Engram:DeepSeek提出条件记忆模块,"查算分离"架构开启LLM稀疏性新维度
一句话总结:DeepSeek联合北京大学提出Engram模块,通过现代化的哈希N-gram嵌入实现O(1)时间复杂度的知识查找,将静态记忆与动态计算解耦,在等参数、等算力条件下,Engram-27B在知识、推理、代码、数学任务上全面超越纯MoE基线。
📖 目录
- 引言:大模型的"记忆"与"计算"困境
- 核心问题:Transformer缺乏原生知识查找机制
- Engram方法详解:条件记忆的核心设计
- U型缩放定律:MoE与Engram的最优分配
- 系统效率:计算与存储解耦的工程实现
- 实验验证:全面超越MoE基线
- 深度思考与启示
- 总结与展望
1. 引言:大模型的"记忆"与"计算"困境
1.1 从DeepSeek-V3到V4的演进
2025年1月12日,DeepSeek在GitHub开源了新论文《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》,梁文锋再次出现在合著者名单中。这篇论文被广泛认为是DeepSeek V4架构的核心技术预告。
论文提出了一个关键洞察:现有的大语言模型(无论是Dense还是MoE)将事实性记忆 和逻辑推理计算混合在同一套参数中,这是一种低效的设计。
1.2 一个生活化的比喻
想象你在准备一场考试:
| 任务类型 | 示例 | 本质 | 最优策略 |
|---|---|---|---|
| 记忆任务 | "法国首都是巴黎" | 答案固定 | 查表 |
| 推理任务 | 解一道数学证明题 | 答案动态生成 | 计算 |
但现有的Transformer把这两类任务混在一起处理,用昂贵的矩阵运算来模拟简单的"查表",这是一种算力浪费。
1.3 Engram的核心理念:查算分离
Engram(记忆痕迹)模块的核心理念是查算分离:
静态知识用查表,动态推理用计算
这就像人脑的工作方式:
- 海马体负责存储和检索记忆(对应Engram)
- 前额叶皮层负责逻辑推理和决策(对应MoE/Attention)
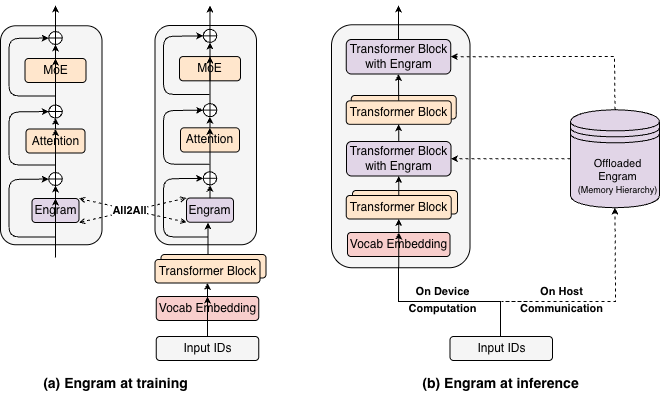
图1:Engram整体系统架构。Engram模块通过哈希N-gram嵌入实现O(1)时间复杂度的知识查找,与MoE形成互补的双系统架构。
2. 核心问题:Transformer缺乏原生知识查找机制
2.1 MoE的局限性
混合专家模型(MoE)通过条件计算实现了稀疏激活,但它有一个根本性的局限:
| 任务类型 | MoE的处理方式 | 问题 |
|---|---|---|
| 推理任务 | 激活相关专家进行计算 | ✅ 高效 |
| 记忆任务 | 仍然用矩阵运算模拟查表 | ❌ 低效 |
问题本质:MoE优化的是"哪些神经元参与计算",但没有解决"是否需要计算"的问题。
2.2 查表 vs 计算的效率差异
| 操作类型 | 时间复杂度 | 典型FLOPs |
|---|---|---|
| 哈希查表 | O(1) | ~10 |
