K8s 集群内存压力检测和智能 Pod 驱逐工具
基于 kubectl 命令的 Kubernetes 集群内存监控和智能 Pod 驱逐脚本。

功能特性
核心功能
- 节点内存监控 : 通过
kubectl top nodes实时监控所有节点的 CPU 和内存使用情况 - 智能告警: 当节点内存超过阈值时,通过钉钉机器人发送告警通知
- 智能驱逐: 当内存压力达到驱逐阈值时,自动计算并执行 Pod 驱逐策略
- 保护机制: 可配置受保护的命名空间、Pod 前缀、标签等,防止关键服务被驱逐
驱逐策略
该工具采用多维度智能决策:
-
QoS 优先级: BestEffort → Burstable → Guaranteed
- Kubernetes 为 Pod 定义了三种 QoS 类别:Guaranteed(最高优先级)、Burstable 和 BestEffort(最低优先级)。工具在驱逐时会优先选择 BestEffort 类别的 Pod,因为这类 Pod 通常没有设置资源请求或限制,驱逐它们对服务质量的影响最小。Guaranteed 类别的 Pod 设置了资源请求和限制且两者相等,具有最高的资源保障,一般不会被驱逐。
-
内存占用: 优先驱逐内存占用高的 Pod(可配置)
- 该工具默认配置为优先驱逐内存占用较高的 Pod,因为这样可以用最少的驱逐操作释放最多的内存资源。这一策略可以通过配置参数 prefer_high_memory 来控制开关。如果需要驱逐多个小内存 Pod 才能达到预期效果,可以适当调高目标内存使用率或增加单次驱逐的最大数量。
-
调度检查: 驱逐前检查其他节点是否有足够资源接收 Pod
- 该工具在驱逐前会检查其他节点是否有足够容量接收被驱逐的 Pod,避免将问题从一个节点转移到另一个节点。这一功能通过估算每个节点的可用内存来实现,确保被驱逐的 Pod 能够被成功调度到其他节点。该工具会检查至少留有 20% 缓冲的可用空间。
-
保护策略:
- 命名空间保护: 工具默认保护 kube-system、kube-public、kube-node-lease 等系统命名空间,以及 monitoring、logging 等运维相关命名空间。任何属于这些命名空间的 Pod 都将自动获得保护。
- DaemonSet/StatefulSet 保护: 工具默认保护 DaemonSet 管理的 Pod,因为它们通常需要在每个节点上运行。可选地保护 StatefulSet 管理的 Pod,因为它们通常与持久存储关联。
- PodDisruptionBudget 保护: 如果某个 Pod 被某个 PDB 策略所覆盖,该工具会检查该 PDB 的最小可用实例数,确保驱逐操作不会违反 PDB 约束。
- 自定义标签/前缀保护: 用户可以通过标签选择器或 Pod 名称前缀来标记需要保护的 Pod,该工具会在驱逐前检查这些规则。
快速开始
环境要求
在部署该工具之前,需要确保目标环境满足以下要求:
- Python 版本: Python >= 3.6,因为该工具使用了 dataclass 和类型提示等 Python 3.6+ 特性
- kubectl 工具: kubectl 命令行工具已安装并配置好 kubeconfig 文件,确保有足够的权限访问目标集群
- metrics-server: 集群需要部署 metrics-server 或其他兼容的指标服务器,因为该工具依赖 kubectl top 命令获取节点指标
- RBAC 权限: 部署账号需要对集群执行以下操作:get nodes(获取节点列表)、top nodes(获取节点指标)、get pods --all-namespaces(获取 Pod 列表)、delete pod(驱逐 Pod)、get pdb(获取 PodDisruptionBudget 配置)
安装
bash
# 1. 进入目录
cd new_k8s_server_monitor
# 2. 安装 Python 依赖
pip3 install -r requirements.txt
# 3. 修改配置文件
vim config.yaml
# 4. 添加执行权限
chmod +x startup.sh安装完成后,建议首次部署时将配置文件中的 dry_run 参数设置为 true,进行一次完整的模拟运行,验证配置是否正确后再启用实际驱逐功能。
