感谢阅读!❤️
如果这篇文章对你有帮助,欢迎 **点赞** 👍 和 **关注** ⭐,获取更多实用技巧和干货内容!你的支持是我持续创作的动力!
**关注我,不错过每一篇精彩内容!**目录
- 一、存储引擎
-
- [1.1 存储引擎分类](#1.1 存储引擎分类)
- [1.2 查看与修改存储引擎](#1.2 查看与修改存储引擎)
- [1.3 存储引擎的适用场景](#1.3 存储引擎的适用场景)
- 二、索引
-
- [2.1 什么是索引?](#2.1 什么是索引?)
- [2.2 索引的分类](#2.2 索引的分类)
- [2.3 索引的操作](#2.3 索引的操作)
- [2.4 MySQL 索引采用了 B+树数据结构](#2.4 MySQL 索引采用了 B+树数据结构)
-
- [2.4.1 二叉树](#2.4.1 二叉树)
- [2.4.2 红黑树(自平衡二叉树)](#2.4.2 红黑树(自平衡二叉树))
- [2.4.3 B树](#2.4.3 B树)
- [2.4.4 B+树](#2.4.4 B+树)
- [2.5 索引类型及核心优化机制](#2.5 索引类型及核心优化机制)
-
- [2.5.1 Hash索引](#2.5.1 Hash索引)
- [2.5.2 聚簇索引和非聚簇索引](#2.5.2 聚簇索引和非聚簇索引)
- [2.5.3 二级索引](#2.5.3 二级索引)
- [2.5.4 单列索引(单一索引)](#2.5.4 单列索引(单一索引))
- [2.5.5 多列索引(复合索引)](#2.5.5 多列索引(复合索引))
- [2.5.6 覆盖索引](#2.5.6 覆盖索引)
- [2.5.7 索引下推](#2.5.7 索引下推)
- [2.6 索引优缺点](#2.6 索引优缺点)
- [2.7 索引的适用场景和不适用场景](#2.7 索引的适用场景和不适用场景)
一、存储引擎
存储引擎(Storage Engine)是数据库管理系统(DBMS)中负责数据的物理存储、检索和管理的核心组件。不同的存储引擎在事务支持、并发控制、索引结构、锁机制、崩溃恢复等方面具有不同特性。不同的存储引擎实现了不同的存储和检索算法,因此在处理和管理数据的方式上存在差异。不同的存储引擎适用于不同的应用场景。
1.1 存储引擎分类
按功能与特性分类(以 MySQL 为例):
| 分类 | 存储引擎 | 特点 |
|---|---|---|
| 事务型 | InnoDB、NDB |
支持 ACID 事务、行级锁、崩溃恢复 |
| 非事务型 | MyISAM、Memory、CSV、Archive |
不支持事务,性能或用途特殊 |
| 内存型 | Memory、NDB(部分) |
数据存于内存,速度快但易失 |
| 归档/压缩型 | Archive |
高压缩比,仅支持插入和查询 |
| 文件交换型 | CSV |
数据以 CSV 文件格式存储,便于外部读取 |
| 虚拟/特殊用途 | Blackhole、Federated |
Blackhole 丢弃数据;Federated 访问远程表 |
注:
PostgreSQL、Oracle、SQL Server等通常不提供用户可选的多引擎,而是采用统一存储模型,但可通过表类型或扩展实现类似功能。
1.2 查看与修改存储引擎
- 查看所有的存储引擎
sql
SHOW ENGINES;- 查看当前默认存储引擎
sql
SHOW VARIABLES LIKE 'default_storage_engine';- 查看某张表使用的存储引擎
sql
SHOW CREATE TABLE 表名;
-- 示例:查看字段ENGINE
SHOW CREATE TABLE STUDENT; -- ENGINE=InnoDB- 创建表时指定存储引擎
sql
CREATE TABLE 表名(
...
) ENGINE = 存储引擎;
-- 示例:
DROP TABLE IF EXISTS USER;
CREATE TABLE USER(
ID INT PRIMARY KEY,
NAME VARCHAR(255)
) ENGINE = MEMORY;- 修改已有表的存储引擎
sql
ALTER TABLE 表名 ENGINE = 新的存储引擎;
-- 修改为 将 MyISAM 存储引擎
ALTER TABLE USER ENGINE = MyISAM;注意,在修改存储引擎之前,需要考虑以下几点:
- 修改存储引擎可能需要执行复制表的操作,因此可能会造成数据的丢失或不可用。确保在执行修改之前备份好数据。
- 修改表的存储引擎可能会影响到现在的应用程序和查询。确保在修改之前评估和测试所有影响。
- 不是所有的存储引擎都支持相同的功能,确保选择的新存储引擎支持应用程序的所需的功能。
ALTER TABLE语句可能需要适当的权限才能执行。确保操作的用户有足够权限来执行修改存储引擎的操作。
1.3 存储引擎的适用场景
1. InnoDB
- 特点:
- 提供完整的
ACID事务支持 - 实现行级锁和
MVCC - 支持外键约束
- 具有较好的并发性能和数据完整性
- 提供完整的
- 适用场景:
- 高并发系统
- 需要数据一致性和完整性的业务
- 频繁读写混合操作
- 适用于大多数应用场景
2. MyISAM (MySQL 8.0+ 已逐步弃用,新项目不推荐使用)
-
特点:
- 快速读取,表结构简单
- 支持全文索引(早期版本优势)
- 使用 表级锁,写操作会阻塞整个表
- 不支持事务、外键、崩溃恢复
-
适用场景:
- 只读或读多于写的场景(如日志分析、报表)
- 对事务无要求的小型应用
3. Memory (原名HEAP)
- 特点:
- 所有数据存储在内存中,访问极快
- 服务重启后数据丢失
- 使用哈希索引(默认)或
B-Tree - 不支持
TEXT/BLOB类型,不支持事务
- 适用场景:
- 临时缓存表(如会话状态、中间计算结果)
- 高速查找的维度表(需容忍数据丢失)
- 适用于需要快速读写的临时数据集、缓存和临时表等场景
4. Archive
- 特点:
- 专为 高压缩归档 设计(使用
zlib压缩) - 仅支持
INSERT和SELECT - 不支持删除、更新、索引(
MySQL 5.1+支持单列索引) - 写入快,存储空间小
- 将数据高效地进行压缩和存储的存储引擎
- 专为 高压缩归档 设计(使用
- 适用场景:
- 日志归档、历史数据冷存储
- 审计记录、传感器历史等只追加场景
- 适用于需要长期存储大量历史数据且不经常查询的场景
5. CSV
- 特点:
- 表数据以标准
CSV文件 形式存储(.csv文件) - 可被 Excel、Python、文本编辑器直接打开
- 不支持索引、NULL、事务
- 表数据以标准
- 适用场景
- 数据导入/导出中间格式
- 与其他系统进行简单数据交换
6. Blackhole
- 特点:
- 所有写入操作被"黑洞"吞噬(不存储任何数据)
- 仅记录
SQL到binlog(可用于复制架构)
- 适用场景
- 主从复制中的中继节点(过滤数据)
SQL语法测试、审计日志转发
7. NDB / NDBCLUSTER(MySQL Cluster)
- 特点:
- 分布式、内存优先的高可用引擎
- 自动分片、无共享架构(shared-nothing)
- 支持 ACID、毫秒级故障切换
- 适用场景
- 电信计费、实时风控、高可用关键系统
- 需要横向扩展和
99.999%可用性的场景
二、索引
2.1 什么是索引?
