背景说明
对于Spark来说提供了两种运行模式,一种是行执行,一种是列执行,我们大部分情况下都是行执行,只有在少部分情况下,比如说读取Parquet这种列存储的文件的时候,才会用到列执行;对于列式执行和行式执行的交接点这里就会提供行到列或者列到行的转换。也就是 ApplyColumnarRulesAndInsertTransitions 规则所做的事情。而这是Spark在框架上能够支持列式向量化执行的原因,这里来对Spark中的 ApplyColumnarRulesAndInsertTransitions 规则进行说明,以及其中的涉及到的链路转换。
本文基于Spark 4.0.0
分析
总体上 ApplyColumnarRulesAndInsertTransitions 规则是按照从上到下,依次遍历物理计划,在行列执行的交汇处,插入RowToColumnarTransition 和
ColumnarToRowTransition 以便于既能按行执行,也能按列执行。
spark中行执行是调用 doExecute 方法:
protected def doExecute(): RDD[InternalRow] ,该方法返回的是 InternalRow 行存数据。
列执行是调用 doExecuteColumnar 方法:
protected def doExecuteColumnar(): RDD[ColumnarBatch],该方法返回的是 ColumnarBatch 列批数据,方便向量化执行。
直接上代码:
case class ApplyColumnarRulesAndInsertTransitions(
columnarRules: Seq[ColumnarRule],
outputsColumnar: Boolean)
extends Rule[SparkPlan] {
/**
* Inserts an transition to columnar formatted data.
*/
private def insertRowToColumnar(plan: SparkPlan): SparkPlan = {
if (!plan.supportsColumnar) {
// The tree feels kind of backwards
// Columnar Processing will start here, so transition from row to columnar
RowToColumnarExec(insertTransitions(plan, outputsColumnar = false))
} else if (!plan.isInstanceOf[RowToColumnarTransition]) {
plan.withNewChildren(plan.children.map(insertRowToColumnar))
} else {
plan
}
}
/**
* Inserts RowToColumnarExecs and ColumnarToRowExecs where needed.
*/
private def insertTransitions(plan: SparkPlan, outputsColumnar: Boolean): SparkPlan = {
if (outputsColumnar) {
insertRowToColumnar(plan)
} else if (plan.supportsColumnar && !plan.supportsRowBased) {
// `outputsColumnar` is false but the plan only outputs columnar format, so add a
// to-row transition here.
ColumnarToRowExec(insertRowToColumnar(plan))
} else if (plan.isInstanceOf[ColumnarToRowTransition]) {
plan
} else {
val outputsColumnar = plan match {
// With planned write, the write command invokes child plan's `executeWrite` which is
// neither columnar nor row-based.
case write: DataWritingCommandExec
if write.cmd.isInstanceOf[V1WriteCommand] && conf.plannedWriteEnabled =>
write.child.supportsColumnar
case _ =>
false
}
plan.withNewChildren(plan.children.map(insertTransitions(_, outputsColumnar)))
}
}
def apply(plan: SparkPlan): SparkPlan = {
var preInsertPlan: SparkPlan = plan
columnarRules.foreach(r => preInsertPlan = r.preColumnarTransitions(preInsertPlan))
var postInsertPlan = insertTransitions(preInsertPlan, outputsColumnar)
columnarRules.reverse.foreach(r => postInsertPlan = r.postColumnarTransitions(postInsertPlan))
postInsertPlan
}-
insertTransitions 是插入行列执行转换的入口。
-
先说说 insertRowToColumnar 方法的作用
该方法的作用 就是插入 行转列的 转换节点,也就是能够提供一个 doExecuteColumnar 方法生成 ColumnarBatch 列批数据 ,该节点会递归调用所有的子节点
- 如果该计划不支持列执行,就加入一个 RowToColumnarExec 结点,此时已经完成了转换结点的插入,但是后续的结点还没有进行 转换节点的 插入,所以继续在该结点上调用
insertTransitions方法进行转换,以便递归调用该计划的子结点进行 结点转换 - 如果该计划不是 转换节点,但是是支持 列执行的, 说明需要对该计划的子节点插入 行列转换节点,所以对该子节点调用 insertRowToColumnar
- 如果以上条件都不满足,也就是支持列存,而且也是 转换节点,则此次方法就结束了
- 如果该计划不支持列执行,就加入一个 RowToColumnarExec 结点,此时已经完成了转换结点的插入,但是后续的结点还没有进行 转换节点的 插入,所以继续在该结点上调用
-
再说说 insertTransitions 方法
该方法会有 outputsColumnar 参数,来表明该
insertTransitions是够要输出列存数据还是行存数据 ,在该Rule中是False,也就是说要输出的是行存数据。- 如果是要输出列式数据,则直接调用 insertRowToColumnar ,返回能够提供一个 doExecuteColumnar 方法生成 ColumnarBatch 列批数据 的计划.
