进程组
进程组的核心定义
进程组是 一个或多个相关进程的集合,可以把它理解成 "进程的分组管理单位"------Linux 系统通过进程组来批量管理一组关联的进程(比如一个命令启动的多个子进程)。
- 唯一标识 :每个进程组有唯一的 进程组 ID(PGID) ,和进程 ID(PID)一样是正整数,存储在
pid_t类型中; - 归属关系 :每个进程除了有自己的 PID,必然属于一个且仅一个进程组(可以理解为 "每个员工都属于一个部门");

组长进程
每个进程组都有一个组长进程,是进程组的 "创建者"。
组长进程的 PID = 该进程组的 PGID(这是判断组长进程的唯一标准)。
通过fork创建子进程,那么父进程就是组长进程。
也可以使用管道,那么第一个就是组长进程
proc2 | proc3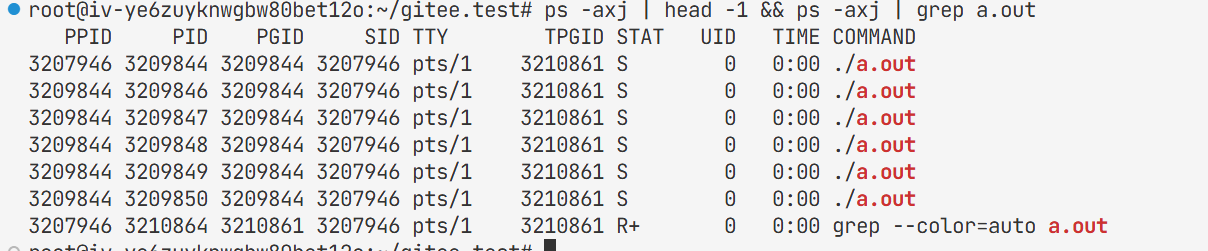
组长进程的作用:负责创建进程组,或创建该组内的其他进程。
进程组的生命周期
- 创建:由组长进程创建(组长进程的 PID 成为该组的 PGID);
- 存续 :只要进程组中还有至少一个进程存在,进程组就存在(无论组长是否终止);
- 销毁 :当进程组中最后一个进程终止 / 退出该组时,进程组才会被销毁。
会话
会话的核心定义
会话是 Linux 进程管理中比进程组更高一层的单位,可以理解为 "进程组的集合",是系统为了管理 "终端关联的一组进程" 而设计的概念。
| 特性 | 说明 |
|---|---|
| 组成 | 一个会话包含一个或多个进程组(比如前台进程组、后台进程组) |
| 唯一标识 | 会话 ID(SID),等于会话首进程的 PID(因为会话首进程必然是进程组组长,所以 SID 也等于其 PGID) |
| 终端关联 | 一个会话通常绑定一个控制终端 (比如 SSH 连接的 pts/2),会话内所有进程共享该终端 |
| 生命周期 | 只要会话中有至少一个进程存在,会话就存在(和进程组逻辑一致) |
会话首进程
会话首进程(Session Leader)是创建会话的进程,核心特征:
- 会话首进程的 PID = 会话的 SID(这是 SID 的定义);
- 会话首进程必然是一个进程组的组长(所以其
PID=PGID=SID); - 会话首进程会成为该会话的 "控制进程",绑定控制终端(会话内所有进程共享这个终端)。
setsid 函数
1. setsid 函数基础
#include <unistd.h>
// 功能:创建新会话,让调用进程成为新会话的首进程
// 返回值:成功返回新会话的 SID(即调用进程的 PID),失败返回 -1
pid_t setsid(void);2. 调用 setsid 后发生的 3 件事
- 调用进程成为新会话的首进程(新会话中只有它一个进程);
- 调用进程成为新进程组的组长(新进程组的 PGID = 调用进程的 PID);
- 调用进程失去控制终端(如果之前和终端绑定,会彻底切断关联)。
进程组组长不能调用setsid
背后的核心目的是:保证进程组的完整性,避免会话管理混乱。
底层逻辑:进程组必须 "完整归属一个会话"
内核规定:一个进程组的所有进程必须属于同一个会话,不能跨会话拆分 ------ 这是会话 / 进程组管理的核心原则(否则终端控制、信号分发、作业控制都会出错)。
假设进程 A 是进程组组长(PID=100,PGID=100),若允许它调用 setsid:
- 进程 A 会成为新会话的首进程(SID=100),进入新会话;
- 但原进程组的其他进程(比如 PID=101、PGID=100)还留在旧会话;
- 结果:同一个进程组的进程被拆分到两个会话,违反 "进程组完整归属一个会话" 的规则,导致终端管理、后台进程控制等逻辑崩溃。
解决方案
"先 fork 创建子进程,父进程终止,子进程调用 setsid"
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
if (pid < 0) {
perror("fork failed"); // fork失败
exit(1);
}
if (pid > 0) {
// 父进程:终止,让子进程成为孤儿进程(非组长)