假设新华字典中的字都是无序的,想象一下你在新华字典中查询一个字,却没有字典目录,你只能一页一页地翻找字典,寻找目标文字,可能翻了几个小时甚至几天才能找到。这显然效率极低。在数据库世界中,索引 (Index)就是那页"字典目录"。它是一种专门用于加速数据检索的数据结构,能让数据库引擎在海量数据中快速定位目标记录,而无序扫描整张表。
2.2 索引的分类
不同的存储引擎有不同的索引类型和实现:
-
按照数据结构分类:
- B+数索引 :采用 B+数的数据结构(
MySQL的InnoDB存储引擎默认采用的索引方式) - Hash 索引 :采用哈希表的数据结构(仅
Memory存储引擎支持)
- B+数索引 :采用 B+数的数据结构(
-
按照物料存储方式分类:
- 聚簇索引(也可以称聚集索引):索引和表中的数据在一起,数据存储的时候就是按照索引顺序存储的。一张表只能有一个聚簇索引。
- 非聚簇索引(也可以称非聚集索引):索引和表中数据是分开的,索引是独立于表空间的,一张表可以有多个非聚簇索引
-
按照字段特性分类:
- 主键索引 :特殊的唯一索引,
InnoDB中即聚簇索引 - 唯一索引 :确保字段值唯一(
UNIQUE),InnoDB中即非聚簇索引(二级索引) - 普通索引:最基本的索引类型,同样属于非聚簇索引(二级索引),叶子节点存的是主键值
- 全文索引 :用于对大文本字段(如
CHAR,VARCHAR,TEXT)进行全文搜索
- 主键索引 :特殊的唯一索引,
-
按照字段个数分类:
- 单列索引:对单个字段建立索引
- 多列索引(也称复合索引):对多个字段组合建立索引,遵循最左前缀原则
2.3 索引的操作
主键自动添加索引
对于主键字段,会自动添加索引,无需自己创建。主键字段上的索引称为主键索引,在 InnoDB 引擎中,主键索引也是聚簇索引。
Unique 约束的字段自动添加索引
对于添加了UNIQUE约束的字段,会自动添加索引,无需自己创建,字段上的索引称为唯一索引。在 InnoDB 中,唯一索引是非聚簇索引(二级索引),其叶子节点存储的是主键值(用于回表查询)。
给指定字段添加索引
- 建表时添加索引:
sql
CREATE TABLE 表名(
定义的字段,
--为某个字段添加索引
INDEX 索引名(字段名)
)
--示例
CREATE TABLE STUDENT(
ID INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(255),
AGE INT,
-- 为NAME字段创建索引
INDEX INEDX_NAME(NAME)
);- 表已经建好,后续给字段添加索引
sql
ALTER TABLE 表名 ADD INDEX 索引名(字段名);
--示例
ALTER TABLE STUDENT ADD INDEX INDEX_NAME(NAME);或者
sql
CREATE INDEX 索引名 ON 表名(字段名);
--示例
CREATE INDEX INDEX_NAME ON STUDENT(NAME);- 查看表上的索引
sql
SHOW INDEX FROM 表名;
-- 示例
SHOW INDEX FROM STUDENT;或者
sql
SHOW KEYS FROM 表名;
--示例
SHOW KEYS FROM STUDENT;| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| STUDENT | 0 | PRIMARY | 1 | ID | A | 0 | BTREE | YES | ||||||
| STUDENT | 1 | INEDX_NAME | 1 | NAME | A | 0 | YES | BTREE | YES |
字段说明:
Table:表名
Non_unique:是否允许重复值
- 0 → 唯一索引(包括主键)
- 1 → 非唯一索引
Key_name:索引名称
- 主键索引固定为 PRIMARY
- 其他索引为你创建时指定的名字(如 idx_name),或自动生成(如外键约束生成的索引)
Seq_in_index:该列在多列索引(复合索引)中的顺序(从 1 开始)
- 示例:
CREATE INDEX idx_name_age ON student(name, age);
则 name 的 Seq_in_index = 1,age 的 Seq_in_index = 2
Column_name:构成该索引的列名
Collation:索引中列的排序方式
- A → 升序(Ascending)
- D → 降序(Descending,MySQL 8.0+ 支持)
- NULL → 不排序(如哈希索引)
Cardinality:索引列的基数(即不同值的数量)的估算值(重要性:这是判断索引是否有效的核心指标!)值越大 → 区分度越高 → 索引效率越高
值越小(接近1)→ 区分度低 → 索引可能被优化器忽略
Sub_part:是否对列的前缀部分建立索引
- NULL → 整列索引
- 数字(如 20)→ 只索引该列的前 20 个字符(常见于 VARCHAR/TEXT)
CREATE INDEX idx_email_prefix ON student(email(20));,这个索引的Sub_part = 20Packed:索引是否被压缩(如使用 PACK_KEYS 表选项)
- 通常为 NULL,很少使用,可忽略
Null:该列是否允许 NULL 值(NULL 值会影响索引效率(B+树需特殊处理),建议尽量将索引列设为 NOT NULL)
