使用星图AI算力平台训练PETRV2-BEV模型
-
- 一、背景介绍
-
- [1.1 什么是BEV模型?](#1.1 什么是BEV模型?)
- [1.2 为什么选择PETRV2?](#1.2 为什么选择PETRV2?)
- [1.3 云端训练的必要性](#1.3 云端训练的必要性)
- 二、操作步骤
-
- [2.1 创建算力实例](#2.1 创建算力实例)
- [2.2 连接到容器环境](#2.2 连接到容器环境)
- [2.3 准备训练环境](#2.3 准备训练环境)
- [2.4 下载模型和数据](#2.4 下载模型和数据)
-
- [2.4.1 下载预训练权重](#2.4.1 下载预训练权重)
- [2.4.2 下载nuscenes数据集](#2.4.2 下载nuscenes数据集)
- [2.5 训练流程详解](#2.5 训练流程详解)
-
- [2.5.1 数据预处理](#2.5.1 数据预处理)
- [2.5.2 精度测试(验证模型是否正常)](#2.5.2 精度测试(验证模型是否正常))
- [2.5.3 开始训练](#2.5.3 开始训练)
- [2.5.4 可视化训练过程](#2.5.4 可视化训练过程)
- [2.5.5 模型导出与部署](#2.5.5 模型导出与部署)
- [2.5.6 运行Demo验证](#2.5.6 运行Demo验证)
- [2.6 进阶:训练xtreme1数据集](#2.6 进阶:训练xtreme1数据集)
一、背景介绍
1.1 什么是BEV模型?
想象一下,当自动驾驶汽车行驶在路上时,它需要通过摄像头、雷达等传感器感知周围环境。这些传感器数据通常是2D图像,而BEV(Bird's Eye View,鸟瞰图)模型的神奇之处在于,它能将这些不同视角的数据"翻译"成一个从上往下看的统一视图。
就像你把不同角度拍摄的照片拼接成一张完整的俯视地图,BEV模型让车辆能更直观地理解周围物体(车辆、行人、障碍物)的位置、大小和运动状态,这对自动驾驶决策至关重要。
1.2 为什么选择PETRV2?
PETRV2是PaddlePaddle 3D开发套件中的一个先进BEV感知模型。它有几个突出的优点:
- 多视角融合:能有效融合来自多个摄像头的数据
- 实时性能:在保持高精度的同时,推理速度快
- 开源友好:基于飞桨框架,社区支持完善
1.3 云端训练的必要性
训练一个BEV模型通常需要:
- 高性能GPU(至少一块,理想情况是多块并行)
- 大量存储空间(数据集往往几十GB)
- 稳定的训练环境(训练可能持续数天)
对于个人开发者或小团队来说,购买和维护这样的硬件成本很高。而云端算力平台提供了一个"随用随租"的解决方案------就像使用共享单车一样,你需要的时候租用,用完就释放,既经济又灵活。
星图AI算力平台(https://ai.csdn.net/compute-power)正是这样一个平台,它提供了:
- 预置的深度学习环境
- 按小时/天/月计费的GPU资源
- 简单的SSH访问方式
二、操作步骤
2.1 创建算力实例
步骤解析:
- 选择合适镜像:我们在星图AI上预置了一个包含PETRV2环境的镜像
- 购买时长: 培训GPU配置及时长
- 等待实例启动:大约15分钟,系统会自动配置好所有环境
为什么需要15分钟?
