文章目录
- 前言
- 一、LangChain可以解决什么问题
- 二、数据流转介绍
-
- 1.从用户输入到LangChain框架处理,在返回结果给用户
- 2.版本的新特性,V1.0和V0.3
- [3. 提示词模板](#3. 提示词模板)
- 4.两类核心模板:
-
- [4.1 基础模板:PromptTemplate(适合纯文本LLM)](#4.1 基础模板:PromptTemplate(适合纯文本LLM))
- [4.2 对话模板ChatPromptTemplate(适用于对话模型)](#4.2 对话模板ChatPromptTemplate(适用于对话模型))
- [4.3 通过动态提示词](#4.3 通过动态提示词)
- 5.LangChain的链
- 总结
前言
LangChain1.0 是一个专为构建生产级AI智能体(agent)而设计的轻量,稳定,模块化的框架,底层基于LangGraph 实现,支持工具调用,持久化,流式响应,人工干预。
LangChain 不是一个大模型,而是一套帮开发者快速搭建基于大模型的智能应用的 "脚手架 + 工具箱",用通俗的话讲,就是让大模型 "能记忆、能联网、能干活、能处理自己不擅长的事" 的桥梁工具。
一、LangChain可以解决什么问题
| 问题类型 | 痛点说明 | 典型应用 |
|---|---|---|
| 对话记忆缺失 | 多轮对话记不住历史信息 | 带记忆的 AI 客服、个人 AI 助手 |
| 知识过时 / 不足 | 大模型不知道最新数据或专业领域知识 | 私有数据的分析、最新行业政策解读、企业知识库问答问答,个人知识管理等 |
| 无法对接外部工具 | 只能输出文字,不能执行实际操作 | 自动查天气、生成 Excel 报表、调用 API,发送邮件,查询数据库等 |
| 多步骤任务拆解 | 无法完成需要多步骤推理 + 工具调用的复杂任务 | 编写技术报告(网络查询相关资源 + 整理内容 + 生成格式+得出结果)、旅游攻略生成(查景点 + 天气 + 交通),处理需要多个步骤才能完成的复杂任务 |
| 解决「多模态 / 多模型协同开发」的问题 | 单一 LLM 只能处理文本,而实际应用常需要文本、图像、音频、视频的多模态交互,或多个 LLM / 模型的协同,可以集各个不同的模型最擅长的方面,更好解决目标问题 | 图像内容分析,跨模型协作 |
| 解决不同模型提供商api调用的格式不统一 | 不同的模型提供商,调用模型的方式有时候有所不同,这导致太依赖单一厂商,如果使用多个厂商的模型,还要有不同的处理方式,以及存在重复编码的问题 | 统一的框架,可以自由的切换使用openai类型的模型接口 |
二、数据流转介绍
1.从用户输入到LangChain框架处理,在返回结果给用户
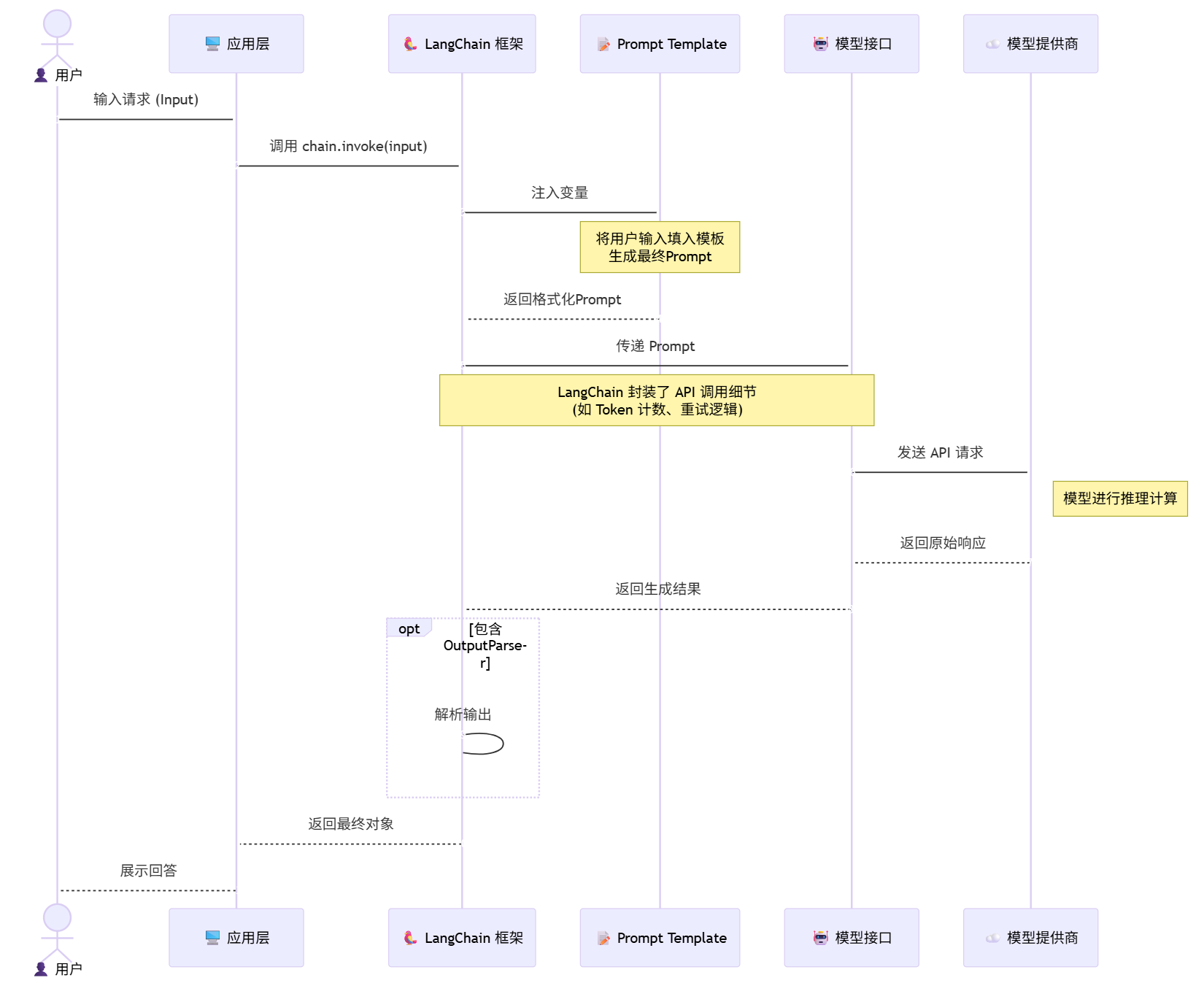
2.版本的新特性,V1.0和V0.3
LangChain V0.3 是 0.x 系列的最后一个大版本,而 V1.0是 LangChain 首个稳定生产级正式版,并非简单的小版本迭代,而是架构重构 + API 固化 + 能力升级 + 生态规范的全方位质变,两个版本的核心定位、设计理念、生产可用性有本质区别。
2.1新增特性
- 统一Agent创建接口: create_agent()
- 中间件系统:(Middleware) 细粒度流程控制
- 标准化输出:content_bloks,不论试用哪个厂商的模型,输出统一的结构化内容。