- YES → 允许 NULL
- 空→ 不允许 NULL
Index_type:索引使用的数据结构类型
- BTREE → 最常见(InnoDB 默认)
- HASH → Memory 引擎支持
- FULLTEXT / SPATIAL → 特殊索引
Comment:索引的额外注释(一般为空)
- 用途:某些存储引擎(如 MyISAM)可能用到
Index_comment:用户创建索引时添加的注释(MySQL 5.7+ 支持)
CREATE INDEX INDEX_NAME ON STUDENT(name) COMMENT '用于按姓名查询学生';
- 删除索引
sql
ALTER TABLE 表名 DROP INDEX 索引名;
--示例
ALTER TABLE STUDENT DROP INDEX INDEX_NAME;2.4 MySQL 索引采用了 B+树数据结构
MySQL的InnoDB存储引擎(默认引擎)使用B+树作为索引的数据结构,为了了解为什么使用B+树,我们需要了解几种树的数据结构
- 二叉树
- 红黑树
- B 树
- B+ 树
区别:树的高度不同。树的高度越低,性能越高。这是因为每一个节点都是一次磁盘
I/O。磁盘I/O是性能开销大的操作。
2.4.1 二叉树
有一张表:
| ID | NAME |
|---|---|
| 401 | 林晓峰 |
| 205 | 陈雨桐 |
| 347 | 赵明远 |
| 119 | 黄子涵 |
| 682 | 郭文轩 |
| 901 | 周静怡 |
| 456 | 吴志豪 |
| 677 | 孙雅婷 |
| 213 | 徐瑞阳 |
| 555 | 王小东 |
如果不给 ID 字段添加索引,默认进行全表扫描,假设查询 ID=555 的数据,那至少需要进行 10 次磁盘 I/O。效率低。如果给 ID 字段添加索引,假设 ID 索引又使用了二叉树 这种数据结构,那么生成的二叉树将会是如下这样(采用左小右大的方式进行构建树结构):
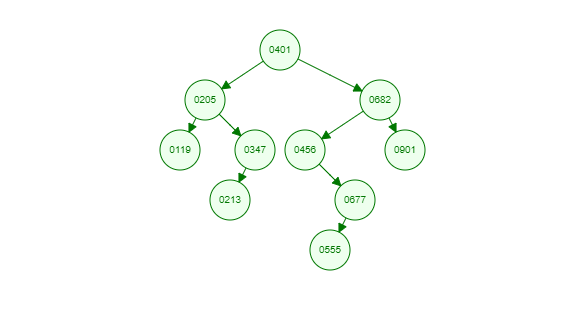
那现在如果查询 ID=555 的数据,至少需要 4 次磁盘 I/O。效率更好了。
但二叉树在数据极端情况下,效率极低。比如这张表:
| ID | NAME |
|---|---|
| 1 | 林晓峰 |
| 2 | 陈雨桐 |
| 3 | 赵明远 |
| 4 | 黄子涵 |
| 5 | 郭文轩 |
| 6 | 周静怡 |
| 7 | 吴志豪 |
| 8 | 孙雅婷 |
| 9 | 徐瑞阳 |
| 10 | 王小东 |
最终构建的二叉树就会退化为一个链表,假设查询ID=10的数据,那么至少需要10次磁盘I/O操作。效率低。所以MySQL的索引没有采用这种数据结构。

2.4.2 红黑树(自平衡二叉树)
有一张表:
| ID | NAME |
|---|---|
| 1 | 林晓峰 |
| 2 | 陈雨桐 |
| 3 | 赵明远 |
| 4 | 黄子涵 |
| 5 | 郭文轩 |
| 6 | 周静怡 |
| 7 | 吴志豪 |
| 8 | 孙雅婷 |
| 9 | 徐瑞阳 |
| 10 | 王小东 |
如果给 ID 字段添加索引,假设 ID 索引又使用了红黑树这种数据结构,那么生成的红黑树将会是如下这样:

假设查询ID=10的数据,那么至少需要5次磁盘I/O操作。相比二叉树,性能有所提升。
红黑树是通过自旋平衡规则进行旋转,子节点会自动分叉为2个分支,从而减少树的高度,当数据有序插入时比二叉树数据检索性能更好。
但如果数据量很大,比如100万条数据,log₂(1000000) ≈ 20,那么树的高度大约是20层,效率依然很低,所以MySQL的索引没有采用这种数据结构。
2.4.3 B树
B树首先是一个自平衡的。 B树每个节点下的子节点数量 > 2。 B树每个节点中也不是存储单个数据,可以存储多个数据。 B树又称为平衡多路查找树
B树分支的数量不是2,是大于2,具体是多少个分支,由阶决定。例如:
- m阶的B树,一个节点下最多有m个节点,每个节点中最多有m-1个数据
- 3阶:一个节点下最多有3个子节点,每个节点中最多有2个数据。
- 4阶:一个节点下最多有4个子节点,每个节点中最多有3个数据。
- 5阶(5, 4)
- 6阶(6, 5)
- ...
- 16阶(16, 15)【MySQL采用了16阶】
有一张表:
| ID | NAME |
|---|---|
| 1 | 林晓峰 |
| 2 | 陈雨桐 |
| 3 | 赵明远 |
| 4 | 黄子涵 |
| 5 | 郭文轩 |
| 6 | 周静怡 |
| 7 | 吴志豪 |
| 8 | 孙雅婷 |
| 9 | 徐瑞阳 |
| 10 | 王小东 |
当阶数m=3时,构建的B树结构如下:

当查询 ID=10的数据时,只需要3次磁盘I/O。
当采用B树存储索引时,更加详细存储结构上这样的。
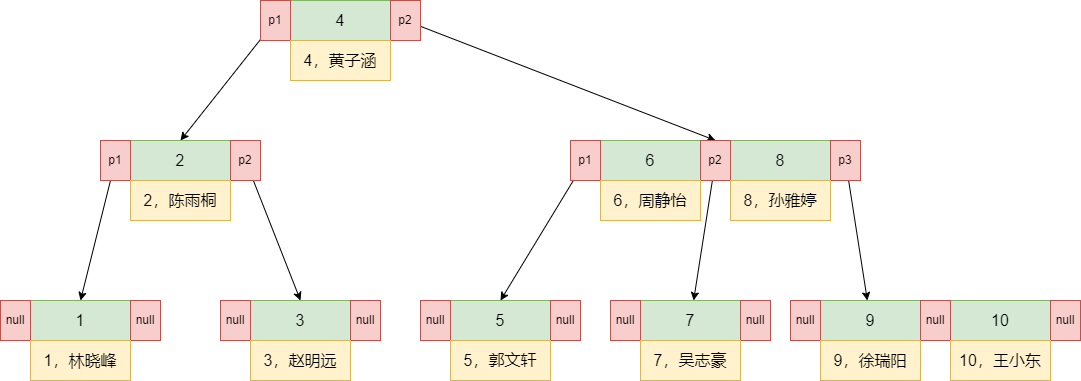
在B树中,每个节点不仅存储了索引值 ,还存储了所以在对应的数据行 ,每个
节点中的p1、p2、p3指针指向下一个节点。每个节点存储索引值和对应的数据行这就是聚簇索引。
当阶数m=16时,并且有100万条数据:
- 第 0 层(根):最多 15 个 key
- 第 1 层:最多 16 个节点,每个 15 key → 共 16 × 15
- 第 2 层:16² 个节点 → 16² × 15 个 key
- ...
