Linux 设备模型学习笔记(2)之 kobject
前言
在学习 Linux 驱动开发时,我们不可避免的会接触到 kobject 这个知识点,对于 kobject ,内核源码中有一个教学文档:Documentation/kobject.txt,文档开头就说:理解驱动模型以及它构建的kobject抽象层的难点之一在于没有显而易见的起点 。这句话我深有体会,面对 kobject、kset、ktype 这三个极其抽象的词,我们很难从他们的字面意思大概推断出他们各自的功能,更不知道他们是怎样协同工作的。
本篇文章作为我的设备模型学习笔记系列的第二篇,我将会记录我从最开始接触kobject这个概念时的一些理解,同时梳理一些必要的核心基础概念,并基于 Linux 6.14 内核编写一个可以在虚拟机上面运行的测试程序,结合实际的 dmesg 日志和 /sys 节点,分析 kobject 到底在各个阶段都干了什么。
1. kobject------C语言中的基类
1.1 名字里面暗藏的玄机
在学习kobject的过程中,如果非要指定一个学习的起点,那可能就是kobject这个词本身吧。这个词本身是两个词的组合,我们把它拆开来看,拆成下面两个词 Kernel Object ,取kernel的首字母和object的全部,就得到了kobject。
如果有过面向对象语言(OOP) 的编程经验,那么对object这个词一定不会陌生。在面向对象语言中,object通常是所有类的基类 ,也就是说,所有的类,无论是字符串,数组,还是自定义的复杂类,本质上都继承自object。
但是 Linux 内核是用 C 语言写的,而 C 语言明明是面向过程 的,为什么会出现对象这个概念呢?
其实这正是 Linux 设备模型设计的精髓,Linux 内核在用 C 语言的语法,来模拟面向对象编程的特性。
1.2 为什么需要这个基类
我们现在已经知道 Linux 内核在使用 C 语言来模拟面向对象编程的特性,那么这样做的意义是什么呢?
事实上,Linux 内核需要管理成千上万种设备,比如:键盘,鼠标,硬盘,CPU,显卡,网卡等等。
这些设备看起来差别很大,毫不相关,但是在内核视角来看,他们还是有一些共性的,下面列举几个:
第一:他们都需要有一个名字 ,尽管他们的名字都不一样吧,但是名字这个属性本身他们都要有。
第二,他们都需要被统计使用情况 ,也就是引用次数,这是非常重要的一个点,后面会反复提及。我们不能在还有进程正在使用一个设备时,就把这个设备的内存释放了,因此需要统计一个设备正在被多少个进程使用,也就是引用次数,当引用次数归零时,内核自动调用回调函数释放该设备内存。
第三,它们都需要被组织起来,形成一个层级关系,可以参考设备树。在释放一个设备的内存时,我们需要确保这个设备在设备树中没有其他子节点正在被引用。
第四,它们都需要和用户进行交互。因此需要在 /sys 下创建一个目录,让用户能看到它。
每个设备都需要实现上面的这些共性,但如果给每种设备都单独写一套代码来实现这些功能,那么内核代码将会变的极其冗余并且难以维护。
于是,聪明的内核开发者将所有设备的这些共性提取出来,设计了 struct kobject 。不管是简单的还是复杂的设备,都需要这个 struct kobject。就好像不管你是要盖一栋摩天大楼,还是盖一间厕所,都需要先打好地基一样。
1.3 独特的嵌入式继承方式
Linux 采用了一种更加原始的方式来实现继承:就是将kobject嵌入到结构体内部。
前言中提到的kobject.txt文档中有这么一句话:Kobjects are generally not interesting on their own; instead, they are usually embedded within some other structure which contains the stuff the code is really interested in.
翻译过来大致意思是这样的:kobject本身通常并没有什么意义,它们通常是嵌入在一些其他的结构,而这些结构才包含代码真正感兴趣的东西。
也就是说我们几乎永远不会单独创建一个 struct kobject 变量。相反,它总是被嵌入到更高级的数据结构中。
口说无凭,我们直接看看内核源码中的具体构造是长什么样子的。
我们先来看字符设备结构体struct cdev,它存放在内核源码目录中的/include/linux/cdev.h文件中,我把截图放在下面:
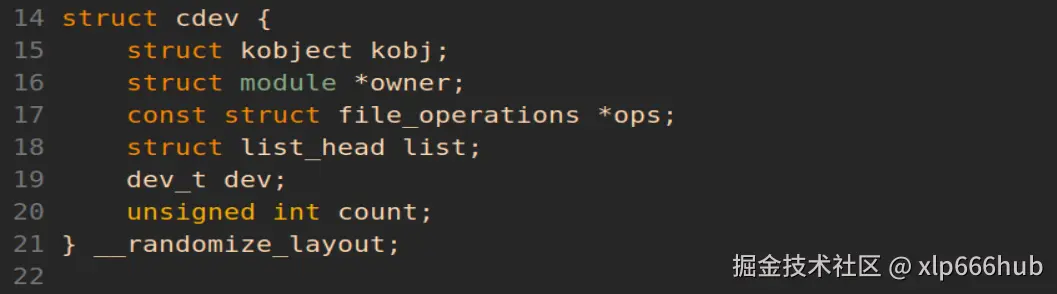