printf("父进程PID:%d\n", getpid()); // 新会话首进程PID
printf("父进程PGID:%d\n", getpgid(0)); // PGID = 子进程PID(新进程组组长)
wait(NULL); // 可选:等待子进程结束
exit(0);
}
// 子进程:此时PID≠PGID(不是组长),可以安全调用setsid
pid_t sid = setsid();
if (sid == -1) {
perror("setsid failed"); // 调用失败(仅当子进程是组长时发生)
exit(1);
}
// 打印关键信息,验证效果
printf("子进程PID:%d\n", getpid()); // 新会话首进程PID
printf("新会话SID:%d\n", sid); // SID = 子进程PID
printf("子进程PGID:%d\n", getpgid(0)); // PGID = 子进程PID(新进程组组长)
// 子进程现在是新会话首进程+新进程组组长,无控制终端(守护进程核心特征)
while (1) {
sleep(1); // 保持进程运行,方便用ps验证
}
return 0;
}编译运行后,用 ps axj | grep 程序名 查看,会看到:
- 子进程的
PID=PGID=SID(新会话首进程 + 新进程组组长); TTY=?(无控制终端),符合预期。


控制终端
控制终端是 用户与 Linux 系统交互的 "专属通道" ,可以理解为 "进程和用户之间的输入输出桥梁"------ 本质是一个终端设备(物理终端如串口、虚拟终端如 pts/2(SSH 连接)、tty1(本地控制台))。
1. 控制终端的由来
- 用户通过终端(比如 SSH、本地控制台)登录 Linux 后,系统会创建一个 Shell 进程 (比如
bash); - 这个登录用的终端,就成为该 Shell 进程的控制终端(Shell 进程是这个终端的 "主人");
- 控制终端的信息会存在进程的 PCB(进程控制块)中,这是进程的核心元数据。
2. 控制终端的继承性
Shell 进程通过 fork/exec 启动的所有子进程(比如你执行的 sleep、ps、ping 等命令),会复制 PCB 中的控制终端信息------ 也就是说,这些子进程的控制终端和 Shell 进程是同一个。
3. 输入输出的默认关联
默认情况下(没有重定向时),进程的:
- 标准输入(stdin):指向控制终端(读用户的键盘输入);
- 标准输出(stdout) 、标准错误(stderr):指向控制终端(输出到显示器 / 终端窗口)。
举个通俗例子:你在 SSH 终端(pts/2)执行 ping www.qq.com,这个 ping 进程的控制终端就是 pts/2:
- 你按
Ctrl+C终止ping→ 键盘输入通过控制终端传给ping进程; ping的输出(延迟、丢包率)→ 通过控制终端显示在你的 SSH 窗口里。
一个会话最多有一个终端
一个终端要么出于闲置状态,要么只绑定一个会话
4.前台 / 后台进程组与信号交互
1. 前台进程组(Foreground Process Group)
- 唯一能和控制终端交互的进程组;
- 终端的键盘信号(Ctrl+C、Ctrl+\)会直接发给该组的所有进程;
- 执行命令时不加
&,默认是前台进程组(比如ping www.qq.com)。
2. 后台进程组(Background Process Group)
- 不能直接和终端交互(读 stdin 会被暂停);
- 不受终端中断信号(Ctrl+C)影响;
- 执行命令时加
&,就是后台进程组(比如sleep 100 &)。
作业与作业控制
作业是针对用户 来讲的概念,指用户为完成某项任务而启动的进程集合。一个作业既可以只包含一个进程,也可以包含多个进程,进程之间互相协作完成任务 ------ 通常的表现形式是一个进程管道。
Shell 分前后台来控制的对象,不是单个进程,而是作业 或者进程组。
- 一个前台作业可以由多个进程组成;
- 一个后台作业也可以由多个进程组成。
Shell 可以同时运行一个前台作业 和任意多个后台作业 ,这种对作业的调度与管理方式,称为作业控制。