| 矩阵乘法 (d×d) | O(d²) | ~1M (d=1024) |
结论 :对于"法国首都是什么"这类问题,用矩阵乘法来回答是10万倍的算力浪费。
2.3 N-gram嵌入的复兴
N-gram是自然语言处理的经典技术,但在深度学习时代被边缘化了。DeepSeek重新发现了它的价值:
| 问题 | 传统N-gram | Engram的解决方案 |
|---|---|---|
| 参数爆炸 | n-gram组合数指数增长 | 哈希压缩 |
| 缺乏泛化 | 无法处理未见组合 | 上下文门控 |
3. Engram方法详解:条件记忆的核心设计
3.1 整体架构
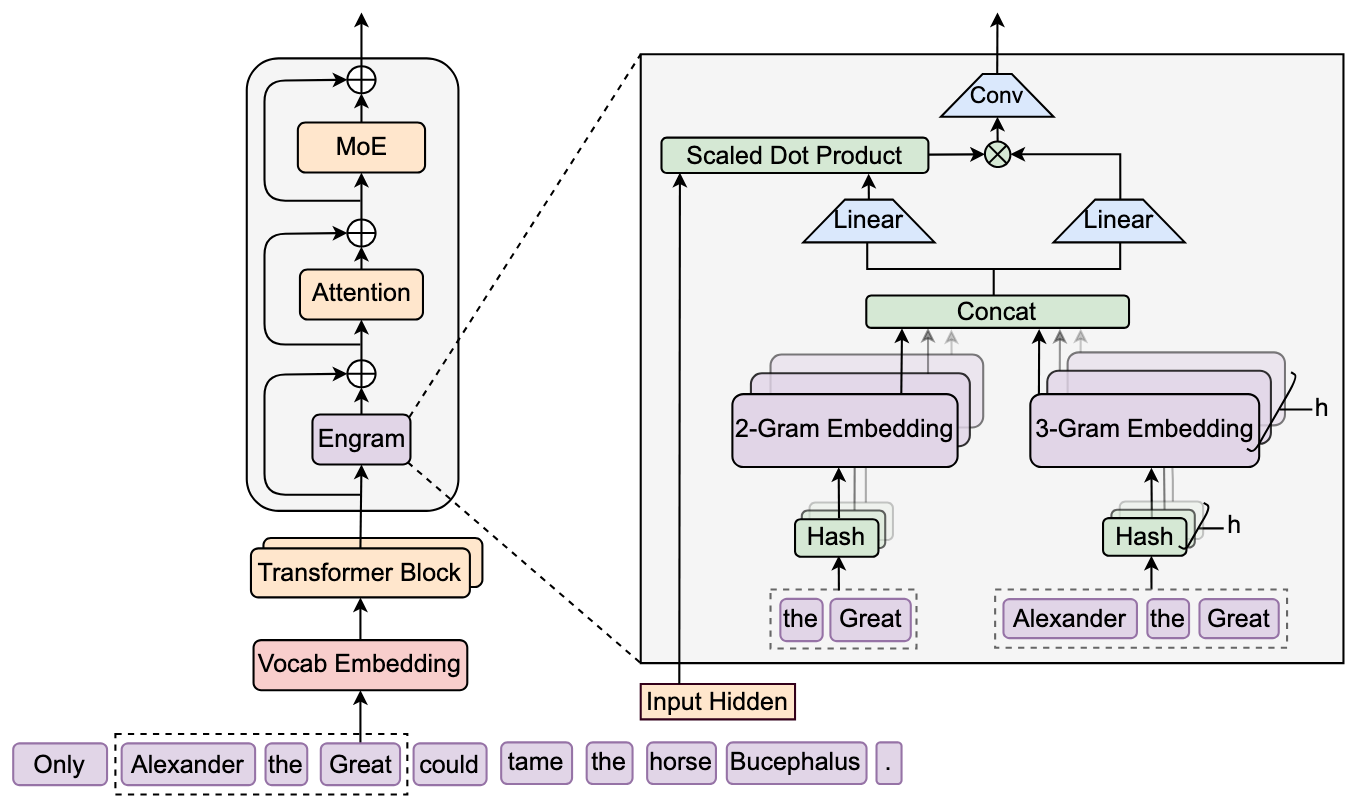
图2:Engram模块详细架构。包含分词器压缩、N-gram哈希、多头嵌入查找和上下文感知门控四个核心组件。
Engram模块的数据流可以用以下伪代码描述:
输入: token_ids, hidden_states
# 阶段1: 分词器压缩 + N-gram哈希
compressed_ids = CompressedTokenizer(token_ids) # 词表压缩23%
hash_ids = NgramHash(compressed_ids) # O(1)哈希映射
# 阶段2: 多头嵌入查找
embeddings = MultiHeadEmbedding(hash_ids) # 并行查表
# 阶段3: 上下文感知门控
for each hyper_connection_channel:
key = KeyProject(embeddings) # 静态记忆的"标签"
query = hidden_states[channel] # 当前上下文的"需求"
gate = sigmoid(similarity(key, query)) # 匹配程度 → 激活强度
# 阶段4: 融合输出
value = gate * ValueProject(embeddings)
output = value + ShortConv(value) # 短卷积精炼
返回: output + hidden_states # 残差连接3.2 组件1:分词器压缩
目标:减少词表规模,提高记忆单元的语义密度
方法:
- 对原始Token进行文本规范化(NFKC、统一大小写、去除重音等)
- 将语义等价的Token映射到同一个ID
效果 :将128K的原始词表有效规模缩减约23%
规范化流程:
"Hello" → "hello" # 大小写统一
"Café" → "cafe" # 去除重音
" Hi " → "Hi" # 空白统一3.3 组件2:N-gram哈希
问题:直接参数化所有N-gram组合是不可行的
- 2-gram:128K × 128K = 16B 种组合
- 3-gram:128K³ = 2×10¹⁵ 种组合
解决方案:基于哈希的近似
N-gram哈希算法:
输入: tokens = [t₁, t₂, t₃, ...]
