PaddleOCR‑VL(CUDA 11.8 + A10)Docker 部署实战教程(含离线模型、接口调用、排障)
本文只记录 OCR 服务(PaddleOCR‑VL) 的部署与验证,不包含任何业务前后端代码。
开源地址:https://github.com/PaddlePaddle/PaddleOCR
部署目标
- 服务能力 :提供
POST /layout-parsing的 HTTP API,对图片/PDF进行文档解析,返回结构化结果与markdown.text。 - 部署方式:Docker Compose 一键构建/启动。
- GPU:支持 NVIDIA GPU(示例为 A10),可配置使用多张卡。
- 离线运行:在构建镜像阶段下载模型文件(可能需要代理,可自行换国内源),部署后即使关闭 VPN 也能推理。
前置条件
- 硬件/系统:x86_64 Linux + NVIDIA A10 GPU * 4。
- 软件 :
- Docker(建议 20.10+)
- Docker Compose 插件(
docker compose) - NVIDIA 驱动 + NVIDIA Container Toolkit(保证容器内可见 GPU,安装步骤自行查询)
执行以下命令可以看到 GPU 列表则证明NVIDIA Container Toolkit生效了
docker run --rm --gpus all nvidia/cuda:12.2.0-base-ubuntu22.04 nvidia-smi
说明:本文使用的基础镜像为ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.2.2-gpu-cuda11.8-cudnn8.9。
目录结构(部署文件位置)
以 PaddleOCR 仓库为例,本教程使用以下目录:
PaddleOCR/deploy/paddleocr_vl_docker/accelerators/gpu-cu118/.envcompose.yamlpipeline.Dockerfile
你可以把该目录拷贝到服务器任意位置(例如 /opt/paddle-ocr/gpu-cu118)独立使用。
1. 拉取基础镜像(可选但推荐)
在 OCR 服务器执行:
bash
docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.2.2-gpu-cuda11.8-cudnn8.92. 部署配置文件(原样贴出)
2.1 .env
text
# 使用 CUDA 11.8 / Paddle 3.2.2 的本地构建镜像(适配你已拉取的 paddle:3.2.2-gpu-cuda11.8-cudnn8.9)
# 如需指定 GPU 卡号:编辑 compose.yaml 中 device_ids
BUILD_FOR_OFFLINE=true
PADDLEOCR_PORT=15000BUILD_FOR_OFFLINE=true:构建阶段下载模型,保证后续离线可推理。PADDLEOCR_PORT=15000:宿主机暴露端口(容器内服务端口固定为8080)。
2.2 compose.yaml
yaml
services:
paddleocr-vl-api:
build:
context: .
dockerfile: pipeline.Dockerfile
# 关键:构建阶段使用宿主机网络,确保能走宿主机 VPN / DNS
network: host
args:
BUILD_FOR_OFFLINE: ${BUILD_FOR_OFFLINE:-true}
image: paddleocr-vl-api:cu118
container_name: paddleocr-vl-api
restart: unless-stopped
ports:
- "${PADDLEOCR_PORT:-15000}:8080"
environment:
- TZ=Asia/Shanghai
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["0", "1", "2", "3"]
capabilities: [gpu]
healthcheck:
test: ["CMD-SHELL", "curl -fsS http://localhost:8080/health || exit 1"]
interval: 30s
timeout: 5s
retries: 10
start_period: 120s说明:
build.network: host:非常关键。很多环境在 Docker build 阶段会出现 DNS/VPN/IPv6 路由导致的apt-get update卡住,这个配置能显著提升稳定性。device_ids:这里让容器"可见" 0~3 四张卡。- 注意:PaddleOCR‑VL‑0.9B 在日志中可能提示 batch size=1,这意味着 单请求不一定能吃满 4 卡;多卡更常见的收益是并发吞吐。
2.3 pipeline.Dockerfile
dockerfile
FROM ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.2.2-gpu-cuda11.8-cudnn8.9
ENV DEBIAN_FRONTEND=noninteractive