作业号
作业号是 Shell 为每个作业分配的本地编号(区别于内核的 PID/PGID),仅在当前 Shell 会话中有效,核心规则如下:
1. 作业号的表现形式
执行后台命令时,Shell 会立即返回 [作业号] PID(最后一个进程的pid),比如:
请忽略前两个sleep进程信息,那是另一个进程组的

2. +/- 的核心含义(默认作业规则)
| 符号 | 含义 | 触发场景 |
|---|---|---|
+ |
默认作业(当前优先操作的作业) | 最新创建 / 切换的作业会标记为 + |
- |
候选默认作业 | 当 + 作业终止 / 退出后,- 作业自动变为 + |
| 无符号 | 普通作业 | 非默认、非候选的作业(仅当后台作业≥3 个时出现) |
示例(后台有 3 个作业时):

[3]+:默认作业(fg 无参数时会切回这个);[2]-:候选默认作业(3 号作业终止后,2 号变为+);[1]:普通作业。
作业状态
| 状态名称(中文) | 状态名称(英文) | 触发原因 | 示例 |
|---|---|---|---|
| 运行中 | Running | 作业在后台正常运行(未被暂停 / 终止) | sleep 300 & 对应的作业 |
| 已停止 / 挂起 | Stopped | 按下 Ctrl+Z 发送 SIGTSTP 信号,作业暂停运行 |
前台运行 ./test 后按 Ctrl+Z |
| 完成(成功) | Done/Completed | 作业正常执行完毕,退出码为 0 | cat /etc/hosts & 执行完成 |
| 完成(失败) | Done (Exit 非 0) | 作业执行出错,退出码非 0 | ls /xxx &(/xxx 不存在,退出码 2) |
| 已终止 | Terminated/Killed | 作业被信号终止(如 kill 命令、Ctrl+C) |
后台作业被 kill %1 终止 |
| 僵尸态 | Defunct/Zombie | 作业中的进程已终止,但父进程未回收其资源 | 作业进程异常退出且未被 wait |
状态查看示例
$ jobs -l
[1]- 2265 Running sleep 300 &
[2]+ 2267 Stopped ./test
[3] 2270 Done cat /etc/hosts &
[4] 2272 Terminated ls /xxx &作业控制的核心指令
作业控制的所有指令均是 Shell 内置命令(仅在当前 Shell 生效),核心指令如下:
| 指令 | 功能 | 常用参数 / 用法 | 示例 |
|---|---|---|---|
jobs |
查看当前 Shell 的所有作业 | -l:显示作业号 + PID + 状态 + 命令 -p:仅显示作业的 PID -s:仅显示停止的作业 -r:仅显示运行中的作业 |
jobs -l(查看所有作业详情)jobs -p(仅看 PID) |
fg |
将后台 / 挂起的作业切到前台运行 | fg %作业号(指定作业)fg %%(默认作业,等价于 fg)fg %命令名(模糊匹配,如 fg %sleep) |
fg %1(切回作业 1)fg(切回默认作业) |
bg |
将挂起的作业切到后台继续运行 | 用法同 fg:bg %作业号/bg |
bg %2(让作业 2 在后台恢复运行) |
kill |
终止 / 控制作业(区别于杀进程) | kill %作业号(终止作业)kill -SIGCONT %作业号(恢复挂起的作业)kill -SIGSTOP %作业号(暂停作业) |
kill %1(终止作业 1)kill -9 %2(强制终止作业 2) |
disown |
将作业从 Shell 的作业列表中移除(脱离 Shell 管控) | -h:作业脱离后,终端断连不发 SIGHUP-r:仅移除运行中的作业-a:移除所有作业 |
disown %1(移除作业 1)disown -h %2(作业 2 脱离后,SSH 断连不终止) |
wait |
等待指定作业 / 进程终止,返回退出码 | wait %作业号/wait PID |
wait %1(等待作业 1 完成) |