请看截图中的第 15 行,struct cdev结构体把 struct kobject结构体当做自己的一个成员变量塞了进来。这样一来,cdev 就自动拥有了引用计数和 Sysfs 的能力。
再来看看设备基类 ,struct device 是整个 Linux 驱动模型中的中流砥柱,无论是 USB 设备,平台设备还是总线设备,最终都会包含这个结构体。它在内核源码目录中/include/linux/device.h文件中,由于这个结构体实在太长了(大约 100 行),我就只截图了关键部分,截图如下:
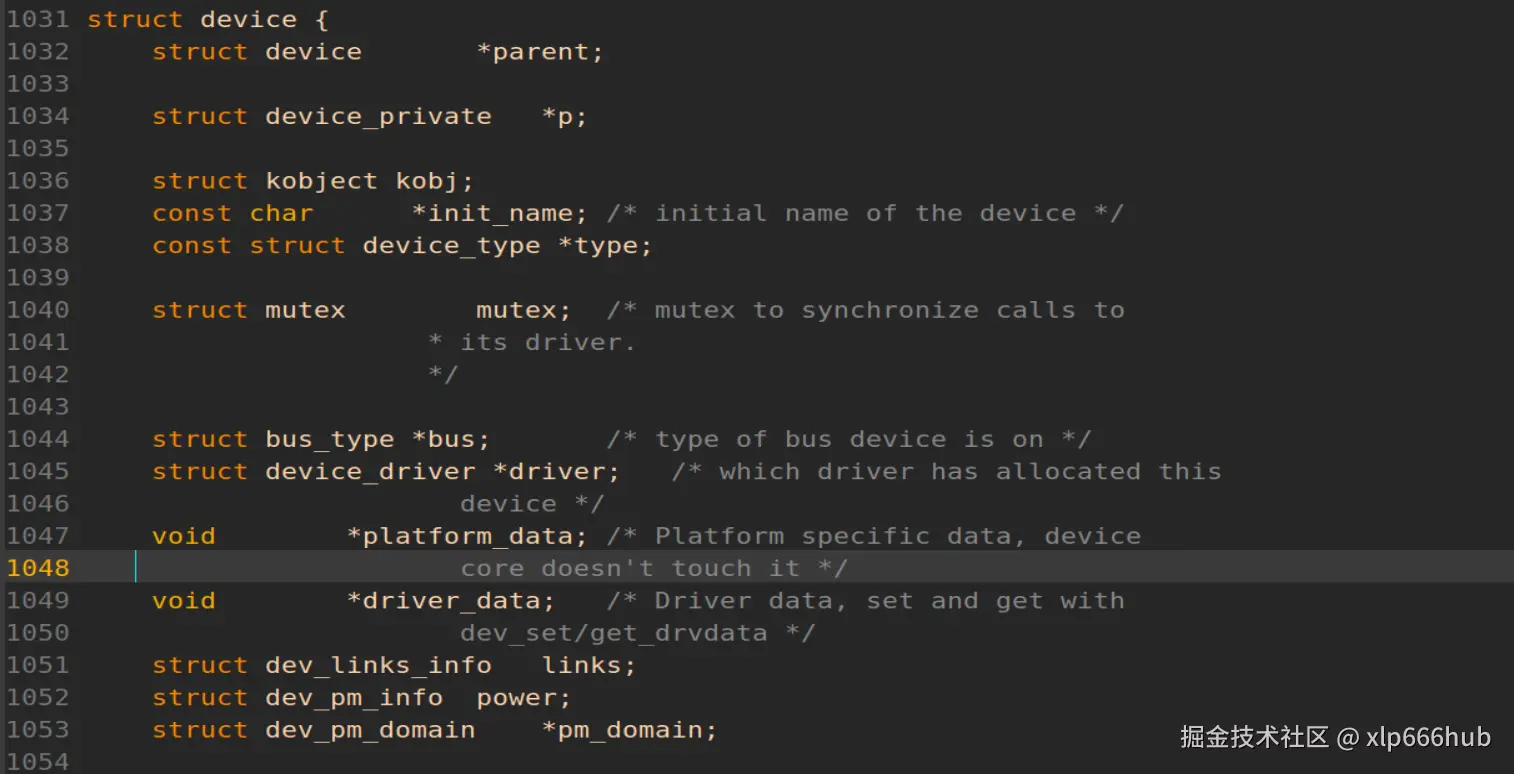
请看截图中第 1036 行,依然是我们熟悉的 struct kobject 结构体。
看到这里,我相信这两张截图已经足够说明问题了。即便是内核中最核心,最复杂的 struct device,其底层逻辑依然是包含了一个 kobject。
这也揭示了一个重要的真理,也是后面我们写测试程序时的逻辑:当内核想要管理一个对象时,它实际上只认识 kobject,内核通过操作对象内部的 kobject 来管理生命周期,而驱动开发者则通过 container_of 宏,根据 kobject 找回具体的 cdev 或 device结构体的地址。
1.4 本章小结
本章我们从kobject这个词本身切入,了解了它是 Linux 驱动模型中所有对象的基类。再过渡到它的功能,知道了它负责引用计数,sysfs 入口和层级管理。再到最后它的结构特点,我们知道了它从不独自出现,而是寄生在其他具体的对象里面,内核通过 kobject 指针管理对象的生命周期,而代码逻辑中要通过 container_of 宏找回具体的设备对象。
到这里,我们对kobject已经有了一定的认识了。
但是我们还不知道:引用计数归零后,具体怎么释放内存,谁来释放内存,而成千上万个kobject又是如何存放的。
这正是驱动模型中另外两个重要的概念,即ktype和kset,我们下一章的内容。
2. ktype 与 kset
2.1 ktype
ktype的全称是struct kobj_type,如果说kobject是一个对象的肉体,那么ktype就是控制这个肉体的行为逻辑的。
我们在第一章中提到过,kobject被嵌入在各种各样的结构体中,当引用计数归零后,内核就要释放内存。
关键问题就在这里:kobject并不知道自己嵌入的那个宿主结构体究竟由多大,并且就算站在我们的角度,虽然能知道这些结构体的大小,但是他们的大小也各不相同。
那么这个问题到底该怎么解决呢?答案就是ktype。
我们先来看看它在内核源码中的定义,在include/linux/kobject.h中,截图如下:
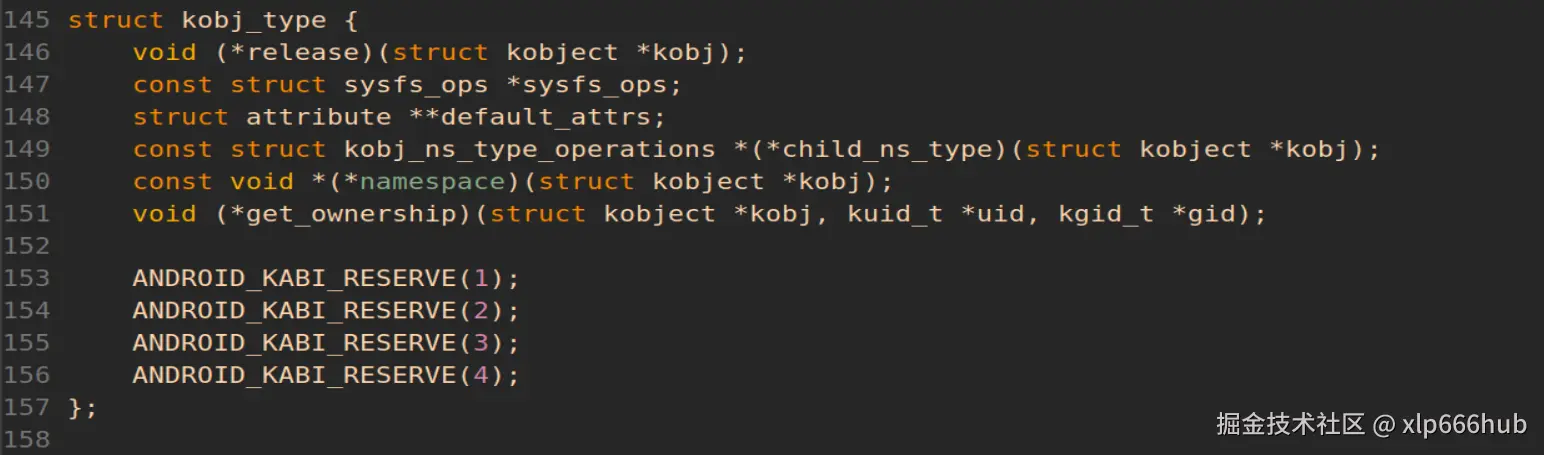
第 146 行的release函数就是ktype最核心的功能,当kobject的引用计数变为 0 时,内核就会自动调用这个函数 ,而我们要做的就是在这个函数中使用container_of宏通过kobject成员的地址得到宿主结构体的地址,然后用kfree将它释放。
要注意的是我们一定是在release函数中用kfree释放内存的,而不是在模块卸载函数中,要知道,模块一旦注册,就不止用户一个人可以加载这个模块,可能还有别的进程在加载这个模块,如果在模块卸载函数中释放内存,执行rmmod时,它会被直接释放,而此时可能还有别的进程正在使用这个模块,从而产生严重的错误。而release函数只有在引用计数归零时才会被调用,也就是说它能够保证这个模块已经没有任何进程在使用了,这样才是绝对安全的。
第 147 行的sysfs_ops,这是控制读写行为 的函数,当用户在 /sys 下读写文件时,内核怎么知道如何处理这个行为?只能全靠这个指针,它定义了 show(读)和 store(写)的具体实现,这个结构体的原型在include/linux/sysfs.h中:

这就是为什么我们在 shell 中使用 cat 和 echo 命令就能直接控制内核变量的底层原理。
关于第 148 行,这里要解释一下,我当前查看的是旧版本的内核源码,而编译时使用的是新版的,在现代 Linux 主线内核(5.12+) 以及大多数新的发行版中,default_attrs 已经被废弃并移除 ,取而代之的是 default_groups,后面的测试程序中使用的正是default_groups。
在新版本中,内核强制要求使用属性组(Groups) 来管理文件,它的作用是告诉内核:当这个 kobject 注册时,自动在 /sys 目录下创建这一组文件。
2.2 kset
在知道了具体的行为是怎么实现的之后,我们再来看看归属。
