1. 研究背景
机器翻译(Machine Translation, MT)是自然语言处理领域最具挑战性的任务之一。从早期的基于规则的方法,到统计机器翻译(SMT),再到神经机器翻译(NMT),翻译质量不断提升。
基于规则的方法(1950s-1980s)依赖语言学家编写的语法规则和词典,统计机器翻译(1990s-2010s)基于大规模双语平行语料库,使用短语表和语言模型,神经机器翻译(2014至今)采用端到端(End-to-End)学习。2017年,Google团队发表《Attention Is All You Need》论文,提出Transformer架构,彻底改变了NLP领域,其是BERT、GPT等预训练模型的基础,推动了大规模语言模型的发展,在机器翻译、文本生成等任务上取得SOTA效果。
本项目立足于Transformer模型,解决实际翻译需求,能够帮助大家理解深度学习在NLP中的最新进展,为后续研究(如大模型)奠定基础。
2. 研究目的
本研究旨在设计并实现一个基于Transformer的英中机器翻译系统,具体目标包括:
- 完整实现Transformer编码器-解码器架构;
- 探索有效的训练策略和超参数配置;
- 在有限数据下获得可接受的翻译质量;
本项目在数据、计算、质量方面还存在一些挑战和限制:
- 数据挑战:训练数据有限(仅200句平行语料)、 词表规模小(英文215词,中文411词)、数据多样性不足
- 计算挑战:模型参数量大(66万参数)、训练时间长(CPU环境下)、GPU内存管理
- 质量挑战:小数据集容易过拟合、翻译流畅度和准确性平衡、未知词(OOV)处理
3. 技术方案
3.1 核心技术栈
- 深度学习框架:PyTorch 2.6
- 数值计算:NumPy
- 可视化:Matplotlib
- 开发环境:Python 3.9
- 硬件加速:CUDA(可选)
3.2 项目结构
QASystemSim/
├── config.py # 大模型配置
├── config_small.py # 小模型配置
├── tokenizer.py # 分词器实现
├── dataset.py # 数据集类
├── transformer_layers.py # Transformer核心组件
├── model.py # 完整Transformer模型
├── prepare_data.py # 数据预处理
├── train.py # 大模型训练脚本
├── train_small.py # 小模型训练脚本
├── translate.py # 翻译/推理脚本
├── test.py # 系统测试
├── data/ # 数据目录
│ ├── train.en # 英文训练数据
│ ├── train.zh # 中文训练数据
│ ├── tokenizer.en # 英文分词器
│ └── tokenizer.zh # 中文分词器
├── checkpoints/ # 模型检查点
│ ├── final_model.pt # 大模型
│ └── final_model_small.pt # 小模型
└── logs/ # 训练日志
├── training_log.txt # 大模型日志
├── training_log_small.txt # 小模型日志
└── training_curve.png # 训练曲线
3.3 算法结构
本系统采用标准的Transformer架构,包含以下核心组件:
- 输入层
- 词嵌入 + 位置编码
- 编码器(N层)
- 解码器(N层)
- 输出层(线性投影 + Softmax)
- 翻译结果
本系统采取的训练策略如下:
- 损失函数采取交叉熵损失;
- 优化器采取Adam优化器;
- 学习率调度采取Warmup策略。前warmup_steps,线性增长,warmup_steps后,平方根衰减,平衡训练初期稳定性和后期收敛速度。
本系统采取的解码策略包括贪婪解码和束搜索解码。
一、贪婪解码
贪婪解码每步选择概率最大的词,速度快,但可能陷入局部最优,适合快速测试。核心算法如下所示:
def greedy_decode(model, src, src_mask, max_len, start_symbol, device):
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).long().to(device)
for i in range(max_len - 1):
# 创建未来掩码
tgt_mask = (1 - torch.triu(
torch.ones(1, ys.size(1), ys.size(1)),
diagonal=1
)).bool().to(device)
# 解码一步
out = model.decode(ys, memory, tgt_mask, src_mask)
prob = model.fc_out(out[:, -1])
# 选择概率最大的词
_, next_word = torch.max(prob, dim=1)
next_word = next_word.item()
# 拼接到输出
ys = torch.cat([ys,
torch.ones(1, 1).fill_(next_word).long().to(device)],
dim=1)
# 遇到结束符停止
if next_word == eos_token_id:
break
return ys二、束搜索解码
束搜索解码保留top-k个候选序列,平衡速度和质量,通常比贪婪解码效果更好。核心算法如下所示:
def beam_search_decode(model, src, src_mask, max_len, start_symbol, beam_size, device):
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).long().to(device)
sequences = [(ys, 0.0)]
for i in range(max_len - 1):
all_candidates = []
for seq, score in sequences:
if seq[0, -1].item() == eos_token_id:
all_candidates.append((seq, score))
continue
tgt_mask = (1 - torch.triu(
torch.ones(1, seq.size(1), seq.size(1)),
diagonal=1
)).bool().to(device)
out = model.decode(seq, memory, tgt_mask, src_mask)
prob = model.fc_out(out[:, -1])
log_prob = torch.log_softmax(prob, dim=-1)
topk_probs, topk_indices = torch.topk(log_prob, beam_size)
for j in range(beam_size):
next_word = topk_indices[0, j].item()
new_seq = torch.cat([seq,
torch.ones(1, 1).fill_(next_word).long().to(device)],
dim=1)
new_score = score + topk_probs[0, j].item()
all_candidates.append((new_seq, new_score))
sequences = sorted(all_candidates, key=lambda x: x[1], reverse=True)[:beam_size]
if all(seq[0, -1].item() == eos_token_id for seq, _ in sequences):
break
best_seq, best_score = sequences[0]
return best_seq4. 实现流程
4.1 数据准备阶段
一、数据集构建
数据来源为英中平行语料库(200句),涵盖日常对话、技术文档等场景。
数据格式如下所示:
train.en:
Hello world
How are you
I love programming
...
