论文标题:Latent Space Super-Resolution for Higher-Resolution Image Generation with Diffusion Models
论文原文 (Paper) :https://arxiv.org/abs/2503.18446
代码 (code) :https://github.com/3587jjh/LSRNA
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
超分辨率重建(代码实践) | CVPR 2025 LSRNA:利用隐空间超分与噪声对齐,打破扩散模型生成 4K 图像的效率瓶颈
目录
-
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
-
- [2.1 文本背景总结](#2.1 文本背景总结)
- [2.2 动机图解分析](#2.2 动机图解分析)
- [3. 主要创新点](#3. 主要创新点)
- [4. 方法细节](#4. 方法细节)
-
- [4.1 整体网络架构](#4.1 整体网络架构)
- [4.2 核心创新模块详解](#4.2 核心创新模块详解)
- [4.3 理念与机制总结](#4.3 理念与机制总结)
- [4.4 图解总结](#4.4 图解总结)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验部分简单分析](#6. 实验部分简单分析)
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
-
1. 核心思想
本文提出了一种名为 LSRNA (Latent Super-Resolution with Noise Alignment) 的新框架,旨在解决现有扩散模型(如 SDXL)在生成超越训练分辨率(如 4K)图像时面临的计算成本高和结构一致性差的问题。其核心策略是将超分辨率(SR)过程从像素空间转移到隐空间(Latent Space) ,通过训练一个轻量级的隐空间超分网络来快速提升分辨率,并设计了**噪声对齐(Noise Alignment, NA)**机制来解决上采样后的潜变量与预训练扩散模型分布不匹配的问题。该方法在保持生成质量(避免重复纹理和结构崩坏)的同时,将推理速度相比 SOTA 方法(如 DemoFusion)提升了约 3倍。
2. 背景与动机
2.1 文本背景总结
目前,基于扩散模型的图像生成(如 Stable Diffusion)在标准分辨率(512x512 或 1024x1024)下效果惊人。然而,当试图生成更高分辨率(如 2K, 4K)时,主要面临两类方法及其局限:
- 级联生成与像素级 SR(Cascaded / Pixel-SR) :先生成低分图,再用超分模型(如 ESRGAN)放大。
- 问题:传统 SR 模型容易产生油画感伪影,且无法"无中生有"地补充生成式的高频细节。
