有网友提了这几个需求,这里,我整理了特别篇发出来
本篇内容非常重要!!全是干货!!归档了Redis十大经典面试题,足以应对高级开发面试
1~5题见《7天学会Redis》特别篇:Redis十大经典面试题
6、redis与数据库的数据一致性,项目是如何保障的
⭐原则:根据实际项目的实际情况,先讲清楚策略,再加上补偿机制
回答:
公司目前的项目使用Cache-Aside(旁路缓存) + 异步补偿(Binlog / MQ)策略。
这里可以详细介绍旁路策略的四种一致性方案的区别。先更新数据库后更新缓存、先更新数据库后删除缓存、先删缓存后更新数据库、先更新缓存后更新数据库。
✅ 核心思想:
- 写操作只负责更新 DB + 删除缓存(一次删)
- 通过 Binlog 或 MQ 异步监听 DB 变更,二次兜底删缓存
补偿机制(后台异步)
方案 1 :监听 MySQL Binlog(推荐)
- 使用 Canal / Debezium / Flink CDC 捕获 DB 变更
- 消费 Binlog → 自动删除或更新对应缓存
- 优势:与业务代码解耦,100% 捕获 DB 变更(包括非应用写入)
方案2: mq异步删除
- 更新数据库后,发送MQ
- 使用RocketMq,若失败自动重试
扩展:
详细见这期内容《7天学会Redis》特别篇: 如何保证缓存与数据库的数据一致性?****
7、大key有没有遇到过,怎么解决的?除了拆分,还有什么办法
⭐原则: 先讲清楚什么是"大 Key",再提出解决方案,最后提一些遇到过的大key,以及解决办法。
回答:
1、什么是"大 Key"?
- String:value > 10KB(如序列化后的对象、大 JSON)
- List/Hash/Set/ZSet:元素数量 > 1 万 或 总内存 > 10MB
2、解决方案
**拆分,**按业务拆或者按量大小拆,再业务代码层再合并
压缩存储(减少内存占用),对 String 类型的大 Value,在应用层压缩后再存入 Redis
使用更适合的数据结构,按业务实际需要合理存储
冷热分离 + 自动归档:
- 定时任务扫描大 Key,按访问时间判断冷热
- 冷数据写入 MySQL,Redis 中仅保留"是否存在"标记