- 第 h 层(叶子层):16ʰ 个节点 → 16ʰ × 15 个 key
最大 key 数 = 15 × ( 1 + 16 + 16 2 + ⋯ + 16 h ) = 15 × 16 h + 1 − 1 16 − 1 = 16 h + 1 − 1 \text{最大 key 数} = 15 \times (1 + 16 + 16^2 + \dots + 16^h) = 15 \times \frac{16^{h+1} - 1}{16 - 1} = 16^{h+1} - 1 最大 key 数=15×(1+16+162+⋯+16h)=15×16−116h+1−1=16h+1−1
令其 ≥ 1,000,000:
16 h + 1 − 1 ≥ 10 6 ⇒ 16 h + 1 ≥ 1 , 000 , 001 16^{h+1} - 1 \geq 10^6 \\ \Rightarrow 16^{h+1} \geq 1,000,001 16h+1−1≥106⇒16h+1≥1,000,001
取对数:
h + 1 ≥ log 16 ( 1 , 000 , 001 ) h+1 \geq \log_{16}(1,000,001) h+1≥log16(1,000,001)
换底公式:
log 16 ( 10 6 ) = log 10 ( 10 6 ) log 10 ( 16 ) = 6 log 10 ( 16 ) ≈ 6 1.2041 ≈ 4.983 \log_{16}(10^6) = \frac{\log_{10}(10^6)}{\log_{10}(16)} = \frac{6}{\log_{10}(16)} \approx \frac{6}{1.2041} \approx 4.983 log16(106)=log10(16)log10(106)=log10(16)6≈1.20416≈4.983
所以:对应 层数 = h + 1 = 5 层
所以使用B数存储100万数据,最多需要5次磁盘I/O。
B树数据结构存在的缺点是:不适合做区间查找,对于区间查找效率较低。假设要查ID在[2~7]之间的,需要查找的是2,3,4,5,6,7。那么查这每个索引值都需要从头节点开始搜索。会有很多的磁盘I/O操作。所以MySQL的索引不采用B树数据结构。而B+树解决了区间查找问题。
2.4.4 B+树
B+树相较于B树改进了以下几点:
B+树将数据都存储在叶子节点,并且叶子节点之间使用双向链表进行连接,这样就很适合范围查找。B+树的非叶子节点上只有索引值,没有数据,所以非叶子节点可以存储更多的索引值,这样可以让B+树更矮更胖,提供检索效率。(因为非叶子节点不需要存储实际数据行(如VARCHAR、TEXT等大字段),每个节点的固定大小(如InnoDB默认16KB)可以容纳更多键值-指针对)
有一张表:
| ID | NAME |
|---|---|
| 1 | 林晓峰 |
| 2 | 陈雨桐 |
| 3 | 赵明远 |
| 4 | 黄子涵 |
| 5 | 郭文轩 |
| 6 | 周静怡 |
| 7 | 吴志豪 |
| 8 | 孙雅婷 |
| 9 | 徐瑞阳 |
| 10 | 王小东 |
当阶数m=3时,构建的B+树结构如下:

当查询 ID=10的数据时,只需要4次磁盘I/O。
当采用B+树存储索引时,且更加详细存储结构上这样的。

MySQL为什么选择B+树作为索引的数据结构,而不是B树?
- 非叶子节点上可以存储更多的键值,阶数可以更大,更矮更胖,磁盘
I/O次数少,数据查询效率高- 所有数据都是有序存储在叶子节点上,让范围查找,分组查找效率更高
- 数据页之间、数据记录之间采用链表链接,让升序降序更加方便操作。
如果一张表没有主键索引,那还会创建
B+树吗?答案:当一张表没有主键索引时,会,
InnoDB仍然会创建B+树------但它是基于一个"隐式生成的聚簇索引"(hidden clustered index)构建的。规则:
- 如果定义了主键(
PRIMARY KEY) → 使用主键作为聚簇索引。- 如果没有主键,但有
NOT NULL且唯一的索引(UNIQUE INDEX) → 选用第一个这样的列作为聚簇索引。- 如果以上都没有 →
InnoDB自动创建一个隐藏的 6 字节ROW_ID列,并以此作为聚簇索引。这个隐藏的
ROW_ID是单调递增的整数,对用户不可见(无法通过 SQL 查询到),仅内部使用。
2.5 索引类型及核心优化机制
2.5.1 Hash索引
Hash索引是基于哈希表(Hash Table)实现的。
- 只支持 等值查询
(=、IN),不支持范围查询(>、<、BETWEEN)、排序(ORDER BY)或最左前缀匹配 - 查找时间复杂度为
