目录
[1. 先补基础:什么是双目视觉(立体匹配)?](#1. 先补基础:什么是双目视觉(立体匹配)?)
[2. 传统方法的局限 & 现在遇到的 "大麻烦"](#2. 传统方法的局限 & 现在遇到的 “大麻烦”)
2.自适应分组相关层(AGCL)------解决"非理想校正"问题
[3.级联循环网络(Cascaded Recurrent Network)------ 解决 "细薄结构算不准" 问题](#3.级联循环网络(Cascaded Recurrent Network)—— 解决 “细薄结构算不准” 问题)
[4.堆叠级联推理框架(Stacked Cascades for Inference)------ 优化高分辨率图处理](#4.堆叠级联推理框架(Stacked Cascades for Inference)—— 优化高分辨率图处理)
[5.损失函数(Loss Function)------ 训练模型的 "指南针"](#5.损失函数(Loss Function)—— 训练模型的 “指南针”)
[6.新合成数据集(Synthetic Training Data)------ 解决 "难例场景" 问题](#6.新合成数据集(Synthetic Training Data)—— 解决 “难例场景” 问题)
前言
该篇笔记会用通俗的中文,从"什么是双目视觉"开始,一步步让您看懂《CREStereo:Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation》这篇重要论文。原文及代码链接:https://github.com/megvii-research/CREStereo![]() https://github.com/megvii-research/CREStereo
https://github.com/megvii-research/CREStereo
一、先搞懂:这篇论文到底要解决什么问题?
在看这篇论文之前,我们得先明白"双目视觉"到底是干什么的,以及现在研究中遇到了什么麻烦。
1. 先补基础:什么是双目视觉(立体匹配)?
我们可以把双目视觉想象成"用两台相机模拟人的两只眼睛":
①我们用两个相机拍同一场景,得到两张图片(论文里称作"立体图像对",左边的叫左图,右边的叫右图)。
②立体匹配的核心任务:找到左图中的每个像素,在右图里对应的像素(因为两个相机位置不同,对应像素会有"位移"),这个位移叫做"视差(disparity)"。
③有了视差,就能算出物体的深度(距离相机有多远)------这是自动驾驶、手机虚化拍照(背景模糊)、增强显示(AR)这些应用的核心技术。
2. 传统方法的局限 & 现在遇到的 "大麻烦"
传统方法(比如局部匹配、全局匹配)在实际场景中效果不算好,后来出现了基于卷积神经网络(CNN)的方法,精度提升了很多,但在"真实世界使用"时,还是有3个绕不开的问题------这就是论文要解决的核心问题:
问题1:细小组件的视差算不准
真实场景中有很多"细薄结构",比如铁丝网、胡须等,这些东西的像素很少,传统CNN方法要么算不出它们的视差,要么算错,导致深度图有漏洞(比如手机虚化时,铁丝网变成模糊的一团,而不是清晰的立体结构)。随着分辨率越来越高,这个问题更加严重。
问题2:相机没校准好(非理想校正)导致匹配失败
理论上,我们会把两个相机拍的图片"校正(rectification)"------让对应像素刚好在同一水平线上("极线"),这样找对应像素只需要左右搜,不用上下搜。但实际情况是:
①两个镜头的参数不一定一样,没法玩没校正;
②相机安装时可能有点倾斜,校正后还是有偏差。
这时那些假设"图片已经完美校正"的方法就会出现错误,找不到正确的对应像素。
问题3:特殊场景(难例)处理不好
有些场景本身就"不好匹配",比如:
①无纹理区域:比如白墙、光滑的桌子(没有花纹,找不到特征点);
②重复纹理区域:比如格子衬衫、瓷砖墙(很多像素看起来一样,容易找错对应关系)。
3.论文的目标
设计一个新的立体匹配算法(CREStereo),解决上面3个问题,实现:
①能精准算出细薄结构的视差;
②就算相机没校正好,也能正确匹配;
③面对无纹理、重复纹理这些难例,依然能算出准确的视差;
④在公开测试集上(比如 Middlebury、ETH3D)超越之前的方法。
二、论文核心内容拆解(逐部分翻译+解释)
论文的结构是"摘要-引言-相关工作-方法-实验-结论",我们逐部分翻译、解释。
(一)摘要
翻译:
随着卷积神经网络的出现,立体匹配算法近年来取得了巨大进展。然而,由于存在细薄结构、非理想校正、相机模块不一致以及各种难例场景等实际复杂因素,从智能手机等消费级设备拍摄的真实世界图像对中准确提取视差仍然是一个巨大挑战。在本文中,我们提出了一系列创新设计来解决实际立体匹配问题:1)为了更好地恢复精细的深度细节,我们设计了一个带有循环细化的分层网络 ,以从粗到细的方式更新视差,并采用堆叠级联架构进行推理;2)我们提出了自适应分组相关层,以减轻错误校正的影响;3)我们引入了一个新的合成数据集,特别关注难例场景,以便更好地泛化到真实世界场景。
解释:
这部分是论文的"精华总结"一句话概括:
-
背景:CNN 让立体匹配进步很大,但消费级设备(比如手机)拍的图,因为细薄结构、相机没校准好等问题,视差算不准;
-
论文做了 3 件事:① 设计循环细化的分层网络 (从粗到细算视差);② 自适应分组相关层(解决校准问题);③ 新的合成数据集(覆盖难例);
(二)引言
翻译:
立体匹配是计算机视觉的经典研究课题,其目标是给定一对校正后的图像,计算两个对应像素之间的位移,即 "视差"。它在许多应用中发挥着重要作用,包括自动驾驶、增强现实、模拟虚化渲染等。
近年来,在大型合成数据集的支持下,基于卷积神经网络(CNN)的立体匹配方法将视差估计的精度提升到了新的高度。然而,要使该算法在日常消费级摄影场景中真正实用,我们仍然面临三大障碍。首先,对于大多数现有算法来说,精确恢复图像精细细节或细薄结构(如网络和线框)的视差仍然是一个复杂问题。其次,对于真实世界的立体图像对,很难获得完美的校正,因为它们通常由具有不同特性的相机模块拍摄。此外,由不一致的相机模块产生的图像对可能在光照、白平衡、图像质量等方面存在差异,使得估计任务更加困难。最后,尽管有研究表明,从足够大的合成数据集训练的模型可以很好地泛化到真实世界场景。但在典型难例(如无纹理或重复纹理区域)中的视差估计仍然很困难,这需要在训练数据集中特别关注覆盖相关场景。
在本文中,我们提出了CREStereo(即级联循环立体匹配网络 ),它包括一系列新颖设计,用于解决实际立体匹配的问题。为了更好地恢复复杂的图像细节,我们设计了一个分层网络 ,以从粗到细 的方式循环更新视差;此外,我们采用堆叠级联架构 进行高分辨率推理。为了减轻校正误差的负面影响,我们设计了自适应分组局部相关层用于特征匹配。此外,我们引入了一个新的合成数据集,在光照、纹理和形状方面具有更丰富的变化,以便更好地泛化到真实世界场景。
我们的主要贡献总结如下:1)我们提出了用于实际立体匹配 的级联循环网络 和用于高分辨率推理 的堆叠级联架构 ;2)我们设计了自适应分组相关层 来处理非理想校正;3)我们创建了一个新的合成数据集,以更好地泛化到真实世界场景;4)我们的方法在 Middlebury 和 ETH3D 等公开基准测试中显著优于现有方法,并大大提高了真实世界立体图像的视差恢复精度。
解释:
引言部分是 "把问题说清楚 + 告诉读者我们做了什么",分 3 层理解:
-
立体匹配的作用:经典课题,用于自动驾驶、手机虚化等;
-
现有 CNN 方法的 3 个核心问题:细薄结构算不准、非理想校正、难例场景处理差;
-
论文的解决方案(CREStereo):3 个创新设计 + 1 个新数据集;
-
论文的成绩:两个权威测试集第一,真实场景效果好;
(三)相关工作
这部分是"回顾之前的研究",告诉读者"我们的方法是站在哪些巨人的肩膀上",分为 4 类,我们逐个解释:
传统算法 。立体匹配是一个具有挑战性的问题,已经研究了很长时间。传统算法可分为局部方法和全局方法 。局部 方法使用以极线 上像素为中心的支持窗口计算匹配代价 。全局 方法将立体匹配视为优化问题,通过置信传播或图割算法制定并优化显示代价函数 。后来提出了一种半全局匹配(SGM)方法,基于动态规划,使用互信息代替亮度信息。
基于学习的算法 。深度神经网络最初 仅用于立体匹配任务中的匹配代价计算。 Zbontar 和 LeCun 提出训练 CNN 来初始化补丁之间的匹配代价 ,然后通过基于交叉的聚合和半全局优化(如SGM)进行细化。近年来,端到端网络已成为立体匹配得到主流。一类网络仅使用2D卷积 。Mayer 等人提出了第一个端到端网络 DispNet 及其相关版本 DispNetC 用于视差估计。Pang 等人 提出了一种名为 CRL 的两阶段框架,具有多尺度残差学习。Guo 等人提出了 GwcNet,使用分组相关来改进相似性测量。AANet引入了一种使用稀疏点和多尺度交互的新颖聚合方法。最近的一种方法RAFT-Stereo利用光流网络RAFT中的迭代细化,设计了一种适用于立体匹配的网络。另一类网络使用3D卷积来执行传统方法中代价体构建和聚合。GCNet 和 PSMNet 提出构建 4D 代价体,并使用 3D 沙漏聚合网络。对于高分辨率图像,Yang 等人提出了一种从粗到细的分层网络来解决内存和速度问题。最近,神经架构搜索也被引入到深度立体网络中。
实际立体匹配。 面向真实世界图像的立体匹配是一个研究较少的问题。Pang 等人提出了一种自适应方法,使 CNN 能够泛化到没有真实视差的目标域。Luo 等人 提出了一种小波合成网络,为手机虚化应用产生更好的结果。Song 等人引入了一种域自适应流水线,使网络缩小合成域和真实世界域之间的差距。
合成数据集。充足的训练数据对于深度立体模型至关重要,但在真实世界中很难获得准确的视差。合成数据集提供了高精度和密集的真实标签。最近,He 等人使用 Blender 构建了一个立体匹配的数据生成流水线,纹理来自常见数据集的真实图像。Autoflow引入了一种简单的方法来渲染随机多边形并带有运动,用于光流训练。尽管这些数据集有效,但它们的物体形状变化有限,视差 / 光流值的分布受到限制,这削弱了从合成域到真实世界的泛化能力。
解释:
这部分核心是理解"之前的方法有什么不足,我们的方法补了什么缺口":
①传统算法:分局部(用窗口算代价)、全局(优化代价函数)、半全局(SGM)------但这些方法在复杂场景(比如细薄结构)中精度不够。
②基于学习的算法(CNN方法):
分两类:用2D卷积(比如 DispNet、RAFT-Stereo)和用 3D 卷积(比如 PSMNet);
RAFT-Stereo 虽然迭代细化,但没解决非理想校正;3D 卷积方法内存消耗大,高分辨率图处理不了;
③实际立体匹配:之前专门针对真实场景的研究很少,我们的方法就是聚焦这个方向;
④合成数据集:之前的数据集难例少、物体形状单一,我们的新数据集就是补了这个短板。
(四)方法------论文中的核心!
