作为损失曲线的笔记用于创新点的查找与查找与查找。
原文来自:Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation
这个方法似乎不是该论文首次提出的,但是我是通过该论文总结的。
一句话来说,这里的损失曲线就是通过训练时得到的损失值判断任务边界,以此来将依赖任务边界的算法运用到任务无关场景。
一.理论依据
关于loss surface的直觉:
- loss 持续下降:说明模型还能从当前分布的样本里学到东西;
- loss 上升/出现峰值(peak):往往意味着数据分布发生变化,当前参数不再适配;
论文假设 "模型会在分布再次变化前先收敛 ",因此在学完一个稳定分布后,loss 会进入平稳平台(plateau),这类平稳平台就被当作"适合巩固知识、开启下一阶段适配"的时刻。
以下是论文中附带的 F i g u r e .1. ( c ) Figure.1.(c) Figure.1.(c) :
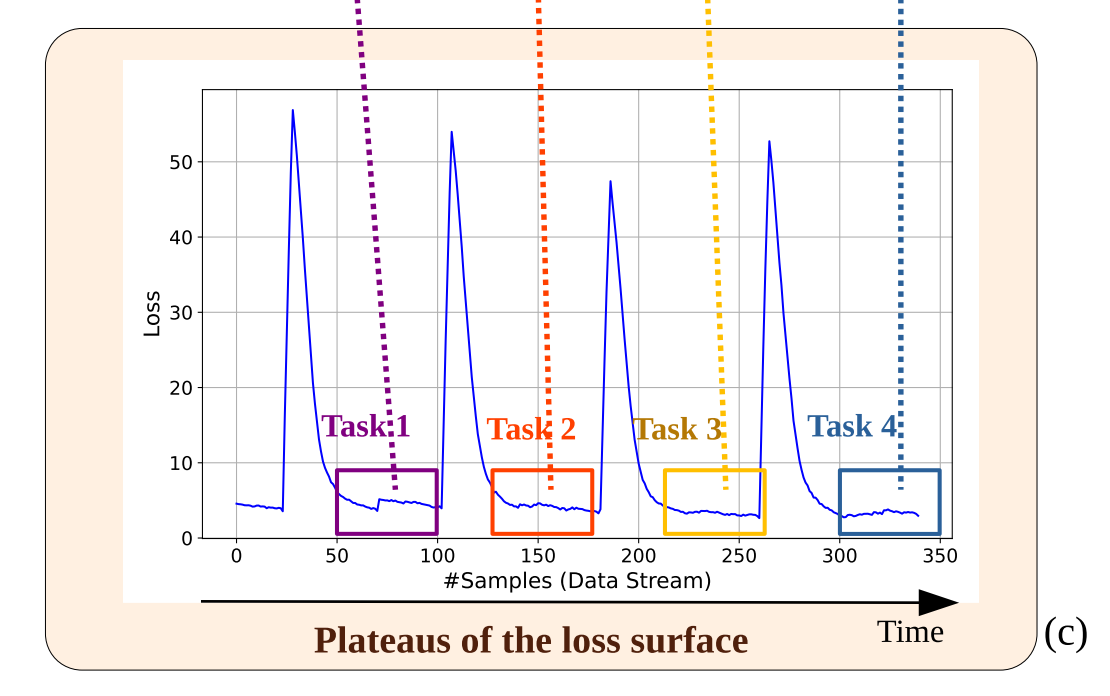
从图中我们可以很容易地看出来,当任务切换时,确实会出现非常明显地损失上升过程。
二.代码实现
为了便于介绍代码中的任务边界的判断逻辑,以下的代码会删除部分与原论文中参数重要性判断等逻辑。
1. 损失窗口数据结构
python
# 存储最近的损失值(滑动窗口)
loss_window = []
# 存储历史统计信息(用于可视化/调试)
loss_window_means = [] # 存储窗口均值
loss_window_variances = [] # 存储窗口方差
last_loss_window_mean = [] # 存储上一个窗口均值
last_loss_window_variance = [] # 存储上一个窗口方差
# 峰值检测标志
new_peak_detected = True # 初始为 True,表示已检测到峰值论文中通过滑动窗口来存储最近的损失值,用于后续计算均值与方差,然后通过设置均值与方差的阈值,来判断当前批次是旧任务还是新任务的批次。
new_peak_detected 是用来标记是否检测到新峰值的,置为True的目的会在接下来的步骤中说明。
2.损失收集与窗口更新
python
# 在每次训练迭代后收集损失
train_loss = total_loss.detach().cpu().numpy() # 当前批次的损失
loss_window.append(np.mean(train_loss)) # 添加到窗口
# 保持窗口大小固定(滑动窗口)
if len(loss_window) > args.loss_window_length:
del loss_window[0] # 移除最老的损失值
# 计算窗口统计量
loss_window_mean = np.mean(loss_window)
loss_window_variance = np.var(loss_window)
print('loss window mean: {0:0.3f}, loss window variance: {1:0.3f}'
.format(loss_window_mean, loss_window_variance))train_loss 存储的是每个 batch 的样本损失,再通过均值计算后得到"当前 batch 内的平均样本损失",存储进入 loss_window。
loss_window_mean 与 loss_window_variance 计算的都是当前窗口的均值与方差。