3、项目上的场景
bash# 扫描大Key redis-cli --bigkeys redis-memory-for-key user:1001:history场景: 缓存了前1000个kol的数据,其中图片数据转base64后一并存储,导致redis读取速度过慢,接口查询速度超过5s
扩展:
这里设计大key,可能会关联到内存淘汰机制
8、redis哨兵模式至少要几个redis服务,如何实现
⭐原则:讲清楚哨兵模式即可
回答:
至少需要:3 个 Redis 节点(1 主 + 2 从) + 3 个 Sentinel(哨兵)进程
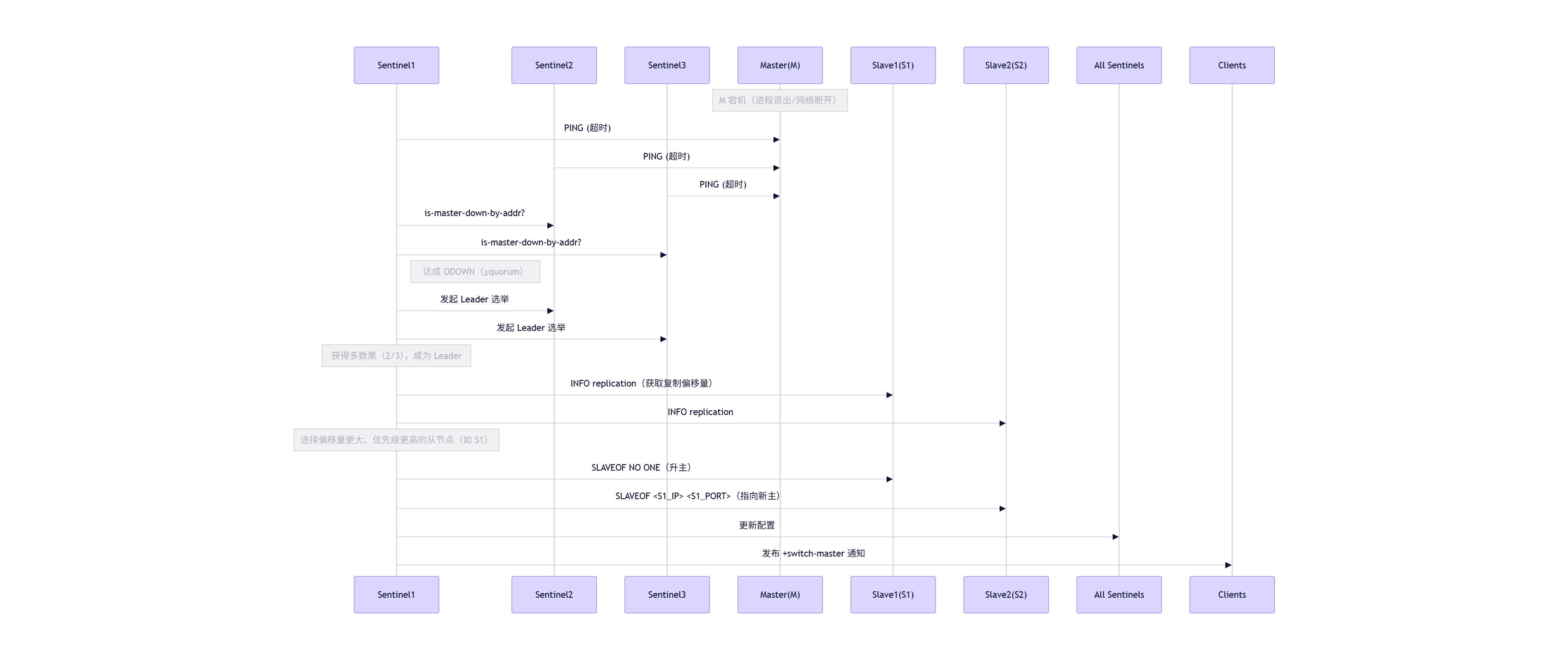
组件 最小数量 为什么? Redis 数据节点 3 个(1 主 + 2 从) - 主节点故障时,需有从节点可升主 - 2 个从节点保证多数派投票安全(防脑裂) Sentinel 哨兵进程 3 个 - 哨兵通过 quorum(法定人数) 投票判断主是否宕机 - 必须奇数个 (避免平票) - 最少 3 个才能容忍 1 个哨兵宕机 **这里注意误区,**我之前的理解误区:若是三个,其中一个redis实例down了,剩余两个怎么选举,万一1:1,选举就失败了。
实际结果:Redis 哨兵模式中的"选举"分为两个层面 ,而主从节点本身不参与投票
两层选举机制
选举类型 谁参与? 目的 投票规则 1. 判断主是否宕机(ODOWN) Sentinel 哨兵之间 决定是否触发故障转移 需 ≥ quorum个哨兵同意2. 选新主(Failover) Sentinel 选从节点 从现有从节点中挑一个升主 Sentinel Leader 单独决定(无需从节点投票)
场景模拟:
- 初始状态:1 主(M) + 2 从(S1, S2)
- M 宕机 → 剩下 S1 和 S2(都是从节点,只负责被选,不参与选)
- 3 个 Sentinel 检测到 M 不可达
- 若 ≥
quorum(如 2 个)哨兵认为 M 宕机 → 触发故障转移- Sentinel 们先选举出一个 Leader(需多数派,3 个哨兵可容忍 1 个故障)