内核里有成千上万个对象,如果全都乱堆在一起,/sys 目录就没法看了,因此我们需要文件夹,将它们进行分类。
而kset就是用来干这个的。我们可以把kset想象成一个目录,如下图:

sys/devices是一个kset,sys/block是一个kset,sys/kernel也是一个kset。
kset功能主要可以分为两大类:
第一个是组织管理 :它会把相关的kobject都串在一个链表上面。比如它会把所有的 USB 设备都挂在 USB 子系统的 kset 下,从而在 /sys 文件系统中形成清晰的目录层级结构。
第二个是处理热插拔事件 :当一个新的 kobject 加入到一个 kset 时,这个 kset 会向用户空间发送一个 Uevent 消息,用户空间的 udev 或 mdev 守护进程收到消息后,就会自动加载驱动、创建对应的设备节点 。换句话说,没有kset,就没有即插即用。
2.3 三者的关系总结
现在我们对这三者的关系进行一个总结,这是理解 Linux 驱动模型非常关键的一张关系网:
kobject是核心对象,ktype控制对象的行为规范,告诉它遇到什么事件对应的作出那些行为,而kset用来组织管理。
每个kobject必须指向一个ktype,原因很简单,它必须要知道遇到怎样的事件作出什么样的反应。kobject可以属于一个kset,也可以不属于,这只是关系到能不能处理热插拔事件。kset本身也是一个kobject,因为它也是一个对象,也需要引用计数和目录。
这就支撑起了整个庞大而复杂的 Linux 设备驱动模型。
下一章,我们将基于 Linux 6.14 内核 ,手写一个包含 kobject、ktype 和 Sysfs 属性的完整驱动模块,并分析运行结果。
3. 编写测试程序
纸上得来终觉浅,绝知此事要躬行。
在前两章中,我们已经较为全面的学习了理论。现在,我们将编写一个完整的内核模块,来验证 kobject 的整个生命周期。
本次实战基于 Linux 6.14 内核,由于内核 API 的变化,代码中关于属性定义的部分使用了最新的 default_groups 接口,这与老版本使用的 default_attrs有所不同。
本章我将会把核心代码分为几个部分,逐个进行分析,最后附上完整的可以直接编译运行的代码。
3.1 定义宿主结构体
正如第一章所说,kobject 是嵌入式的,我们需要定义一个自己的结构体,把 kobject 塞进去,同时在这个结构体里面放入我们真正想管理的数据。代码如下:
c
struct my_kobj_struct{
int val; //真正关心的数据
struct kobject kobj; //嵌入的kobject
};最终我们将在shell中通过cat和echo命令来读取或者修改这个val。
3.2 实现 sysfs 读写逻辑
用户在终端使用 cat 和 echo 命令时,内核需要知道该执行怎样的操作,这就是我们这部分要实现的功能。
这里最关键的是 container_of,内核只会传给我们 kobject 指针,我们需要反推出 my_kobj_struct 的地址,然后才能访问 val。
代码如下:
c
//实现读操作
static ssize_t val_show(struct kobject *kobj,struct kobj_attribute *attr,char *buf)
{
struct my_kobj_struct *obj;
obj = container_of(kobj,struct my_kobj_struct,kobj);//通过kobject地址找到宿主结构体地址
return sprintf(buf,"%d\n",obj->val);
}
//实现写操作
static ssize_t val_store(struct kobject *kobj,struct kobj_attribute *attr,const char *buf,size_t count)
{
struct my_kobj_struct *obj;
int ret;
obj = container_of(kobj,struct my_kobj_struct,kobj);
//将字符串转化为整数
ret = kstrtoint(buf,10,&obj->val);
if(ret < 0)
{
return ret;
}
return count;
}
注意这里的两个函数是依据我们 2.1 节截图中的函数原型进行编写的。
上面的读操作对应用户空间的cat命令,写操作对应用户空间的echo命令,当用户空间执行相应的命令时,内核便会调用对应的函数。