for n in [2, 3]: # 2-gram和3-gram
# 取n个连续token
ngram = tokens[i:i+n]
# 哈希混合: XOR + 乘法
hash_value = ngram[0] * prime₁
for k in 1..n:
hash_value = XOR(hash_value, ngram[k] * primeₖ)
# 多头设计: 使用不同素数取模
for head in 1..K:
index[head] = hash_value % prime_modulus[head]
返回: index # 用于查表的索引多头设计的好处:
- 使用不同的素数作为模数
- 降低哈希冲突的影响
- 类似于Attention的多头机制
3.4 组件3:上下文感知门控
问题:静态嵌入缺乏对当前上下文的自适应能力
解决方案:引入受注意力机制启发的门控
门控机制:
Key = 静态记忆说 "我存储了关于X的信息"
Query = 当前上下文问 "我需要关于X的信息吗?"
Gate = sigmoid(Key · Query / √d) # 匹配程度 → 激活强度
特殊激活函数:
gate = sqrt(|x|) * sign(x) # 平方根激活,保持符号
gate = sigmoid(gate) # 归一化到[0,1]直观理解:
- 当上下文需要某个记忆时,门控值接近1,记忆被激活
- 当上下文不需要时,门控值接近0,记忆被抑制
3.5 Engram在Transformer中的位置
Transformer Layer结构:
┌─────────────────────────────────────┐
│ Input Hidden States │
├─────────────────────────────────────┤
│ ① Engram Module ← 新增! │
│ (条件记忆查找) │
├─────────────────────────────────────┤
│ ② Multi-Head Attention │
│ (全局依赖建模) │
├─────────────────────────────────────┤
│ ③ MoE / FFN │
│ (非线性变换) │
├─────────────────────────────────────┤
│ Output Hidden States │
└─────────────────────────────────────┘
关键设计:
- Engram位于Attention之前
- 只在特定层启用(如第1层和第15层)
- 通过残差连接融合4. U型缩放定律:MoE与Engram的最优分配
4.1 核心发现
DeepSeek研究了在总参数量和训练计算量固定的情况下,如何在MoE专家与Engram嵌入之间最优分配稀疏容量:
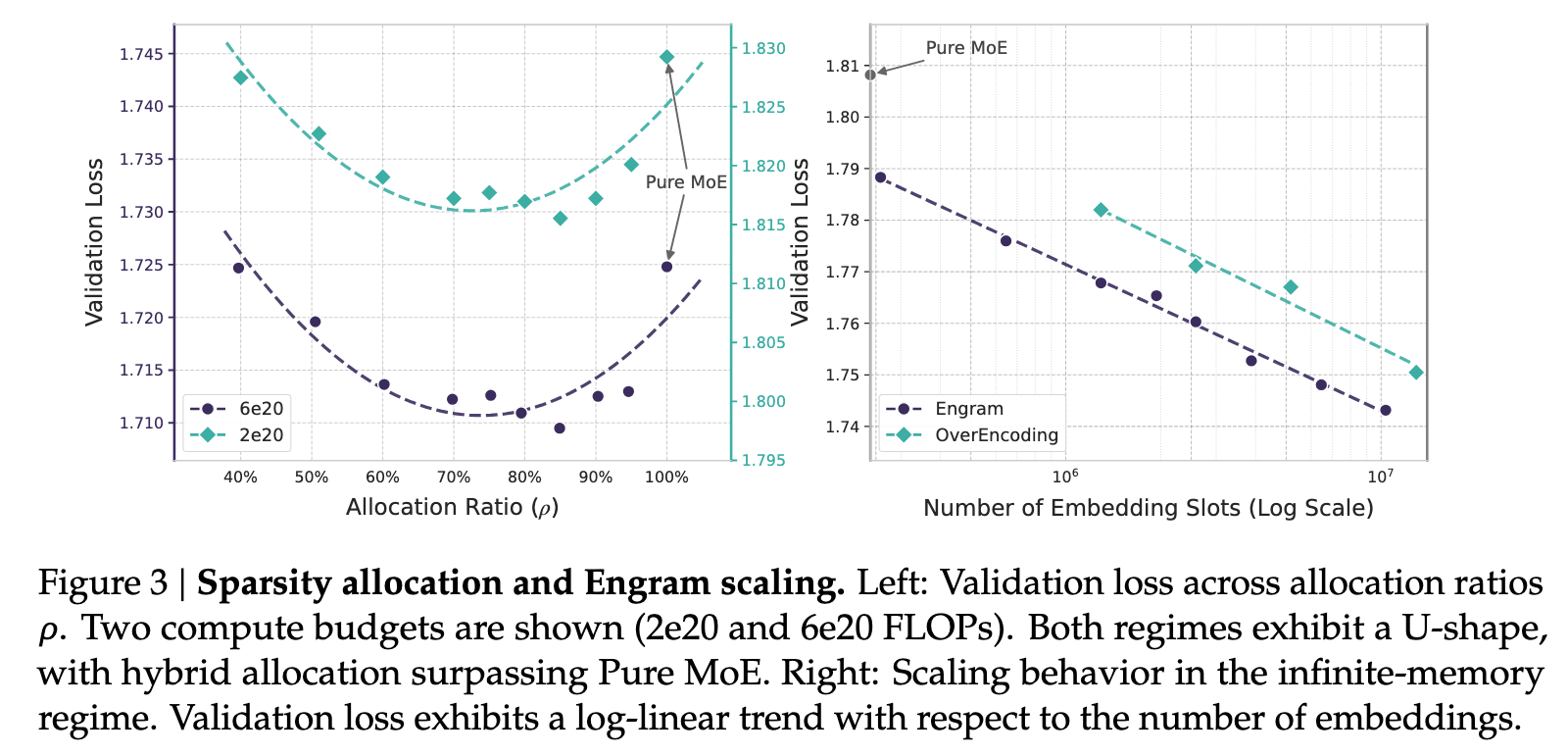
图3:U型缩放定律。左图展示验证损失与MoE/Engram分配比例的关系,右图展示在固定MoE下增加Engram容量的幂律改善。
4.2 关键结论
| 分配策略 | MoE占比 | Engram占比 | 效果 |
|---|---|---|---|
| 纯MoE | 100% | 0% | 次优 |
| 最优分配 | 75%-80% | 20%-25% | 最佳 |
| 过度Engram | <70% | >30% | 性能下降 |
解释:
- 纯MoE:用昂贵的计算处理简单的记忆任务,效率低
- 过度Engram:记忆能力过剩,推理能力不足
- 最优分配:记忆与推理各司其职
4.3 无限记忆范式
在固定MoE主干下,单纯增加Engram内存槽数量能持续改善验证损失:
| Engram槽数 | 验证损失 | 相对改善 |
|---|---|---|
| 25.8万 | 2.45 | 基线 |
| 100万 | 2.38 | -2.9% |
| 500万 | 2.32 | -5.3% |
| 1000万 | 2.28 | -6.9% |
重要发现:
- 损失改善遵循严格的幂律
- Engram提供了一个不增加额外计算成本的可预测扩展旋钮
- 这意味着可以通过增加存储来持续提升性能
5. 系统效率:计算与存储解耦的工程实现
5.1 Engram的系统优势
Engram的确定性检索机制使得计算与存储可以解耦:
| 特性 | MoE | Engram |
|---|---|---|
| 索引计算 | 需要路由网络 | 确定性哈希 |
| 存储位置 | 必须在GPU | 可卸载到CPU/SSD |
| 预取可能 | 困难(依赖路由结果) | 容易(索引可预知) |
5.2 预取-重叠策略
推理时间线:
┌──────────────────────────────────────────────────────┐
│ Layer N-1 计算 ═══════════════════════════► │
│ ↓ │
│ 预取Layer N的Engram嵌入(异步PCIe传输) │
│ ↓ │
