这不仅仅是两个模型的比较,更是两种AI范式的对话。
一、 设计哲学:两种世界观
| 维度 | LSTM的世界观 | Transformer的世界观 |
|---|---|---|
| 核心隐喻 | 时间的诗人 :认为世界是动态的、连续的流。理解当下,必须回顾过去,记忆在时间中流淌和演变。 | 空间的建筑师 :认为世界是静态的、关联的网络。理解整体,必须洞察所有部分之间的结构关系。 |
| 对序列的理解 | 严格的因果序 :序列是依序发生的事件链。第 t 时刻的状态是理解第 t+1 时刻的前提。 |
全连接的图 :序列是一组同时存在、彼此关联的节点。任何两个节点间都可以直接建立联系,顺序只是图的一个属性。 |
| 关键约束 | 信息必须通过"瓶颈"传递:历史信息被压缩在固定长度的隐状态向量中,在每一步传递,形成信息瓶颈。 | 位置信息必须显式注入 :模型自身没有顺序概念,必须通过位置编码 从外部告知"谁在前,谁在后"。 |
二、 核心机制:信息流动的解剖
1. LSTM:门控的精密流动
LSTM像一个带有精密控制阀的水库系统,其核心在于 "门" 对信息流的调控:
-
遗忘门 :决定上一时刻的长期记忆
C_t-1有多少需要被丢弃。 -
输入门 :决定当前时刻的新信息有多少需要被写入长期记忆。
-
输出门 :基于当前输入和新的长期记忆,决定当前的输出(隐状态) 是什么。
-
流程 :
(h_t-1, C_t-1)-> 遗忘/输入 -> 更新为C_t-> 输出 ->h_t。这个过程必须串行。
2. Transformer:注意力的全局关联
Transformer像一个高度互联的议会,其核心是 "自注意力" 的并行计算:
从 "输入" 开始就分道扬镳,贯穿了完全不同的核心计算单元 ,最终导致了它们对硬件利用的天壤之别,并因此奠定了各自在AI发展史上的不同角色:
-
Query, Key, Value 投影 :每个词元被映射为三组向量,代表其"诉求 "、"身份 "和"实质信息"。
-
注意力分数 :通过计算所有
Query和所有Key的点积,得到一个N x N的注意力矩阵。它明确表示每个词元应该"关注"其他所有词元的程度。 -
加权聚合 :用注意力权重对所有的
Value进行加权求和,得到每个词元的新表示 。这个新表示直接融合了全局上下文信息。 -
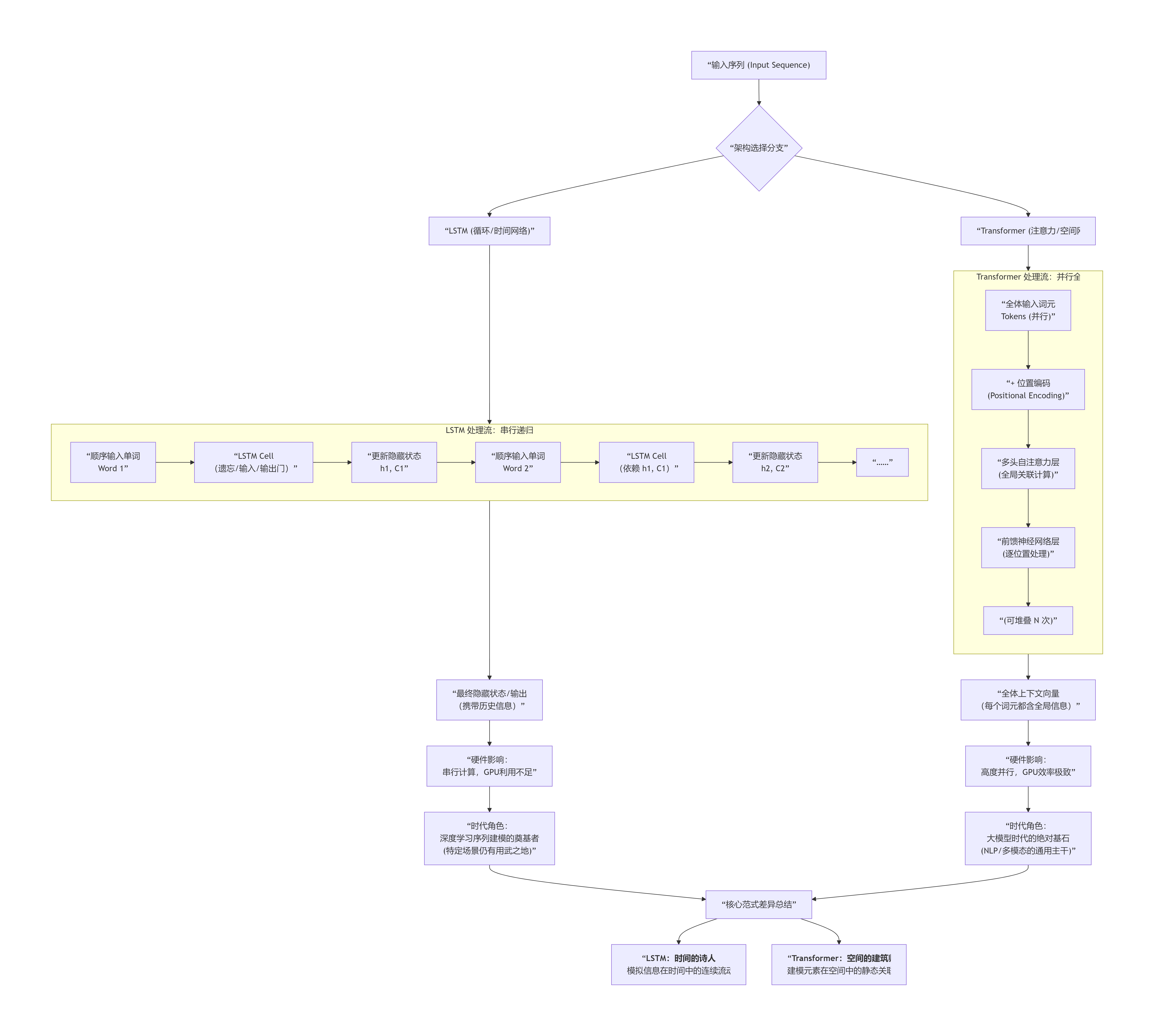
流程关键点解读
上图清晰地揭示了两条截然不同的技术路径:
-
LSTM(左侧路径) 是 "时间驱动" 的。