- 系统需要从镜像仓库拉取约10GB的容器镜像
- 配置GPU驱动和CUDA环境
- 初始化存储空间和网络设置
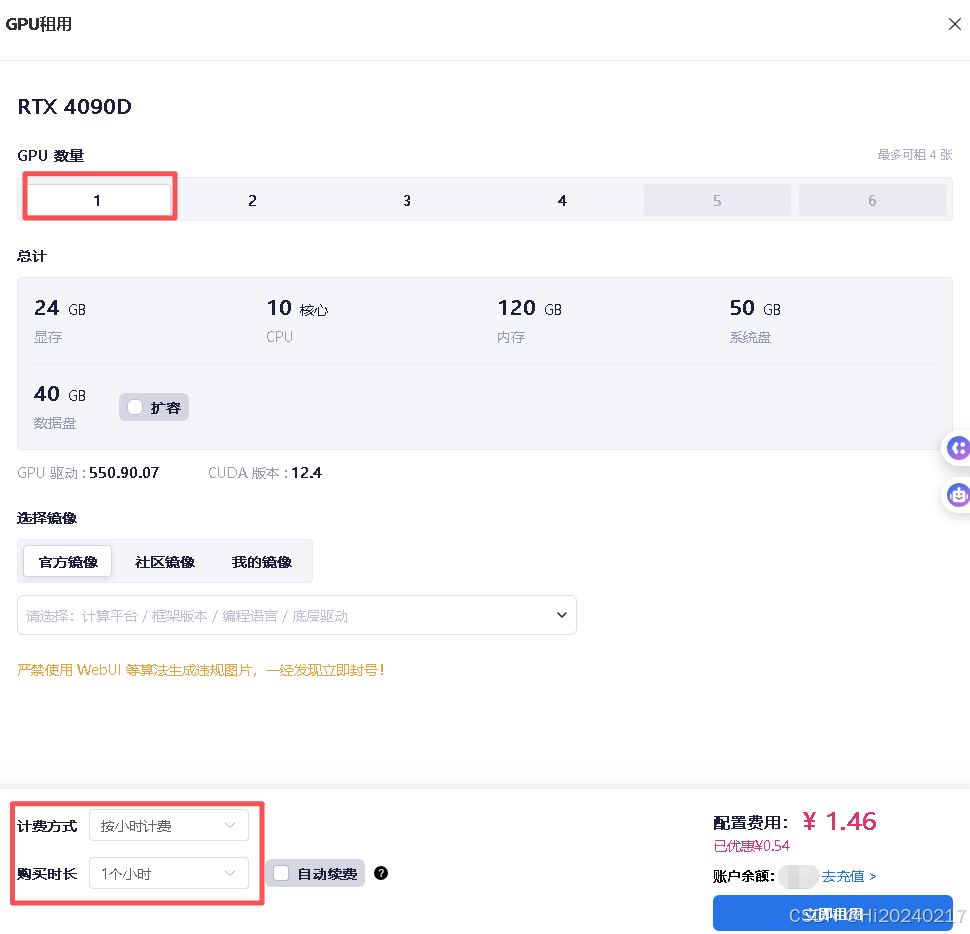
小贴士:
- 如果只是测试,申请1小时就够了
- 正式训练时根据数据集大小调整时长
- 记得在不用时主动释放实例,避免产生额外费用
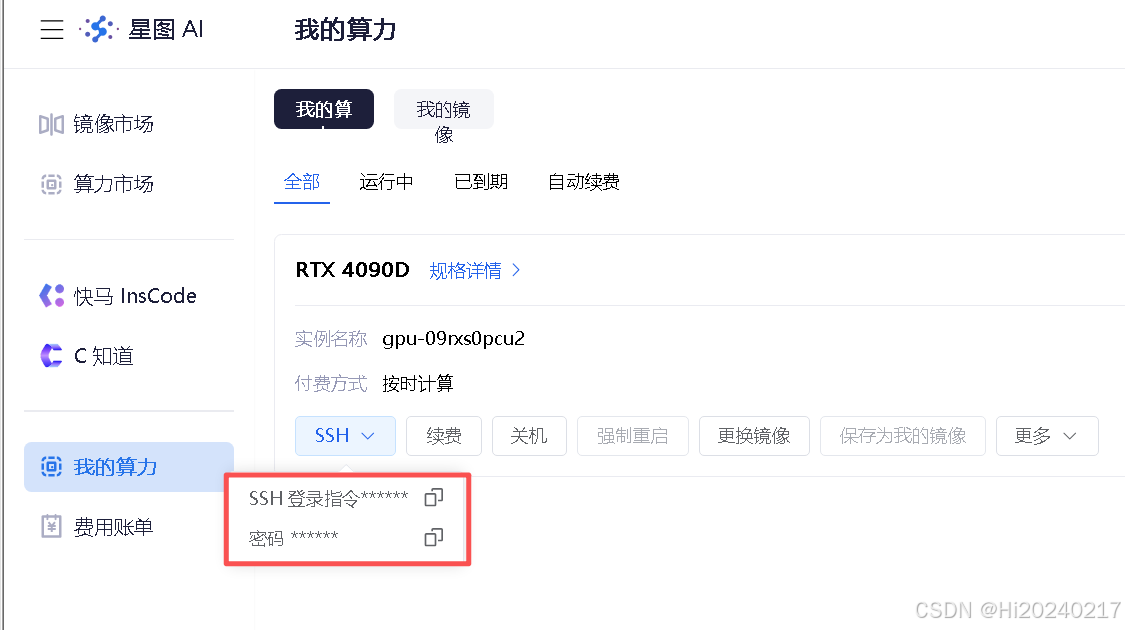
2.2 连接到容器环境
bash
# 从平台控制台复制SSH命令
ssh -p [端口号] root@[服务器地址]连接成功后的验证:
- 输入
nvidia-smi查看GPU状态 - 确认CUDA版本是否匹配
- 检查磁盘空间是否充足
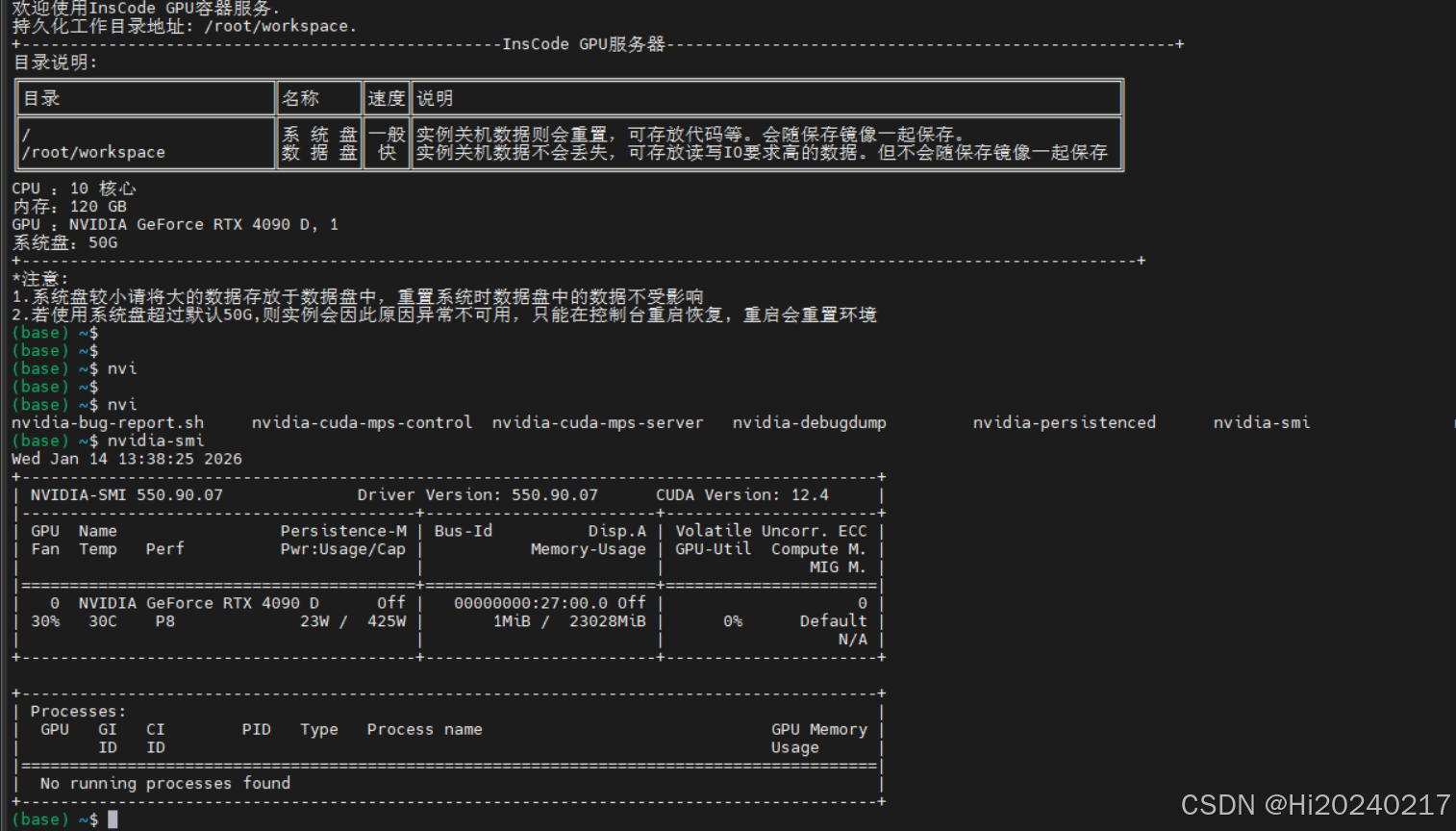
2.3 准备训练环境
为什么需要conda环境?
Conda是Python的环境管理工具,它允许我们在同一台机器上创建多个独立的Python环境。这样不同项目可以使用不同版本的库,避免版本冲突。
bash
# 激活预配置的环境
conda activate paddle3d_env
# 验证环境
python --version
pip list | grep paddle2.4 下载模型和数据
2.4.1 下载预训练权重
bash
wget -O /root/workspace/model.pdparams https://paddle3d.bj.bcebos.com/models/petr/petrv2_vovnet_gridmask_p4_800x320/model.pdparams预训练权重的作用:
- 模型已经在大量数据上学习过基本特征
- 可以加速训练收敛
- 特别适合数据量较小的场景
2.4.2 下载nuscenes数据集
bash
# 下载mini版数据集
wget -O /root/workspace/v1.0-mini.tgz https://www.nuscenes.org/data/v1.0-mini.tgz