O(1)(理想情况下) Memory引擎:原生支持显式创建Hash索引。InnoDB引擎:不支持用户显式创建Hash索引,但会自适应地在内存中为热点索引页构建自适应哈希索引(Adaptive Hash Index, AHI),以加速等值查询;
原理如下:
有一张表:
| ID | NAME | AGE |
|---|---|---|
| 1 | 林晓峰 | 18 |
| 2 | 林一霖 | 19 |
| 3 | 陈雨桐 | 20 |
假设给NAME字段上添加了Hash索引,并且构建的Hash表如下:

当查询NAME="陈雨桐"。通过Hash算法将"陈雨桐"转为数组下标,再通过下标找到链表,然后在链表中遍历找到"陈雨桐"的行指针,就找到这行数据。
注意:不同的字符串,经过哈希算法得到的数组下标可能相同,这叫做哈希碰撞/哈希冲突。好的哈希算法应该具有很低的碰撞概率。常用的哈希算法如
MD5、SHA-1、SHA-256等都被设计为尽可能减少碰撞的发生。
Hash索引优缺点:
优点:
- 只能用在等值比较中,效率很高
缺点:
- 无法用于排序、范围扫描
- 哈希冲突可能降低性能
- 不适用于高重复值字段(如性别)
2.5.2 聚簇索引和非聚簇索引
按照数据的物理存储方式不同,可以将索引分为聚簇索引 (聚集索引)和非聚簇索引(非聚集索引)。
聚簇索引
- 每个表有且仅有一个聚簇索引(因为数据只能按一种物理顺序存储)。
InnoDB中,主键就是聚簇索引。如果没有主键,InnoDB会用隐藏ROW_ID构建聚簇索引。- 数据行与索引存储在一起:叶子节点直接包含完整的行数据。
聚簇索引的原理图:(B+树,叶子节点上存储了索引值 + 数据)
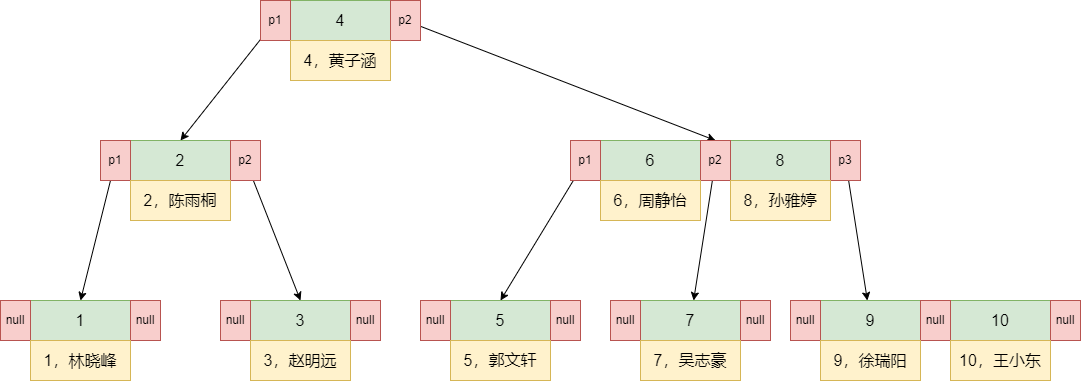
优点:
- 数据与索引一体存储:聚簇索引的叶子节点直接包含整行数据,因此通过聚簇索引查找可以直接返回完整记录,无需额外回表操作。
- 范围查询高效:因为数据按聚簇索引的顺序物理存储,范围扫描(如
WHERE id BETWEEN 10 AND 100)非常快,只需顺序读取磁盘页。 - 主键查询性能最优:主键通常是聚簇索引,因此主键等值查询(
WHERE id = ?)速度极快。 - 减少
I/O次数:对于按聚簇索引顺序访问的数据,可以利用磁盘局部性原理,提升缓存命中率。
缺点:
- 每个表只能有一个聚簇索引:因为数据只能按一种物理顺序存储,无法同时"聚簇"在多个字段上。
- 插入/更新可能引起页分裂:如果插入的数据不是按聚簇索引顺序(如使用
UUID作主键),会导致频繁的页分裂和碎片,降低写入性能。 - 主键设计不当影响性能:若主键过长(如
VARCHAR(255)),会增大所有二级索引的体积(因为二级索引叶子节点存储的是主键值)。 - 不适合频繁更新的列作为聚簇索引:更新聚簇索引列的值会导致整行数据在物理上移动(或重建),开销大。即对数据进行修改或删除时需要更新索引树,会增加系统的开销。
非聚簇索引
- 一张表可有多个聚簇索引
- 索引与数据分开存储:叶子节点只存索引列值 + 主键值(
InnoDB中) InnoDB中的所有二级索引都是非聚簇索引。MyISAM中任意字段上的索引都是非聚簇索引。- 查询时若需要其他字段,需通过主键回表到聚簇索引中查找完整数据。
非聚簇索引的原理图:(B+树,叶子节点上存储了索引值 + 行指针)
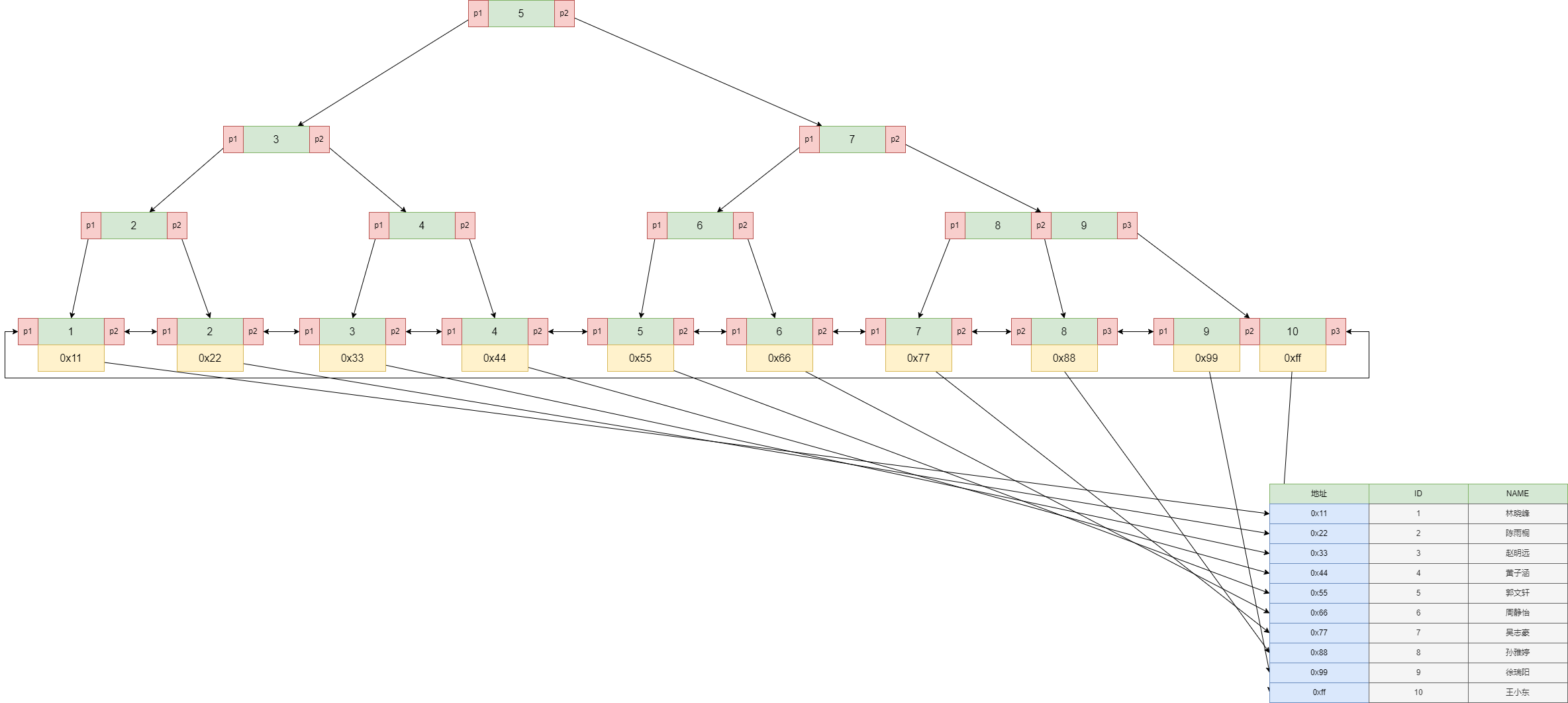
优点:
- 可创建多个:一个表可以有多个非聚簇索引,用于加速不同查询条件(如
name, email, created_at等)。 - 不影响数据物理存储顺序:非聚簇索引是独立结构,不会干扰表的数据组织。
- 支持覆盖索引(
Covering Index):如果查询的所有字段都包含在非聚簇索引中(即"索引覆盖"),无需回表,性能接近聚簇索引。 - 适合高选择性字段:对于唯一或接近唯一的字段(如手机号、邮箱),非聚簇索引能快速定位。
缺点:
- 需要回表(
Lookup):大多数情况下,非聚簇索引只存储主键值,要获取完整数据必须再查一次聚簇索引(即"回表"),增加I/O。 - 占用额外存储空间:每个非聚簇索引都是一棵独立的
B+树,会消耗内存和磁盘空间。 - 维护成本高:每次
INSERT/UPDATE/DELETE操作都可能需要更新多个非聚簇索引,影响写性能。 - 对范围查询效率较低(相比聚簇索引):虽然也能做范围扫描,但若需回表,性能不如聚簇索引的顺序读。
2.5.3 二级索引
二级索引也属于非聚簇索引。也有人把二级索引称为辅助索引。
有一个表STUDENT,ID是主键。AGE是非主键。在AGE字段上添加的索引称为二级索引。(所有非主键索引都是二级索引)
| ID | NAME | AGE |
|---|---|---|
| 1 | 林晓峰 | 21 |
| 2 | 陈雨桐 | 32 |
| 3 | 赵明远 | 42 |