- 基于 Patch 的多重扩散(Patch-based Diffusion, e.g., DemoFusion) :将大图切块,利用预训练模型分别去噪并融合。
- 问题:推理速度极慢(计算量随分辨率线性或超线性增长);容易出现"多头怪"、"重复纹理"等结构不一致问题(缺乏全局一致性)。
2.2 动机图解分析
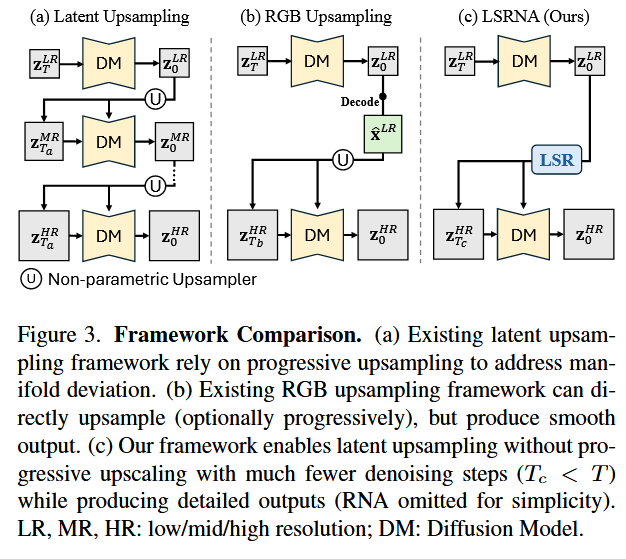
看图说话与痛点分析:
- 左侧 (Existing Methods):观察 DemoFusion 和 Pixelsmith 的生成结果,你会发现明显的**"语义重复" (Repeating Patterns)** 现象。例如,生成一个人物时,可能会出现两个头或者身体结构错乱。这是因为基于 Patch 的方法缺乏全局的语义把控,模型在局部 Patch 中"自作主张"地生成了独立的主体。
- 中间 (Pixel-space SR):如果直接使用像素级超分(如 SwinIR),虽然结构对了,但纹理细节显得僵硬、不自然,缺乏扩散模型特有的真实感和细腻度。
- 右侧 (Ours - LSRNA):本文方法生成的图像既保持了全局结构的连贯性(没有多头),又拥有丰富且自然的生成式细节。
- 核心问题引出:这幅图直观地揭示了**"全局结构一致性"与"生成效率"之间的矛盾**。本文试图通过在隐空间进行一次性的全局上采样,来彻底解决 Patch 分割带来的结构断裂问题。
3. 主要创新点
- LSRNA 框架:首创性地提出在隐空间(Latent Space)进行超分辨率,以此作为高分辨率生成的初始化,替代了昂贵的级联去噪或 Patch 融合过程。
- 轻量级隐空间超分网络 (LSR Module):设计了一个专门针对 VAE 潜变量(Latent codes)的轻量级上采样网络,能够从低分辨率潜变量中恢复高频语义信息。
- 频率感知噪声对齐 (Frequency-aware Noise Alignment, NA):发现并解决了隐空间上采样带来的"域偏移"问题。通过在频域对齐上采样潜变量与高斯噪声的统计分布,确保其能被预训练的扩散模型无缝接纳进行后续精修(Refinement)。
- 高效推理 :在生成 4K 图像时,相比 DemoFusion 减少了约 66% 的推理时间,且无需复杂的 prompt 工程即可实现高质量生成。
4. 方法细节
4.1 整体网络架构
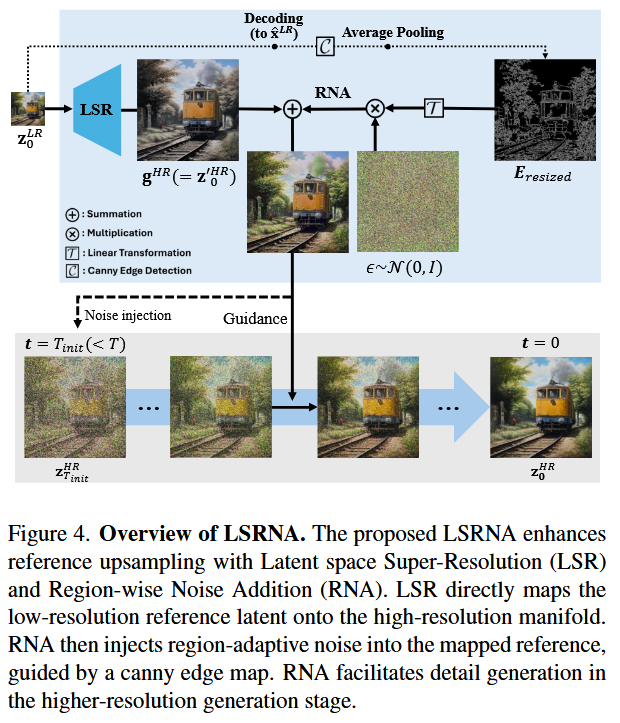
数据流详解 :
LSRNA 是一个即插即用的增强框架,其完整数据流如下:
- 低分辨率生成 (LR Generation) :
- 首先利用 SDXL 在标准分辨率(如 1024 2 1024^2 10242)下生成一个低分辨率的潜变量 z L R z_{LR} zLR。这一步确定了图像的全局构图和内容。
- 隐空间超分 (Latent Super-Resolution) :
- 将 z L R z_{LR} zLR 输入到训练好的 LSR 模块中。
- LSR 模块将潜变量的空间分辨率放大(例如 4倍),输出高分辨率潜变量 z S R z_{SR} zSR。此时, z S R z_{SR} zSR 包含了放大的语义特征。