3.峰值检测
python
# --- 峰值检测逻辑 ---
if not new_peak_detected and loss_window_mean > last_loss_window_mean + np.sqrt(last_loss_window_variance):
new_peak_detected = True # 检测到峰值!
print("PEAK DETECTED: Data distribution shift detected!")这里的认定峰值的逻辑是:
- 未检测到峰值
- 当前窗口的均值大于上一次窗口的均值加上一个标准差
两者均符合时,就会标记为峰值。
4.平台期检测
python
# --- 平台期检测逻辑 ---
if (loss_window_mean < args.loss_window_mean_threshold and
loss_window_variance < args.loss_window_variance_threshold and
new_peak_detected):
count_updates += 1
print('IMPORTANT: Loss plateau detected! Triggering knowledge consolidation...')
# 记录当前平台期的统计量
last_loss_window_mean = loss_window_mean
last_loss_window_variance = loss_window_variance
# 重置峰值标志(准备检测下一个峰值)
new_peak_detected = False这里的认定平台期的逻辑是:
- 检测到峰值
- 当前窗口的均值小于均值的阈值
- 当前窗口的方差小于方差的阈值
此时,检测到平台期,峰值标志会被重置,在原论文中,会在平台期进行LoRA参数的替换与参数重要性估计的更新,这里省略。
论文中提出的各数据集的阈值如下表所示:
| 阈值类型 | CIFAR-100 | ImageNet-R | ImageNet-S | CORe50 | CUB-200 |
|---|---|---|---|---|---|
| 均值阈值 | 2.6 | 5.2 | 5.6 | 6.0 | 24.0 |
| 方差阈值 | 0.03 | 0.02 | 0.06 | 0.1 | 1.0 |
三.总结
目标 :在无显式任务标识 的在线持续学习场景中,通过监控训练损失曲线的变化,自动检测数据分布的切换时刻(任务边界),从而触发模型的"知识巩固"操作(如LoRA参数冻结与更新)。
理论基础:模型的损失曲线反映了其与当前数据分布的适配程度。
- 损失下降/平稳:模型正在学习或已适应当前分布。
- 损失陡升/出现峰值:数据分布很可能发生了切换,模型不再适应。
- 关键假设 :模型在面临新分布前,会先对旧分布达到收敛(即损失进入平台期)。
核心流程:
- 滑动窗口监控:维护一个最近若干个批次的损失值窗口。
- 实时统计:持续计算窗口内损失的均值与方差。
- 两阶段检测 :
- 峰值检测 :当
当前窗口均值 > 上一平台期均值 + 上一平台期标准差时,判定出现数据分布变化(任务切换)。 - 平台期检测 :当
已检测到峰值且当前窗口均值 < 均值阈值且当前窗口方差 < 方差阈值时,判定模型已在新任务上达到初步收敛,进入适合进行知识巩固的平台期。此时触发关键操作(如更新重要参数、固化部分权重),并重置检测器,准备识别下一个任务
- 峰值检测 :当
总的来说,该方法是一个将损失监控用于任务边界感知的低成本方法。