- 如果是要输出行式数据,且该计划支持列输出,且不支持行输出,则 插入
ColumnarToRowExec该节点 会调用子结点的executeColumnar方法,所以同时要插入insertRowToColumnar方法,以便该节点支持executeColumnar - 如果是要输出行式数据,且已经是 列行转换节点,则直接返回该计划
- 否则,对该计划的子结点调用
insertTransitions方法,以便对每个结点都会进行规则转换
举个例子:
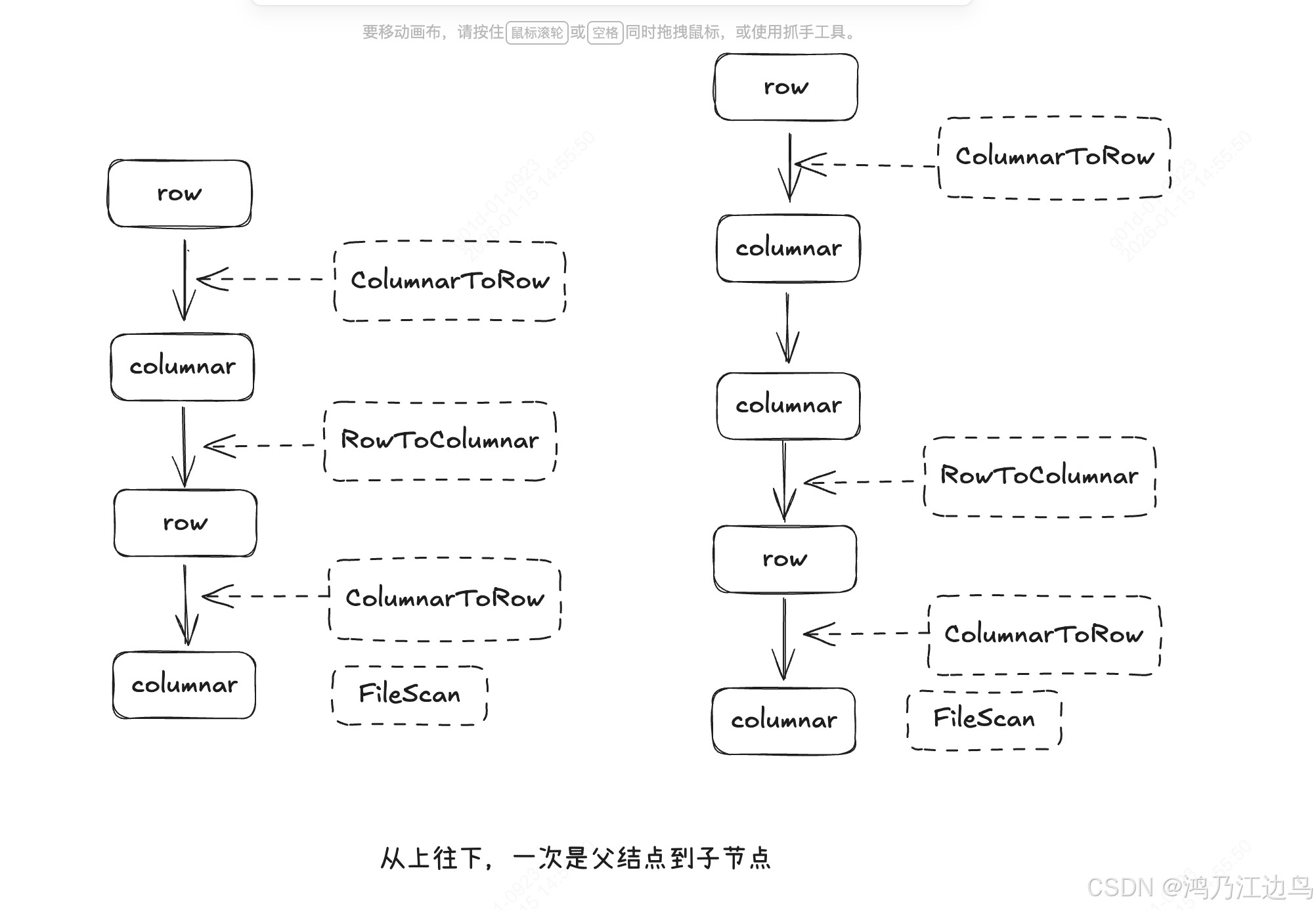
其中实体框是规则转换前的,虚线是经过规则转换后,加上去的物理转换结点计划,途中对应了两个不同的物理计划