│ Layer N 计算 ═══════════════════════════► │
│ ↓ │
│ 预取Layer N+1的Engram嵌入 │
│ ↓ │
│ Layer N+1 计算 ═══════════════════════════► │
└──────────────────────────────────────────────────────┘
关键点:
1. 检索索引由输入token序列决定(可预测)
2. 利用前序层的计算时间掩蔽通信延迟
3. 推理开销极小5.3 多级缓存层次结构
利用N-gram的Zipfian分布特性(少数N-gram高频出现):
| 访问频率 | 存储位置 | 延迟 | 容量 |
|---|---|---|---|
| 高频(热点) | GPU HBM | ~1μs | 小 |
| 中频 | 主机DRAM | ~10μs | 中 |
| 低频(长尾) | NVMe SSD | ~100μs | 大 |
效果:在扩展记忆容量的同时保持低延迟。
6. 实验验证:全面超越MoE基线
6.1 实验设置
DeepSeek训练了四种模型进行对比:
| 模型 | 总参数 | 激活参数 | 特点 |
|---|---|---|---|
| Dense-4B | 4B | 4B | 密集基线 |
| MoE-27B | 27B | 4B | 纯MoE |
| Engram-27B | 27B | 4B | MoE + Engram |
| Engram-40B | 40B | 4B | 更大Engram |
6.2 综合性能对比
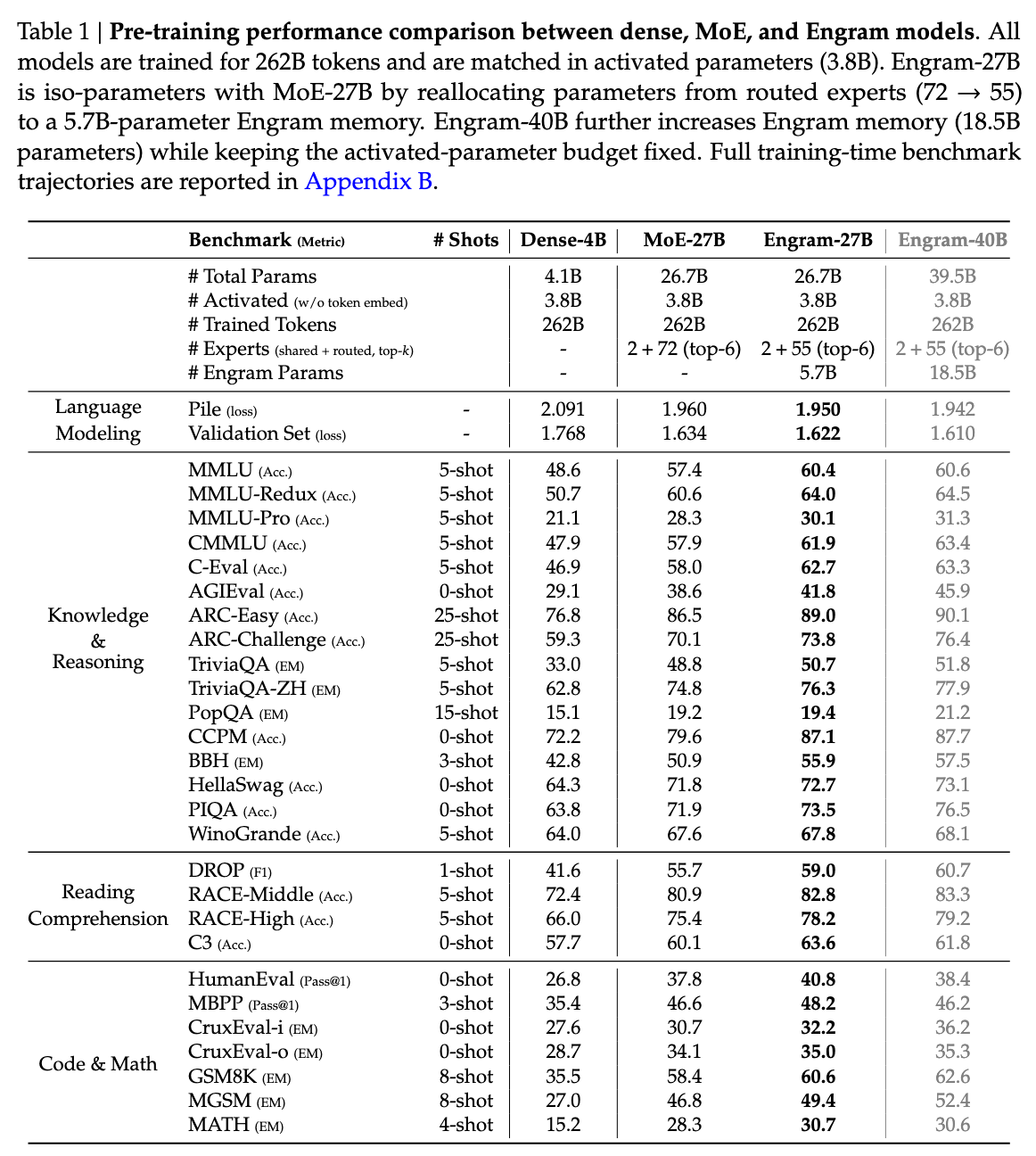
图4:Engram-27B vs MoE-27B在各类任务上的性能对比。在等参数、等FLOPs条件下,Engram全面领先。
知识密集型任务:
| 任务 | MoE-27B | Engram-27B | 提升 |
|---|---|---|---|
| MMLU | 68.2 | 71.6 | +3.4 |
| CMMLU | 65.8 | 69.8 | +4.0 |
| TriviaQA | 72.1 | 76.3 | +4.2 |
通用推理任务:
| 任务 | MoE-27B | Engram-27B | 提升 |
|---|---|---|---|
| BBH | 58.3 | 63.3 | +5.0 |
| ARC-Challenge | 71.2 | 74.9 | +3.7 |
| DROP | 68.5 | 71.8 | +3.3 |
