本期内容为自己总结归档,7天学会Redis。其中本人遇到过的面试问题会重点标记。
(若有任何疑问,可在评论区告诉我,看到就回复)
Day 6 - 内存&性能调优
6.1 缓存设计模式
6.1.1 缓存穿透解决方案:布隆过滤器
什么是缓存穿透?
缓存穿透是指查询一个不存在的数据,由于缓存中没有,请求会穿透到数据库,如果大量这样的请求,会给数据库带来巨大压力甚至崩溃。
典型场景:
-
恶意攻击:故意请求不存在的ID
-
业务逻辑缺陷:查询已删除或未创建的数据
-
示例
⭐布隆过滤器原理
布隆过滤器(Bloom Filter)是一种概率型数据结构,用于快速判断一个元素是否一定不存在于集合中。
核心特点:
-
空间效率极高:使用位数组和多个哈希函数
-
存在假阳性:可能误判为存在(但不会误判为不存在)
-
不支持删除:标准布隆过滤器不支持删除操作
工作流程:
Redis布隆过滤器实现
Redis 4.0+通过BF.RESERVE、BF.ADD、BF.EXISTS等命令支持布隆过滤器:
bash
# 创建布隆过滤器,指定误差率和容量
BF.RESERVE user_filter 0.01 100000
# 添加元素
BF.ADD user_filter user:1001
BF.ADD user_filter user:1002
# 检查元素是否存在
BF.EXISTS user_filter user:1001 # 返回1(可能存在)
BF.EXISTS user_filter user:9999 # 返回0(一定不存在)
# 批量操作
BF.MADD user_filter user:1003 user:1004 user:1005
BF.MEXISTS user_filter user:1003 user:9999缓存穿透解决方案
方案1:缓存空对象
bash
public Object getData(String key) {
// 1. 查询缓存
Object value = cache.get(key);
if (value != null) {
if (value instanceof NullObject) {
return null; // 缓存了空值
}
return value;
}
// 2. 查询数据库
value = database.get(key);
// 3. 处理结果
if (value == null) {
// 缓存空值,设置较短过期时间
cache.set(key, new NullObject(), 300); // 5分钟
} else {
cache.set(key, value, 3600); // 1小时
}
return value;
}方案2:布隆过滤器拦截
java
public class BloomFilterCache {
private BloomFilter<String> bloomFilter;
private Cache<String, Object> cache;
public Object getWithBloomFilter(String key) {
// 1. 布隆过滤器检查
if (!bloomFilter.mightContain(key)) {
return null; // 一定不存在
}
// 2. 查询缓存
Object value = cache.get(key);
if (value != null) {
return value;
}
// 3. 查询数据库
value = database.get(key);
if (value == null) {
// 数据库也没有,可能是布隆过滤器误判
// 记录日志,考虑重建布隆过滤器
log.warn("Bloom filter false positive for key: {}", key);
} else {
cache.set(key, value, 3600);
}
return value;
}