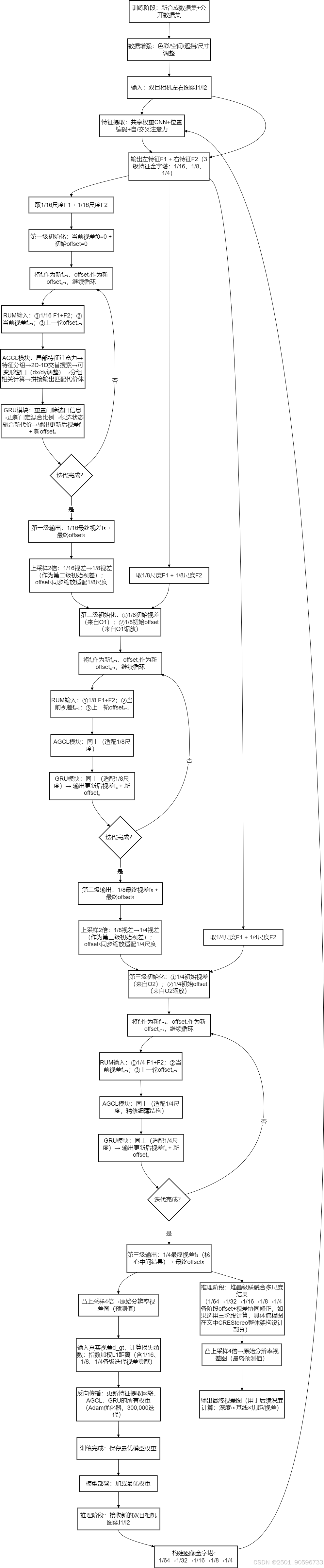
1.CREStereo整体架构设计
这部分是"我们怎么设计CREStereo ",分为5个部分:自适应分组相关层 (AGCL,解决问题2)、级联循环网络 (解决问题1)、堆叠级联推理架构 (优化高分辨率图处理)、损失函数 (训练模型用)、新合成数据集(解决问题3)。
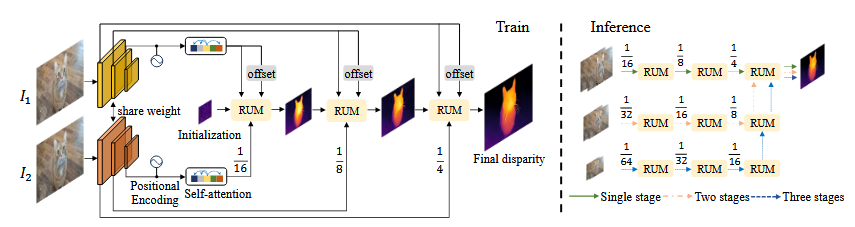
图2
上图图2是CREStereo的整体架构 (核心架构图),左边是"训练时的网络",右边是"推理时的堆叠架构"。你可以想象成:
①训练时:用3级特征金字塔 (把图片缩小成3个尺度),通过3个级联的循环更新模块(RUM),从粗到细算视差;
②推理时:把图片做成金字塔(多个分辨率),用堆叠的级联架构,结合多尺度信息,处理高分辨率图。
更详细的解释:我们先从左边的训练部分开始,然后看右边的推理部分。
①训练部分(Train)
我们从"输入→特征提取→视差计算" 一步步拆解:
-
输入图像对 (I1, I2):
- 两张输入的立体图像,通常是左右眼拍摄的同一场景的图片。
-
特征提取(Feature Extraction)模块(黄色+橙色积木块):
-
两张图像分别通过一个共享权重 的特征提取网络( 同一个特征提取网络**)** ,生成特征图,这样左 / 右图像的特征是 "同一种语言",方便后续匹配。
-
图中黄色和棕色的积木块代表特征图。
-
-
位置 编码和自注意力(Positional Encoding & Self-attention):
-
在特征图上加入位置编码(因为特征本身是没有 "哪里是左、哪里是右" 的,加了位置编码后,模型才知道 "这个特征在图像的左上角"),增强特征图中位置信息的表达能力。
-
自注意力机制 用于在特征图上聚合全局信息------比如计算某个像素的特征时,不仅看自己,还看整个图像的其他像素(比如知道 "这个像素是铁丝网的一部分"),减少匹配模糊。
-
-
初始视差估计(Initialization):
- 初始的视差图是从最低分辨率(1/16),这里的 "1/16" 是 "特征图的缩放比例"(左 / 右图像的特征图被缩小到原始图像的 1/16 大小)开始的,图中紫色的立方体表示。这个模块的作用是给 "第一个 RUM" 提供初始视差(默认是全 0,相当于 "先假设所有像素的视差都是 0")。
-
循环更新模块(Recurrent Update Module, RUM):
-
RUM模块用于迭代更新视差图。图中每个RUM模块后都有一个箭头指向下一个分辨率层次。用 AGCL 算匹配、GRU 更新视差,是视差精准化的 "关键手"。
-
视差图经过RUM模块后,会通过上采样 (offset)到更高的分辨率层次。它的输入 有3个 :①左、右图像的特征 ;②上一个模块过来的"当前视差 ";③"offset "偏移量:模型自己学出来的"搜索方向调整值"(解决非理想校正的关键)。它的输出是"更精准的视差图",同时输出新的"offset"传给下一个RUM。
-
-
多级特征金字塔(Multi-level Feature Pyramid):
-
特征图和视差图在不同的分辨率层次上进行处理,从1/16到1/8再到1/4,逐步提高细节的分辨率。
-
图里 RUM 旁边的 "1/16、1/8、1/4":是当前视差图的缩放比例(对应 "特征图的大小")。第一个 RUM 处理的是 "1/16 大小的特征",输出 "1/16 大小的视差图";这个视差图会被 "放大 2 倍"(变成 1/8 大小),传给第二个 RUM;第二个 RUM 输出 "1/8 大小的视差图",再放大 2 倍(变成 1/4 大小)传给第三个 RUM;第三个 RUM 输出 "1/4 大小的视差图",最后放大到 "原始图像大小",就是 "Final disparity"(最终视差图)。
-
-
最终视差图(Final Disparity):
- 经过多个RUM模块迭代后,得到最终的视差图,图中最右边的紫色图表示。
②推理部分(Inference)
推理部分是训练好模型后,模型在实际使用时,如何从输入图像中计算出视差图的过程。核心是 "图像金字塔 + 堆叠级联":
1.图像金字塔(不同缩放比例的图)
①图里的 "1/64、1/32、1/16、1/8、1/4":是双目相机左右图像的 "缩放版本"(比如原始图像是 1024×768,1/64 就是 16×12,1/32 是 32×24,以此类推)
②这些缩放图组成 "图像金字塔"(从下到上,图越来越大)。
2.堆叠级联的流程(箭头的含义)
图里的箭头代表"视差的传递方向 ",每个 "→":代表「视差图的上采样(放大)+ 输入下一个 RUM 细化」,所有阶段共享同一个训练好的RUM模块(权重一样),不是三个不同的 RUM:
①如果选择三阶段(蓝色线 ,三根不同颜色的线(绿色实线、紫色虚线、蓝色虚线 )是算法提供的 "三种推理模式 ",不是同时走,而是根据你的需求选一种 ),则先处理最下层的小图 (1/64):用RUM算出1/64大小的视差;
②把这个视差"放大2倍"(变成1/32大小),传给"1/32层"的RUM,作为它的"初始视差";