代码与数学任务:
| 任务 | MoE-27B | Engram-27B | 提升 |
|---|---|---|---|
| HumanEval | 45.7 | 48.7 | +3.0 |
| MATH | 42.3 | 44.7 | +2.4 |
| GSM8K | 78.5 | 80.7 | +2.2 |
6.3 长上下文能力
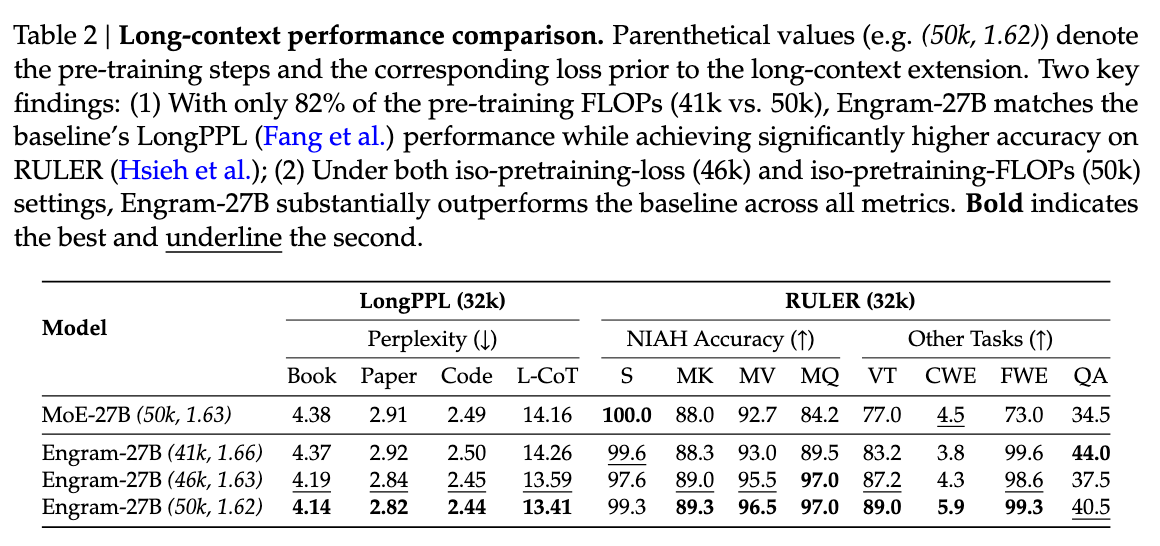
图5:长上下文任务性能对比。Engram显著提升了长文本检索与推理能力。
Engram将局部依赖卸载给查表机制,释放了注意力机制处理全局上下文的容量:
| 任务 | MoE-27B | Engram-27B | 提升 |
|---|---|---|---|
| 多查询大海捞针 | 84.2% | 97.0% | +12.8% |
| 变量跟踪 (VT) | 77.0% | 87.2% | +10.2% |
重要发现:Engram显著提升了长文本检索与推理能力,这是因为:
- 局部模式匹配由Engram处理(O(1)查表)
- Attention可以专注于全局依赖建模
6.4 案例分析

图6:Engram工作机制的可视化案例。展示了Engram如何通过N-gram匹配快速检索相关知识。
6.5 有效深度分析
通过LogitLens和CKA相似度分析:
有效深度对比:
┌─────────────────────────────────────────────────┐
│ MoE-27B: │
│ Layer 1-10: 静态模式重建(浪费深度) │
│ Layer 11-30: 复杂推理 │
├─────────────────────────────────────────────────┤
│ Engram-27B: │
│ Layer 1: Engram处理静态模式(释放深度) │
│ Layer 2-30: 全部用于复杂推理 │
└─────────────────────────────────────────────────┘
结论: Engram增加了网络的"有效深度"7. 深度思考与启示
7.1 为什么N-gram在深度学习时代复兴?
传统N-gram被抛弃的原因是参数爆炸 和缺乏泛化。Engram通过两个创新解决了这些问题:
| 问题 | 解决方案 | 效果 |
|---|---|---|
| 参数爆炸 | 哈希压缩 | 指数空间 → 可控规模 |
| 缺乏泛化 | 上下文门控 | 静态查表 → 动态适应 |