| 4 | 黄子涵 | 39 |
| 5 | 郭文轩 | 41 |
| 6 | 周静怡 | 27 |
| 7 | 吴志豪 | 30 |
二级索引数据结构:
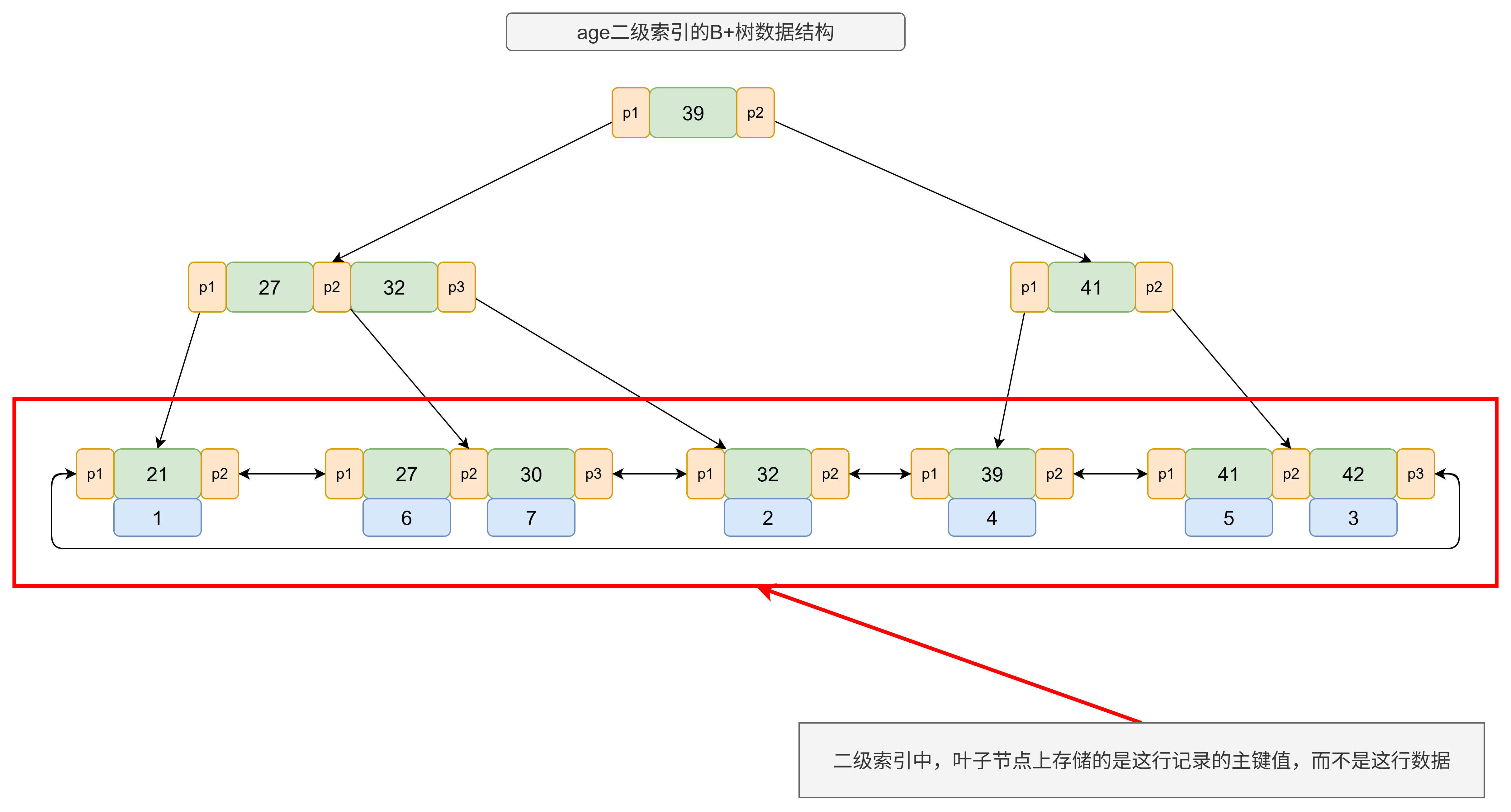
二级索引的查询原理:
例如:查询AGE=30的学生信息
sql
SELECT * FROM STUDNET WHERE AGE = 30;- 在
AGE索引树中找到AGE=30的节点,得到了主键值7 - 再根据主键值,去
主键索引树中,找到这条数据信息。这叫做回表
为什么会"回表"?
因为使用了
SELECT *。避免"回表【回到原数据表】"是提高SQL执行效率的手段。例如:
SELECT ID FROM STUDENT WHERE AGE = 30;这样的SQL语句是不需要回表的,直接就获得了ID值。
2.5.4 单列索引(单一索引)
单列索引,指针对数据库表中的单个字段(单列) 创建的索引,其作用是对该列的数据实现高效的快速查找与排序,能够有效提升数据库的查询响应速度,优化数据库整体检索性能。
举个例子,假设存在一张学生数据表(STUDENT),表中包含字段:学生编号(ID)、姓名(NAME)、年龄(AGE)、性别(GENDER)。
若我们为该表的「学生编号(ID)」列创建单列索引,那么所有以该字段作为查询条件或排序依据的操作,都会得到性能优化。例如执行如下 SQL 查询语句:
sql
SELECT * FROM STUDNET WHERE ID = 1;在建立单列索引的前提下,数据库会直接通过索引快速匹配定位到 ID =1 的数据行,避免了全表扫描的低效检索方式,以此显著加快查询速度。
2.5.5 多列索引(复合索引)
多列索引(Multi-Column Index)也被称作复合索引(Compound Index),指的是基于数据库表中的两个及以上字段共同创建的索引。
与单列索引仅包含单个字段不同,多列索引会将多个列的字段值组合在一起作为索引键,核心作用是大幅提升多字段组合条件查询的检索效率。
举个例子,假设我们有一张订单表(Order),表中包含的字段有:订单编号(OrderID)、客户编号(CustomerID)、订单日期(OrderDate)和订单金额(OrderAmount)。
如果我们为该表的「客户编号」与「订单日期」两个字段创建多列索引 (CustomerID, OrderDate),那么当查询条件中同时包含这两个字段时,数据库就能通过该索引快速定位到匹配的记录。
例如执行如下 SQL 查询语句:
sql
SELECT * FROM `Order` WHERE CustomerID = 1001 AND OrderDate = '2023-02-01';因为提前创建了对应的多列索引 ,数据库可直接通过该索引精准筛选出符合条件的订单记录,无需进行全表扫描,进而显著提升查询速度。
需要注意的是,多列索引 在提升查询效率的同时,也会带来一定的使用成本:创建和维护多列索引会占用更多的存储空间,同时对数据表的新增、修改、删除等写操作的执行效率,会产生轻微的影响。
相较于单列索引,多列索引具备以下优势:
- 减少索引数量:一个多列索引可包含多个查询常用字段,能有效减少数据表中创建的索引总数,降低索引的存储空间占用和日常维护成本。
- 提升多条件查询性能:当查询语句的筛选条件中,包含多列索引的相关字段时,数据库可直接通过多列索引完成高效的条件匹配与数据过滤,大幅提升查询效率。
- 实现覆盖查询:如果多列索引中包含了查询所需的全部字段,数据库可直接从索引中提取返回结果,无需回表查询数据表的原始数据,这也是性能最优的查询方式。
- 优化排序与分组操作 :多列索引本身是按字段组合排序存储的,当查询中涉及基于索引字段的排序(
ORDER BY)或分组(GROUP BY)操作时,可直接使用索引完成排序和分组,无需额外处理,提升操作效率。
2.5.6 覆盖索引
当查询所需的所有字段都包含在某个索引的列中时,数据库可以直接从索引中返回结果,无需回表。这种索引就称为覆盖索引 。
当使用覆盖索引时,MySQL可以直接通过索引,也就是索引上的数据来获取所需的结果,而不必再去查找表中的数据。这样可以显著提高查询性能。
假设有一个用户表(USER)有以下列:ID,NAME,AGE,EMAIL。
需求:根据NAME查询用户的EMAIL。如果为了提高这个查询的性能,可以创建一个多列索引 ,包含(NAME,EMAIL)这两列。使用查询语句时,只查询包含在索引列中的字段,此时这个多列索引就成为了覆盖索引 。覆盖索引 是从使用角度来称呼的。
| ID | NAME | AGE | |
|---|---|---|---|
| 1 | Alice | 20 | Alice@qq.com |