public void addToBloomFilter(String key) {
bloomFilter.put(key);
}
}方案3:多层缓存防御
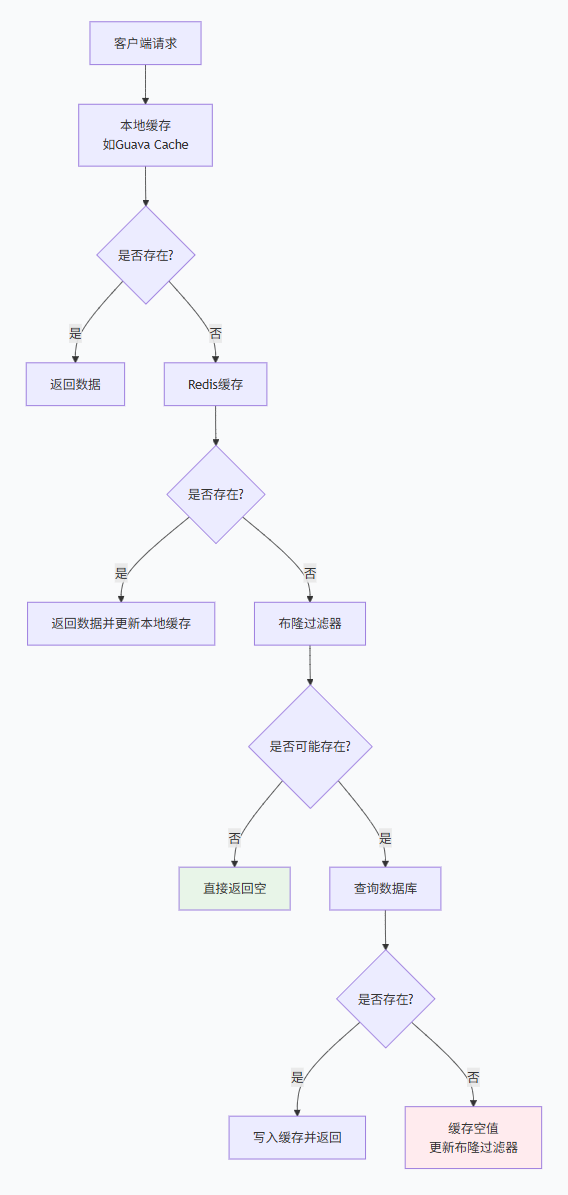
性能对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 缓存空对象 | 实现简单,拦截准确 | 可能缓存大量无效数据 | 数据ID范围有限 |
| 布隆过滤器 | 内存占用小,效率高 | 存在误判率,不支持删除 | 大规模数据,可接受误判 |
| 多层防御 | 防护全面,性能好 | 实现复杂 | 对安全性要求高 |
6.1.2 缓存击穿应对:互斥锁设计
什么是缓存击穿?
缓存击穿是指一个热点key在缓存过期瞬间,有大量并发请求同时查询数据库,导致数据库压力骤增。
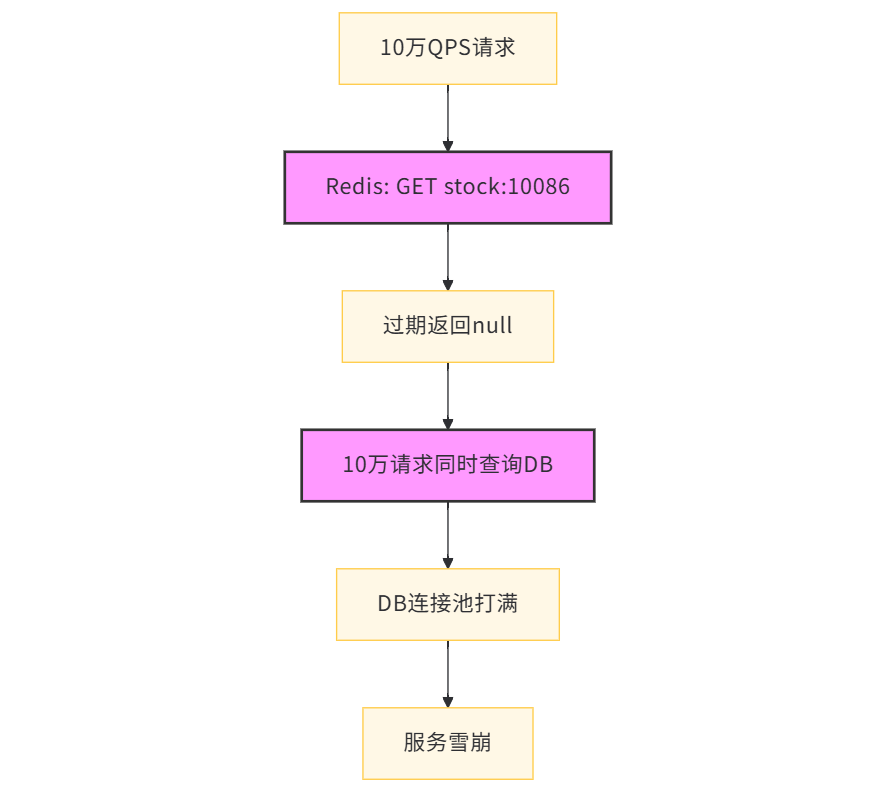
与缓存穿透的区别:
-
缓存穿透:查询不存在的数据
-
缓存击穿:查询存在但过期的热点数据
互斥锁解决方案
核心思想:只允许一个线程去查询数据库,其他线程等待并复用结果。
方案1:Redis分布式锁(关注专栏,后面单独讲)
java
public class CacheBreakdownSolution {
private static final String LOCK_PREFIX = "lock:";
private static final int LOCK_EXPIRE = 10; // 锁过期时间(秒)
public Object getDataWithDistributedLock(String key) {
// 1. 查询缓存
Object value = redis.get(key);
if (value != null) {
return value;
}
// 2. 尝试获取分布式锁
String lockKey = LOCK_PREFIX + key;
String requestId = UUID.randomUUID().toString();
try {
// 使用SET NX EX获取锁
boolean locked = redis.setnxex(lockKey, requestId, LOCK_EXPIRE);
if (locked) {
try {
// 3. 再次检查缓存(double check)
value = redis.get(key);
if (value != null) {
return value;
}
// 4. 查询数据库
value = database.get(key);
// 5. 写入缓存
if (value != null) {
redis.setex(key, 3600, value); // 缓存1小时
} else {
// 数据库也没有,缓存空值防止穿透
redis.setex(key, 300, new NullObject());
}
return value;
} finally {
// 释放锁(使用Lua脚本保证原子性)
String script =
"if redis.call('get', KEYS[1]) == ARGV[1] then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
redis.eval(script, Arrays.asList(lockKey), Arrays.asList(requestId));
}
} else {
// 6. 未获取到锁,等待并重试
Thread.sleep(100);
return getDataWithDistributedLock(key); // 递归重试
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("获取数据中断", e);
}
}
}方案2:本地锁+分布式锁组合