终端的特殊按键会向前台作业发送信号(后台作业不受影响),核心信号及默认行为如下:
| 按键 | 触发信号 | 信号含义 | 默认行为 | 能否被捕获 / 忽略 |
|---|---|---|---|---|
Ctrl+C |
SIGINT |
中断信号 | 终止前台作业的所有进程 | 可以(比如程序捕获后做清理) |
Ctrl+\ |
SIGQUIT |
退出信号 | 终止前台作业并生成核心转储文件(core dump) | 可以 |
Ctrl+Z |
SIGTSTP |
挂起信号 | 暂停前台作业的所有进程(仅暂停,不终止) | 可以 |
守护进程
守护进程是 Linux 中脱离控制终端、在后台长期运行、独立于用户会话的特殊进程,核心特征:
- 无控制终端(
ps axj中TTY=?); - 是新会话的首进程(
SID=PID)、新进程组的组长(PGID=PID); - 不受终端断连(
SIGHUP信号)影响,7×24 小时运行(如nginx、mysql均为守护进程); - 父进程是系统的
init进程(PID=1),避免成为僵尸进程。
在终端销毁时,与之关联的会话里的进程会收到SIGHUP(挂起信号),普通进程默认会响应这个信号终止运行。
#pragma once
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <signal.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <time.h> // 日志时间戳
#include <errno.h> // 错误码处理
// 常量定义
const char *root = "/";
const char *dev_null = "/dev/null";
// 默认日志文件路径(可根据需求修改)
const char *daemon_log_path = "/var/log/my_daemon.log";
// 日志级别枚举
enum LogLevel {
LOG_INFO, // 普通信息
LOG_WARN, // 警告
LOG_ERROR // 错误
};
int Daemon(bool ischdir, bool isclose) {
// 1. 忽略可能引起程序异常退出的信号
signal(SIGCHLD, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
// 2. fork 退出父进程(避免成为进程组组长)
pid_t pid = fork();
if (pid < 0) {
cout << "LOG_ERROR, fork失败: " << strerror(errno) << endl;
return -1;
} else if (pid > 0) {
cout << "LOG_INFO, 父进程(PID:" << getpid() << ")退出" << endl;
exit(0); // 父进程退出
}
// 子进程继续执行
cout << "LOG_INFO, 子进程(PID:" << getpid() << ")创建成功" << endl;
// 3. 创建新会话(脱离终端核心步骤)
if (setsid() < 0) {
cout << "LOG_ERROR, setsid失败: " << strerror(errno) << endl;
return -1;
}
cout << "LOG_INFO, 新会话创建成功,已脱离控制终端" << endl;
// 4. 切换工作目录到/(可选)
if (ischdir) {
if (chdir(root) < 0) {
cout << "LOG_WARN, 切换工作目录到/失败: " << strerror(errno) << endl;
} else {
cout << "LOG_INFO, 工作目录已切换到/" << endl;
}
}
// 5. 关闭/重定向标准IO
if (isclose) {
close(0);
close(1);
close(2);
cout << "LOG_INFO, 已关闭标准输入/输出/错误" << endl;
} else {
int fd = open(dev_null, O_RDWR);