-
数据必须严格按时间步顺序输入,像一条河流。
-
核心的 LSTM Cell 通过门控机制 ,像一个有选择性的记忆单元,在每一步读取输入、并结合上一步的隐藏状态来更新当前记忆和输出。
-
信息在循环中串行传递,形成了处理长序列的瓶颈,也导致其难以充分利用现代GPU的并行能力。
-
-
Transformer(右侧路径) 是 "空间驱动" 的。
-
所有词元一次性并行输入,像一个静态的网络。
-
首先通过 "位置编码" 为词元注入顺序信息,因为其结构本身没有顺序概念。
-
核心的 "多头自注意力" 层让每个词元瞬间与序列中所有其他词元进行交互,直接计算全局关联。
-
随后通过 "前馈网络" 层对每个位置的独立信息进行加工。这种结构天然适合矩阵并行计算,与GPU硬件完美契合。
-
-
LSTM 作为先驱,证明了循环网络处理序列的强大能力。
-
Transformer 作为新范式 ,以其并行性和全局性,真正释放了规模化计算的潜力,成为当今大模型时代的根基。
三、 硬件亲和性:催生时代的幕后推手
这是Transformer胜出的物理基础,也是理解AI发展的关键。
| 硬件视角 | LSTM:与GPU"天性不合" | Transformer:为GPU"量身定做" |
|---|---|---|
| 并行度 | 序列级并行 :不同序列可以并行,但同一序列内部必须串行计算。GPU的数千核心无法被有效利用。 | 令牌级并行 :序列内所有词元的计算完全独立,可以在矩阵乘法中一次性完成,极度契合GPU的SIMD架构。 |
| 计算类型 | 大量小型、串行的逐元素操作(门控计算),GPU优势不明显。 | 核心是大型、稠密的矩阵乘法,这是GPU的绝对强项。 |
| 内存访问 | 隐藏状态需要频繁读写,内存访问模式不规则。 | 计算高度规整,易于优化,能充分利用高速缓存。 |
| 结果 | 训练一个大型LSTM模型耗时漫长,扩展性差。 | 训练效率呈数量级提升 ,使得在海量数据 上训练千亿参数 的巨型模型成为可能,直接开启大模型时代。 |
四、 生态位:各自统治的疆域
经过技术竞争,二者已形成清晰的疆界。
Transformer主导的"大陆":
-
自然语言处理:所有主流预训练模型的基础,包括BERT(理解)、GPT系列(生成)、T5(统一范式)。
-
多模态学习:如CLIP(图文对齐)、DALL-E(文生图),其核心是处理不同模态的"序列"。
-
大语言模型的基座:ChatGPT、Gemini、LLaMA等一切LLM的骨架。