③"1/32 层" 的 RUM 细化出 1/32 大小的视差,再放大 2 倍传给 "1/16 层";
④以此类推,直到 "1/4 层" 的 RUM,最后输出 "1/4 大小的视差图",再放大到原始图像大小,得到最终结果。
3.不同颜色的线:
-
绿色线(Single stage):只走 "最上层的 1/16→1/8→1/4",是 "单阶段计算"(最快但精度最低);
-
紫色虚线(Two stages):走 "1/32→1/16→1/8"+"1/16→1/8→1/4",是 "两阶段计算"(速度和精度折中);
-
蓝色虚线(Three stages) :走"1/64→1/32→1/16"+"1/32→1/16→1/8"+"1/16→1/8→1/4"(注意不是单纯叠加视差图,可以看下图中的具体流程,上采样+下采样 得出视差图和特征再进入下一个阶段,因为每个阶段的 "输入视差" 必须和 "当前处理的特征图尺度一致"),是 "三阶段计算"(最慢但精度最高(论文里刷榜用的就是这种))。
-
这些线的作用是 "堆叠多个级联流程"------ 阶段越多,利用的 "小图信息" 越充分,视差精度越高。
③总结:训练 + 推理的核心逻辑
-
训练阶段:用 "1/16→1/8→1/4" 的级联 RUM,让模型学会 "从粗到细算视差";
-
推理阶段 :用 "1/64→1/32→...→1/4" 的图像金字塔 + 堆叠级联,多阶段堆叠的核心是:每个阶段的输出不是 "最终视差",而是 "给下一个更粗尺度阶段的初始视差",最后只输出一个 "最精细的视差图"。既解决了双目相机高分辨率图像的内存问题,又保证了细薄结构的视差精度;
-
图里的 "线条聚集":是因为每个模块需要 "多个输入(特征、视差、偏移量)" 才能工作,这些输入共同决定了 "下一个视差的精度"。
2.自适应分组相关层(AGCL)------解决"非理想校正"问题
真实世界立体相机很难实现完美校正。例如,两个相机可能没有严格放置在水平极线上 ,导致3D空间中的轻微旋转;或者相机镜头拍摄的图像即使经过校正后通常仍有残余畸变 。因此,对于立体图像对,对应点可能不在同一扫描线 上。因此,提出了自适应分组相关层(AGCL) ,以减少 这种情况下的匹配模糊性,与全队匹配相比实现了更好的性能,同时仅计算局部相关。
一,局部特征注意力 (Local Feature Attention)。不同于为每个像素对计算全局相关(会消耗大量内存和计算资源),我们只在局部窗口中匹配点,以避免大量内存消耗和计算成本。借鉴用于系数特征匹配的LoFTR,我们在级联的第一阶段计算相关之前添加了一个注意力模块 ,以便在单个或交叉特征图中聚合全局上下文信息 。我们向骨干网络输出添加位置编码,增强特征图的位置依赖性。交替计算自注意力和交叉注意力,并使用线性注意力层来降低计算复杂度。
二,2D-1D交替局部搜索 (2D-1D Alternate Local Search)。我们仅在局部搜索窗口中计算相关,输出小得多的H×W×D体积(H和W是特征图的高度和宽度,D是相关对的数量,远小于W),以节省内存和计算成本。此外,当模型泛化到具有不同基线(两个相机之间的距离)的立体对时,我们不需要预设范围。
给定两个重采样和经过注意力处理的特征图F₁(左图特征)和 F₂(右图特征),位置(x,y)处的局部相关可以表示为:
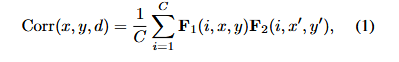
其中x'=x+f (d),y'=y+g (d),Corr (x,y,d)∈是第 d 个(d∈0,D-1)相关对的匹配代价,C是特征通道数,f (d) 和 g (d) 表示当前像素在水平和垂直方向上的固定偏移。
传统 上,立体匹配中校正后的两个图像之间的搜索方向仅位于极线 上。为了处理非理想立体校正情况,我们采用2D-1D交替局部搜索策略 来提高匹配精度,在1D搜索模式 下,我们设置了g(d)=0,f (d)∈-r,r(r=4,1D 搜索模式的 "搜索半径"------1D 模式下,只在水平方向搜索,搜索范围是 "当前像素左右各 r 个像素")。f(d)的正位移值 保留用于每次迭代采样后调整不准确的结果。公式(1)计算的结果在通道维度上堆叠并连接,形成最终的相关体。在2D搜索模式 下,使用类似于膨胀卷积的、膨胀率为1的k×k网格(2D 搜索模式 下,要在 "当前像素的上下左右都搜索"(解决非理想校正的垂直偏差),k×k 网格就是 "搜索区域的形状 ")进行相关计算。我们设置,以确保输出特征具有相同的通道数,以确保输出特征具有相同的通道数,以便它们可以输入到共享权重的更新块(架构图里的 "share weight" 是 "特征提取网络的共享权重",而 RUM 里的 "共享权重更新块" 是 "GRU 的共享权重",两者完全无关)中。与迭代重采样配合,交替局部搜索还充当循环细化的传播模块,网络学习用当前位置更准确的邻居替换其有偏差的预测。
三、可变形搜索窗口 (Deformable search window)。立体匹配在遮挡或无纹理区域通常会遇到模糊性。在固定的局部搜索窗口中计算的相关容易受到这些情况的影响。将可变形卷积 扩展到相关计算中,我们使用内容自适应搜索窗口 生成相关对------这与AANet不同,AANet仅在代价聚合中采用类似策略。通过学习额外的偏移量dx和dy,新的相关可以计算为:
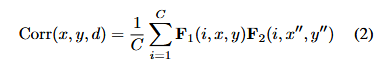
其中 x''=x+f (d)+dx,y''=y+g (d)+dy。下图图4展示了偏移量如何改变传统搜索窗口的形状。
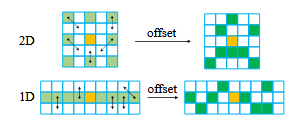
图4 自适应局部相关的示意图
在图4中, 核心是展示 "额外的偏移量 dx、dy 如何改变传统搜索窗口的形状",解决 "遮挡、无纹理区域" 的匹配模糊问题。上半部分(Top):2D situation(2D 搜索模式下的自适应窗口),下半部分(Bottom):1D situation(1D 搜索模式下的自适应窗口),箭头代表 "偏移量的方向"。
dx 和 dy 是模型在训练过程中 "自适应学习到的",不是预设的固定值 !训练初期:dx 和 dy 初始化为 0,窗口是传统固定窗口;训练过程中:模型会计算 "预测视差" 和 "真实视差(ground truth)" 的误差 ------ 如果某个区域匹配错误(比如非理想校正导致没搜到对应像素),模型会调整 dx 和 dy,让窗口 "移向" 正确的匹配位置;训练后期:模型学到 "不同场景下的 dx、dy 规律"------ 比如无纹理区域 dx=±2,遮挡区域 dy=±1,非理想校正区域 dx=+3、dy=-1 等;推理时:模型会根据输入的双目图像特征,自动输出对应的 dx 和 dy,调整窗口形状 / 位置,实现自适应匹配。图 2 的 offset、图 3 AGCL 的 offset,本质都是图 4 中调整窗口的 "dx 和 dy"。
四、分组相关 (Group-wise correlation)。受引入的分组 4D 代价体的启发,我们将特征图分成 G 组 ,分别计算局部相关。最后,我们在通道维度上连接 G 个 D×H×W 的相关体,得到 GD×H×W 的输出体。该过程如下图图3所示。
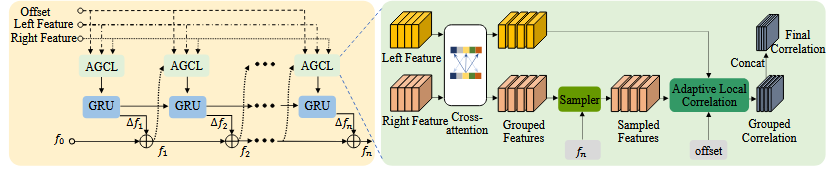
图3 模块架构图
下面详细介绍图3 , 图3分为左右两部分 :左边是RUM (循环更新模块 )的内部结构,右边是AGCL (自适应分组相关层 )的内部结构,线条代表"数据流向"。
核心逻辑 :RUM 调用 AGCL 计算 "匹配代价 (相关体)",再用 GRU 更新视差 ,同时输出新的偏移量反馈给 AGCL,形成循环。
①图 3 右半部分:AGCL 的内部结构 + 线条含义(重点!)
AGCL 是 "计算匹配代价 " 的核心 ,右半部分展示了从 "输入特征 " 到 "输出相关体" 的完整流程,咱们按 "数据流向" 一步步拆:
- AGCL 的输入是什么?
-
输入 1:Left Feature(左特征)→ 双目相机左图像经过 "特征提取网络 + 局部特征注意力" 后的特征图(比如尺寸是 H×W×C,C 是通道数)
-
输入 2:Right Feature(右特征)→ 双目相机右图像的对应特征图(和左特征尺寸、通道数完全一致)
2.AGCL的内部步骤+线条含义
|----|-----------------------------------------|----------------------------------------------------------------------------------------|
| 步骤 | 组件名称(英文) | 作用 |
| 1 | Cross-attention(交叉注意力) | 让左、右特征 "互相参考",聚合全局上下文 (局部特征注意力用在此处,比如左特征知道右特征的哪些区域可能匹配) |
| 2 | Grouped Features(分组特征) | 把经过交叉注意力的左、右特征 ,各自分成 G 组(比如 G=8,C=256→每组 32 通道) |
| 3 | Sampled Features(采样特征) | 根据 "上一轮的偏移量 (offset)",从右特征 的分组特征中 "采样" 可能匹配的区域 |
| 4 | Adaptive Local Correlation(自适应局部相关) | 核心步骤 !计算左、右采样特征的 "匹配程度 "(相关值),这里包含了 "2D-1D 交替搜索 + 可变形搜索窗口" |
| 5 | Grouped Correlation(分组相关) | 每个特征组输出一个 "小组相关体"(比如尺寸 H×W×D,D 是匹配对数),例如8 个小组就有 8 个相关体,每个都记录了该组的匹配程度 |
| 6 | Concat(拼接) | 把 G 个 "小组相关体" 在 "通道维度" 上拼接起来。例如,G个 H×W×D 的相关体,拼接后变成 H×W×(G×D) 的 "大相关体",包含所有小组的匹配信息 |
| 7 | Final Correlation(最终相关体) | AGCL 的输出 ,传给 RUM 的 GRU 模块 |
②图 3 左半部分:RUM的内部结构 + 线条含义
RUM 的作用是 "用 AGCL 的相关体更新视差 ",左半部分展示了 "循环更新" 的流程:
RUM 的输入是什么?
