写在前面的话
ALS(交替最小二乘法),它是解决矩阵分解的"左右互搏术"。
但在机器学习的世界里,还有另一位更通用的"超级英雄" ------ SGD(随机梯度下降)。
如果说 ALS 是精密的"数学解析解"(每次都算出一个局部最优),那么 SGD 就是一个探险家,在误差的群山中一步步摸索,最终找到宝藏(最小误差)。
今天,我们用最直观的方式,拆解 SGD 是如何攻克推荐系统的。
1. 我们的目标:寻找最低的山谷
我们在做矩阵分解时,目标依然没变:让预测分和真实分的误差越小越好。
想象一下,把"总误差"看作是地图上的海拔高度。
- 如果参数设得烂(预测不准),海拔就在山顶(误差大)。
- 如果参数设得好(预测准),海拔就在山谷(误差小)。
我们的任务,就是要把这两个矩阵(用户表 XXX 和 电影表 YYY)里的几万个参数调整好,让我们从山顶走到最低的山谷里去。
2. 怎么走?(梯度下降 Gradient Descent)
想象你被蒙住双眼放在了山顶,你想下山,该怎么办?
2.1 摸那个"坡"
你看不见全貌,但你的脚能感觉到脚下的坡度。
- 如果左脚高右脚低(坡度向下),你就往右迈一步。
- 如果前脚高后脚低,你就往后退一步。
在数学上,这个"坡度"就叫梯度 (Gradient) 。
梯度的方向,总是指向山顶 (也就是误差变大的方向)。所以为了下山(减小误差),我们要只要沿着梯度的反方向走。
核心口诀 :
新的位置 = 旧的位置 - (步长 ×\times× 坡度)
- 步长 (Learning Rate) :非常关键!
- 步长太大:容易扯着蛋,甚至直接跨过山谷跑到对面上坡去了(震荡)。
- 步长太小:像蜗牛一样挪,猴年马月才能下山(收敛太慢)。
3. 为什么要"随机" (Stochastic)?
普通的梯度下降(GD),是把全班几千万个评分都对一遍,算出总误差,然后才迈出一步。
- 优点:走得稳,方向准。
- 缺点 :太慢了! 算一次要半天,走一步累死人。这对于海量数据的淘宝、抖音来说是不可接受的。
于是,SGD (随机梯度下降) 诞生了。
3.1 醉汉的智慧
SGD 的策略是:我不管全班,我随便抓一个学生(随机采样一个评分),看我给他预测得准不准。
- 如果不准,我立马调整参数!
- 然后再抓下一个......
虽然单个样本可能会把方向带偏(比如为了迎合一个特立独行的用户,反而离大众口味远了),走起路来跌跌撞撞 ,像个醉汉。但因为 update 次数极其频繁,在大方向上,它依然会迅速滚向山谷。
4. SGD 在矩阵分解中的实操步骤
回到推荐系统,SGD 是怎么更新参数的?
步骤详解
- 随机抽样 :
- 系统随机抽到一条数据:张三给《战狼》打了 5 分。
- 当前预测 :
- 模型看一眼自己当前的参数(比如说此时张三的动作分是 0.1,战狼动作成分是 0.8)。
- 预测出:0.1×0.8=0.080.1 \times 0.8 = 0.080.1×0.8=0.08 分。
- 计算误差 :
- 误差 e=5−0.08=4.92e = 5 - 0.08 = 4.92e=5−0.08=4.92。误差巨大!说明主要矛盾在于张三的动作分太低了(或者战狼的动作分太低,或者两者都低)。
- 立即修正 (Update) :
- 根据公式,把"张三的动作分"调大 一点,把"战狼的动作分"也调大一点。
- 注意 :这时候李四、王五的向量,以及《泰坦尼克》的向量完全不动。只改张三和战狼。
- 循环 :
- 下一秒抽到了李四给《泰坦尼克》打分... 继续改。
数学公式(人话版)
新值=旧值+学习率×(误差×对方的值−正则化约束) \text{新值} = \text{旧值} + \text{学习率} \times (\text{误差} \times \text{对方的值} - \text{正则化约束}) 新值=旧值+学习率×(误差×对方的值−正则化约束)