# 解压到指定目录
mkdir -p /root/workspace/nuscenes
tar -xf /root/workspace/v1.0-mini.tgz -C /root/workspace/nuscenes关于nuscenes数据集:
- 自动驾驶领域权威数据集
- 包含1000个场景,每个场景20秒
- 提供相机、激光雷达、GPS/IMU等多传感器数据
- mini版包含10个场景,适合快速验证
2.5 训练流程详解
2.5.1 数据预处理
bash
cd /usr/local/Paddle3D
# 清理旧的标注文件
rm /root/workspace/nuscenes/petr_nuscenes_annotation_* -f
# 创建PETR格式的数据标注
python3 tools/create_petr_nus_infos.py --dataset_root /root/workspace/nuscenes/ --save_dir /root/workspace/nuscenes/ --mode mini_val预处理的作用:
- 将原始数据转换为模型能理解的格式
- 生成训练、验证、测试集的划分
- 提取关键信息(物体边界框、类别标签等)
2.5.2 精度测试(验证模型是否正常)
bash
python tools/evaluate.py \
--config configs/petr/petrv2_vovnet_gridmask_p4_800x320_nuscene.yml \
--model /root/workspace/model.pdparams \
--dataset_root /root/workspace/nuscenes/关键指标解释:
- mAP(平均精度):越高越好,表示检测准确率
- mATE(平均平移误差):越低越好,表示位置预测误差
- mASE(平均尺度误差):越低越好,表示大小预测误差
- NDS(NuScenes检测分数):综合评分,主要参考指标
输出
bash
mAP: 0.2669
mATE: 0.7448
mASE: 0.4621
mAOE: 1.4553