java
public class HybridLockSolution {
// 本地锁(针对单JVM内的并发)
private final ConcurrentHashMap<String, Object> localLocks = new ConcurrentHashMap<>();
public Object getDataWithHybridLock(String key) {
// 1. 查询缓存
Object value = redis.get(key);
if (value != null) {
return value;
}
// 2. 获取本地锁(减少分布式锁竞争)
Object localLock = localLocks.computeIfAbsent(key, k -> new Object());
synchronized (localLock) {
try {
// 再次检查缓存
value = redis.get(key);
if (value != null) {
return value;
}
// 3. 获取分布式锁
String lockKey = "lock:" + key;
String requestId = UUID.randomUUID().toString();
try {
if (redis.setnxex(lockKey, requestId, 10)) {
// 查询数据库
value = database.get(key);
// 写入缓存
if (value != null) {
redis.setex(key, 3600, value);
}
return value;
} else {
// 等待其他线程完成
Thread.sleep(50);
return getDataWithHybridLock(key);
}
} finally {
// 释放分布式锁
releaseDistributedLock(lockKey, requestId);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
} finally {
localLocks.remove(key);
}
}
}
}方案3:逻辑过期时间
java
public class LogicalExpirationSolution {
static class CacheData {
private Object data;
private long expireTime; // 逻辑过期时间
// getters and setters
}
public Object getDataWithLogicalExpiration(String key) {
// 1. 查询缓存
String cacheValue = redis.get(key);
if (cacheValue == null) {
// 缓存不存在,加载数据
return loadData(key);
}
// 2. 反序列化
CacheData cacheData = JSON.parseObject(cacheValue, CacheData.class);
// 3. 检查是否逻辑过期
if (cacheData.getExpireTime() <= System.currentTimeMillis()) {
// 已过期,异步更新
CompletableFuture.runAsync(() -> {
updateData(key);
});
}
// 4. 返回数据(即使过期也返回旧数据)
return cacheData.getData();
}
private Object loadData(String key) {
// 使用互斥锁加载数据
// 实现略...
}
private void updateData(String key) {
// 后台更新数据,使用互斥锁避免并发更新
// 实现略...