ENV PIP_NO_CACHE_DIR=0
ENV PYTHONUNBUFFERED=1
ENV PYTHONDONTWRITEBYTECODE=1
# 基础依赖:curl(健康检查)、wget(离线模型下载)、libgl1(OpenCV/可视化依赖)
# 说明:部分环境 Docker build 阶段可能存在 DNS/IPv6/VPN 路由问题,导致 apt-get update 卡住。
# 这里强制 IPv4 + 增加重试与超时,提升构建稳定性。
RUN set -eux; \
printf 'Acquire::ForceIPv4 "true";\nAcquire::Retries "5";\nAcquire::http::Timeout "30";\nAcquire::https::Timeout "30";\n' > /etc/apt/apt.conf.d/99-ocr-network; \
apt-get update; \
apt-get install -y --no-install-recommends \
curl \
wget \
ca-certificates \
libgl1 \
libglib2.0-0 \
; \
rm -rf /var/lib/apt/lists/*
RUN python -m pip install --upgrade pip
ARG PADDLEOCR_VERSION=">=3.3.2,<3.4"
RUN python -m pip install "paddleocr[doc-parser]${PADDLEOCR_VERSION}" \
&& paddlex --install serving
# PaddleOCR-VL 依赖:文档解析需要特殊版本 safetensors(官方推荐)
# 注意:安装 PaddleOCR 依赖时可能自动升级 safetensors,这里在最后强制回装官方特殊版本。
RUN python -m pip install --force-reinstall https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
# 使用非 root 用户运行服务
RUN groupadd -g 1000 paddleocr \
&& useradd -m -s /bin/bash -u 1000 -g 1000 paddleocr
ENV HOME=/home/paddleocr
WORKDIR /home/paddleocr
ARG BUILD_FOR_OFFLINE=false
RUN if [ "${BUILD_FOR_OFFLINE}" = 'true' ]; then \
mkdir -p "${HOME}/.paddlex/official_models" \
&& cd "${HOME}/.paddlex/official_models" \
&& wget -q \
https://paddle-model-ecology.bj.bcebos.com/paddlex/official_inference_model/paddle3.0.0/UVDoc_infer.tar \
https://paddle-model-ecology.bj.bcebos.com/paddlex/official_inference_model/paddle3.0.0/PP-LCNet_x1_0_doc_ori_infer.tar \
https://paddle-model-ecology.bj.bcebos.com/paddlex/official_inference_model/paddle3.0.0/PP-DocLayoutV2_infer.tar \
https://paddle-model-ecology.bj.bcebos.com/paddlex/official_inference_model/paddle3.0.0/PaddleOCR-VL_infer.tar \
&& tar -xf UVDoc_infer.tar \
&& mv UVDoc_infer UVDoc \
&& tar -xf PP-LCNet_x1_0_doc_ori_infer.tar \
&& mv PP-LCNet_x1_0_doc_ori_infer PP-LCNet_x1_0_doc_ori \
&& tar -xf PP-DocLayoutV2_infer.tar \
&& mv PP-DocLayoutV2_infer PP-DocLayoutV2 \
&& tar -xf PaddleOCR-VL_infer.tar \
&& mv PaddleOCR-VL_infer PaddleOCR-VL \
&& rm -f UVDoc_infer.tar PP-LCNet_x1_0_doc_ori_infer.tar PP-DocLayoutV2_infer.tar PaddleOCR-VL_infer.tar \
&& mkdir -p "${HOME}/.paddlex/fonts" \
&& wget -q -P "${HOME}/.paddlex/fonts" https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/fonts/PingFang-SC-Regular.ttf; \