- 结构化输出原生支持:将输出的内容结构化输出(json结构),并在主循环中使用。
- 基于LangGraph的底层架构:Agent实际是LangGraph编排的状态图(StateGraph)。
- 包结构精简与迁移路径:移除冗余模块,核心包更加轻量。旧版的V0.3功能(如LLMChain,ConversationBufferMemory)迁移到langchain-classic。
详细说明:
1.统一Agent创建接口
python
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langchain import create_agent
# 1. 定义工具
@tool
def search(query: str) -> str:
"""搜索指定关键词的信息"""
return f"搜索结果:{query} 的相关内容"
# 2. 初始化任意LLM(OpenAI/Anthropic/Azure/Gemini均可)
llm = ChatOpenAI(model="gpt-4")
# 3. 【核心】一行代码创建Agent,无其他冗余配置
agent = create_agent(llm, [search])
# 4. 统一调用方式
result = agent.invoke({"input": "帮我搜索2026年人工智能行业趋势"})2.中间件系统
✔️ 核心:Agent 的全生命周期「可挂载节点」(细粒度到极致)
V1.0 将 Agent 的执行链路,标准化为以下核心可拦截节点(所有节点都支持挂载中间件),覆盖从输入到输出的每一个环节:
- 输入预处理阶段:Agent 接收到用户输入后,思考前 → 可做:输入脱敏、关键词过滤、输入格式校验、上下文补全;
- 思考阶段:LLM 生成思考步骤 / 工具调用意图后 → 可做:思考内容日志埋点、思考意图校验、非法意图拦截;
- 工具调用前置阶段:决定调用某个工具后,执行调用前 → 可做:工具权限校验、参数合法性校验、限流控制、调用日志;
- 工具调用后置阶段:工具返回结果后,Agent 继续思考前 → 可做:结果二次加工、结果格式化、结果校验、失败重试;
- 输出阶段:Agent 生成最终答案后,返回给用户前 → 可做:输出内容过滤、敏感词替换、输出格式化、结果埋点、耗时统计。
✔️ 中间件的核心特性
① 可插拔:中间件是独立的模块,挂载 / 卸载无需修改核心业务代码,一行代码即可生效;
② 可组合:多个中间件可以挂载在同一个节点上,按顺序执行,比如「日志埋点 + 权限校验 + 限流」可以同时挂载在工具调用前置节点;
③ 可复用:中间件是标准化的,一个中间件可以挂载到任意 Agent/Chain 上,比如一个「脱敏中间件」可以复用在所有需要输入脱敏的 Agent 中;
④ 无侵入:中间件只拦截输入 / 输出,不修改 Agent 的核心执行逻辑,完美解耦。
python
from langchain_core.runnables import RunnablePassthrough
from langchain import create_agent
from langchain_openai import ChatOpenAI
# 定义一个「工具调用日志中间件」
def log_tool_call(inputs):