train.zh:
你好世界
你好吗
我爱编程
...
二、分词器构建
英文分词:
- 基于单词的分词
- 保留大小写
- 添加特殊标记:<pad>, <sos>, <eos>, <unk>
中文分词:
- 基于字符的分词
- 处理中文字符
- 添加特殊标记
特殊标记:
- <pad>: 填充标记 (0)
- <sos>: 序列开始 (1)
- <eos>: 序列结束 (2)
- <unk>: 未知词 (3)
三、数据预处理
- 读取原始文本
- 分词并转换为索引
- 统一序列长度(填充或截断)
- 构建数据集类
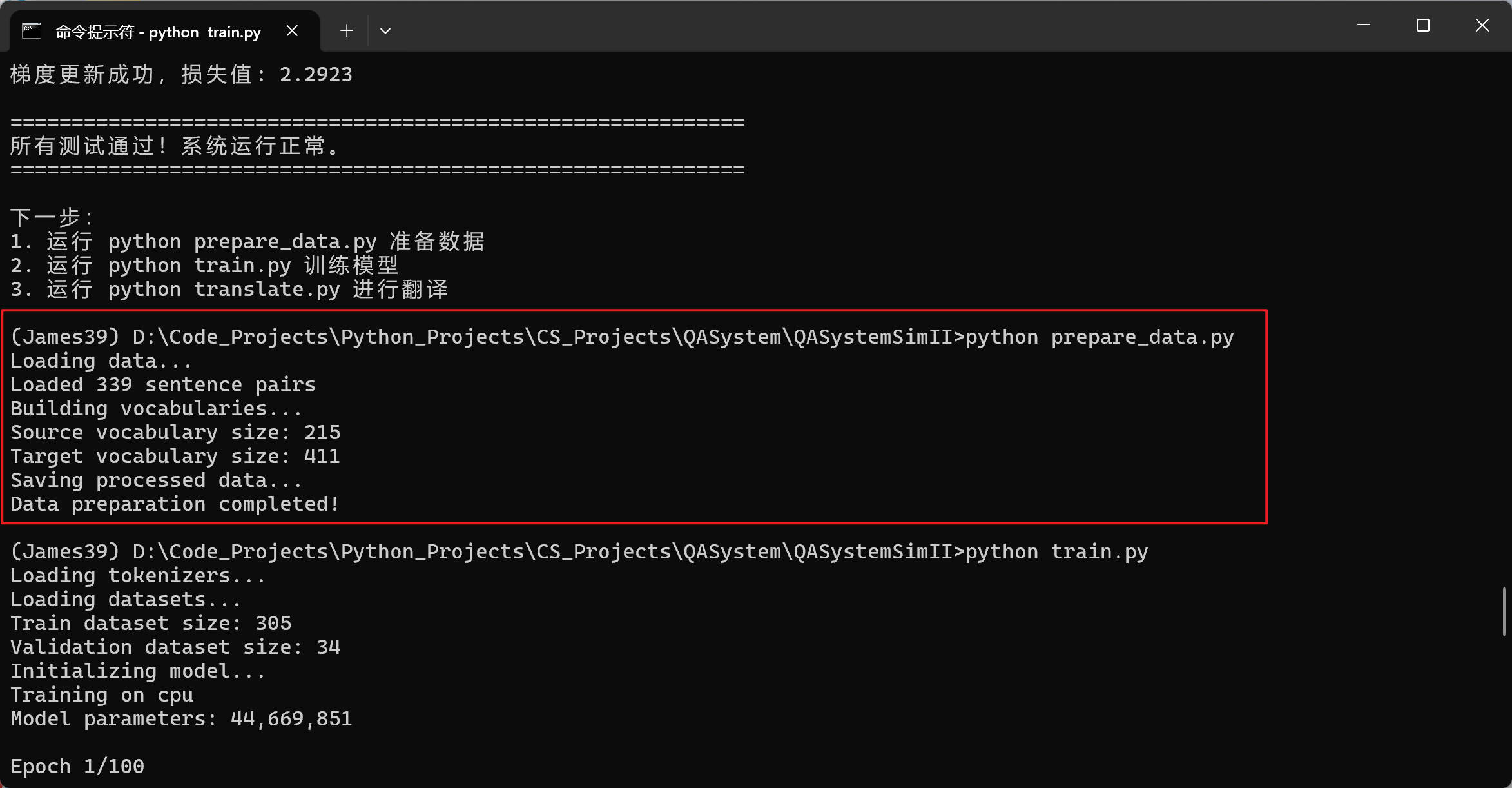
执行prepare_data.py代码,运行效果如下图所示:
4.2 模型训练
训练流程的核心算法如下所示:
ef train_epoch(model, dataloader, criterion, optimizer, scheduler, config, device):
model.train()
total_loss = 0
for batch in dataloader:
# 数据移到设备
src = batch['src'].to(device)
tgt = batch['tgt'].to(device)
src_mask = batch['src_mask'].to(device)
tgt_mask = batch['tgt_mask'].to(device)
# 梯度清零
optimizer.zero_grad()
# 准备目标输入(移除最后一个token)
tgt_input = tgt[:, :-1]
tgt_output = tgt[:, 1:]
# 创建目标掩码(未来掩码)
seq_len = tgt_input.size(1)
tgt_mask_input = (tgt_input != tgt[0, 0].to(device)
.unsqueeze(1).unsqueeze(3))