- Leader Sentinel 从 S1、S2 中选一个作为新主(根据优先级、复制偏移量等)
📌 从节点只是"候选人",不是"投票人"。所以不存在"两个从节点 1:1 投票"的情况,如图
⚠️ 注意:
- 哨兵进程可以和 Redis 节点部署在同一台机器(节省资源),但生产环境建议独立部署;
- 绝对不能只有 2 个哨兵:若一个宕机,剩下一个无法形成多数派(1/2 < 50%),无法自动故障转移。
哨兵系统通过 "监控 + 通知 + 自动故障转移" 三步实现高可用:
- 监控(Monitoring)
- 每个 Sentinel 每秒向 主、从、其他哨兵 发送
PING- 检测 Redis 节点是否存活(主观下线)
- 多个 Sentinel 达成共识 → 客观下线(ODOWN)
- 自动故障转移(Automatic Failover)
当主节点被判定 ODOWN 后:
选举 Leader Sentinel :
- 所有 Sentinel 通过 Raft-like 协议选举一个 Leader(需获得 多数票)
Leader 执行故障转移 :
- 从从节点中选一个 最优从节点(优先级、复制偏移量、runid)
- 将其提升为新主(
SLAVEOF NO ONE)- 通知其他从节点复制新主
- 更新配置并通知客户端
通知(Notification)
- 通过 API 或 Pub/Sub 通知客户端主节点已变更
- 客户端重新连接新主(需客户端支持,如 Jedis 的
SentinelPool)9、redis分布式锁,如果是集群,如何保证分布式锁正常生效。项目上有用到吗
⭐原则:讲述分布式锁实现,重点讲集群环境下的RedLock算法
回答:
第一步先说明问题
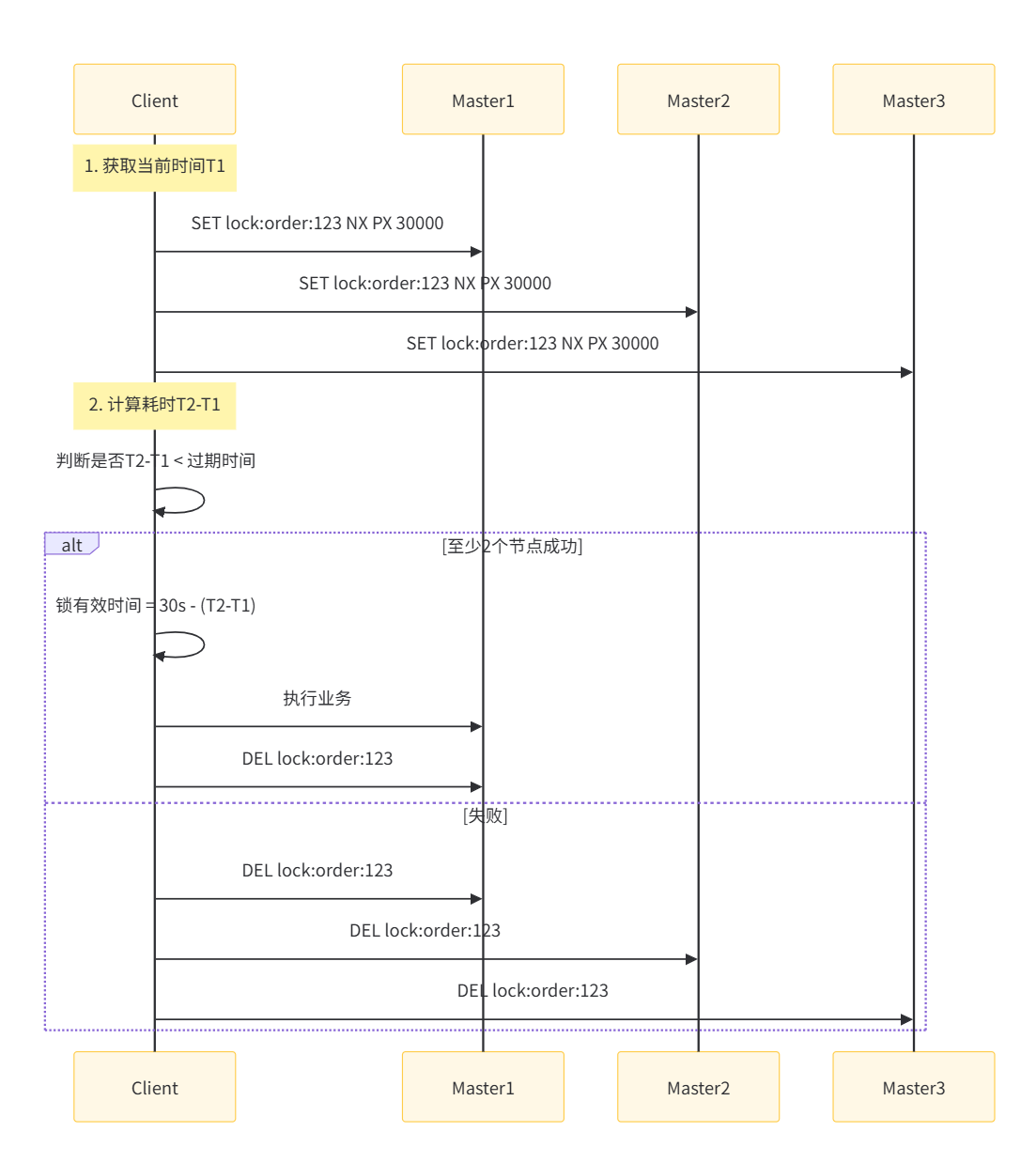
问题:主从异步复制 + 故障转移 = 锁可能失效
- 客户端 A 在 主节点 上成功加锁(
SET key value NX PX 10000)- 主节点将写操作异步复制给从节点
- 此时主节点宕机,某个从节点被提升为新主
- 但新主尚未收到锁的写入 → 锁"消失"
- 客户端 B 可在新主上再次加锁 → 两个客户端同时持有同一把锁!
