一、MySQL进阶
"当凌晨三点的电商网站因数据丢失而崩溃时,一个叫InnoDB的引擎正在默默守护着下一次的崛起。"
------ 一场关于可靠性与性能的数据库革命,如何改变互联网的底层逻辑?
2000年,互联网正经历Web 2.0的爆发式增长。电商、社交平台如雨后春笋般涌现,但MySQL的默认存储引擎MyISAM却成了系统崩溃的定时炸弹:
- ❌ 不支持事务:用户下单后支付失败,订单却已扣款
- ❌ 表级锁 :一个
UPDATE锁死整张表,高并发下系统直接瘫痪 - ❌ 崩溃恢复慢:服务器宕机后,修复数据需数小时
💡 2002年,eBay因MyISAM锁表问题导致12小时宕机,损失超$500万。这场危机,直接催生了InnoDB的诞生。
InnoDB由芬兰公司Innobase Oy开发(2000年),2005年被Oracle收购,2006年随MySQL 5.0成为默认事务型存储引擎 。它的诞生,是数据库领域对"可靠性 "与"高并发"的终极妥协。
1. InnoDB引擎-架构
InnoDB的架构可拆解为三大核心系统,像人体的大脑(内存)、骨骼(磁盘)、神经系统(后台线程),共同支撑起高可用数据库:
内存结构(Buffer Pool) → 数据缓存中枢
磁盘结构(表空间/页) → 数据持久化根基
后台线程(Master Thread)→ 系统自愈引擎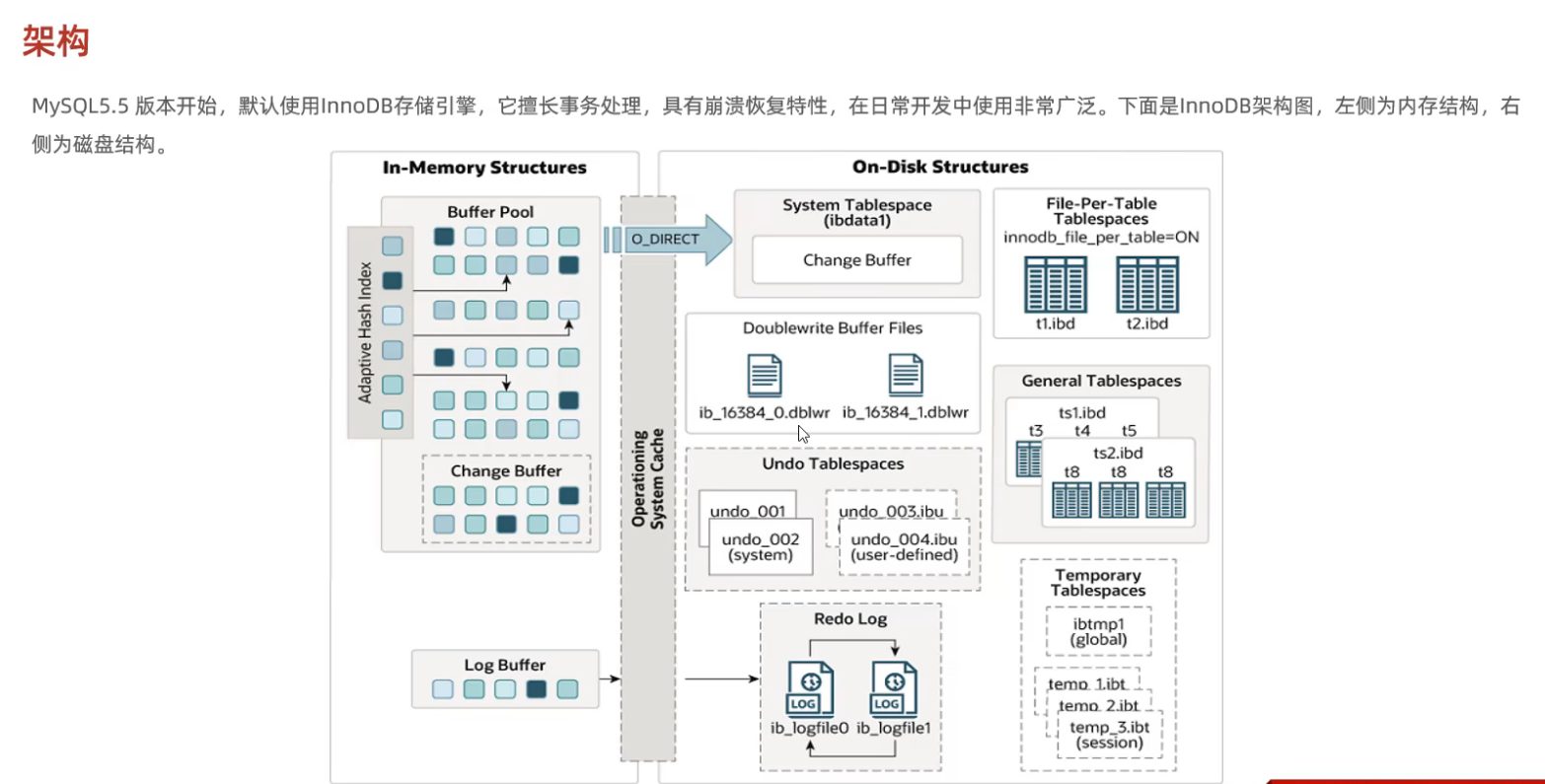
✅ 专业提示:InnoDB的架构设计哲学是 "用内存加速,用磁盘保证可靠"。
内存结构:性能的"加速引擎"
在数据库的世界里,磁盘 I/O 是性能的头号敌人 。想象一下:当你查询一条数据时,如果每次都得从磁盘读取(速度约10ms),而如果能从内存中获取(速度约0.1ms),性能提升将高达100倍!
InnoDB 的内存结构,就是为了解决这个问题而生的。它像一座智能高速公路,让数据在内存中"飞驰",而非在磁盘上"爬行"。