配置钉钉机器人
钉钉机器人用于接收内存压力告警和驱逐通知,配置步骤如下:
- 在钉钉群中添加自定义机器人:打开钉钉群聊,点击右上角的群设置图标,选择群机器人管理,点击添加机器人,选择自定义机器人,设置名称和头像后完成创建
- 获取 Webhook 地址:创建完成后会生成一个 Webhook 地址,复制该地址用于配置
- 在
config.yaml中配置:
yaml
alert:
dingtalk_webhook: "https://oapi.dingtalk.com/robot/send?access_token=YOUR_TOKEN"
enabled: true
silence_period: 1800 # 静默期(秒),建议设置为 900-3600 之间使用方式
该工具提供了 startup.sh 脚本来管理监控进程,支持多种操作模式:
bash
# 启动监控
./startup.sh start
# 模拟模式启动(不实际驱逐)
./startup.sh start --dry-run
# 停止监控
./startup.sh stop
# 重启监控
./startup.sh restart
# 查看状态
./startup.sh status
# 执行单次检查
./startup.sh once
# 查看日志
./startup.sh logs 100
# 实时查看日志
./startup.sh follow启动监控:该工具会在后台启动监控进程,按照配置的检查间隔(默认为 300 秒)持续监控集群状态。
模拟模式:使用 --dry-run 参数启动时,所有驱逐操作都会记录日志但不会实际执行,适合在部署前测试配置或观察驱逐建议。
停止/重启:使用 stop 和 restart 命令可以优雅地停止或重启监控进程。
执行单次检查:使用 once 参数可以让该工具执行一次完整的检查流程后自动退出,适合用于定时任务或一次性检查。
日志查看:logs 命令可以查看历史日志,follow 命令可以实时跟踪最新日志输出。
配置说明
配置文件 config.yaml 包含以下主要部分,每个部分都有详细的参数说明和默认值。
告警配置
告警配置控制告警的发送行为和钉钉机器人的设置:
yaml
alert:
dingtalk_webhook: "钉钉机器人Webhook地址"
enabled: true # 是否启用钉钉告警
silence_period: 1800 # 静默期(秒),同一节点在此时间内不重复告警dingtalk_webhook:钉钉机器人的 Webhook 地址,需要在钉钉群组中添加自定义机器人并获取。地址格式为 https://oapi.dingtalk.com/robot/send?access_token=xxx。
enabled:布尔值,控制是否启用钉钉告警功能。设置为 false 将完全禁用告警,适合只想执行驱逐而不需要通知的场景。
silence_period:告警静默时间,单位为秒。建议设置为 900(15 分钟)到 3600(1 小时)之间。静默期的设置需要平衡及时性和告警泛滥的矛盾:设置太短可能导致频繁告警,设置太长可能错过重要告警。
阈值配置
阈值配置是影响该工具响应行为的核心参数,直接决定了在什么情况下触发告警和驱逐:
yaml
thresholds:
memory_alert: 90 # 内存告警阈值 (%)
memory_eviction: 95 # 内存驱逐阈值 (%)
cpu_alert: 85 # CPU告警阈值 (%)memory_alert:内存告警阈值,当节点内存使用率超过此值时发送告警。建议设置为集群平均内存使用率加上 5-10 个百分点。例如,如果集群平均使用率约为 80%,可以设置告警阈值为 85%-90%。设置过低会导致频繁告警,设置过高可能错过预警时机。
memory_eviction:内存驱逐阈值,当节点内存使用率超过此值时触发 Pod 驱逐。建议设置为告警阈值加上 5 个百分点。对于内存敏感的业务,可以适当降低驱逐阈值;对于内存相对宽裕的集群,可以适当提高驱逐阈值。
cpu_alert:CPU 告警阈值,仅用于告警提示,不会触发驱逐。CPU 使用率通常不是驱逐的触发条件,因为 CPU 压力可以通过水平扩展更优雅地解决。
驱逐策略