}
}互斥锁实现细节
Redis分布式锁的三种实现方式对比:(关注专栏,细节单独讲)
| 实现方式 | 优点 | 缺点 | 推荐度 |
|---|---|---|---|
| SETNX + EXPIRE | 简单直接 | 非原子性,可能死锁 | ⭐⭐ |
| SET NX EX | 原子操作 | Redis 2.6.12+支持 | ⭐⭐⭐⭐ |
| RedLock算法 | 高可用,防单点故障 | 实现复杂,性能较低 | ⭐⭐⭐ |
推荐实现:
bash
# 使用SET命令的NX和EX选项
SET lock:user:1001 request_id NX EX 10
# 解锁使用Lua脚本保证原子性
EVAL "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end" 1 lock:user:1001 request_id热点key检测与预防
检测方法:
-
监控工具 :Redis的
hotkeys参数或监控QPS -
客户端统计:在客户端统计key的访问频率
-
网络分析:通过流量分析识别热点key
预防措施:
-
本地缓存:在应用层缓存热点数据
-
随机过期时间:避免同时过期
-
永不过期+异步更新:设置逻辑过期时间
-
多级缓存:使用本地缓存+Redis+数据库
6.1.3 缓存雪崩预防:分层缓存+过期时间分散
什么是缓存雪崩?
缓存雪崩是指大量缓存key同时过期,导致所有请求直接打到数据库,引起数据库压力过大甚至崩溃。
与缓存击穿的区别:
-
缓存击穿:单个热点key过期
-
缓存雪崩:大量key同时过期
分层缓存架构
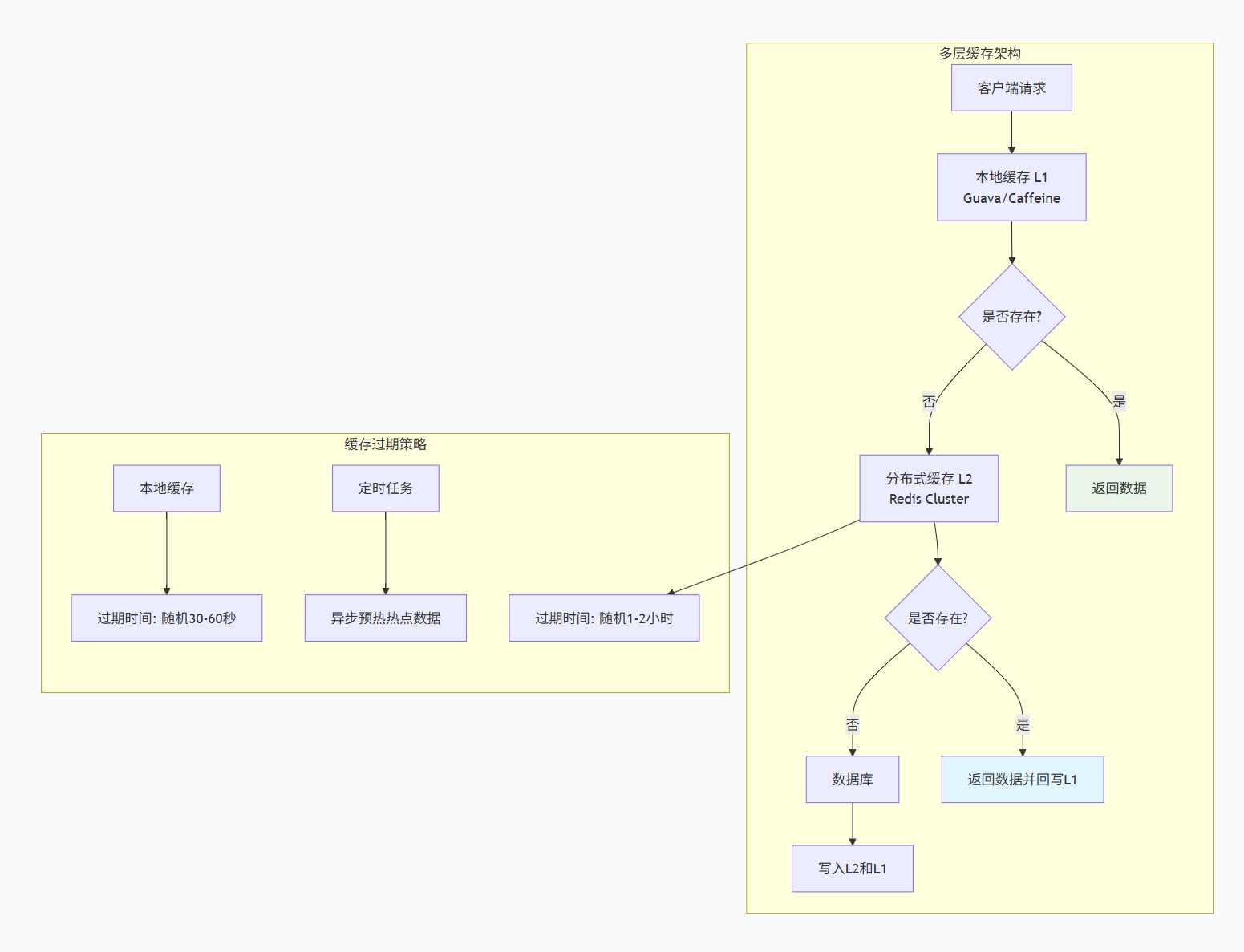
过期时间分散策略
方案1:随机过期事件
方案2:分层过期策略,按业务需要分层过期,注意层级
6.2 内存优化策略
6.2.1 内存淘汰策略深度解析
Redis内存管理机制
Redis内存管理采用"分配器+淘汰策略 "的双层机制。当Redis使用内存达到maxmemory配置值时,会根据指定的淘汰策略自动删除键来释放内存。
内存淘汰触发时机:
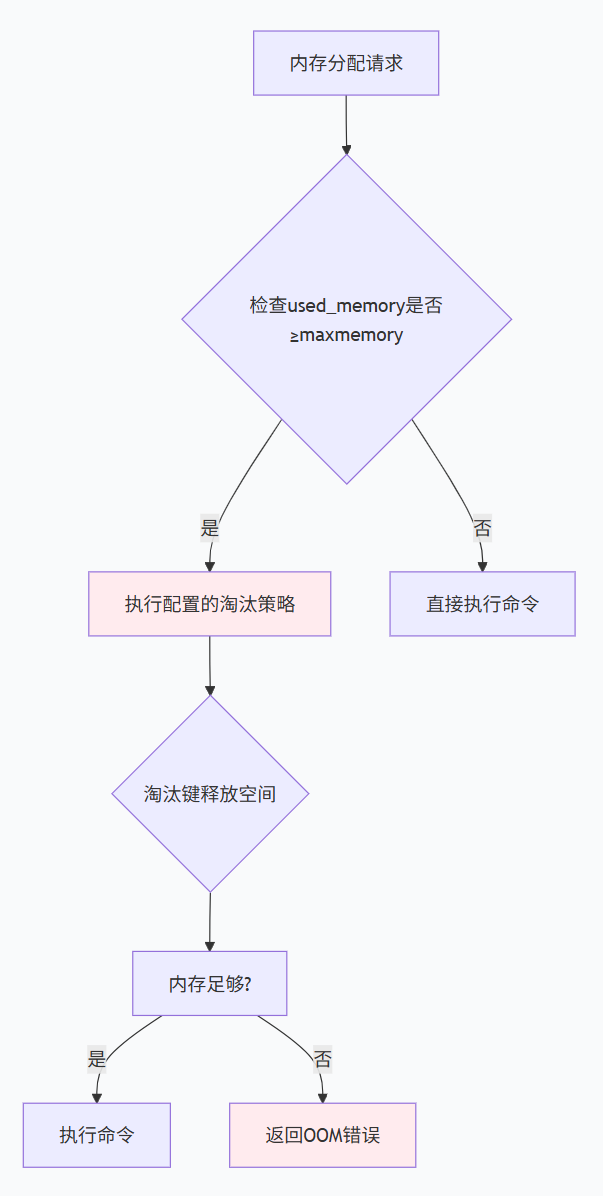
8种内存淘汰策略
Redis提供了8种内存淘汰策略,当内存达到maxmemory限制时触发:
-
noeviction:不淘汰,内存满时拒绝写请求
适用场景:数据绝对不能丢失,有严格监控和扩展机制
-
allkeys-lru:从所有键中使用LRU算法淘汰
适用场景:缓存服务,有明显热点数据
-
volatile-lru:从设置了过期时间的键中使用LRU算法淘汰
适用场景:混合存储,需要保留永久数据
-