💡 现实案例:某电商平台将 Buffer Pool 从 2GB 提升至 8GB 后,查询响应时间从 50ms 降至 5ms,系统吞吐量提升 10 倍!
InnoDB 的内存结构可概括为四大核心组件:
Buffer Pool(缓冲池) ← 核心中的核心
↓
Change Buffer(变更缓冲区)
↓
Adaptive Hash Index(自适应哈希索引)
↓
Log Buffer(日志缓冲区)这四者共同构成 InnoDB 的"内存高速公路",让数据查询和更新如鱼得水。
缓冲池(Buffer Pool):内存的"数据高速公路"
Buffer Pool 是 InnoDB 最重要的内存组件,它缓存了从磁盘读取的数据页和索引页,让后续查询无需再访问磁盘。
为什么重要?
- 通常配置为物理内存的 50%~80%
- 减少磁盘 I/O 次数 → 提升查询速度
- 为其他内存组件提供基础支持
页的类型管理(Buffer Pool 的"交通规则")
Buffer Pool 中的数据页分为三类:
| 类型 | 含义 | 状态 | 说明 |
|---|---|---|---|
| Free Page | 空闲页 | 未被使用 | 可分配给新数据 |
| Clean Page | 干净页 | 与磁盘一致 | 无需刷盘 |
| Dirty Page | 脏页 | 内存已修改,磁盘未更新 | 需要刷盘 |

🌟 关键点:Buffer Pool 通过三种链表管理这些页:
- Free List:管理空闲页
- Flush List:管理脏页(按修改时间排序)
- LRU List:管理正在使用的页
改进型 LRU 算法:如何避免"热数据"被刷出内存?
普通 LRU:新数据从链表头部加入,释放空间时从末尾淘汰
InnoDB 改进版 LRU :将新数据插入到 LRU 列表的 3/8 处,形成两个区域:
- New 区域(63%):存放频繁访问的数据
- Old 区域(37%):存放使用较少的数据
💡 为什么这样设计?