📌 这违反了分布式锁的互斥性,是严重问题。
第二步,RedLock整体流程如下
第三步,讲述项目上实际使用。项目上使用redissio框架使用缓存。讲到redsiison,一般都会问到看门狗机制
扩展:
《7天学会Redis》Day 7 - Redisson 全览
10、项目上使用redission,解释下看门狗机制。做分布式锁时,如果锁到期没释放怎么办。
⭐原则:看门狗机制的启动,作用,结束全流程
回答:
✅1、看门狗线程什么时候启动?
在成功加锁(
lock()或tryLock())且未指定leaseTime时,Redisson 会为该锁启动一个 Watchdog 任务。✅2、看门狗线程做了什么?(核心逻辑)
Watchdog 不是一个独立线程 ,而是由 Redisson 的
ConnectionWatchdog线程池中的定时任务执行(基于 Netty 的 EventLoop 或 ScheduledExecutorService)。🛠️ 每次执行的动作(每
internalLockLeaseTime / 3执行一次,默认 10 秒):
-- Lua 脚本(伪代码) if redis.call("HEXISTS", KEYS[1], ARGV[1]) == 1 then return redis.call("PEXPIRE", KEYS[1], ARGV[2]) else return 0 end具体行为:
- 检查当前线程是否仍持有该锁
- 通过锁 key 中存储的 唯一线程标识(UUID + threadId) 判断
- 如果持有,则将锁的 TTL 重置为
lockWatchdogTimeout(默认 30 秒)- 如果不持有(已被 unlock),则取消后续续期任务
⏱️ 执行频率 :
默认
lockWatchdogTimeout = 30_000 ms→ 每 10 秒 续期一次✅三、看门狗任务什么时候结束?
Watchdog 任务会在以下任一条件满足时立即取消:
- 显式调用
unlock()
- Redisson 在
unlock()时,会:
- 删除 Redis 中的锁 key
- 主动取消该锁对应的 Watchdog 定时任务
- JVM 进程退出
- Watchdog 是 JVM 内的定时任务,进程终止 → 任务自然消失
- 此时 Redis 中的锁会在 30 秒后自动过期(由 Redis 的 TTL 机制保证)
- Redis 连接断开(极端情况)
- 若 Redis 宕机或网络中断,续期失败
- 但锁仍会在原始 TTL(30 秒)后过期,不会造成死锁
❗ 注意 :
Watchdog 不会因为业务线程阻塞(如 Full GC)而停止,只要 JVM 活着,它就会继续尝试续期。
总结发言:Redisson 的看门狗是一个定时续期任务 ,在调用无参 lock() 成功后启动。
它每 10 秒检查一次当前线程是否仍持有锁,如果是,就将锁的 TTL 重置为 30 秒。
当调用 unlock() 或 JVM 退出时,该任务会立即取消。它的核心价值是让开发无需预估业务耗时 ,但关键操作我们仍会手动指定租约时间并配合幂等设计。