-
甚至计算机视觉:Vision Transformer已证明,将图像切块视为序列后,注意力机制同样能超越传统的CNN。
LSTM坚守的"岛屿"与"遗产":
-
严格流式应用:实时语音识别、实时股价预测、在线控制系统,其"来一个处理一个"的特性与任务本质匹配。
-
轻量级与边缘部署:在计算和内存受限的IoT设备或手机端,小型LSTM仍有价值。
-
学术与历史价值:门控思想是深度学习的重要遗产,其变体(如GRU)仍有研究价值。
-
特定序列的局部建模:有时作为Transformer架构中的一个组件,用于增强局部特征提取。
五、 系统性对比与决策树
| 特性 | LSTM | Transformer | 胜出方与原因 |
|---|---|---|---|
| 长程依赖 | 弱,易衰减 | 强,直接建模 | Transformer:自注意力机制 |
| 训练速度 | 慢,串行瓶颈 | 极快,完全并行 | Transformer:GPU亲和性 |
| 推断延迟 | 低,可流式输出 | 高,需完整序列 | LSTM:任务特性匹配 |
| 位置感知 | 固有 | 需手动添加 | 平手:Transformer通过编码能更灵活处理位置 |
| 可解释性 | 中等,门控有逻辑 | 较低,注意力图是黑盒 | LSTM(相对) |
| 数据饥渴度 | 较低 | 极高,依赖大数据 | 平手:由任务数据量决定 |
| 工业地位 | 利基市场 | 绝对主流与基石 | Transformer:综合性能与可扩展性 |
最终决策指南 :
当你面临选择时,可以遵循以下逻辑:
-
默认起点 :对于绝大多数问题,首先考虑Transformer或其变体。这是目前取得SOTA性能的最可靠路径。
-
仅当出现以下所有条件时,才考虑LSTM:
-
任务本质是严格实时的流式处理(输入一点,必须立刻输出一点,无法等待未来)。
-
计算和存储资源极其苛刻,无法承担Transformer的复杂度。
-
序列长度非常短,且数据量小,Transformer的优势无法发挥。
-
总结:范式转移的必然
LSTM → Transformer 的演进,本质是从"时间动力学"模型到"空间关系学"模型的范式转移。
这种转移的催化剂是 GPU的并行计算能力 和 互联网时代的海量数据 。Transformer并非在理论上"击败"了LSTM,而是在新的计算环境和数据规模下 ,其全局、并行 的设计哲学与硬件形成了历史性的共振,从而释放了前所未有的潜力,重塑了整个AI领域的发展轨迹。