-
输入 1:Final Correlation(最终相关体)→ 来自 AGCL 的输出(H×W×(G×D))
-
输入 2:上一轮的视差预测(比如 fₙ₋₁,上一轮 RUM 输出的视差图)
-
输入 3:上一轮的 offset(上一轮 GRU 输出的偏移量)
解释:
AGCL 是解决 "非理想校正" 的核心,我们拆成小部分:
①核心痛点:非理想校正时,对应像素不在同一水平线,传统方法只左右搜(1D 搜索),找不到对应点;
②AGCL 的 4 个关键设计(逐个解释):
|--------------|------------------------|---------------------------------------------------------------|
| 设计名称 | 作用 | 通俗理解 |
| 局部特征注意力 | 聚合全局信息,减少匹配模糊 | 找对应像素时,不仅看当前像素,还看整个图像的上下文(比如知道这是铁丝网,就往细薄结构方向找) |
| 2D-1D 交替局部搜索 | 解决非理想校正(对应像素不在同一行) | ① 1D 搜索:只左右搜(处理大部分理想情况);② 2D 搜索:上下左右都搜(处理校正偏差的情况);交替进行,既准确又高效 |
| 可变形搜索窗口 | 处理遮挡 、无纹理区域 | 搜索窗口不是固定的正方形,而是根据内容 "变形"(比如无纹理的白墙,窗口变大找更多线索;遮挡区域,窗口避开被挡的像素) |
| 分组相关 | 提升匹配精度,减少噪声 | 把特征图分成好几组,每组单独算相关,最后合并结果 ------ 就像好几个人一起找对应点,最后投票选最准的 |
③公式看不懂没关系,记住核心:AGCL 通过 "局部 + 自适应 + 分组",在不增加太多计算量的情况下,解决了 "非理想校正" 导致的匹配错误。
其中,AGCL 是RUM 模块的内部组件 (不是独立模块),所有 AGCL 的操作都在架构图里的 "RUM" 紫色模块中执行。AGCL、局部特征注意力、2D-1D 交替局部搜索位置都在「RUM 模块内部 」,在架构图里看不到 "AGCL""局部特征注意力" 这些文字,因为它们是 RUM 的 "内部子模块"。架构图左侧(训练阶段)的三个 "RUM" 紫色模块,每个 RUM 里都包含完整的 AGCL 流程;架构图右侧(推理阶段)的所有 RUM,也都包含 AGCL(因为训练和推理用的是同一个 RUM 权重)。在每个 RUM 内部,执行顺序是:RUM 拿到特征后,先通过 "局部特征注意力 " 优化特征,再用 "2D-1D 交替搜索 " 找可能的匹配像素,用 "分组相关 " 算匹配程度,最后用 "可变形窗口 " 微调位置 ------ 这一整套就是 AGCL 的完整执行流程,全在 RUM 内部完成。流程图如下所示。

3.级联循环网络(Cascaded Recurrent Network)------ 解决 "细薄结构算不准" 问题
对于无纹理或重复纹理区域,由于感受野(感受野是卷积神经网络每一层输出的特征图上每个像素点在原始图像上映射的区域大小,这里的原始图像是指网络的输入图像,是经过预处理后的图像)大且语义信息充足,使用低分辨率、高级特征图进行匹配更稳健。然而,这种特征图可能会丢失细薄结构的细节。为了同时保持稳健性和保留高分辨率输入中的细节,我们提出了用于相关计算 和视差更新的级联循环细化。
循环更新模块(RUM) 。我们基于GRU块 (门控循环单元,一种神经网络,记住有用的旧信息,过滤没用的新信息,更新当前需要的关键信息)和自适应分组相关层 (AGCL)构建了循环更新模块 (RUM)。在不同级联层次分别为每个特征图计算相关,并独立细化视差数次。如图3所示,"采样器"以fₙ导出的坐标网格为输入,采样分组特征的位置。{f₁,...,fₙ} 是 n 次迭代的中间预测,初始化为 f₀(全零)。当前相关体由学习到的偏移量 o∈构建。GRU 块更新当前预测,并将其输入到下一次迭代的 AGCL 中。
级联细化(Cascaded Refinement)。除了级联的第一级(从输入分辨率的1/16开始,视差初始化为全零),其他级别都将前一级预测的上采样版本作为初始化。尽管处理不同的细化级别,但所有 RUM 共享相同的权重。在最后一个细化级别之后,进行凸上采样,以获得输入分辨率的最终预测。
解释:
这部分是解决 "细薄结构算不准" 的关键,核心思路是 "从粗到细,循环优化":
①先理解两个概念:
低分辨率特征图:图片缩小后提取的特征(比如原图 1024×768,缩小到 64×48),优点是 "看得远"(感受野大),能把握整体结构(比如知道哪里是物体,哪里是背景),但细节丢了。
高分辨率特征图:原图或略缩小的特征图,优点是 "看得细"(能看到铁丝网的每个像素),但容易受噪声干扰。
②级联循环网络工作流程:
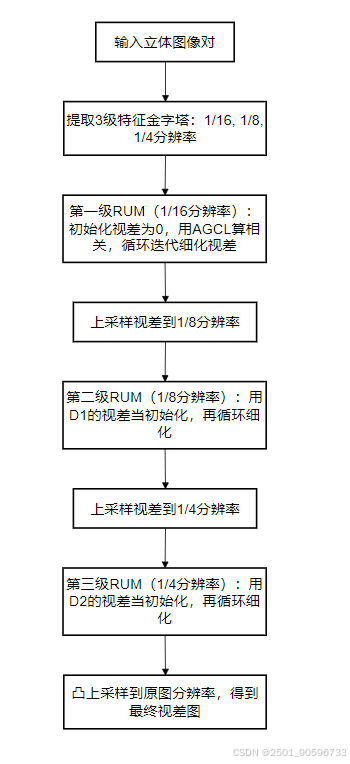
③为什么能解决细薄结构问题?
