特征更接近、不同类样本的特征更远离。
三元组网络的核心是优化 "三元组损失",通过同时输入 "锚点样本(Anchor)、同一类的正样本(Positive)、不同类的负样本(Negative)",让模型学习到的特征满足:
锚点样本与正样本的特征距离 < 锚点样本与负样本的特征距离 + 一个小的间隔
这样准备训练集:首先训练集里面随机选一个图片,记录下这个图片,设这个图片为锚点。 从同类别里面随机抽一个图片,将其记录为正样本。 再抽一个别的类别的图片,几率为负样本。

将正样本、负样本嗨哟锚点都输入卷积神经网络。
记录正样本与锚点之间在特征空间上的距离,求差。做类似的操作,分别对正样本和负样本进行操作。我们希望相同类别的特征向量可以在一起,不同类别的可以分开。
右边的图是特征空间,两个之前的距离平方就是d+,理想情况下d+越小越好。负样本是蓝色的点,希望他和红色的额距离越大越好。
训练好之后我们来给他进行分类。给一个query,用神经网络提取特征,比较特征向量的距离。算出所有的距离然后找到距离最小的。

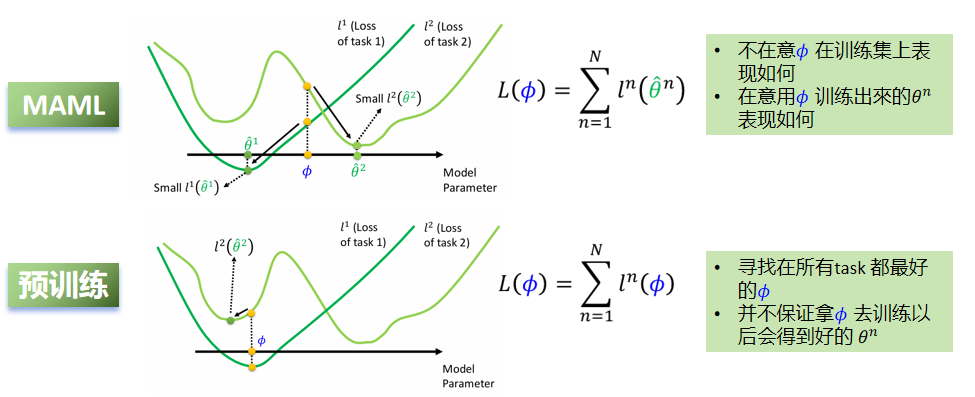
MAML
MAML,全称呼叫做Model-Agnostic Meta-Leaming ,意思是模型无关的元学习。所以MAML并不是一个深度学习模型,而更像是一种训练技巧。
MAML要做的事情是学习一个"好"的初始化参数。以前我们是训练一个模型,然后让这个模型的参数0最优,而现在我们训练MAML是希望初始化参数中最优,这样就可以实现"快速学习"(使用来自新任务的少量数据就能解决学习任务,而且只需要几步梯度下降就能得到好的泛化效果)。
那么,如何学呢?