mAVE: 0.2500
mAAE: 1.0000
NDS: 0.2878
Eval time: 5.8s
Per-class results:
Object Class AP ATE ASE AOE AVE AAE
car 0.446 0.626 0.168 1.735 0.000 1.000
truck 0.381 0.500 0.199 1.113 0.000 1.000
bus 0.407 0.659 0.064 2.719 0.000 1.000
trailer 0.000 1.000 1.000 1.000 1.000 1.000
construction_vehicle 0.000 1.000 1.000 1.000 1.000 1.000
pedestrian 0.378 0.737 0.263 1.259 0.000 1.000
motorcycle 0.356 0.748 0.314 1.410 0.000 1.000
bicycle 0.063 0.760 0.236 1.862 0.000 1.000
traffic_cone 0.637 0.418 0.377 nan nan nan
barrier 0.000 1.000 1.000 1.000 nan nan2.5.3 开始训练
bash
python tools/train.py \
--config configs/petr/petrv2_vovnet_gridmask_p4_800x320_nuscene.yml \
--model /root/workspace/model.pdparams \
--dataset_root /root/workspace/nuscenes/ \
--epochs 100 \
--batch_size 2 \
--log_interval 10 \
--learning_rate 1e-4 \
--save_interval 5 \
--do_eval参数详解:
--epochs 100:训练100轮--batch_size 2:每次处理2个样本(受限于GPU显存)--learning_rate 1e-4:学习率,控制参数更新幅度--do_eval:每轮结束后进行验证
2.5.4 可视化训练过程
bash
# 启动VisualDL可视化工具
visualdl --logdir ./output/ --host 0.0.0.0端口转发技巧 :
由于云服务器通常不直接开放Web端口,我们需要通过SSH隧道进行访问:
bash
ssh -p 31264 -L 0.0.0.0:8888:localhost:8040 root@gpu-09rxs0pcu2.ssh.gpu.csdn.net这是什么原理?
- 将本地的8888端口映射到远程的8040端口
- 访问本地
http://localhost:8888实际上访问的是远程的VisualDL服务
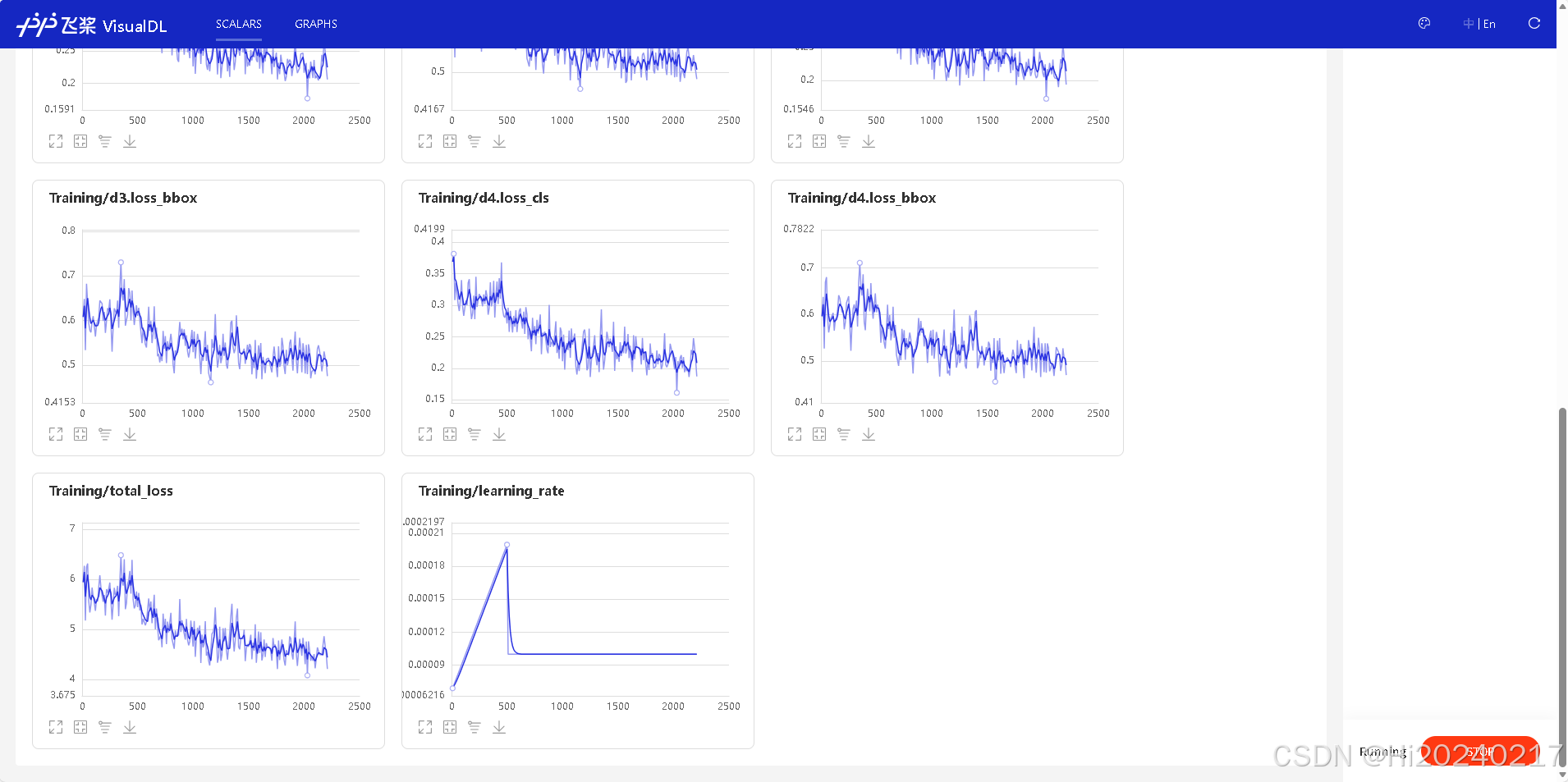
在VisualDL中你可以看到:
- 损失函数下降曲线
- 验证指标变化趋势
- 学习率调整情况
2.5.5 模型导出与部署
训练完成后,我们需要将训练模型导出为推理格式:
bash
# 创建导出目录
rm -rf /root/workspace/nuscenes_release_model
mkdir -p /root/workspace/nuscenes_release_model
# 导出模型
python tools/export.py \
--config configs/petr/petrv2_vovnet_gridmask_p4_800x320_nuscene.yml \
--model output/best_model/model.pdparams \
--save_dir /root/workspace/nuscenes_release_model导出文件说明:
model.pdmodel:模型结构文件model.pdiparams:模型权重文件model.pdiparams.info:模型信息文件
2.5.6 运行Demo验证
bash