| 2 | Bob | 21 | Bob@qq.com |
| 3 | Cindy | 22 | Cindy@qq.com |
| 4 | Tom | 23 | Tom@qq.com |
创建覆盖索引:
sql
CREATE INDEX INDEX_NAME_EMAIL ON USER(NAME,EMAIL);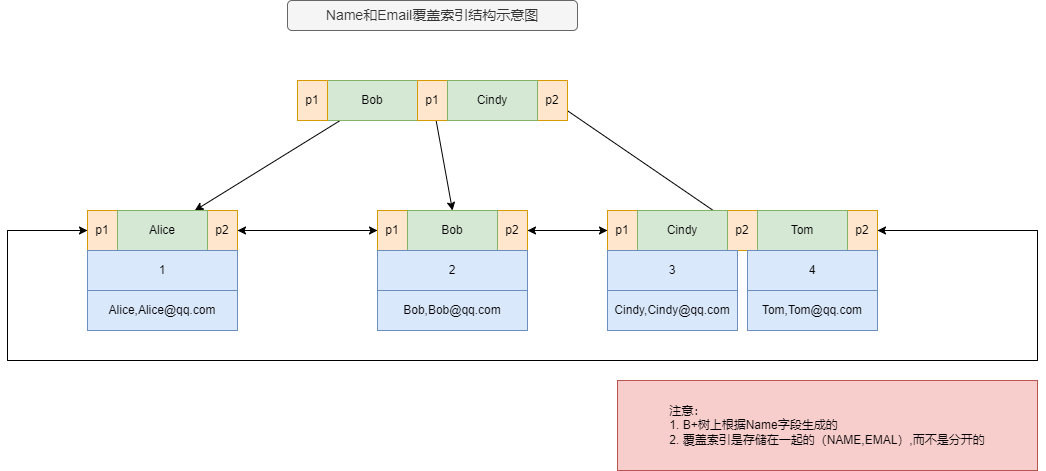
当执行以下查询时:
sql
-- ✅ 覆盖索引:查询字段都在索引中
SELECT EMAIL FROM USER WHERE NAME = 'Tom';→ 可以直接从索引中读取 (NAME, EMAIL),不需要回表访问数据行
sql
-- ❌ 不是覆盖索引:需要 age 字段,不在索引中
SELECT AGE FROM USER WHERE NAME = 'Bob';→ 必须通过 ID=2 回表查找 AGE → 需要额外 I/O
MySQL可以直接使用覆盖索引 (INDEX_NAME_EMAIL)来获取EMAIL,而不必再去查找用户表中的数据。这样可以减少磁盘I/O并提高查询效率。而如果没有覆盖索引,MySQL会先使用索引(NAME)来找到匹配的行,然后再回表查询获取EMAIL,这个过程会增加更多的磁盘I/O和查询时间。
值得注意的是,覆盖索引的创建需要考虑查询的字段选择。如果查询需要的字段较多,可能需要创建包含更多列的覆盖索引,以满足完全覆盖查询的需要。
覆盖索引的优点:
-
提升查询性能
覆盖索引包含查询所需的所有字段,数据库无需回表(即访问主表数据行),可直接从索引中返回结果。这避免了额外的磁盘
I/O和数据页加载,显著加快查询速度。 -
减少 I/O 与内存开销
由于无需读取完整的数据行,系统在磁盘读取和内存缓存方面的压力大幅降低,尤其在高频查询或大数据量场景下效果明显。
-
降低网络传输量(适用于分布式/远程数据库)
当查询结果完全由索引提供时,传输的数据量更小,有助于减少网络带宽消耗,提升响应效率(尤其在客户端-服务器架构中)。
-
减轻系统负载,提升稳定性
在高并发或资源受限的环境中,减少回表操作可有效降低
CPU、I/O和锁竞争等系统开销,从而增强数据库的整体可靠性和可维护性。
覆盖索引的缺点:
-
占用更多存储空间
覆盖索引需包含多个列的数据,导致索引体积显著增大,可能消耗大量磁盘空间,尤其在宽表或大字段(如
TEXT、VARCHAR长字符串)被纳入索引时更为明显。 -
增加写操作成本
索引越大,对
INSERT、UPDATE和DELETE操作的影响越显著------每次数据变更都需同步更新庞大的索引结构,可能拖慢写入性能。 -
使用条件受限
仅当查询的
SELECT列和WHERE条件中的字段全部被索引覆盖时,才能触发覆盖索引。若查询涉及未包含的列,数据库仍需回表,无法享受性能优势。
💡 最佳实践建议 :
覆盖索引并非"越多越好"。应结合高频查询模式,选择性地为关键查询路径设计精简、高效的覆盖索引,平衡读写性能与存储成本。
2.5.7 索引下推
索引下推(Index Condition Pushdown,简称 ICP)是 MySQL 数据库中针对索引查询的重要性能优化手段。该优化的核心逻辑是:将查询语句中的部分过滤条件,直接下推到数据库的「索引检索层级」提前执行过滤,以此减少无效的回表次数,大幅优化查询的整体性能。
具体来说,在未开启索引下推时,MySQL 仅通过索引快速匹配到符合索引前置条件的记录后,就会立刻通过主键回表读取完整的数据行,再在内存中对剩余的过滤条件进行筛选;而开启索引下推优化后,MySQL 会在索引的叶子节点层级就执行相关的过滤条件,提前过滤掉不满足条件的索引记录,只将真正符合全部条件的记录主键返回,再基于这些有效主键进行回表操作。这种方式能避免对无效数据的回表读取,减少磁盘 I/O 开销,从而缩短查询耗时。
索引下推的优化逻辑通常基于多列(复合)索引生效,单列索引场景下几乎没有该优化的适用空间。
假设有如下 USER 用户表结构及数据:
| ID | NAME | AGE | CITY |
|---|---|---|---|
| 1 | 吕木云 | 27 | 上海 |
| 2 | 黄芸欢 | 21 | 深圳 |
| 3 | 王芸茜 | 29 | 北京 |
| 4 | 黄文旺 | 30 | 云南 |
| 5 | 陈馨薇 | 28 | 深圳 |
为该表创建多列索引:
sql
ALTER TABLE USER ADD INDEX IDX_NAME_CITY_AGE (NAME, CITY, AGE);举个应用案例,需求为:查询所在城市是 深圳 且年龄大于 25 岁的用户信息,对应的查询语句为:
sql