- 如果你误差大,我就大改。
- 对方的值越大(说明对方特征显著),这一单误差你的责任就越大,你就得改越多。
5. ALS vs SGD:谁是王者?
| 特性 | ALS (交替最小二乘) | SGD (随机梯度下降) |
|---|---|---|
| 计算方式 | 精确解析解 (走楼梯) | 迭代逼近 (走斜坡) |
| 并行能力 | 完美 (Spark 标配) | 较难 (互相依赖) |
| 处理隐式反馈 | 强项 (没打分也能算) | 较麻烦 |
| 实现难度 | 较复杂 | 很简单 (十几行代码) |
| 适用场景 | 海量数据分布式计算 | 增量更新、单机流式计算 |
6. 图解 SGD
下图展示了从山顶跌跌撞撞滚向红心(最低点)的过程。
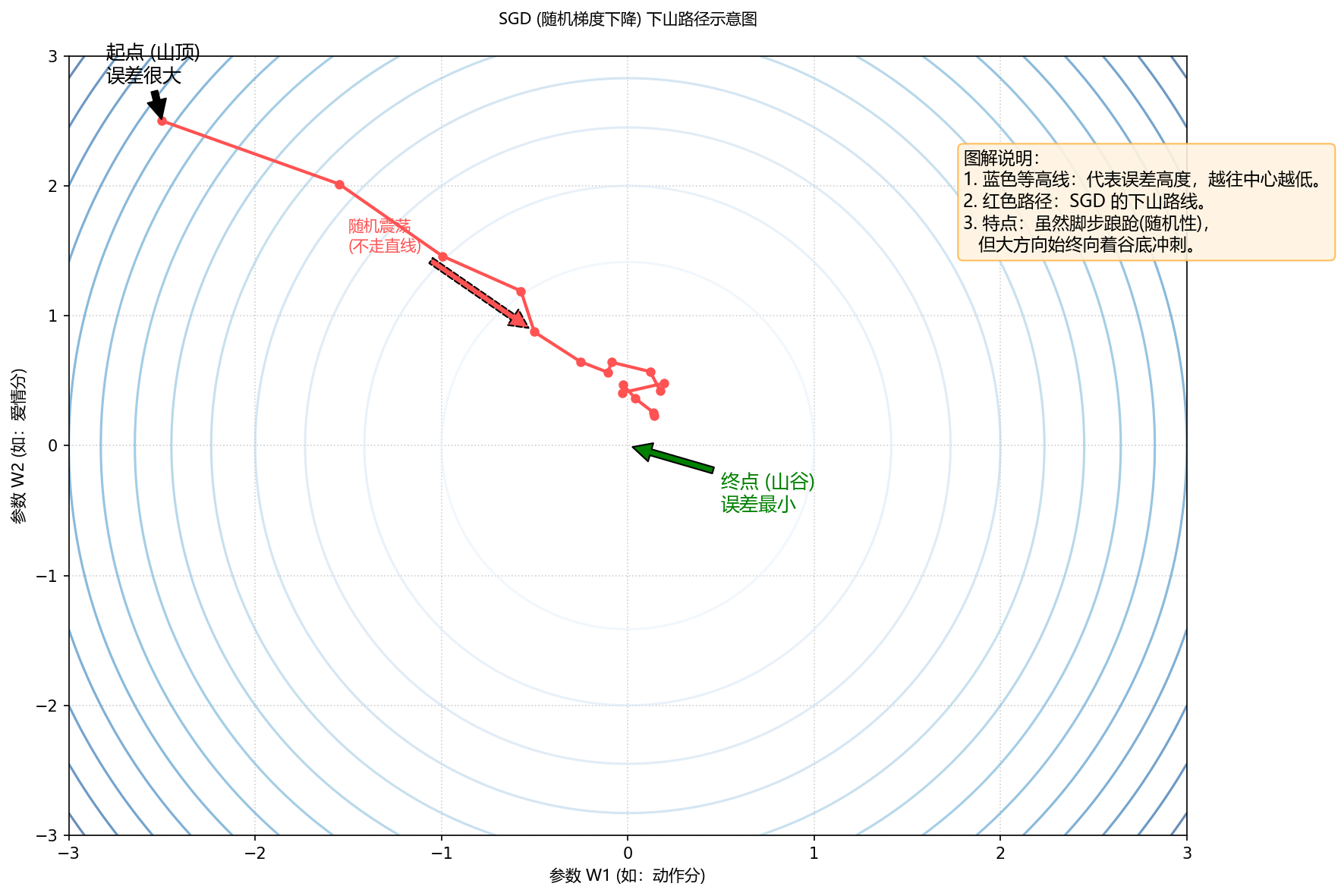
希望这个比喻能帮你理解 SGD 的精髓:天下武功,唯快不破!