print(f"【工具调用日志】调用工具:{inputs['tool_name']},参数:{inputs['tool_input']}")
return inputs
# 创建Agent
llm = ChatOpenAI(model="gpt-4")
agent = create_agent(llm, [search])
# 【核心】挂载中间件到「工具调用前置节点」
agent = agent.with_middleware(log_tool_call, at="tool_call_pre")
# 调用Agent,中间件自动生效
agent.invoke({"input": "搜索2026年AI趋势"})3.标准化输出
标准结构如下(Pydantic 强类型定义):
python
from pydantic import BaseModel
from typing import List, Optional, Dict
class ContentBlock(BaseModel):
type: str # 必选:内容类型,固定枚举值 → text/code/image/tool_call/metadata
content: str # 必选:内容主体,纯文本/代码片段/图片URL/工具调用JSON
metadata: Optional[Dict] = None # 可选:元数据,如来源、置信度、模型名称等
id: Optional[str] = None # 可选:唯一标识ID核心枚举类型(type)全覆盖所有场景:
- text:普通文本回答(99% 的场景);
- code:代码片段(比如 Agent 生成的 Python 代码);
- image:图片内容(比如多模态模型返回的图片 URL);
- tool_call:工具调用的结构化结果;
- metadata:模型返回的元数据(比如 token 消耗、耗时)。
✔️ 核心特性
① 自动归一化:所有 LLM/Agent 的输出,都会被 LangChain 底层自动转换为 content_blocks 格式,开发者无需手动转换,无感知使用;
② 强类型校验:基于 Pydantic 的强类型定义,不会出现格式错误,解析时无需做异常判断;
③ 按需提取:数组结构支持「多内容块共存」,比如 Agent 的回答中既有文本,又有代码,会被拆分为两个 ContentBlock,开发者可以按需提取;
④ 完全兼容:content_blocks 是 V1.0 的默认输出格式,所有新接口(create_agent()、LangGraph)都原生返回该格式,无需手动开启。
4.结构化输出原生支持
所有 V1.0 的 LLM 实例,都内置了该方法,无需手动写 Prompt、无需手动挂载解析器,一行代码即可让 LLM 输出指定结构的 JSON,底层会自动生成最优的 Prompt 提示、自动绑定 Schema、自动校验格式:
python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
# 1. 定义你需要的JSON结构(强类型)
class ProductInfo(BaseModel):
product_name: str
price: float
category: str
stock: int
# 2. 初始化LLM,一行开启结构化输出
llm = ChatOpenAI(model="gpt-4").with_structured_output(ProductInfo)