驱逐配置是该工具最复杂的配置部分,需要根据实际业务情况仔细调整:
yaml
eviction:
enabled: true # 是否启用自动驱逐
mode: "auto" # auto=自动驱逐, manual=仅建议
max_pods_per_round: 3 # 单轮最大驱逐数量
cooldown_period: 60 # 驱逐后冷却时间(秒)
target_memory_usage: 85 # 目标内存使用率 (%)
min_pod_memory_mb: 500 # 最小Pod内存阈值enabled:布尔值,控制是否启用自动驱逐功能。设置为 false 将只发送告警而不执行驱逐。这在工具刚部署或进行维护期间非常有用。
mode:驱逐模式选择。auto 表示自动驱逐,Pod 会被立即删除;manual 表示只生成驱逐建议而不实际执行,适合需要人工确认的保守场景。
max_pods_per_round:单次驱逐周期的最大 Pod 数量。这个参数需要根据集群规模和业务容忍度来调整。对于小型集群,建议设置为 2-3;对于大型集群,可以适当增加。但不宜一次驱逐过多 Pod,因为大量的 Pod 重建会增加调度压力并可能导致服务中断。
cooldown_period:驱逐后的冷却时间,表示两次驱逐操作之间的最小间隔。如果集群负载较高,Pod 可能需要较长时间才能调度成功,建议设置为 90-120 秒。
target_memory_usage:驱逐的目标内存使用率。驱逐操作会持续到节点内存使用率降至该值以下。设置过低可能导致过度驱逐,设置过高可能导致驱逐效果不明显。
min_pod_memory_mb:可驱逐 Pod 的最小内存阈值。内存占用低于此值的 Pod 不会被考虑驱逐,因为驱逐它们释放的内存有限,却会造成额外的调度开销。对于以大量小内存 Pod 为主的集群,可以适当提高此阈值。
保护配置
保护配置是确保关键服务安全的核心配置,该工具实现了五层保护机制:
yaml
protection:
# 受保护的命名空间
namespaces:
- "kube-system"
- "kube-public"
- "kube-node-lease"
- "cattle-system"
- "cattle-fleet-system"
- "ingress-nginx"
- "monitoring"
- "logging"
- "calico-system"
- "tigera-operator"
- "dify"
# 受保护的Pod名称前缀
pod_prefixes:
- "coredns"
- "etcd"
- "kube-apiserver"
- "kube-controller"
- "kube-scheduler"
- "kube-proxy"
- "canal"
- "calico"
- "flannel"
- "weave"
- "metrics-server"
- "node-exporter"
- "prometheus"
- "alertmanager"
- "grafana"
- "filebeat"
- "fluent"
- "dify"
# 受保护的Pod标签
# 格式: "key=value" 或仅 "key"(存在即保护)
pod_labels:
- "app.kubernetes.io/part-of=kube-system"
- "k8s-app=kube-dns"
- "protection=enabled"
# 是否保护特定类型的Pod
protect_daemonset: true
protect_statefulset: false
protect_pdb_pods: truenamespaces:受保护的命名空间列表。任何属于这些命名空间的 Pod 都将自动获得保护,不会被驱逐。该工具默认包含所有关键系统命名空间和常见运维命名空间。
pod_prefixes:受保护的 Pod 名称前缀列表。匹配这些前缀的 Pod 不会被驱逐。该工具默认包含所有关键系统组件的名称前缀。
pod_labels:受保护的 Pod 标签列表。支持两种格式:key=value 表示需要精确匹配标签值;key 表示只要 Pod 包含该标签即受保护。