- 噪声对齐 (Noise Alignment) :
- z S R z_{SR} zSR 直接送入扩散模型会因为分布不匹配导致生成失败。因此,通过 NA 模块 对 z S R z_{SR} zSR 进行频域调整,使其符合扩散模型在特定时间步 t t t 的输入分布,得到对齐后的潜变量 z ^ S R \hat{z}_{SR} z^SR。
- 高分辨率精修 (HR Refinement) :
- 将 z ^ S R \hat{z}_{SR} z^SR 作为初始状态(加上部分噪声),送入预训练的 SDXL 模型进行少量的去噪步数(Refinement Steps)。由于不需要从纯高斯噪声开始,这步极快。
- 输出 (Output) :
- 最后通过 VAE Decoder 将精修后的潜变量解码为像素图像。
4.2 核心创新模块详解
模块 A:隐空间超分网络 (Latent Super-Resolution, LSR)
- 内部结构 :
- 这就好比一个专门为 Latent Code 设计的"ESRGAN"。它由堆叠的残差块 (Residual Blocks) 和 上采样层 (PixelShuffle/Transposed Conv) 组成。
- 输入是 4通道的 z L R z_{LR} zLR,输出是 4通道的 z S R z_{SR} zSR。
- 流动机制 :
- 数据在残差块中流动以提取深层特征,然后通过上采样层扩展空间维度。
- 设计目的 :
- VAE 的 Encoder/Decoder 是有损的。如果在像素空间做 SR 再 Encode 回去,会损失大量语义信息。在隐空间直接操作可以保留更多用于生成的语义线索。
模块 B:噪声对齐 (Noise Alignment, NA)
- 设计理念 :
- 扩散模型是在标准高斯分布噪声上训练的。经过 LSR 网络上采样出来的潜变量 z S R z_{SR} zSR,其频率响应(尤其是高频部分)与扩散模型预期的分布存在巨大差异(Domain Gap)。如果不处理,扩散模型会把这些差异误认为是"内容"而非"噪声",导致生成伪影。
- 工作机制 :
- 频域分解 :使用快速傅里叶变换 (FFT) 将 z S R z_{SR} zSR 转换到频域。
- 统计对齐 :根据扩散模型在当前时间步 t t t 的理论信噪比(SNR),调整 z S R z_{SR} zSR 各个频段的均值和方差,使其匹配标准分布。
- 逆变换:通过 IFFT 转换回空间域。
- 作用 :它像一个"适配器",欺骗扩散模型,让它觉得输入的 z S R z_{SR} zSR 是一个合法的、带噪声的中间状态,从而顺利进行后续的去噪。
4.3 理念与机制总结
LSRNA 的核心理念是 "先全局铺陈,后局部精修"。
- 机制:利用低分辨率生成步骤锁定全局结构(解决"多头"问题),利用隐空间 SR 快速填充信息空白(解决"速度"问题),利用噪声对齐确保兼容性,最后利用扩散模型本身的先验进行纹理"脑补"。