python tools/demo.py /root/workspace/nuscenes/ /root/workspace/nuscenes_release_model nuscenesDemo功能:
- 加载测试数据
- 使用导出的模型进行推理
- 可视化检测结果

2.6 进阶:训练xtreme1数据集
如果你有更多时间,可以尝试更大的xtreme1数据集:
2.6.1、准备数据集
bash
# 数据预处理(假设数据已上传到/root/workspace/xtreme1_nuscenes_data/)
cd /usr/local/Paddle3D
rm /root/workspace/xtreme1_nuscenes_data/petr_nuscenes_annotation_* -f
python3 tools/create_petr_nus_infos_from_xtreme1.py /root/workspace/xtreme1_nuscenes_data/2.6.2、测试精度
bash
python tools/evaluate.py \
--config configs/petr/petrv2_vovnet_gridmask_p4_800x320.yml \
--model /root/workspace/model.pdparams \
--dataset_root /root/workspace/xtreme1_nuscenes_data/
# 开始训练
python tools/train.py \
--config configs/petr/petrv2_vovnet_gridmask_p4_800x320.yml \
--model /root/workspace/model.pdparams \
--dataset_root /root/workspace/xtreme1_nuscenes_data/ \
--epochs 100 \
--batch_size 2 \
--log_interval 10 \
--learning_rate 1e-4 \
--save_interval 5 \
--do_eval