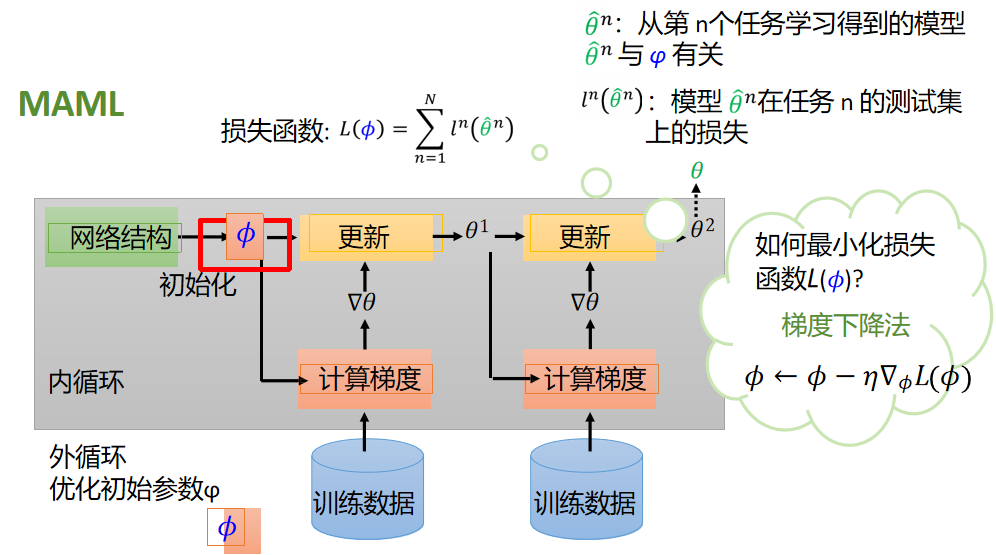
(左上角)首先定义一个损失函数,输入是初始化的参数。将初始化的参数在不同的任务重进行训练
(有上角)设θn为在第n个任务上学习到的模型,它显然和初始化的参数有关系。然后,用l来表示它的损失。把所有的任务损失l加起来就是总损失函数L
如何训练/使损失函数最小呢?使用梯度下降法进行训练
那么就有人问了,都是在正式训练之前对参数进行调整,MAML与预训练的差别究竟在哪里?
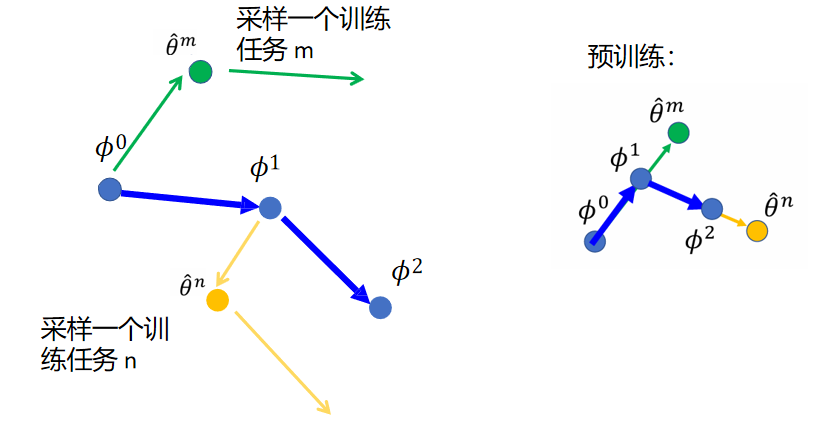
对于MAML,不在意𝜙在训练集上表现如何。在意用𝜙训练出來的θ^n表现如何。也就是像图里的φ一样,它对应的地方在两个绿色的线上面都不是最低值。但是以这个值作为初始开始训练,他们只要沿着梯度下降,很快就能达到各自task的loss最低值。因此这就是一个好的初始值
对于预训练来说,寻找在所有task 都最好的𝜙、它找的初始值可能是两个Task综合的最低点,也就是图中的位置。一旦开始以这个为初始值训练,深绿色的部分已经是最低值,但是浅绿色的线很容易陷入到局部最小值而不是全局最小值。因此,它并不具备"未来学习的潜力。并不保证拿𝜙去训练以后会得到好的 θ^n
现在以可视化的角度说一下maml是怎么实现的 有一个初始的参数值φ0.现在每一个训练任务就是一个训练资料。
- ①首先,在第一次做训练m的时候,我们先更新出来一个参数θm。
- ②然后计算θm对损失函数的偏微分,
- ③计算出来的防线作为φ的更新方向。
- ④然后在训练n的时候更新出θn,
- ⑤再做偏微分,拿去更新φ2
对比一下预训练:相比maml,少一次对于损失函数的偏微分。也就是说,每次只计算一步就得出新的参数φ