我们需要先了解container_of这个宏到底干了什么事情,它定义在include/linux/kernel.h文件中,如下:
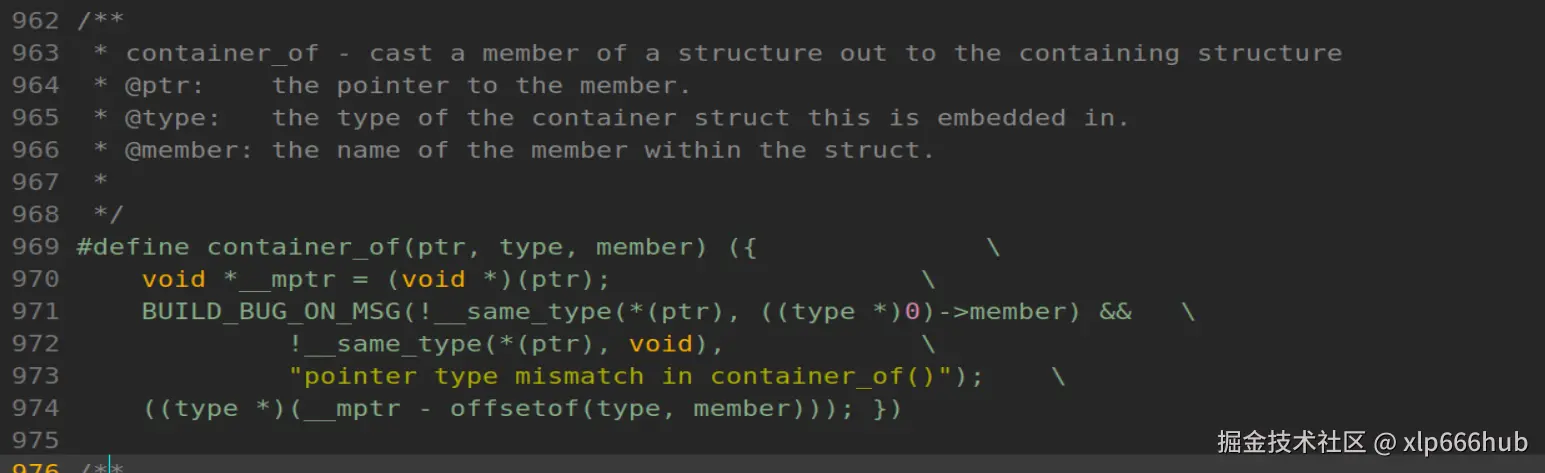
它有三个参数,第一个参数是ptr,它是指向结构体中成员的指针 ,这里是kobj的地址,是内核通过函数参数传递进来的。
第二个参数是type,是宿主结构体的类型 ,这里是struct my_kobj_struct。
第三个参数是member,是成员在结构体中的名字 ,这里是kobj。
这个宏的作用是通过kobj的地址,得到包含kobj的宿主结构体struct my_kobj_struct的地址。拿到了宿主结构体的指针 obj,我们就可以畅通无阻地访问 obj->val 了。
对于这个宏具体的解释,在我前面的文章《链表与它在 Linux 内核中的实现》中讲过,这里我们只需要会使用它就行了,就不再过多讲解它的原理了,感兴趣的话可以去看看我前面那篇文章。
现在我们回到上面的读函数 的具体代码,首先定义了一个struct my_kobj_struct类型的指针obj,然后使用container_of宏通过kobj的地址得到struct my_kobj_struct结构体的地址,并传给obj。最后return sprintf(buf,"%d\n",obj->val),其实可以分为两步来看,第一步,把%d替换为obj->val,然后再把这个字符串整体放到buf里面。第二步,执行return,我们知道sprintf的返回值是写入成功的字符个数,这个字符个数会返回给调用这个函数的人,也就是sysfs内核核心层。
这里实际上与我们常见的应用层函数还是有些区别的,这里函数的调用者是内核 ,参数也是内核传递进来的,buf正是内核 在调用show 函数之前,专门分配好的一块内存(通常是一个内存页,PAGE_SIZE,即 4096 字节),内核把这块内存的首地址传函数,然后sprintf函数把字符串存放在这块内存里面,最终显示给用户看。
我们接下来看一下写函数 ,前面还是一样的逻辑,用container_of宏得到宿主结构体的地址。然后需要用kstrtoint将字符串转化为整数,这个函数名非常形象,即kernel string to int,就是在内核中使用的将字符串转化成整数的函数 。为什么要把字符串转化为整数呢?事实上,当我们在 shell 中使用echo命令向文件中写入数字时,shell 会将它以字符串的形式传递给内核,但是好在它并没有直接写入到文件中,而是被内核给拦截下来了,存放在了我们上面讲过的预先分配好的内存中,再将它以参数的形式传递给我们的函数,从而使得我们在这个函数中能够把它转化为我们需要的int类型,并写入文件中。
这就是sysfs的读写函数的逻辑。
3.3 属性定义与打包
这部分我们需要把读写函数包装成文件,并最终打包成组。
c
//定义属性文件的名称和权限(名称:val,权限:rw-r--r--)
static struct kobj_attribute val_attribute = __ATTR(val,0644,val_show,val_store);
//属性数组,一般是多个属性,这里只放一个
static struct attribute *attrs[] = {
&val_attribute.attr,
NULL, //必须以NULL结尾
};
//把属性数组打包进一个group
static const struct attribute_group attr_group = {
.attrs = attrs,
};
//定义group数组
static const struct attribute_group *attr_groups[] = {
&attr_group,
NULL,
};
我们来看一下__ATTR这个宏,它定义在include/linux/sysfs.h中:

第一个参数name,表示在 /sys 目录下生成的文件名。第二个参数是文件权限。对于第三个参数,只要有人读取这个文件,就会调用这个参数对应的函数。第四个参数与第三个参数原理相同。
这个宏实际上用于简化 struct kobj_attribute 的初始化,可以类比为注册的过程,在/sys目录下注册一个名为name的文件,他的权限是所有者可以读写,其他人只能读,当有人读这个文件时,调用这个函数,有人写这个文件时调用那个函数。
后面就是标准的打包动作,没什么要讲的。
3.4 定义 ktype
c
//release回调,引用计数归零时,这个函数被内核自动调用
static void my_release(struct kobject *kobj)