fi
RUN chown -R paddleocr:paddleocr /home/paddleocr
USER paddleocr
EXPOSE 8080
# PaddleOCR-VL 服务默认监听 8080,接口为 POST /layout-parsing
CMD ["paddlex", "--serve", "--pipeline", "PaddleOCR-VL"]3. 构建与启动
在 OCR 服务器进入部署目录(示例):
bash
cd /opt/paddle-ocr/gpu-cu1183.1 一键构建并启动
bash
docker compose --env-file .env -f compose.yaml up -d --build3.2 查看日志
bash
docker logs -f paddleocr-vl-api看到类似以下日志说明服务已启动:
Uvicorn running on http://0.0.0.0:8080
4. 验证服务可用
4.1 健康检查
bash
curl -fsS http://127.0.0.1:15000/health4.2 curl 调用(URL 模式)
bash
curl -sS -X POST "http://127.0.0.1:15000/layout-parsing" \
-H "Content-Type: application/json" \
-d '{"file":"https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png","fileType":1,"visualize":false}' \
| head -c 20004.3 Python 调用(Base64 模式,最通用)
bash
python3 - <<'PY'
import base64
import json
import urllib.request
API_URL = "http://127.0.0.1:15000/layout-parsing"
IMG_PATH = "/path/to/test.jpg" # 替换为实际图片路径
with open(IMG_PATH, "rb") as f:
b64 = base64.b64encode(f.read()).decode("ascii")
payload = {
"file": b64,
"fileType": 1,
"visualize": False,
}
data = json.dumps(payload).encode("utf-8")
req = urllib.request.Request(API_URL, data=data, headers={"Content-Type": "application/json"})
resp = urllib.request.urlopen(req, timeout=300)
print("status:", resp.status)
print(resp.read(3000))
PY4.4 Java 调用示例(JDK 11+ HttpClient)
说明:以下示例演示如何用 Java 直接调用 OCR 服务(不依赖 Spring)。
java
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.nio.file.Files;
import java.nio.file.Path;
import java.time.Duration;
import java.util.Base64;
public class PaddleOcrVlClientDemo {
public static void main(String[] args) throws Exception {
String apiUrl = "http://127.0.0.1:15000/layout-parsing";
Path img = Path.of("/path/to/test.jpg");
String b64 = Base64.getEncoder().encodeToString(Files.readAllBytes(img));
String json = "{\"file\":\"" + b64 + "\",\"fileType\":1,\"visualize\":false}";
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(apiUrl))
.timeout(Duration.ofMinutes(10))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(json))
.build();
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println("status: " + response.statusCode());
System.out.println(response.body().substring(0, Math.min(2000, response.body().length())));
}
}5. Postman 调用指南(避免踩坑)