# 3. 调用LLM,直接返回「结构化的ProductInfo对象」,不是字符串!
result = llm.invoke("帮我提取商品信息:苹果手机15,价格5999元,分类数码产品,库存100台")
print(result.product_name) # 直接点属性调用,无需解析JSON → 苹果手机15
print(result.price) # 5999.05.基于LangGraph的底层架构
核心特性 & 价值(史诗级,生产级刚需)
① 彻底摆脱线性逻辑:支持任意复杂的流程编排,分支、循环、并行、重试、中断、恢复,应有尽有,比如:规划→执行→重试→合并结果,轻松实现;
② 可视化调试:LangGraph 内置了可视化能力,能将 StateGraph 绘制成流程图,开发者可以直观地看到 Agent 的执行路径,调试效率提升 10 倍;
③ 状态持久化:全局状态池(State)可以被持久化到数据库中,实现「Agent 的断点续跑」,比如一个长任务执行到一半中断,下次可以从断点继续执行;
④ 高扩展性:新增功能只需新增节点,无需修改核心逻辑,比如新增一个「输出脱敏」节点,直接挂载到生成节点后即可;
⑤ 所有特性的基石:前面的create_agent()统一接口、Middleware 中间件、content_blocks 标准化输出、结构化输出原生支持,全部基于 StateGraph 的节点和状态池实现。
6.包结构精简与迁移路径
3. 提示词模板
在 LangChain 中,提示词模板(Prompt Template) 是连接用户输入与大模型的核心桥梁,也是实现提示词标准化、复用化、结构化 的关键工具。它的核心价值是:将硬编码的提示词转为「可配置、可复用、支持动态变量注入」的模板,避免重复编写相似提示词,同时提升大模型生成结果的稳定性和一致性。
为什么需要:
- 不可以进行复用,多个不同的场景可能需要修改整个提示词。
- 没有固定的标准,团队协作的提示词风格不同,难以管理。
- 难以维护,对于变量的注入需要手动写代码。
4.两类核心模板:
4.1 基础模板:PromptTemplate(适合纯文本LLM)
核心步骤:定义模板 → 初始化 → 绑定变量 → 调用 LLM
步骤 1:定义模板并初始化 PromptTemplate,通过 input_variables 指定模板中的变量,template 字段写入带占位符的提示词。
python
from langchain_core.prompts import PromptTemplate
# 1. 定义提示词模板:包含2个变量 {topic} 和 {word_count}
template = """
请你写一篇关于{topic}的科普短文。
要求:
1. 语言通俗易懂,适合非专业读者;
2. 字数严格控制在{word_count}字以内;
3. 必须包含至少1个核心知识点。
"""
# 2. 初始化 PromptTemplate,指定变量列表
prompt_template = PromptTemplate(
input_variables=["topic", "word_count"], # 必须与模板中的变量一一对应
template=template
)步骤 2:绑定变量,生成最终提示词
通过 format() 方法传入变量值,生成可直接发给大模型的提示词。
python
# 绑定变量:传入 topic 和 word_count 的具体值
final_prompt = prompt_template.format(topic="人工智能大模型", word_count=300)
print(final_prompt)
# 结果
请你写一篇关于人工智能大模型的科普短文。
要求:
1. 语言通俗易懂,适合非专业读者;
2. 字数严格控制在300字以内;
3. 必须包含至少1个核心知识点。步骤 3:对接 LLM,获取生成结果
在 V1.0 中,PromptTemplate 实现了 Runnable 接口,可以直接与 LLM 串联成链路。
python
from langchain_openai import ChatOpenAI