- 避免"热点数据"被意外淘汰
- 保证高频查询的数据始终在内存中
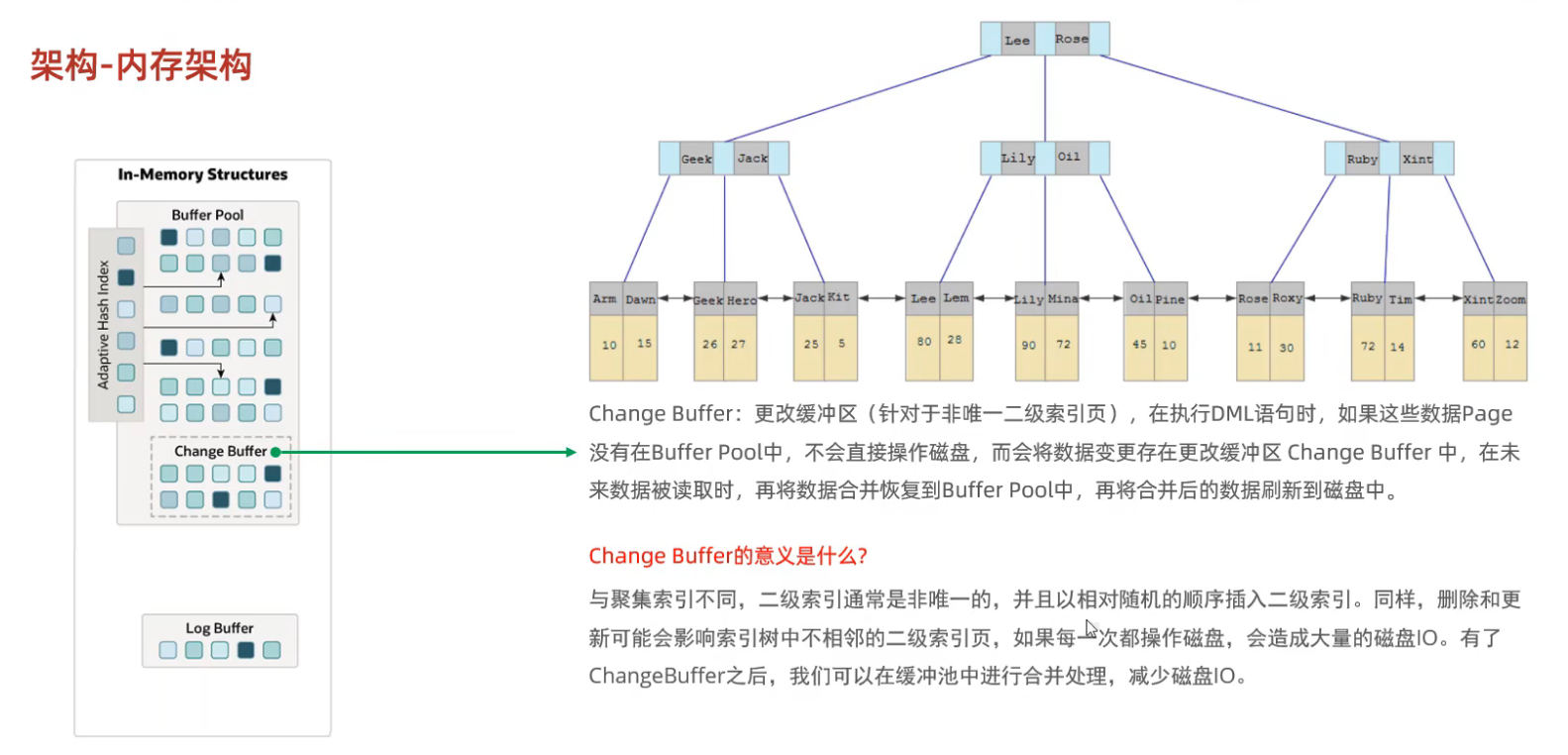
变更缓冲区(Change Buffer):写操作的"智能调度员"
Change Buffer 用于优化对"非唯一二级索引"的写操作。
❌ 问题背景
当对二级索引进行更新(INSERT/UPDATE/DELETE)时,如果索引页不在 Buffer Pool 中:
- 需要从磁盘加载索引页(随机 I/O,很慢)
- 写入索引页(随机 I/O,很慢)
✅ 解决方案:Change Buffer
- 如果目标索引页不在 Buffer Pool 中,InnoDB 不立即写入磁盘
- 而是将变更暂存到 Change Buffer
- 后续当该页被加载到 Buffer Pool 时,再将变更合并到实际索引页
💡 适用场景:仅适用于非唯一二级索引(唯一索引必须立即检查冲突)
📊 效果对比
| 操作 | 无 Change Buffer | 有 Change Buffer |
|---|---|---|
| 随机 I/O | 10 次 | 1 次 |
| 写入时间 | 10ms | 1ms |
| 系统吞吐量 | 1000 QPS | 8000 QPS |
✅ 优势:将多次随机写合并为一次顺序读+一次写,大幅提升写性能
自适应哈希索引(Adaptive Hash Index):自动优化的"智能加速器"
自适应哈希索引是 InnoDB 根据查询模式自动构建的哈希索引,用于加速等值查询。
🔍 为什么需要哈希索引?