{
struct my_kobj_struct *obj;
obj = container_of(kobj,struct my_kobj_struct,kobj);
printk(KERN_INFO "kobject_demo: Release 被调用,正在释放内存\n");
kfree(obj);//这是真正释放内存的地方
}
//定义ktype
static struct kobj_type my_ktype = {
.release = my_release,
.sysfs_ops = &kobj_sysfs_ops, //使用默认的sysfs操作
.default_groups = attr_groups, //指定默认创建哪些属性文件
};在定义ktype之前我们要写好回调函数,这个回调函数很容易理解,就是当一个kobject的引用计数归零时,内核调用它对应的release回调函数并把该kobj的地址作为参数传递进来 。而在函数内部通过该kobject的地址使用container_of宏找到宿主结构体的地址,这个过程已经讲过很多遍了,找到后直接使用kfree释放掉就行了。
再下面就是重头戏,定义ktype。刚才可能会有人疑惑,为什么kobject的引用计数归零了,内核就知道要调用我们的my_release函数呢?答案就在这,前面第二章我们就讲过,ktype就是用来控制行为逻辑 的,当引用计数归零后,内核知道要执行release回调函数了,但他并不知道所谓的回调函数在哪,我们的ktype告诉它,回调函数就是my_release。
再看sysfs_ops,我们要知道,Linux 内核是分层设计的,Sysfs 核心层 (VFS)只知道有人在读写文件,但它不知道这个文件对应的 kobject 具体是用什么方式来处理读写的,而sysfs_ops 就是那个通用的接口标准 。kobj_sysfs_ops是内核提供的一个默认实现,这里讲原理比较抽象,我来打个比方把:
假如你现在在终端执行cat命令,sysfs核心 知道你想读取val这个文件(前面__ATTR宏中把val定义为文件名),然后它会找到val对应的kobject(前面也讲过,内核只认识kobject),然后它会去找这个kobject对应的ktype,我们前面也说过,每个kobject必须要有一个对应的ktype,因为用户空间的每一个操作都要有对应的行为逻辑。当sysfs核心 找到ktype时,他会问 "有人要读val这个文件,这事归谁管?" 由于我们定义的是默认的&kobj_sysfs_ops,ktype就会说归kobj_sysfs_ops管,然后这个kobj_sysfs_ops就会找到val的属性定义,也就是我们 3.3 节写的val_attribute,他发现这个属性指定了读文件要去找val_show函数,于是内核就会调用val_show函数。
也就是说,sysfs_ops 是连接用户发起的标准 read 请求 和 驱动开发者自定义的 val_show 函数之间的桥梁。如果没有它,内核就不知道该去调用哪一个函数。
再来说说第三个成员,这个可以理解为一份清单,里面可以包含多个属性文件,attr_groups是我们上一节编写的,我们非常清楚里面只有一个名为val的属性文件。而default_groups告诉内核,在注册这个kobject的时候,顺便把里面的属性文件,也就是val一次性建好。
3.5 模块初始化与退出
c
static struct my_kobj_struct *my_obj;
static int __init my_kobj_init(void)
{
int retval;
printk(KERN_INFO "kobj_demo: 模块加载中...\n");
//动态分配内存,必须用kzalloc
my_obj = kzalloc(sizeof(*my_obj),GFP_KERNEL);
if(!my_obj)
{
return -ENOMEM;
}
//初始化数据
my_obj->val = 1207;
//初始化并添加到内核
//参数一:kobject指针 参数二:ktype指针 参数三:父kobject 参数四:目录名称
retval = kobject_init_and_add(&my_obj->kobj,&my_ktype,kernel_kobj,"my_kobject_example");
if(retval)
{
kobject_put(&my_obj->kobj);
return retval;
}
kobject_uevent(&my_obj->kobj,KOBJ_ADD);