protect_daemonset:是否保护 DaemonSet 管理的 Pod。默认为 true,因为 DaemonSet Pod 通常需要在特定节点上运行。
protect_statefulset:是否保护 StatefulSet 管理的 Pod。默认为 false,因为 StatefulSet Pod 通常与持久存储关联,驱逐后可能涉及数据迁移。
protect_pdb_pods:是否保护受 PodDisruptionBudget 约束的 Pod。默认为 true,确保驱逐操作不会违反 PDB 约束。
高级配置
高级配置提供了一些额外的控制选项:
yaml
advanced:
dry_run: false # 模拟模式
exclude_master_nodes: true # 排除master节点
excluded_nodes:
- "master-*" # 支持通配符
node_label_selector: "" # 节点标签过滤
include_cluster_summary: true # 集群资源统计是否包含在告警中dry_run:是否启用模拟模式。启用后该工具会记录所有驱逐操作但不会实际执行,适合在部署前测试配置。
exclude_master_nodes:是否自动排除 master/controlplane 节点。默认为 true,建议在生产环境中保持启用。
excluded_nodes:需要排除的节点名称列表,支持通配符匹配。例如 "master-*" 可以排除所有以 master- 开头的节点。
node_label_selector:节点标签选择器,只监控带有特定标签的节点。留空则监控所有节点。
include_cluster_summary:控制是否在告警消息中包含集群资源统计信息。启用后可以快速了解整体资源状况。
工作流程
┌─────────────────────────────────────────────────────────────┐
│ 主循环开始 │
└───────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ kubectl top nodes 获取节点指标 │
└───────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 检查内存使用率阈值 │
│ │
│ 内存 < 90% ─────────────────────────────────► 正常 │
│ 内存 >= 90% && < 95% ────────────────────────► 告警 │
│ 内存 >= 95% ─────────────────────────────────► 告警+驱逐 │
└───────────────────────────┬─────────────────────────────────┘
│ (需要驱逐)
▼
┌─────────────────────────────────────────────────────────────┐
│ 获取节点上所有Pod及其资源使用情况 │
└───────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 过滤受保护的Pod │
│ - 系统命名空间 │
│ - DaemonSet/StatefulSet │
│ - PDB保护 │
│ - 自定义保护规则 │
└───────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 计算驱逐优先级并排序 │
│ - QoS类型 (BestEffort > Burstable > Guaranteed) │
│ - 内存占用大小 │
│ - Pod运行时长(可选) │
└───────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 检查调度可行性 │
│ - 其他节点是否有足够资源 │
│ - 估算驱逐后内存释放量 │
└───────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 执行驱逐 │
│ - kubectl delete pod --grace-period=30 │
│ - 等待冷却时间 │