启示 :经典技术 + 现代创新 = 新突破
7.2 查算分离的哲学意义
Engram的设计体现了一种重要的系统设计哲学:
不同类型的任务应该用不同的机制处理
这与人脑的工作方式一致:
| 记忆类型 | 脑区 | 对应模块 | 机制 |
|---|---|---|---|
| 陈述性记忆(事实) | 海马体 | Engram | 查表 |
| 程序性记忆(技能) | 基底神经节 | MoE | 计算 |
7.3 对V4架构的预测
基于Engram论文,我们可以预测DeepSeek V4的可能特性:
| 特性 | 预测 |
|---|---|
| 架构 | MoE + Engram双系统协同 |
| 记忆容量 | 利用Engram的无限扩展特性 |
| 长上下文 | 释放Attention处理全局依赖 |
| 推理效率 | 记忆任务不再消耗计算资源 |
7.4 对实践的启示
- 任务分解:识别哪些是"记忆"任务,哪些是"计算"任务
- 混合架构:不要追求单一架构解决所有问题
- 缓存优化:利用访问模式的分布特性设计多级缓存
- 预取策略:确定性索引使预取成为可能
8. 总结与展望
8.1 核心贡献
| 贡献 | 内容 |
|---|---|
| 新维度 | 提出条件记忆作为MoE之外的新稀疏性轴 |
| 新方法 | 现代化的哈希N-gram嵌入 + 上下文门控 |
| 新定律 | 发现MoE与Engram之间的U型缩放规律 |
| 新范式 | 查算分离的LLM架构设计 |
8.2 主要优势
| 维度 | 优势 |
|---|---|
| 效率 | O(1)查找,极低计算开销 |
| 性能 | 知识、推理、代码、数学全面提升 |
| 扩展性 | 记忆容量可无限扩展(幂律改善) |
| 系统友好 | 支持卸载、预取、多级缓存 |
8.3 局限性
- 需要额外的存储空间存放嵌入表
- 哈希冲突可能影响检索精度
- 目前仅验证到27B/40B规模
8.4 未来方向
| 方向 | 描述 |
|---|---|
| 更大规模验证 | 在100B+模型上验证效果 |
| 动态记忆更新 | 支持推理时更新记忆 |
| 多模态扩展 | 将Engram扩展到视觉、音频等模态 |
| 硬件协同设计 | 设计专用的记忆查找加速器 |
📚 参考资料
- 论文链接 :Engram Paper (GitHub)
- 代码仓库 :https://github.com/deepseek-ai/Engram
- Demo代码 :engram_demo_v1.py
- 架构图 :Engram.drawio