allkeys-random:从所有键中随机淘汰
适用场景:访问模式均匀,无明确热点
-
volatile-random:从设置了过期时间的键中随机淘汰
适用场景:缓存数据,不关心淘汰顺序
-
volatile-ttl:从设置了过期时间的键中淘汰剩余时间最短的
适用场景:希望优先淘汰即将过期的数据
-
allkeys-lfu(Redis 4.0+):从所有键中使用LFU算法淘汰
适用场景:需要基于访问频率进行淘汰,如Session存储
-
volatile-lfu(Redis 4.0+):从设置了过期时间的键中使用LFU算法淘汰
适用场景:需要基于频率淘汰,同时保留永久数据
6.2.2 内存碎片整理
Redis内存分配机制
Redis使用自己实现的内存分配器(jemalloc的修改版)来管理内存。内存碎片主要来自两个方面:
-
内部碎片:分配器为对齐而浪费的空间
-
外部碎片:已分配内存块之间的空闲空间
内存分配器层级:
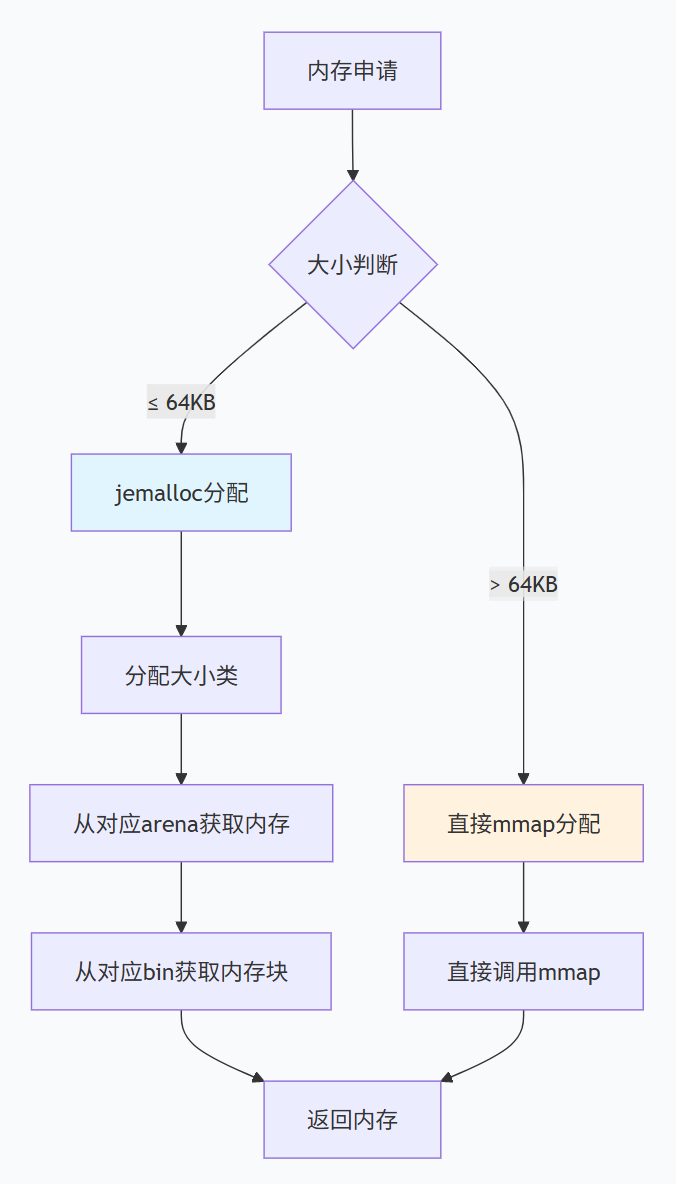
bash
# 查看内存信息
redis-cli info memory
# redis.conf
activedefrag yes # 开启主动整理
active-defrag-threshold-lower 10 # 碎片率>10%开始整理