SELECT * FROM USER WHERE CITY = '深圳' AND AGE > 25;如果仅为 AGE 字段创建单列索引,该场景无法触发索引下推优化。传统的查询方式中,数据库会先通过年龄索引读取所有满足 age > 25 的记录并完成回表,再在内存中逐一筛选出城市为 深圳 的数据,这个过程会产生大量无效的回表 I/O 操作。
而基于上述的多列索引 IDX_NAME_CITY_AGE (NAME, CITY, AGE) 开启索引下推后,查询的执行逻辑发生了本质优化:数据库在扫描多列索引的过程中,会在索引层级就同时校验 CITY = '深圳' 和 AGE > 25 两个过滤条件,只筛选出同时满足双条件的索引记录。
只有通过索引层级过滤后的有效记录,才会被执行回表操作,读取数据表中的完整行数据,最终返回结果。
这种优化方式的核心价值,就是通过索引层的前置过滤,减少了不必要的磁盘 I/O 和数据传输,从根源上提升了多条件查询的执行效率。
- 索引下推的核心特点:不是取消回表,而是减少回表的次数;该优化和覆盖索引是两种不同的性能优化思路,覆盖索引是「彻底避免回表」,索引下推是「减少无效回表」。
- 索引下推是「查询执行阶段」的优化策略,覆盖索引是「索引使用角度」的最优状态,多列索引是「索引创建角度」的类型;三者结合使用时,能实现 MySQL 查询性能的最大化优化,也是实际业务中最常用的索引优化组合。
2.6 索引优缺点
索引是数据库中用于优化数据检索效率的重要数据结构,能够快速定位目标数据,有效加速查询操作,其优缺点如下:
优点:
- 提升查询性能:通过索引快速定位数据,减少查询扫描的数据量,大幅加快数据检索速度。
- 优化排序效率:借助索引的有序存储特性,可快速完成字段的排序与分组,降低排序的资源消耗。
- 减少磁盘 I/O :避免全表扫描的大量磁盘读写,减少磁盘
I/O次数,提升数据读取效率。
缺点:
- 占用额外存储空间:索引作为独立数据结构,会占用一定的物理存储,数据量越大、索引越多,空间占用越明显。
- 损耗写操作性能:执行插入、更新、删除操作时,需同步更新索引,增加操作耗时,降低写操作效率。
- 消耗系统资源 :索引的检索与维护会占用内存、
CPU资源,高并发场景下可能影响数据库整体性能。
2.7 索引的适用场景和不适用场景
索引是数据库性能优化的核心手段,但并非所有场景都适用。需结合表的数据量、读写频率、业务需求等因素综合判断,具体的适用与不适用场景如下:
建议创建索引的场景:
- 高频查询的字段:
对于经常出现在WHERE条件、JOIN关联条件中的字段,创建索引能大幅减少数据库的扫描范围,直接定位目标数据,显著提升查询响应速度。例如用户表的ID、订单表的NO这类高频查询字段,非常适合建立索引。 - 数据量大的表(大表):
当数据表的记录数达到数万甚至数十万级别时,全表扫描的耗时会急剧增加。此时为查询字段建立索引,可避免全表扫描的低效操作,快速定位所需数据,优化效果会非常明显。而小表的全表扫描本身耗时极短,索引的优化收益有限。 - 需排序 / 分组的字段:
对于经常出现在ORDER BY、GROUP BY子句中的字段,创建索引能利用索引的有序存储特性,避免数据库执行额外的排序计算,直接通过索引完成排序或分组操作,大幅降低资源消耗。 - 键关联字段:
在多表关联查询(如JOIN操作)中,外键字段是表与表之间的关联纽带。为外键字段建立索引,能加速表之间的关联匹配过程,避免关联时的全表扫描,提升多表查询的整体效率。 - 唯一性高的字段:
字段的唯一性越高,索引的筛选效率就越强。例如ID、手机号这类唯一性 接近100%的字段,索引能快速匹配到单条记录;反之,唯一性低的字段索引效果会大打折扣。
不建议创建索引的场景:
- 高频更新的表或字段
对频繁执行INSERT、UPDATE、DELETE操作的表或字段,不建议创建过多索引。因为每次写操作不仅要修改数据表的原始数据,还需要同步更新所有关联的索引结构,这会显著增加写操作的耗时,降低业务的写入性能。 - 数据量极小的表(小表)
对于仅包含数百、数千条记录的小表,全表扫描的时间成本极低,索引带来的查询性能提升几乎可以忽略不计。此时创建索引反而会额外占用存储空间,增加数据库的维护负担。 - 唯一性极差的字段
对于性别(仅男 / 女)、状态(仅启用 / 禁用)这类取值范围极小、唯一性极差的字段,不建议创建索引。这类字段的索引筛选效果差,查询时大概率仍需扫描索引的大部分数据,甚至索引文件的体积会超过数据表本身,既浪费存储空间,又无法有效提升查询效率。 - 查询结果占比极高的字段
如果查询语句需要返回表中 30% 以上的记录,使用索引的效率反而不如全表扫描。因为此时数据库需要频繁地在索引和数据表之间切换读取,产生大量额外I/O开销。
总结:索引的核心本质是「以空间换时间」,即用索引占用的额外存储空间,换取查询效率的大幅提升;实际应用中需合理创建索引,平衡查询性能与写操作效率,避免过度建索引或建无效索引。