if (fd > 0) {
dup2(fd, 0);
dup2(fd, 1);
dup2(fd, 2);
close(fd);
cout << "LOG_INFO, 标准输入/输出/错误已重定向到/dev/null" << endl;
} else {
cout << "LOG_ERROR, 打开/dev/null失败: " << strerror(errno) << endl;
return -1;
}
}
cout << "LOG_INFO, 守护进程创建完成" << endl;
return 0;
}为什么忽略 SIGCHLD(子进程结束信号)
1. 先明确:TCP 服务中 SIGCHLD 的触发场景
你的 TCP 服务大概率会创建子进程(或线程)处理客户端请求(比如主进程监听端口,子进程处理单个客户端的读写):
- 客户端断开连接 → 子进程完成任务后终止;
- 内核会向服务主进程(守护进程)发送
SIGCHLD信号,告知 "你的子进程终止了"。
2. 不忽略 SIGCHLD 的致命问题:僵尸进程堆积
Linux 进程的核心规则:
子进程终止后,内核不会立即回收其资源(PID、内存、退出状态),必须等待父进程调用
wait()/waitpid()主动 "认领",否则子进程会变成僵尸进程(Z 状态)。
守护进程是长期运行的,若不处理 SIGCHLD:
- 父进程(守护进程)默认 "收到
SIGCHLD但不做任何操作",既不终止,也不调用wait(); - 子进程持续以僵尸状态存在,占用系统 PID 资源(Linux 可用 PID 数量有限,默认几万);
- 长期运行后,PID 资源耗尽 → 系统无法创建新进程(包括服务的新子进程、其他系统服务、用户命令),最终导致服务完全不可用。
3. 忽略 SIGCHLD 的核心效果:内核自动回收子进程
当你执行 signal(SIGCHLD, SIG_IGN); 后,内核会改变行为:
父进程明确忽略
SIGCHLD时,子进程终止后,内核无需等待父进程调用wait(),直接回收子进程的所有资源(PID、内存等),子进程不会变成僵尸进程。
为什么忽略 SIGPIPE(管道破裂信号)?
1. 先明确:TCP 服务中 SIGPIPE 的触发场景
SIGPIPE 是网络通信中高频非致命异常,触发条件:
服务进程尝试向「已断开的 TCP 套接字」写数据(比如客户端突然断网、关闭浏览器,服务不知情仍调用
send()写数据)。
对 TCP 服务来说,这种场景几乎无法避免:
- 客户端网络波动(比如手机断网);
- 客户端强制关闭连接(比如用户关掉 App);
- 网络超时导致连接被动断开。
2. 不忽略 SIGPIPE 的致命问题:服务直接崩溃
Linux 进程对 SIGPIPE 的默认行为是立即终止进程------ 这对守护进程是 "致命缺陷":
- 一个客户端断连触发
SIGPIPE→ 整个服务进程终止; - 所有已连接的客户端都会断开,服务完全不可用;
- 这种 "因单个客户端的非致命异常导致整体崩溃" 的情况,在生产环境中绝对不允许。
3. 忽略 SIGPIPE 的核心效果:进程不终止,可优雅处理错误
执行 signal(SIGPIPE, SIG_IGN); 后:
- 进程不会因
SIGPIPE终止,继续运行; - 原本触发
SIGPIPE的send()/write()操作会返回-1,且errno被设置为EPIPE; - 你可以在代码中检查这个错误,主动关闭无效的套接字,记录日志,不影响其他客户端。
将自己的服务设置为守护进程
int main(int argc, char *argv[])
{
if (argc != 2)
{
std::cout << "Usage : " << argv[0] << " port" << std::endl;
return 0;
}
uint16_t localport = std::stoi(argv[1]);
Daemon(false, false);
std::unique_ptr<TcpServer> svr(new TcpServer(localport,
HandlerRequest));
svr->Loop();
return 0;
}