│ - 发送驱逐通知 │
└───────────────────────────┬─────────────────────────────────┘
│
▼
等待下一个检查周期监控检查阶段:该工具通过 kubectl top nodes 命令获取所有节点的资源使用情况。需要集群已部署 metrics-server。如果获取失败,该工具会记录错误日志并返回空列表。
阈值判断阶段:该工具根据配置的告警阈值(默认 90%)和驱逐阈值(默认 95%)对每个节点进行分类。低于告警阈值的节点视为正常;介于两者之间的节点发送告警;超过驱逐阈值的节点触发驱逐流程。
告警发送阶段:如果存在告警节点,该工具生成包含节点列表和集群资源概览的告警消息,通过钉钉机器人发送。发送前检查静默期,避免重复告警。
驱逐决策阶段:对于需要驱逐的节点,该工具获取该节点上所有 Pod 的列表,应用五层保护规则过滤受保护的 Pod,对剩余 Pod 按优先级排序,计算需要驱逐的 Pod 列表。驱逐前检查其他节点是否有足够容量接收被驱逐的 Pod。
驱逐执行阶段:根据驱逐模式执行实际操作。自动模式下使用 kubectl delete pod 命令驱逐 Pod,每个驱逐操作之间有冷却时间。手动模式下只记录驱逐建议。驱逐完成后发送驱逐通知。
告警示例
内存压力告警
当节点内存使用率超过告警阈值时发送:
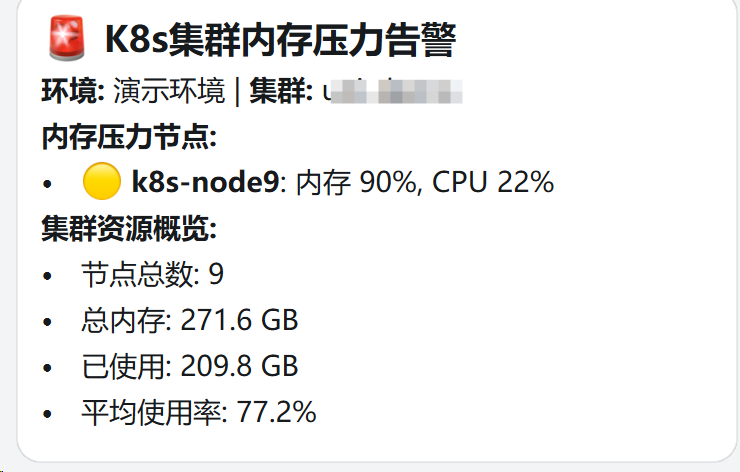
🚨 K8s集群内存压力告警
环境: 演示环境 | 集群: demo
**内存压力节点:**
- 🔴 **k8s-node135**: 内存 96%, CPU 15%
- 🟡 **node85**: 内存 91%, CPU 33%
**集群资源概览:**
- 节点总数: 12
- 总内存: 180.5 GB
- 已使用: 152.3 GB
- 平均使用率: 84.3%告警消息说明:
- 🔴 红色圆点:表示内存使用率超过驱逐阈值的紧急节点,需要立即处理
- 🟡 黄色圆点:表示内存使用率超过告警阈值但尚未达到驱逐阈值的警告节点,需要关注
- 集群资源概览:提供整体资源状况,帮助评估问题严重程度
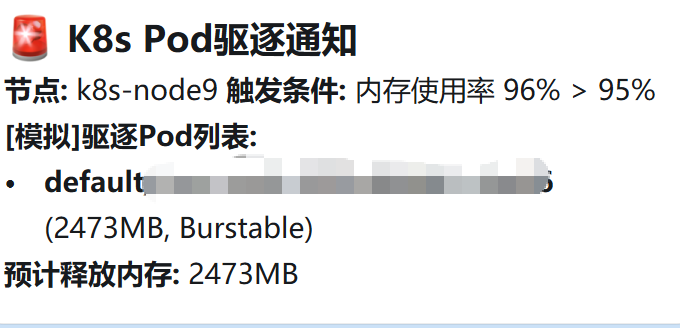
Pod驱逐通知
当该工具执行 Pod 驱逐后发送:
🚨 K8s Pod驱逐通知
环境: 演示环境 | 集群: demo
**节点:** k8s-node135
**触发条件:** 内存使用率 96% > 95%
**已驱逐Pod列表:**
- `default/exam-web-6559b75bf-dqpnh` (3679MB, Burstable)
- `default/resourceapi-web-5747fd649d-vnhsk` (2393MB, Burstable)
**预计释放内存:** 6072MB驱逐通知说明:
- 节点:触发驱逐的节点名称
- 触发条件:当前内存使用率和驱逐阈值的对比
- 已驱逐 Pod 列表:被驱逐的 Pod 完整名称、内存占用和 QoS 类别
- 预计释放内存:所有被驱逐 Pod 释放的内存总量
常见问题
Q: 如何确保关键服务不被驱逐?
有多种方式保护关键服务,层层防护确保关键服务安全:
方式一:命名空间保护。将服务部署在受保护的命名空间中。该工具默认保护 kube-system、kube-public 等系统命名空间,也可以在配置中添加自定义的受保护命名空间。任何属于这些命名空间的 Pod 都将自动获得保护。
方式二:Pod 名称前缀保护 。在 config.yaml 中添加 Pod 名称前缀规则。该工具默认保护 coredns、kube-proxy 等关键系统组件的 Pod,可以根据实际部署情况添加更多前缀,如数据库、中间件等服务的 Pod 名称前缀。
方式三:标签保护 。给 Pod 添加保护标签 protection=enabled,然后在配置文件中添加对应的 pod_labels 规则。这是最灵活的保护方式,可以精确控制哪些 Pod 需要保护。
方式四:PodDisruptionBudget 保护。创建 PodDisruptionBudget,配置最小可用实例数。该工具会自动保护受 PDB 约束的 Pod,确保驱逐操作不会违反 PDB 约束。
Q: 驱逐后 Pod 会去哪里?