active-defrag-threshold-upper 100 # 碎片率>100%强制整理
active-defrag-cycle-min 1 # 每次整理占用1% CPU
active-defrag-cycle-max 25 # 最多占用25% CPU
碎片率解读:
1.0 - 1.1:理想状态,几乎无碎片
1.1 - 1.5:正常范围,可接受
1.5 - 2.0:碎片率较高,可能需要干预
> 2.0:碎片率过高,建议采取措施
< 1.0:内存交换(swap)发生,非常危险6.2.2 大Key识别与处理
大Key的定义
| 类型 | 大Key标准 | 风险 |
|---|---|---|
| String | value > 10KB | 阻塞网络,慢查询 |
| Hash/Set/ZSet | 元素数 > 5000 | 操作慢,迁移困难 |
| List | 元素数 > 10000 | 阻塞,内存碎片 |
| Stream | 长度 > 1000 | 内存占用大 |
解决方案
方案1: 拆
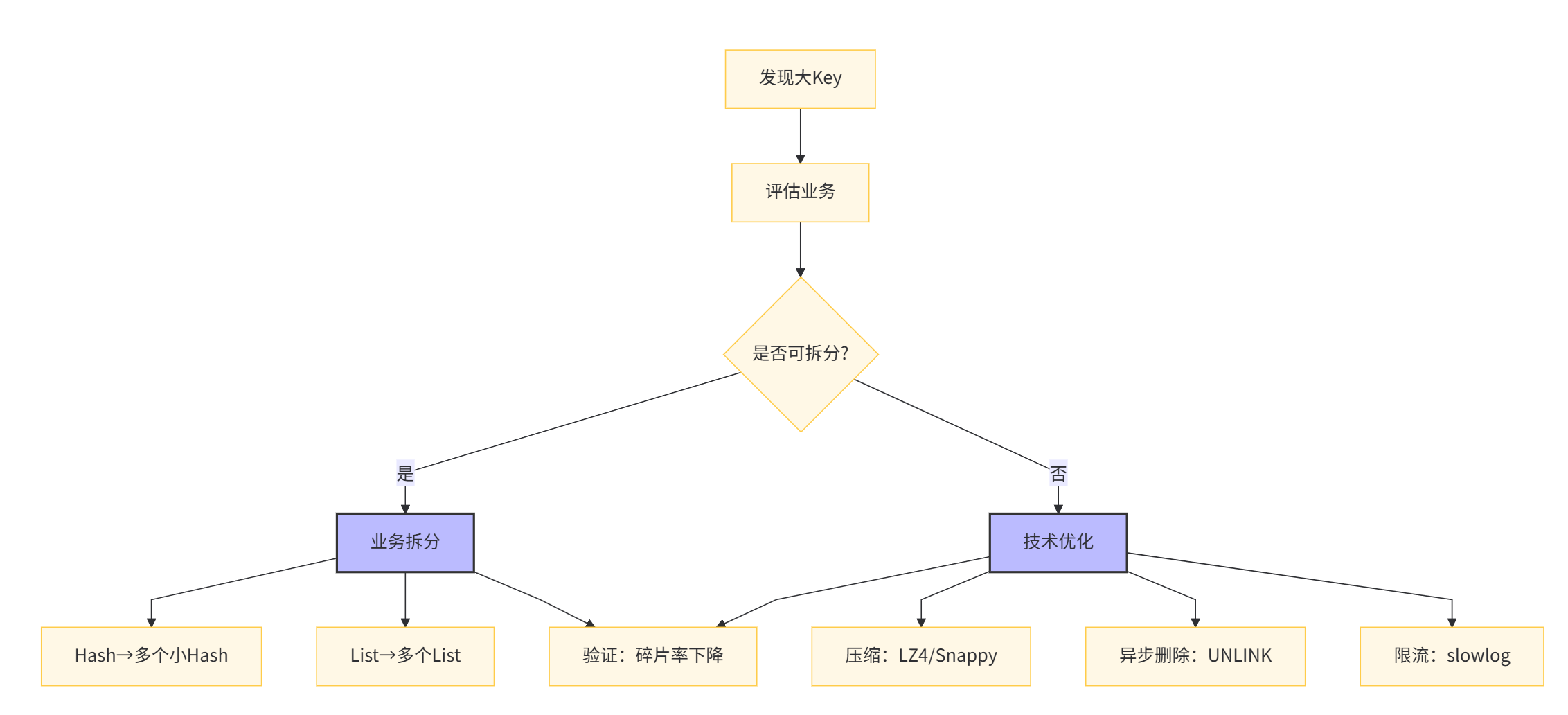
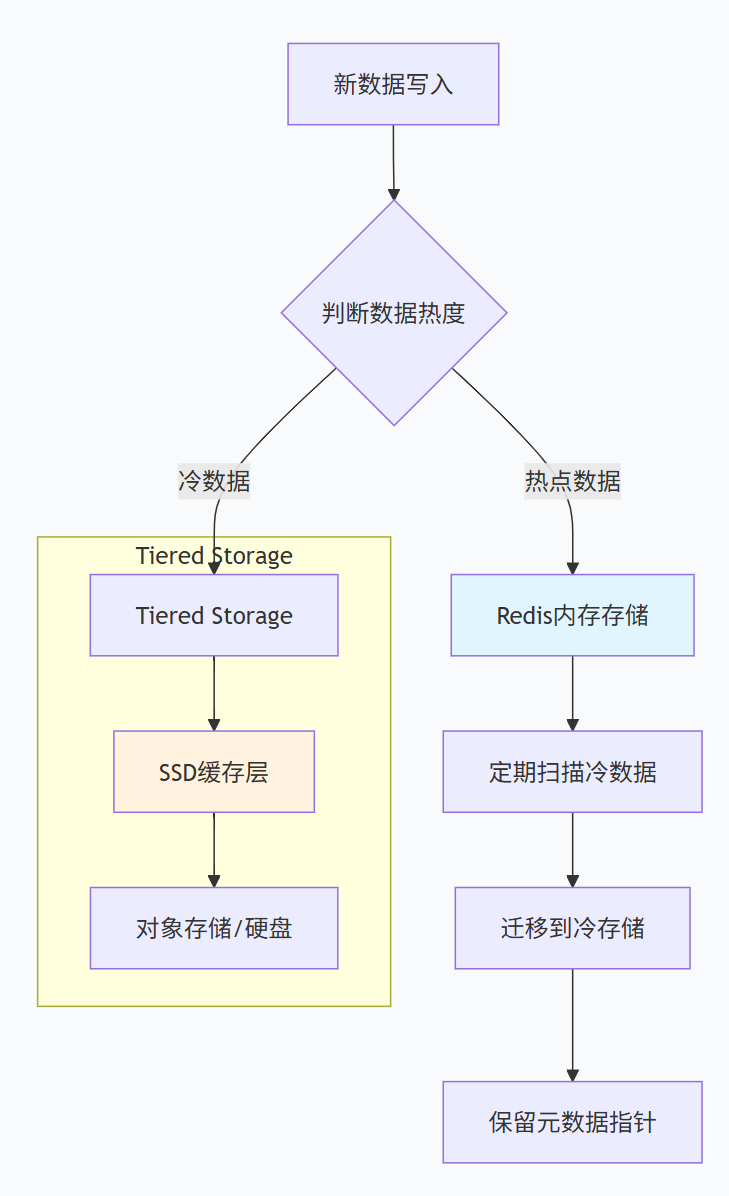
方案2:冷热分离
6.3 面试高频考点
考点1:缓存穿透、击穿、雪崩的区别和解决方案?见上述6.1
考点2:Redis大Key和热Key问题如何排查和解决?
面试回答:
大Key排查:
-
使用redis-cli :
redis-cli --bigkeys -
内存分析 :
redis-cli memory usage key -
RDB分析:使用redis-rdb-tools分析dump文件
-
自定义扫描:使用SCAN命令遍历所有key
大Key解决方案:
-
拆分:将大Hash、List、Set拆分为多个小key
-
压缩:对value进行压缩存储
-
删除:清理无用的大Key
-
数据结构优化:选择更合适的数据结构
-
冷热分离:将冷数据迁移到其他存储
热Key排查:
-
Redis监控 :
redis-cli --hotkeys(Redis 4.0+) -
客户端统计:在客户端统计key访问频率
-
网络分析:分析网络流量识别热Key
-
监控命令 :
redis-cli monitor(谨慎使用)
热Key解决方案:
-
本地缓存:在应用层缓存热Key数据
-
读写分离:将读请求分散到多个从节点
-
分片:将热Key拆分为多个子key
-
限流保护:对热Key请求进行限流
-
数据副本:创建多个副本分散请求
考点3:⭐如何保证缓存与数据库的数据一致性?
见《中间件》专栏 《7天学会Redis》特别篇: 如何保证缓存与数据库的数据一致性?