从粗到细:先在低分辨率图中找到物体的大致位置(比如铁丝网的轮廓),再在高分辨率图中细化细节(铁丝网的每个铁丝);
循环细化:每个 RUM 都迭代好几次(比如 5 次),每次都用 AGCL 重新算相关,修正之前的错误,越算越准;
共享权重:所有 RUM 用一样的参数,减少计算量,还能让低分辨率学到的知识迁移到高分辨率。
4.堆叠级联推理框架(Stacked Cascades for Inference)------ 优化高分辨率图处理
训练期间我们使用固定分辨率的三级特征金字塔进行分层细化,然而,对于更高分辨率的输入图像,为了扩大提取特征的感受野和相关计算,需要进行更多的下采样。但对于高分辨率图像中具有大位移的小物体,直接下采样可能会导致这些区域的特征恶化。为了解决这个问题,我们设计了带有捷径(shortcut)的堆叠级联架构用于推理。具体来说,我们预先下采样立体图像对,构建图像金字塔,并将它们输入到同一个训练好的特征提取网络中,以利用多尺度上下文。堆叠级联架构的概述如图 2 右侧所示(为简洁起见,未显示同一阶段的捷径连接)。对于堆叠级联的特定阶段(图 2 中的行),该阶段的所有 RUM 将与更高分辨率阶段的最后一个 RUM 一起使用。堆叠级联的所有阶段在训练期间共享相同的权重,因此不需要微调。
解释:
这部分是 "推理时的优化",解决 "高分辨率图处理不了" 的问题:
-
痛点:高分辨率图(比如手机拍的 2048×1536)直接输入网络,内存不够;但如果直接缩小(下采样),小物体(比如远处的电线)的特征会消失,视差算不准;
-
解决方案:图像金字塔 + 堆叠级联:
-
图像金字塔:把高分辨率图做成多个尺度(比如 2048×1536 → 1024×768 → 512×384);
-
堆叠级联:每个尺度都用之前训练好的级联网络(共享权重),然后把不同尺度的结果结合起来(用捷径连接);
-
-
效果:既利用了低尺度图的大感受野(把握整体),又保留了高尺度图的细节(小物体),内存消耗还可控。
5.损失函数(Loss Function)------ 训练模型的 "指南针"
对于我们特征金字塔的每个阶段 s∈{1/16, 1/8, 1/4},我们使用上采样算子 μₛ将输出序列 {,...,
} 调整到完整的预测分辨率,并使用类似于 RAFT 的指数加权 L₁距离作为损失函数(γ 设为 0.9)。给定真实视差
,总损失定义为:
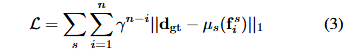
损失函数 的作用是 "告诉模型训练时哪里错了,错得有多严重"(损失函数用于量化模型预测与真实值之间的差异),不用懂公式,记住 3 个关键点:
-
多阶段损失:不仅用最后一级的输出算误差,还用上 1/16、1/8、1/4 三个阶段的输出算误差 ------ 让模型在每个阶段都学习,避免只学最后一级而前面阶段没学好;
-
指数加权:后面的迭代(比如第 5 次迭代)的误差权重比前面的(比如第 1 次)大 ------ 鼓励模型越迭代越准;
-
L₁距离:计算预测视差和真实视差(
)的绝对误差 ------ 这种损失对异常值(比如个别算错的像素)不敏感,训练更稳定
6.新合成数据集(Synthetic Training Data)------ 解决 "难例场景" 问题
与之前的合成数据集相比,我们的数据生成流水线特别关注真实世界场景中的难例,并具有各种增强。我们使用 Blender (一款 3D 建模渲染软件)生成合成训练数据。每个场景包含左右图像对和相应的像素级精确密集视差图,由双虚拟相机和自定义放置的物体捕获。我们的主要设计考虑如下,部分示例如图 5 所示。

图5
形状(Shape)。我们多样化了作为主要场景内容的模型形状,来源包括:1)ShapeNet数据集,包含超过 40,000 个常见物体的 3D 模型,形状各异,构成我们的基本内容来源;2)Blender 的树苗生成插件,提供细节丰富且杂乱的视差图;3)我们使用 Blender 的内部基本形状,结合线框修改器,生成具有孔洞和镂空结构的挑战性场景模型。