nopeak_mask = (1 - torch.triu(
torch.ones(1, seq_len, seq_len),
diagonal=1
)).bool().to(device)
tgt_mask_input = tgt_mask_input & nopeak_mask
# 前向传播
output = model(src, tgt_input, src_mask, tgt_mask_input)
# 计算损失
output = output.reshape(-1, output.size(-1))
tgt_output = tgt_output.reshape(-1)
loss = criterion(output, tgt_output)
# 反向传播
loss.backward()
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(
model.parameters(),
config.gradient_clip
)
# 参数更新
optimizer.step()
lr = scheduler.step()
total_loss += loss.item()
return total_loss / len(dataloader)验证流程的核心算法如下所示:
def validate(model, dataloader, criterion, device):
model.eval()
total_loss = 0
with torch.no_grad():
for batch in dataloader:
src = batch['src'].to(device)
tgt = batch['tgt'].to(device)
src_mask = batch['src_mask'].to(device)
tgt_mask = batch['tgt_mask'].to(device)
tgt_input = tgt[:, :-1]
tgt_output = tgt[:, 1:]
seq_len = tgt_input.size(1)
tgt_mask_input = (tgt_input != tgt[0, 0].to(device)
.unsqueeze(1).unsqueeze(3))
nopeak_mask = (1 - torch.triu(
torch.ones(1, seq_len, seq_len),
diagonal=1
)).bool().to(device)
tgt_mask_input = tgt_mask_input & nopeak_mask
output = model(src, tgt_input, src_mask, tgt_mask_input)
output = output.reshape(-1, output.size(-1))
tgt_output = tgt_output.reshape(-1)
loss = criterion(output, tgt_output)
total_loss += loss.item()
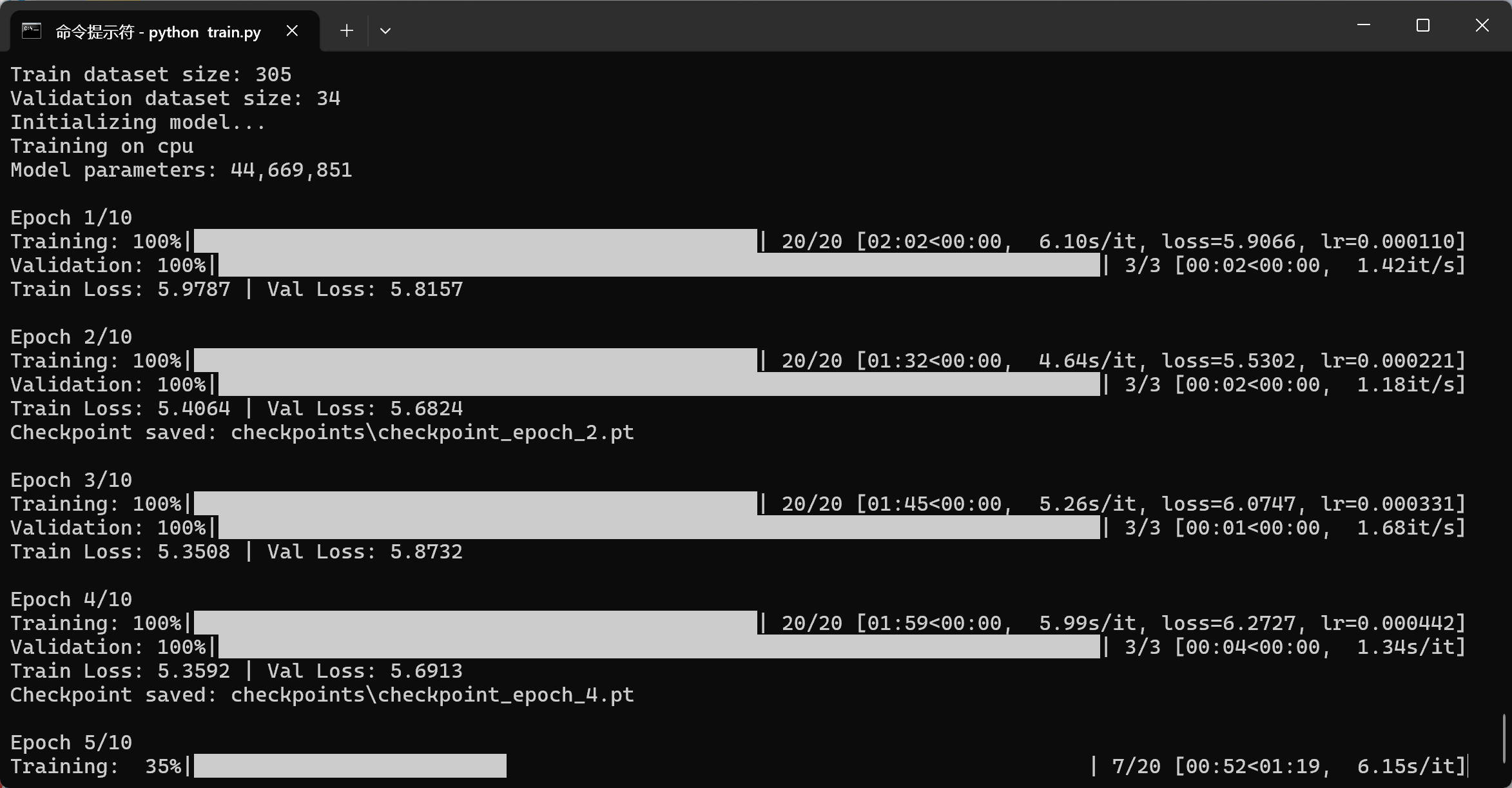
return total_loss / len(dataloader)执行train.py或者train_small.py代码的运行效果图如下所示:
4.3 推理与翻译
翻译流程的核心代码如下所示:
def translate(model, src_sentence, src_tokenizer, tgt_tokenizer, config, device):
model.eval()
# 编码源句子
src_encoded = src_tokenizer.encode(src_sentence, config.max_seq_len)
src_tensor = torch.tensor(src_encoded).unsqueeze(0).to(device)