- B+ Tree 索引:需匹配 2-3 次(O(log n))
- 哈希索引:只需一次匹配(O(1))
💡 但哈希索引的局限:不能做范围查询,只能做等值匹配
🤖 自适应哈希索引如何工作?
- InnoDB 监控索引的查询频率
- 当发现某些索引页被频繁访问时
- 自动为这些页上的索引键建立哈希索引
- 将 B+ Tree 的随机访问转化为哈希表的 O(1) 访问
📈 实际效果
- 等值查询速度提升 5-10 倍
- 无需人工干预,自动管理
- 仅对热点数据生效,不影响其他查询
💡 重要提示:自适应哈希索引是自动管理的,不需要手动配置。

日志缓冲区(Log Buffer):事务安全的"保险箱"
日志缓冲区用于暂存事务生成的 Redo 日志,减少 Redo 日志的磁盘 I/O 次数。
📌 为什么需要日志缓冲区?
- 事务提交时,必须确保数据持久性
- Redo 日志是崩溃恢复的关键
- 频繁写磁盘会导致性能下降
⚙️ 工作流程
- 事务执行时,修改数据页
- 将修改记录写入 Log Buffer
- 事务提交时,将 Log Buffer 中的数据写入磁盘
- 通过
innodb_log_buffer_size控制缓冲区大小
✅ 优势:减少磁盘 I/O,提升事务提交速度

内存结构协同工作:一次查询的旅程
让我们用一个实际查询来理解内存结构的协同工作:
sql
SELECT name FROM users WHERE id = 100;- Buffer Pool :检查是否缓存了包含
id=100的页- 如果命中(命中率高),直接返回结果
- 如果未命中,从磁盘读取数据页到 Buffer Pool
- 自适应哈希索引 :如果
id是热点查询字段,会自动建立哈希索引- 使查询从 B+ Tree 的 O(log n) 降至 O(1)
- Log Buffer:如果该查询涉及修改(如 UPDATE),会先写入日志缓冲区
- Change Buffer:如果涉及二级索引更新且页不在 Buffer Pool 中,会暂存变更
🌟 这个过程的全部时间,可能只有 0.1ms(相比磁盘 I/O 的 10ms,提升了 100 倍)!
| 组件 | 默认值 | 推荐值 | 适用场景 |
|---|---|---|---|
| Buffer Pool | 128MB | 50%~80% 物理内存 | 所有场景 |
| Buffer Pool Instances | 1 | 4~8 | 多核 CPU 服务器 |
| Change Buffer | 默认开启 | 无需配置 | 高并发写入场景 |
| Adaptive Hash Index | 默认开启 | 无需配置 | 热点查询场景 |
| Log Buffer | 16MB | 64MB~128MB | 高事务写入场景 |
💡 重要提示:不要过度配置。内存是有限的,过多配置会导致系统交换(Swap),反而降低性能。