光照和纹理(Lighting and texture)。我们在场景内随机位置放置不同类型、颜色和亮度的灯光,形成复杂的光照环境。真实世界图像被用作物体和场景背景的纹理,特别是包含重复图案或缺乏可见特征的难例场景。此外,我们利用 Blender 的 Cycles 渲染器的光线追踪能力,随机将物体设置为透明或具有金属反射,以覆盖具有类似属性的真实世界场景。
视差分布(Disparity distribution)。为了覆盖不同的基线设置,我们努力确保生成数据的视差在宽范围内平滑分布。我们将物体放置在由相机视场和最大距离形成的截头锥体形状的空间内。每个物体的确切位置从概率分布中随机选择,然后根据其到相机的距离缩放物体,以防止遮挡视线。这种做法导致了随机但可控的视差分布。
(五)实验(Experiments)
这部分是 "用数据说话",证明 CREStereo 比之前的方法好。我们不用看所有细节,重点看 3 类实验:
1. 消融实验(Ablation Study)------ 证明每个创新设计都有用
消融实验的思路:"去掉某个设计,看性能是不是下降"------ 如果下降,说明这个设计是必要的。
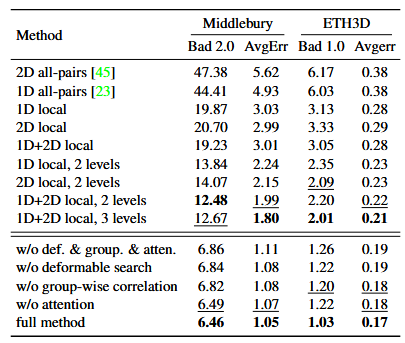
表一
(1)相关层类型的影响(表 1 上半部分):
-
结论:用 AGCL 的 "1D+2D 局部相关 " 比传统的 "全对相关"(RAFT-Stereo 用的)精度高很多;级联层数越多(1→2→3),精度越高。
-
说明:AGCL 的局部相关和交替搜索是有效的。
(2)AGCL 组件的影响(表 1 下半部分):
-
结论:去掉 "可变形搜索窗口 "、"分组相关 "、"局部特征注意力" 中的任何一个,精度都会下降。
-
说明:AGCL 的 4 个设计都是必要的,缺一不可。
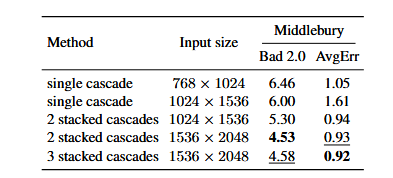
表二
(3)堆叠级联的影响(表 2):
-
结论:高分辨率图(比如 1536×2048)用堆叠级联,比不用的精度高很多(Bad2.0 从 6.00 降到 4.53)。
-
说明:堆叠级联能有效处理高分辨率图。
(4)新数据集的影响(图 6):
-
结论:用我们的新数据集训练,比用之前的数据集(Sceneflow)训练,损失更低,在真实测试集上的误差更小。
-
说明:新数据集的难例设计有效,模型泛化能力更强
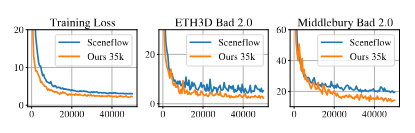
图6
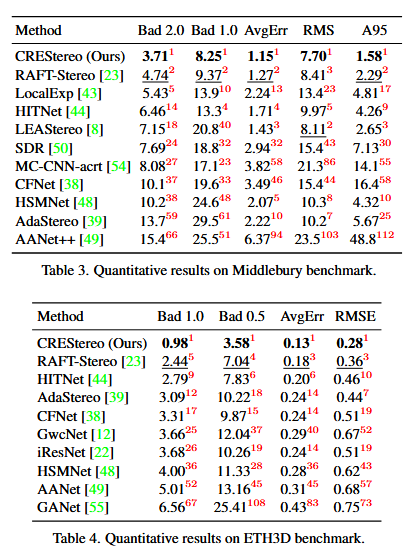
2. 与现有方法的对比(表 3、表 4)------ 证明是当前最好的
(六)结论(Conclusion)
尽管深度立体网络取得了前所未有的成功,但在真实世界场景中准确恢复视差仍然存在障碍。在本文中,我们提出了 CREStereo ,一种新颖的立体匹配网络 ,在公开基准测试和真实世界场景中都取得了最先进的结果。我们的核心观点是,为了使算法在真实世界中真正有效,网络架构和训练数据都值得深入思考。通过带有自适应相关 的级联循环网络 ,我们能够比现有方法更好地恢复精细的深度细节;并且通过精心设计合成数据集,我们成功地更好地处理了无纹理或重复纹理区域等难例场景。我们方法的一个局限性是,该模型尚未高效到可以在当前的移动应用中运行。未来的改进可以使我们的网络适应各种便携式设备,最好是实时运行。
结论部分总结全文 + 展望未来:
-
核心贡献:网络架构(级联循环 + AGCL)+ 训练数据集(难例丰富),共同解决了真实场景的立体匹配问题;
-
局限性:模型现在比较复杂,手机等移动设备上跑不了(速度慢、耗内存);
-
未来方向:优化模型效率,让它能在手机上实时运行。
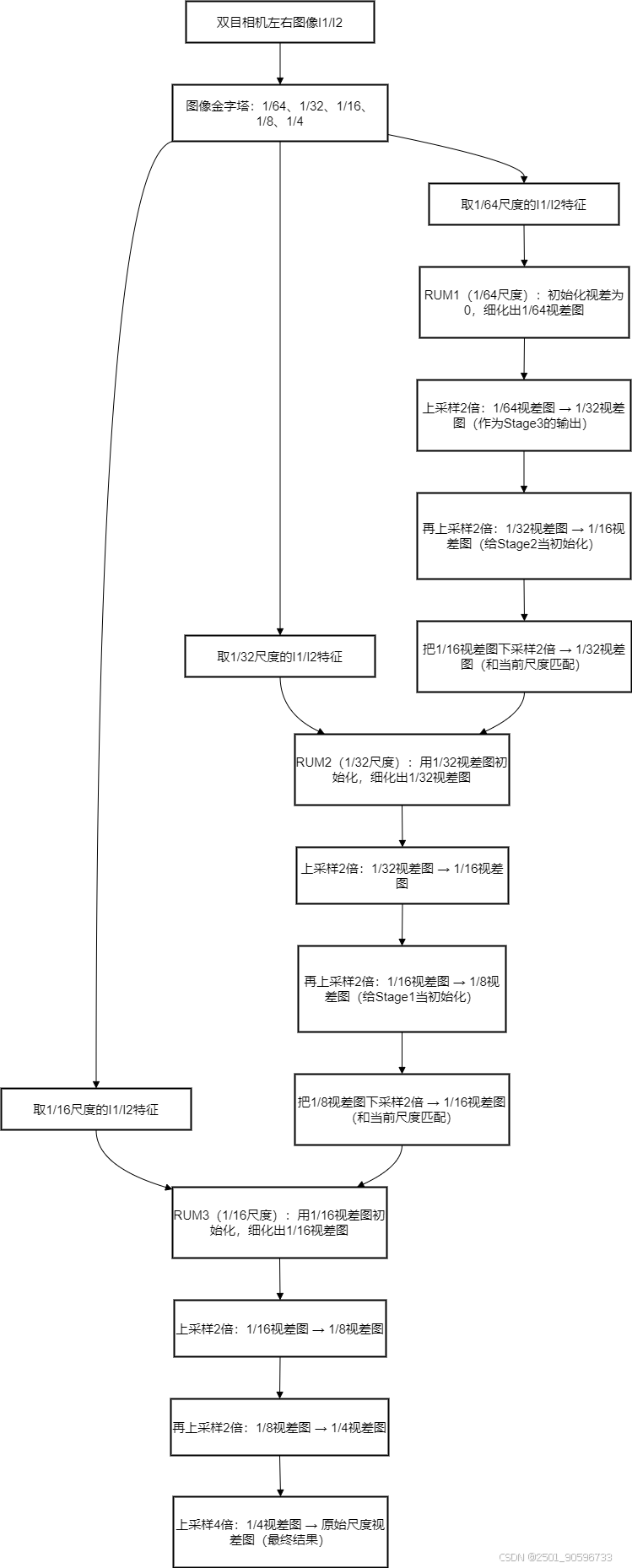
下面为CREStereo 算法完整细化流程图(含 RUM 输入输出细节):