# 初始化 LLM
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 串联 模板 + LLM 成 Runnable 链路
chain = prompt_template | llm
# 调用链路(传入变量字典)
result = chain.invoke({"topic": "人工智能大模型", "word_count": 300})
print(result.content)4.2 对话模板ChatPromptTemplate(适用于对话模型)
核心步骤:定义角色片段 → 组装模板 → 调用 LLM
步骤 1:定义角色片段(SystemMessagePromptTemplate/HumanMessagePromptTemplate)
对话模板由多个消息片段(Message Prompt Template) 组成,每个片段对应一个角色。
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate
# 1. 定义系统角色模板:设置助手的行为准则(固定不变,可复用)
system_template = """
你是一个专业的{field}科普助手,语言风格{style}。
回答要求:
1. 必须基于事实,拒绝编造;
2. 长度不超过200字;
3. 结尾必须加上一句相关的趣味小知识。
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
# 2. 定义用户角色模板:接收用户的动态输入
user_template = "请解释一下 {concept} 的核心原理"
human_message_prompt = HumanMessagePromptTemplate.from_template(user_template)步骤 2:组装为 ChatPromptTemplate
python
# 组装:system → user(顺序很重要,系统指令优先)
chat_prompt_template = ChatPromptTemplate.from_messages([
system_message_prompt,
human_message_prompt
])步骤 3:绑定变量并调用 LLM
python
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo")
chain = chat_prompt_template | llm
# 传入所有变量:system 的 field/style + user 的 concept
result = chain.invoke({
"field": "计算机科学",
"style": "风趣幽默",
"concept": "大语言模型的注意力机制"
})
print(result.content)
# 结果
#大语言模型的注意力机制,就像你读书时会重点关注关键词一样------模型处理文本时,会给不同单词分配不同权重,让相关词汇"更受重视"。比如翻译"我爱中国",它会聚焦"我""爱""中国"的关联,而非无关虚词。
#趣味小知识:注意力机制最早在2017年的Transformer论文中被提出,如今已是大模型的核心基石~4.3 通过动态提示词
提示词也可以动态的进行设置:可以根据不同的角色类型动态使用不同的提示词,例如一个专业的人问一个知识,一个新手问一个相同的知识,就需要针对不同的角色,回答出不同的内容,可以更好的让其进行理解。
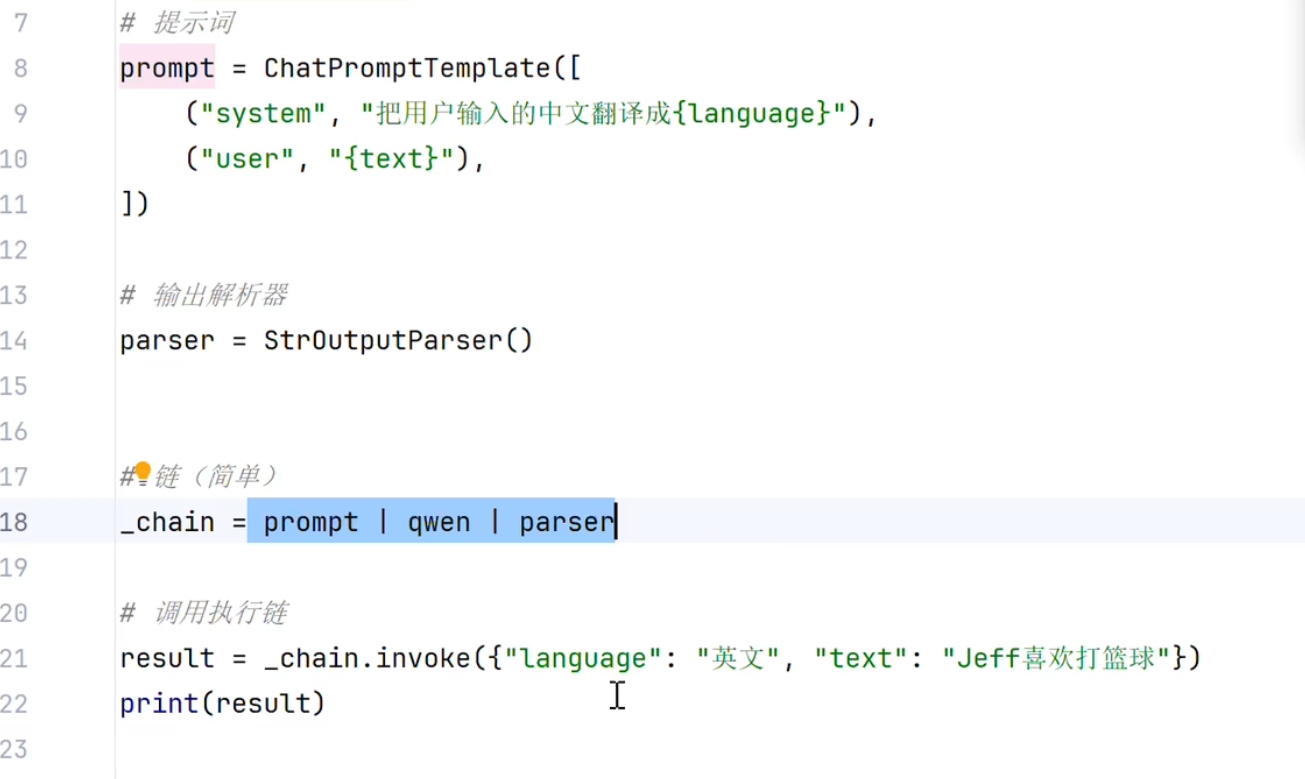
5.LangChain的链

**说明:**这里通过一个提示词的模板,然后动态传入不同的提示词,并使用一个解析器将最后的结果转为字符串。链的说明:_chain = 将提示词 | 大模型 | 解析器,通过一个管道"|"将提示词,大模型,解析器串在一起,实现最终的功能,减少了不必要的代码,简化代码结构和中间变量。
总结
LangChain 是一款开源的大模型应用开发框架,核心目标是降低大模型应用的开发门槛,通过组件化、模块化、可扩展的设计,将大模型与外部工具、数据、系统进行高效串联,帮助开发者快速构建从**「简单原型」到「企业级生产应用」**的全链路大模型系统。