return 0;
}
static void __exit my_kobj_exit(void)
{
printk(KERN_INFO "kobj_demo: 模块卸载...\n");
kobject_put(&my_obj->kobj);
}
module_init(my_kobj_init);
module_exit(my_kobj_exit);这里为了保证kobject的生命周期,定义了一个全局的my_obj指针。
模块初始化函数中为my_obj分配内存时,必须要使用kzalloc,kzalloc比kmalloc多做了一件事,那就是把申请到的内存全部清零 。为什么要全部清零呢?请看结构体的第二个成员,是struct kobject kobj,它的内部极其复杂,而我们又只使用了它的一部分成员,如果不将其他没有使用到的成员内存清 0,可能会导致访问非法内存,从而使程序崩溃。
对于kobject_put函数,它的作用是将引用计数减 1 ,内核会进行检查,如果计数变为 0,立即调用 my_ktype->release,如果不是 0,则什么都不做,这保证了谁最后用完谁释放内存。
我们来看kobject_init_and_add这个函数,这个函数是 kobject 生命的起点,它把kobject初始化并添加到 Sysfs 。第一个参数&my_obj->kobj表示要初始化的对象的地址,就填宿主结构体中的kobject成员的地址就行了。第二个参数&my_ktype用来指定这个kobject对应的ktype。第三个参数kernel_kobj用来指定父对象,这里填kernel_kobj,意味着我们的目录会出现在 /sys/kernel/ 下面,如果填 NULL,它就会出现在 /sys/ 的目录下。第四个参数是最终生成的目录名称。要注意的是,由于我们已经为kobject申请好了内存,如果初始化这步失败了,也要用kobject_put触发release从而释放内存。
my_kobj_exit这个函数就没什么要注意的点了,直接my_kobj_exit就行了。
最后将模块初始化与退出函数进行注册,就完成了。
3.6 完整代码清单
完整代码如下,新版的 Linux 内核可以直接拿去编译运行。
c
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/kobject.h>
#include <linux/sysfs.h>
#include <linux/slab.h>
#include <linux/string.h>
//定义宿主结构体
struct my_kobj_struct{
int val; //真正关心的数据
struct kobject kobj; //嵌入的kobject
};
//实现读操作
static ssize_t val_show(struct kobject *kobj,struct kobj_attribute *attr,char *buf)
{
struct my_kobj_struct *obj;
obj = container_of(kobj,struct my_kobj_struct,kobj);//通过kobject地址找到宿主结构体地址
return sprintf(buf,"%d\n",obj->val);
}
//实现写操作
static ssize_t val_store(struct kobject *kobj,struct kobj_attribute *attr,const char *buf,size_t count)
{
struct my_kobj_struct *obj;
int ret;
obj = container_of(kobj,struct my_kobj_struct,kobj);
//将字符串转化为整数
ret = kstrtoint(buf,10,&obj->val);
if(ret < 0)
{
return ret;
}
return count;
}
//定义属性文件的名称和权限(名称:val,权限:rw-r--r--)
static struct kobj_attribute val_attribute = __ATTR(val,0644,val_show,val_store);
//属性数组,一般是多个属性,这里只放一个
static struct attribute *attrs[] = {
&val_attribute.attr,
NULL,
};
//把属性数组打包进一个group
static const struct attribute_group attr_group = {