驱逐的 Pod 会被其控制器(Deployment/ReplicaSet)重新创建,调度器会选择资源充足的节点进行调度。该工具在驱逐前会检查其他节点是否有足够资源,确保被驱逐的 Pod 能够被成功调度到其他节点。被驱逐的 Pod 删除后,控制器检测到 Pod 数量减少,会创建新的 Pod 来维持期望的副本数,Kubernetes 调度器根据资源可用性选择最优节点。
Q: 如何只查看驱逐建议而不实际执行?
两种方式可以实现只查看驱逐建议而不实际执行:
方式一:配置模式 。设置 eviction.mode: "manual",在这种模式下,该工具会计算驱逐计划并记录日志,但不会实际执行驱逐操作。适合需要人工确认的保守场景。
方式二:命令行参数 。使用 --dry-run 参数启动服务:./startup.sh start --dry-run,这种方式同样不会实际执行驱逐,适合在部署前测试配置是否正确或观察驱逐建议。
Q: 如何调整驱逐的激进程度?
通过调整以下参数可以控制驱逐的激进程度:
-
memory_eviction:提高驱逐阈值可以降低触发频率。例如从 95% 提高到 97%,只有更严重的内存压力才会触发驱逐。
-
max_pods_per_round:减少单次驱逐数量可以使驱逐过程更加保守。例如从 3 减少到 1,每次只驱逐一个 Pod。
-
min_pod_memory_mb:提高最小 Pod 内存阈值可以跳过小内存 Pod,避免驱逐效果不明显的操作。例如从 500 提高到 1000。
-
cooldown_period:增加冷却时间可以延长驱逐间隔,给 Pod 更多的重新调度时间。例如从 60 秒增加到 120 秒。
-
target_memory_usage:提高目标内存使用率可以减少驱逐次数。例如从 85% 提高到 90%,只需驱逐到更低的压力水平即可。
Q: 驱逐后内存没有明显下降怎么办?
驱逐后内存没有明显下降可能有以下原因:
原因一:被驱逐的 Pod 内存占用很小。驱逐多个小内存 Pod 才能看到明显效果。解决方案:降低 min_pod_memory_mb 参数或增加单次驱逐数量。
原因二:Pod 正在被重新调度到其他节点。如果其他节点也有内存压力,可能会出现驱逐后内存迅速回升的情况。解决方案:检查其他节点的状态,可能需要整体扩容。
原因三:节点上存在内存泄漏。驱逐 Pod 释放的内存很快被其他进程消耗。解决方案:排查内存泄漏的根本原因,可能需要重启节点或升级有问题的应用。
Q: 收到大量重复告警怎么办?
如果收到大量重复告警,说明静默期设置过短。解决方案:增加 silence_period 参数的值,例如设置为 3600(1 小时)。另外也可以适当提高告警阈值,将阈值设置得更高一些,减少告警的触发频率。在调整阈值时,需要平衡告警的及时性和准确性。
Q: 没有收到告警怎么办?
没有收到告警可能的原因和解决方法:
原因一:钉钉机器人 Webhook 地址配置错误。检查 config.yaml 中的 dingtalk_webhook 是否正确,复制完整的 Webhook 地址。
原因二:告警功能被禁用。检查 config.yaml 中的 alert.enabled 是否设置为 true。
原因三:节点内存使用率未超过告警阈值。通过 kubectl top nodes 确认当前节点的内存使用情况。
原因四:在静默期内。检查上次告警发送时间,距离现在是否在配置的静默期内。