Redis作为高性能内存数据库的核心竞争力,不仅在于其丰富的数据结构类型,更在于其底层精妙的设计与实现。本文将深入剖析String、List、Hash、Set、Sorted Set五大核心数据结构的实现原理,结合Redis 7.0源码解析其设计哲学。
String(动态字符串)
底层结构:SDS(Simple Dynamic String)
java
struct sdshdr {
int len; // 已用长度
int alloc; // 总分配长度
unsigned char flags; // 类型标识
char buf[]; // 字节数组
};- 空间预分配:当SDS需要扩容时,会额外分配未使用空间(<1MB时翻倍,≥1MB时每次+1MB)
- 惰性释放:缩短字符串时不立即回收内存,通过len字段标记可用空间
- 二进制安全:通过len字段而非空字符判断结束,可存储任意二进制数据
场景特征:
- 计数器(INCR/DECR原子操作)
- 缓存对象(JSON序列化存储)
- 分布式锁(SETNX命令)
List(链表)
底层结构:Quicklist(3.2版本后)
java
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; // 元素总数
unsigned long len; // quicklistNode数量
int fill : QL_FILL_BITS; // 单个ziplist最大容量
unsigned int compress : QL_COMP_BITS; // LZF压缩深度
} quicklist;复合结构:
- 宏观:双向链表(支持前后遍历)
- 微观:ziplist(内存紧凑结构)
- 压缩机制:通过LZF算法压缩中间节点(配置list-compress-depth)
性能优化:
- 元素≤48字节且列表长度≤512时使用ziplist(通过list-max-ziplist-size配置)
- 通过fill参数控制单个ziplist大小(默认8KB)
Hash(字典)
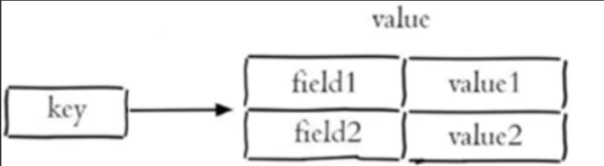
底层编码:
- ziplist(默认):
- 存储格式:field1, value1, field2, value2,...
- 适用条件:field数量≤512且value大小≤64字节(hash-max-ziplist-entries/values)
- hashtable:
- 使用dictht结构实现
- 渐进式rehash:维护两个哈希表,逐步迁移数据
源码结构:
java
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; // 双哈希表
long rehashidx; // rehash进度
int iterators; // 迭代器数量
} dict;最佳实践:
- 对象属性存储(用户信息)
- 配置参数聚合存储
- 使用HSCAN避免大Hash阻塞
Set(集合)
底层实现:
- intset:
- 有序整数数组
- 条件:元素均为整数且数量≤512(set-max-intset-entries)
- hashtable:
- 字典实现(value=null)
特殊操作优化:
- SINTERSTORE使用位图算法优化交集计算
- SPOP使用随机探针+删除策略
- SISMEMBER时间复杂度O(1)
应用场景:
- 标签系统
- 唯一性校验
- 好友关系(并集/差集运算)
Sorted Set(有序集合)
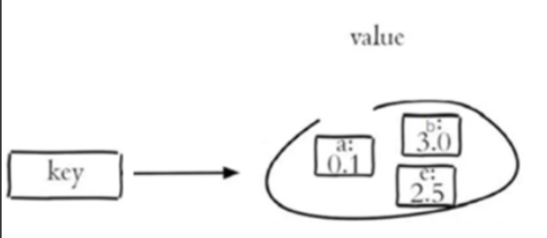
底层实现:
- ziplist(默认):
- 存储格式:member1, score1, member2, score2,...
- 适用条件:元素数量≤128且member长度≤64(zset-max-ziplist-entries/value)
- 跳表+字典:
- skiplist:实现范围查询(ZRANGE)
- dict:实现O(1)复杂度元素查找
跳表结构:
java
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;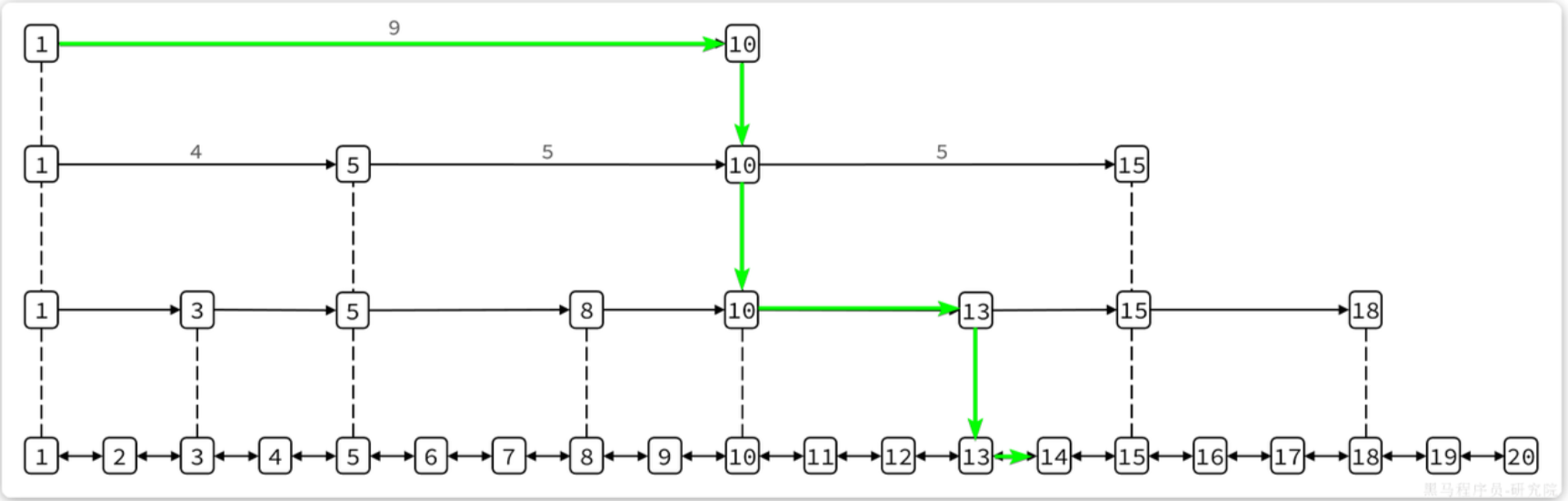
设计亮点:
- 随机化层高(1/4概率升级)
- 范围查询性能媲美平衡树
- 支持相同score的字典序排序
数据结构选择策略
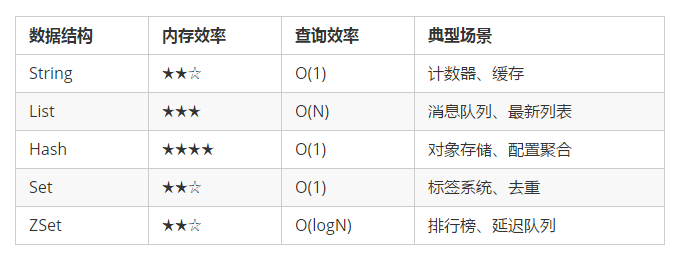
调优建议:
- 监控内存碎片率(mem_fragmentation_ratio)
- 合理设置ziplist转换阈值
- 对大Key进行分片处理(如user:1000:info拆分为多字段)
- 使用SCAN系列命令代替KEYS