.attrs = attrs,
};
//定义group数组
static const struct attribute_group *attr_groups[] = {
&attr_group,
NULL,
};
//release回调,引用计数归零时,这个函数被内核自动调用
static void my_release(struct kobject *kobj)
{
struct my_kobj_struct *obj;
obj = container_of(kobj,struct my_kobj_struct,kobj);
printk(KERN_INFO "kobject_demo: Release 被调用,正在释放内存\n");
kfree(obj);//这是真正释放内存的地方
}
//定义ktype
static struct kobj_type my_ktype = {
.release = my_release,
.sysfs_ops = &kobj_sysfs_ops, //使用默认的sysfs操作
.default_groups = attr_groups, //指定默认创建哪些属性文件
};
static struct my_kobj_struct *my_obj;
static int __init my_kobj_init(void)
{
int retval;
printk(KERN_INFO "kobj_demo: 模块加载中...\n");
//动态分配内存,必须用kzalloc
my_obj = kzalloc(sizeof(*my_obj),GFP_KERNEL);
if(!my_obj)
{
return -ENOMEM;
}
//初始化数据
my_obj->val = 1207;
//初始化并添加到内核
//参数一:kobject指针 参数二:ktype指针 参数三:父kobject 参数四:目录名称
retval = kobject_init_and_add(&my_obj->kobj,&my_ktype,kernel_kobj,"my_kobject_example");
if(retval)
{
kobject_put(&my_obj->kobj);
return retval;
}
kobject_uevent(&my_obj->kobj,KOBJ_ADD);
return 0;
}
static void __exit my_kobj_exit(void)
{
printk(KERN_INFO "kobj_demo: 模块卸载...\n");
kobject_put(&my_obj->kobj);
}
module_init(my_kobj_init);
module_exit(my_kobj_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("XLP");3.7 编译方法
完整的 Makefile 文件如下:
makefile
obj-m += kobj_demo.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean对于内核模块来说,它的 Makefile 和普通 C 语言应用程序的 Makefile 完全不同。普通 C 语言的 Makefile 是自己调用 gcc,而内核模块的 Makefile 本质上是调用内核源码树里的构建系统来编译代码。
在编写完驱动代码后,我们需要将其编译成 .ko (Kernel Object) 文件 。由于内核模块是运行在内核空间的,它不能像普通 C 程序那样直接用 gcc 编译,而必须使用内核提供的构建系统 ,也就是 Kbuild。
下面解析一下这个 Makefile 代码:
首先看第一行,obj-m表示要把后面的目标编译成内核模块 ,最终生成 .ko 文件。+=表示追加。还有目标文件的后缀是.o而不是.c,这是因为 Kbuild 会自动寻找同名的 .c 源文件,将其编译并链接。
all下面的命令才是真正的编译动作,-C告诉 make 工具切换到后面指定的目录去执行 ,$(shell uname -r)是一个 Shell 命令,用来获取当前运行的内核版本号。/build是一个软链接,指向内核源码的头文件和构建脚本所在的位置。
如下图:
请注意我当前所在的目录和 Makefile 中要跳转的目录是相同的,而且可以看到 build 是一个软链接。最终会到这个软链接指向的目录中去干活。