# 创建源掩码
src_mask = (src_tensor != src_tokenizer.word2idx['<pad>'])
.unsqueeze(1).unsqueeze(2).to(device)
# 解码
start_symbol = tgt_tokenizer.word2idx['<sos>']
output = greedy_decode(
model, src_tensor, src_mask,
config.max_decode_len, start_symbol, device
)
# 解码
translation = tgt_tokenizer.decode(output[0].tolist())
return translation执行translate.py代码开始进行英译中,运行效果如下图所示:
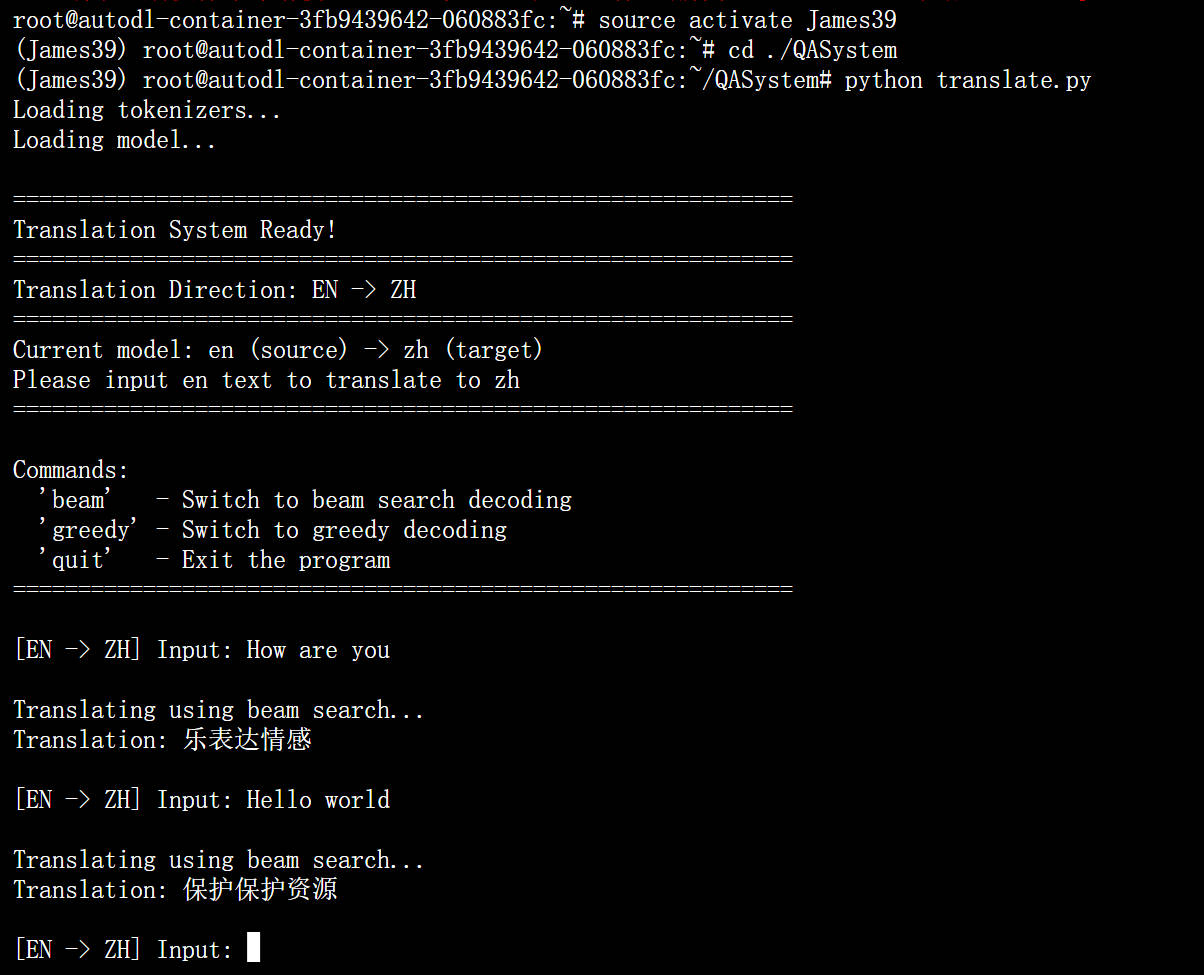
由于数据集较小,尽管通过train.py还是train_small.py代码训练的大模型、小模型已经训练了5000个epoch,但翻译效果仍然不佳。后续改进的方向就是增加数据集大小、提高模型复杂度。
4.4 日志与监控
- 训练日志:记录模型配置信息、数据集统计、每个epoch的训练/验证损失、学习率变化、最佳模型epoch
- 可视化:绘制训练损失和验证损失、保存为PNG图片、直观展示训练过程
5. 总结
总言之,本项目已完成如下功能:
- 英中机器翻译系统
- 多种解码策略(贪婪、束搜索)
- 自动模型加载
- 训练日志记录
- 交互式翻译界面
模型配置信息如下所示:
- 大模型:66万参数,6层编码器/解码器
- 小模型:16万参数,2层编码器/解码器
- 支持GPU加速训练
本项目还存在以下影响因素:
- 数据规模:200句数据不足以训练高质量模型
- 词表大小:小词表限制了表达能力
- 训练轮数:50-100个epoch偏少,建议1000+
- 模型容量:小数据集下大模型容易过拟合
最后,上传该项目的运行视频供参考:
基于Transformer模型的智能机器翻译算法