- 公式解读 :
z H R = Refine ( Align ( LSR ( z L R ) ) , t ) z_{HR} = \text{Refine}(\text{Align}(\text{LSR}(z_{LR})), t) zHR=Refine(Align(LSR(zLR)),t)
这个流程避免了从 t = T t=T t=T(纯噪声)开始的高分辨率去噪,而是从 t = t m i d t=t_{mid} t=tmid 开始,大大缩短了路径。
4.4 图解总结
回到动机图解(图2):
- LSRNA 通过 z L R z_{LR} zLR 锁定了全局结构,所以不会出现左图 DemoFusion 那样的结构崩坏。
- LSRNA 通过扩散模型的 Refinement,注入了生成式细节,所以不会出现中图 Pixel-SR 那样的油画感。
- NA 模块确保了这一流程的顺畅流转,解决了潜在的分布不匹配问题。
5. 即插即用模块的作用
LSRNA 具有极强的扩展性和通用性:
- 适用场景 :
- 文生图 (Text-to-Image):直接提升 SDXL / SD 1.5 的生成分辨率上限。
- 图生图 (Image-to-Image):可以配合 ControlNet 使用,实现 4K 级别的受控生成。
- 具体应用 :
- 老照片修复与增强:利用其生成能力修复低清照片细节。
- 商业海报生成:快速生成可直接打印级别的超高清素材,无需漫长的等待。
- 实时预览:由于速度快,可以在用户调整 prompt 时提供较高分辨率的预览。
6. 实验部分简单分析
论文在 COCO 和各类高分辨率数据集上进行了对比实验。
-
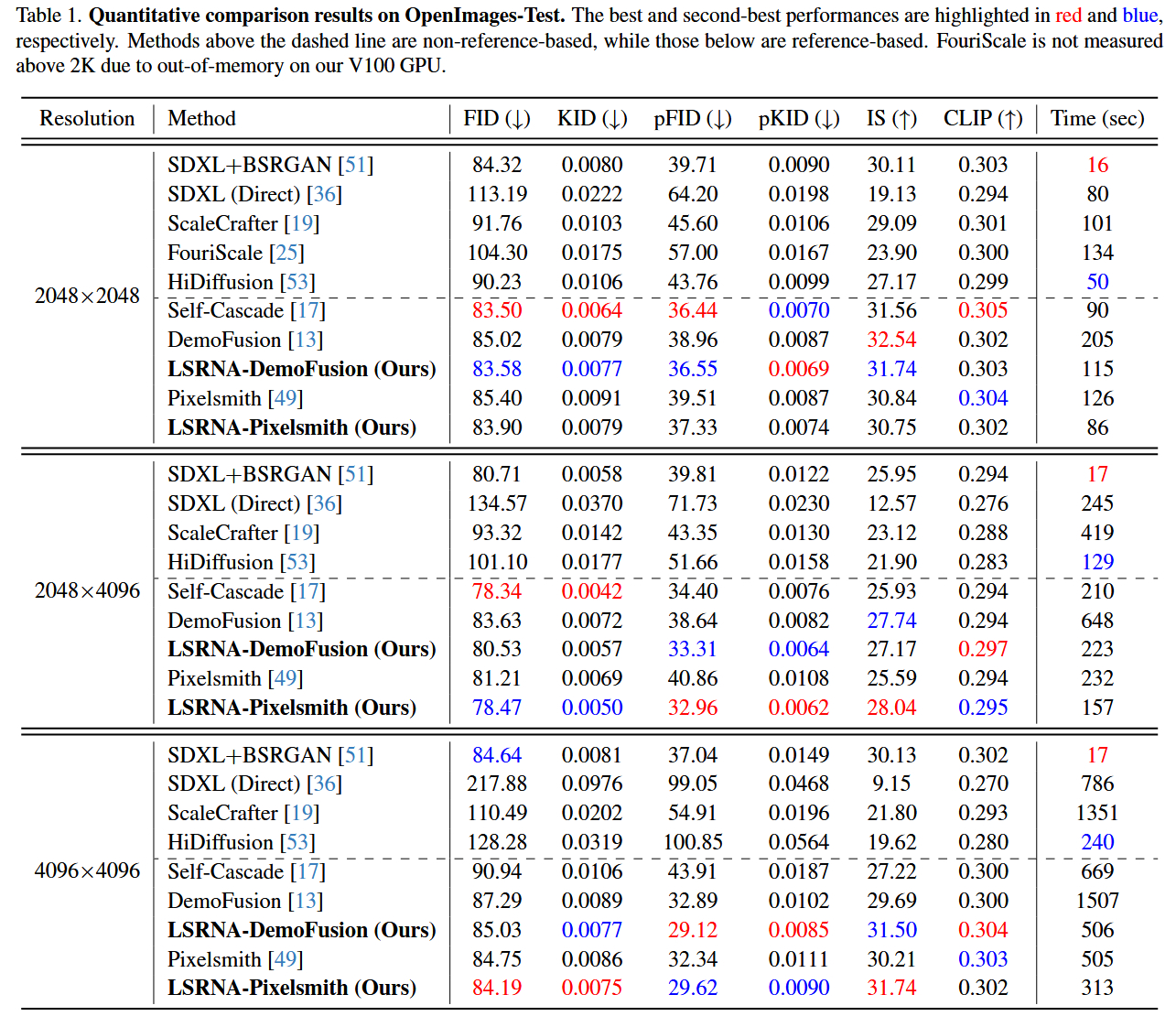
定量对比:
- 速度 :生成 4096×4096 图像,LSRNA 耗时仅为 DemoFusion 的 34% ,Pixelsmith 的 62%。这是一次巨大的效率提升。
- 质量指标:在 FID (Fréchet Inception Distance) 和 CLIP Score 上,LSRNA 均优于对比方法,说明生成的图像更真实且更符合文本描述。
-
定性对比:
- 可视化结果显示,LSRNA 生成的纹理(如毛发、织物)更加锐利自然,且没有出现 Patch 边界的接缝感或重复物体。
-
消融实验:
- 去除 Noise Alignment 后,生成的图像充满了噪点和怪异的颜色块,证明了 NA 模块对于跨尺度隐空间生成的必要性。
- 去除 LSR 模块(直接插值上采样),图像变得模糊,细节严重缺失。
总结 :LSRNA 是一篇非常扎实的工作,它跳出了"怎么切 Patch"的思维定式,回头重新审视了 Latent Space 的可操作性。通过引入传统的 SR 思想并结合频域分析,巧妙解决了扩散模型扩图难的问题。对于关注 AIGC 落地 和 高分辨率生成 的同学来说,这篇论文提供了非常宝贵的思路。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。