5.1 正确配置
- Method :
POST - URL :
http://<OCR服务器IP>:15000/layout-parsing - Body :选择
raw,右侧类型选择 JSON(非常关键) - Headers :确保
Content-Type: application/json
示例请求体(URL 模式):
json
{
"file": "https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png",
"fileType": 1,
"visualize": false
}示例请求体(Base64 模式):
json
{
"file": "<粘贴整段base64字符串>",
"fileType": 1,
"visualize": false
}请求返回示例:
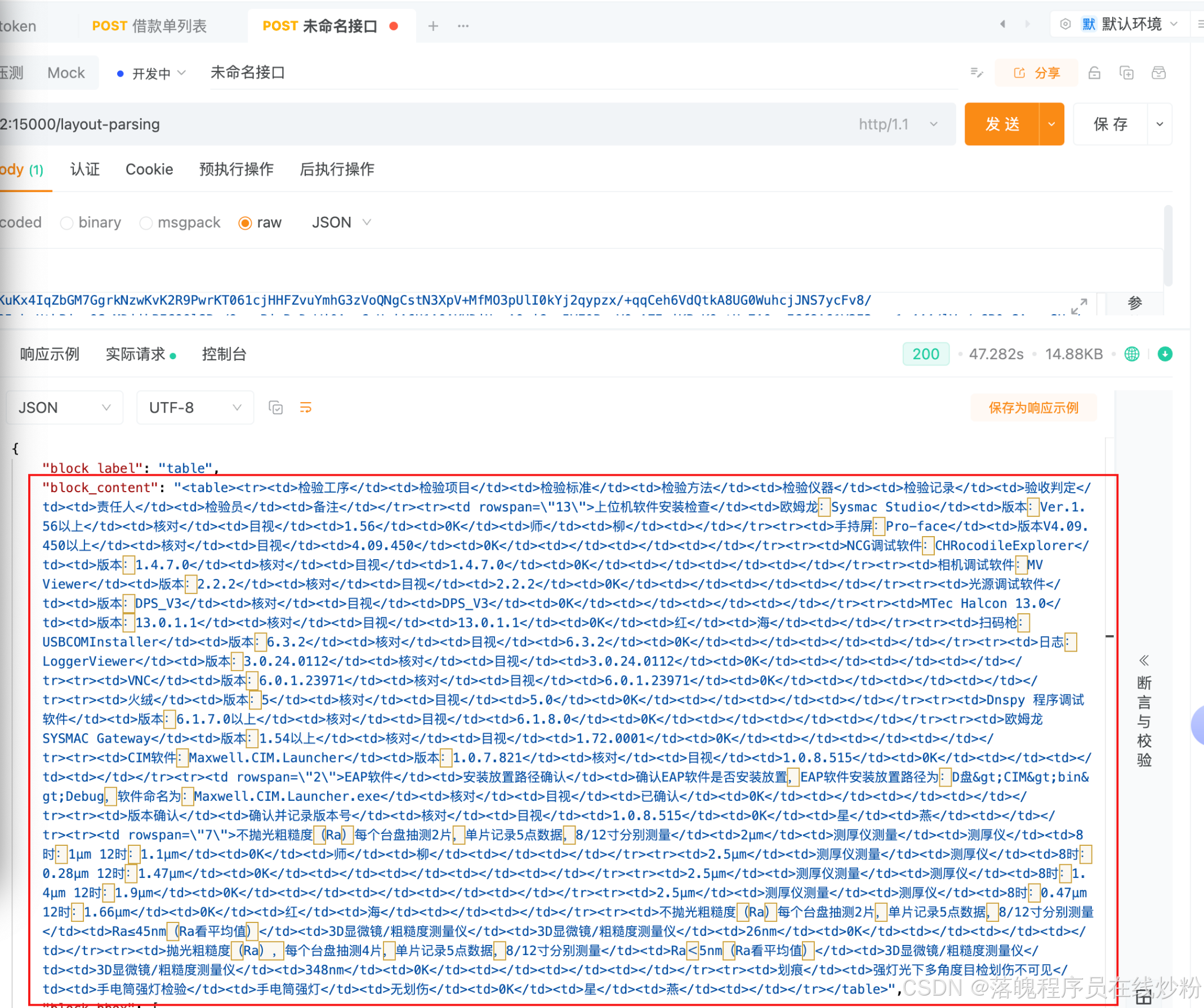
5.2 常见报错:Object of type bytes is not JSON serializable
这通常是 请求体没按 JSON 发出去 导致服务端校验失败,PaddleX 在序列化校验错误时又遇到 bytes 触发二次异常。
排查清单:
- Body 是否为
raw -> JSON(而不是Text/form-data/binary) Content-Type是否为application/json- 请求体是否被引号包成一个"整体字符串"(错误)
5.3 大图片 Base64 容易踩的坑
大图片 Base64 可能在复制/粘贴过程中被换行或截断,导致 JSON 解析失败。
建议:
- 优先使用 URL 模式(
file传 URL) - 或者将 Base64 写入文件后全选复制(避免终端截断)
6. Python:生成 Base64 并写入 bs64.txt(推荐用于 Postman 粘贴)
在本地(或任意机器)执行:
bash
python3 - <<'PY'
import base64
from pathlib import Path
p = Path("/Users/lyk/Downloads/OCR6.png")
out = Path("/Users/lyk/Downloads/bs64.txt")
data = base64.b64encode(p.read_bytes()).decode("ascii")
out.write_text(data, encoding="utf-8")
print(f"wrote base64 to: {out} (len={len(data)})")
PY然后打开 bs64.txt 全选复制,粘贴到 Postman 的 JSON 请求体 file 字段。
7. 多 GPU 使用说明
7.1 让容器可见多张卡
修改 compose.yaml 的:
device_ids: ["0", "1", "2", "3"]
然后重建容器(不一定需要重建镜像):
bash
cd /opt/paddle-ocr/gpu-cu118
docker compose --env-file .env -f compose.yaml up -d --force-recreate7.2 性能预期(很重要)
日志若提示类似:
PaddleOCR-VL-0.9B local model only supports batch size of 1
通常意味着:
- 单次请求并不一定能利用多卡加速(更可能只用到一张卡)。
- 多卡更常见的收益是:提升并发吞吐。
如需更强的并发吞吐,推荐做法:
- 启动多个实例(每个实例绑定一张卡、不同端口),再通过 Nginx 或上层业务做负载均衡。
8. 常见问题排查
8.1 apt-get update 卡住 / Ign: ... InRelease
原因多为 build 阶段 DNS/VPN/IPv6 路由问题。
解决手段:
compose.yaml增加build.network: hostpipeline.Dockerfile强制 IPv4 + 重试 + 超时(本文已包含)
8.2 ImportError: libgthread-2.0.so.0
这是 OpenCV(cv2)依赖缺失导致,安装 libglib2.0-0 可解决(本文 Dockerfile 已包含)。
8.3 Postman 大图片 Base64 报校验异常
优先使用 URL 模式,或用本文提供的 bs64.txt 文件方式粘贴 Base64。
9. 服务接口速查
- 健康检查 :
GET /health - 主接口 :
POST /layout-parsing- 请求 JSON:
file:Base64 字符串 或 文件 URLfileType:1=图片,0=PDFvisualize:是否返回可视化结果(建议false)
- 响应 JSON:重点关注
result.layoutParsingResults[].markdown.text
- 请求 JSON:
结束语
到此为止,你已经拥有一个可用的 PaddleOCR‑VL OCR 服务,能够用 curl / Python / Java / Postman 进行调用,并支持离线推理与多 GPU 可见配置。后续如果你希望做"多实例 + 负载均衡"来提升并发吞吐,也可以基于本文的 Compose 继续扩展。