M=$(PWD),M 是内核 Makefile 定义的一个变量,代表 External Module(外部模块) 的路径。$(PWD)代表当前目录。意思是虽然要去上面软链接指定的目录中去编译,但是源文件和编译后生成的文件都要放在当前目录下。
modules是内核 Makefile 里的一个目标,专门用来编译模块。
clean是清理命令,和上面的编译命令原理相同。
在上面编写测试程序的目录下,编写文件名为 Makefile 的文件,并把上面的内容复制进去,然后在命令行使用 make 即可开始编译。
4. 运行结果验证
代码编写完毕,Makefile 也准备好了,现在我们准备编译并验证运行结果。
4.1 编译
在命令行执行 make 命令:
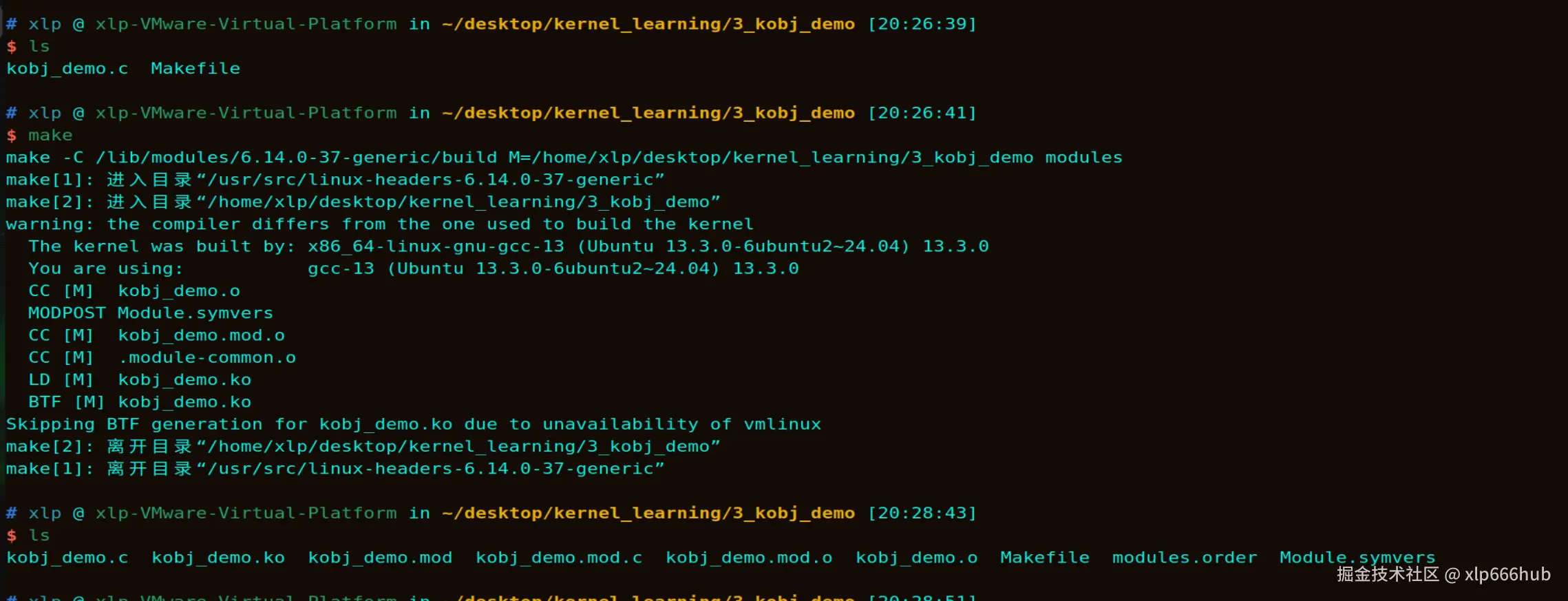
可以看到,在编译之前我们只有 c 源文件和 Makefile 文件。编译成功后当前目录下多出了许多文件,请看第二个文件,这就是我们需要的.ko文件。
4.2 加载模块
编译成功后,我们使用下面命令加载模块:
c
sudo insmod kobj_demo.ko加载成功后,我们可以通过 ls 命令查看 /sys/kernel 目录下是否生成了我们指定的目录,执行结果如下:
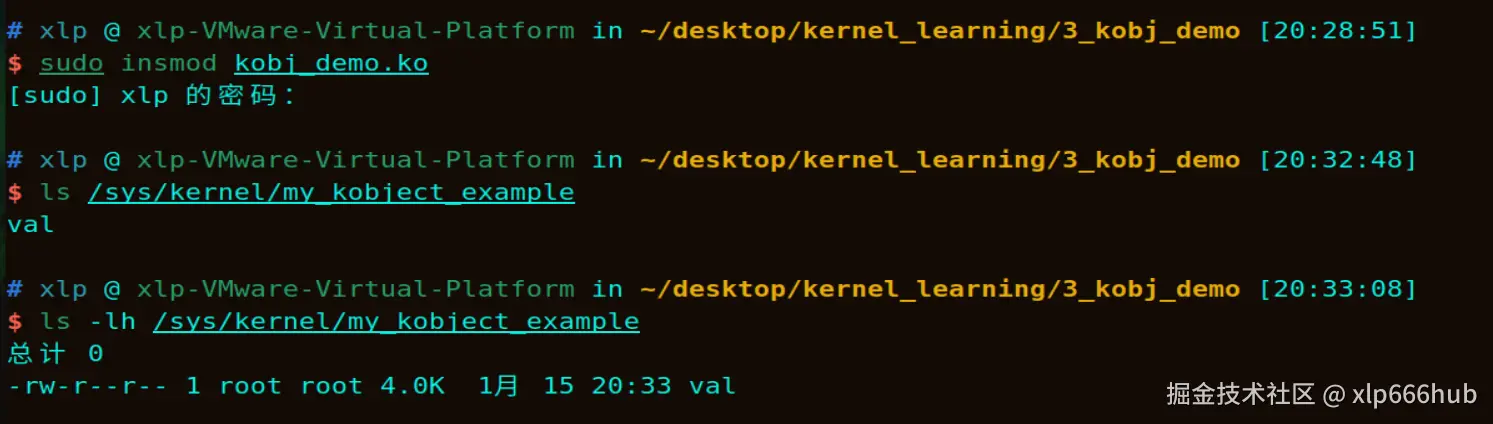
可以看到,/sys/kernel/ 下确实出现了一个名为 my_kobject_example 的目录,并且该目录下已经生成了我们的属性文件val,并且该属性文件的权限也和我们在程序中配置的一模一样。
my_kobject_example目录的出现验证了 kobject_init_and_add 函数已经执行成功。
val 文件的出现验证了 ktype 中的 default_groups 属性组生效了,正如前面所讲,内核在注册对象的同时自动帮我们创建了这个属性文件。
4.3 Sysfs 读写测试
下面先使用cat命令查看一下val文件:

可以看到,输出为1207,这个和我们程序中初始化的val的值是一样的。
我们使用下面echo命令修改一下val的值,在进行读取试试:
bash
echo 999 | sudo tee /sys/kernel/my_kobject_example/val竖线是管道符,它的作用是把左边 命令的输出,变成右边 命令的输入。tee这个命令可以把内容写入 到指定的文件中的同时,并且把内容打印到屏幕上。这也是我们执行这条命令后屏幕会出现 999 的原因。

到这,读写测试就完成了。
当我们执行 cat 时,终端输出了 1207,这说明内核成功调用了我们的 val_show 函数。
当我们执行 echo 999 时,再次读取变成了 999,这证明 val_store 函数被调用,且成功修改了内存中的值。
最重要的是这证明了 container_of 宏的强大,内核只给了我们一个 kobject 指针,但我们成功通过它找回了 my_kobj_struct 结构体,并访问到了里面的 val 变量。
4.4 生命周期与内存释放
在进行操作之前我们先来查看一下日志,可以看到,我们在程序中用printk打印的模块加载中的内容已经被成功打印到了内核日志中。
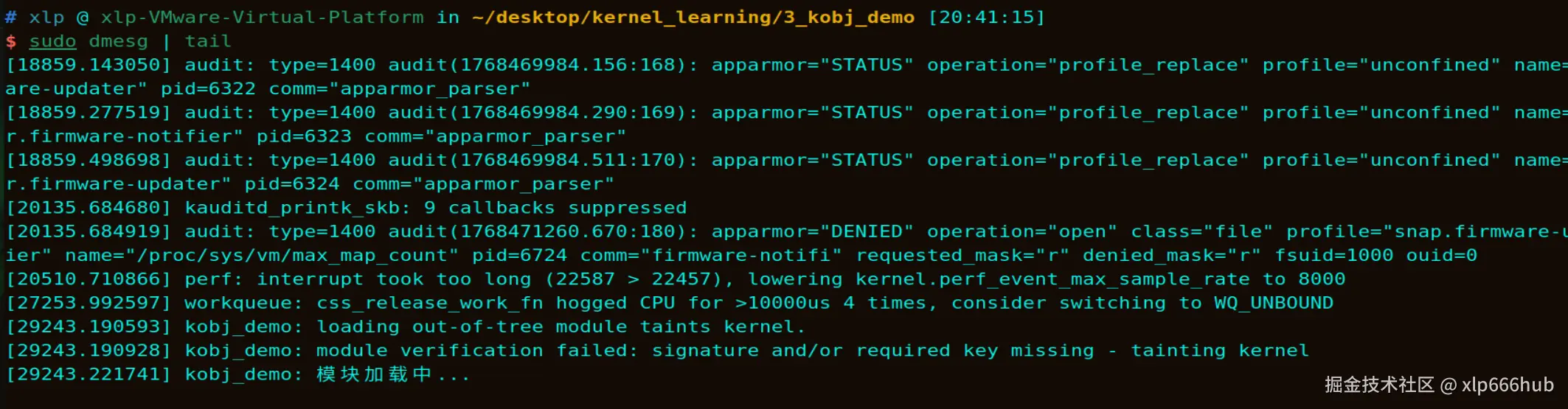
我们打开一个新的窗口,使用sudo dmesg -w命令实时查看内核日志。然后在原来的窗口卸载模块:
bash
sudo rmmod kobj_demo
可以看到,日志中出现了我们程序中卸载模块时要打印的内容,并且由于只有我们在使用这个模块,引用次数为1,卸载之后调用kobject_put将引用次数减一,引用次数变为 0,然后内核调用了release函数,成功释放内存。
5. 总结
至此,我们完成了对 Linux 内核中相当抽象的一个内容kobject的拆解。
回首望去,从刚开始面对 kobject.txt 时的不知所措,到深入源码剖析 ktype 与 sysfs_ops 是怎样联动的,再到最后构建出一个驱动对象并成功运行,这个过程本身就是对内核设计哲学的深度理解。
在现在的驱动开发中,我们有现成的 platform_device,有成熟的 Device Tree,有封装完美的 USB 和 PCI 子系统,我们几乎永远不需要亲手去写 kobject_init,那学习它的意义何在?
打个比方把,如果把 Linux 驱动开发比作练武,那么会调用 device_register 这样的 API 仅仅只是学会了招式,而彻底理解 kobject的工作原理,才是修炼了内功。要知道,一个人要想达到触类旁通的境界,往往是需要很深厚的内功的。
知其然,更要知其所以然。