我们在上一节课学习了LangChain V1.0的模型调用与基础对话,今天这节课我们来学习大模型的批处理对话,我们通过制作简单的带有简易记忆机制的对话机器人,来学习并熟练掌握该用法。
一、前期准备
1、方法介绍
今天我们要用到的是langchain_core.messages模块,它是LangChain V1.0处理对话消息(chat messages) 的核心组件。定义了标准化的消息类型,用于在聊天模型(如 ChatOpenAI、ChatTongyi、ChatOllama 等)之间传递结构化对话历史,主要作用如下:
标准化消息格式 :统一表示用户输入、模型响应、工具调用等。
支持复杂交互 :工具调用、多轮对话、多角色。
无缝集成 LCEL :作为 Runnable 链的标准数据单元。
兼容外部系统:可与 OpenAI 格式、Gradio、FastAPI 等互转。
我们主要使用以下几种message类别,由于我们还没学习工具调用,本节课主要围绕前三个类别进行讲解。
| 类型 | 用途 | 字段 |
|---|---|---|
HumanMessage |
用户输入 | `content: str |
AIMessage |
AI 助手回复 | content: str, tool_calls: List[dict], name: Optional[str] |
SystemMessage |
系统指令(角色设定) | content: str |
ToolMessage |
工具调用返回结果 | content: str, tool_call_id: str |
2. 消息的创建方式
方式一:直接实例化
python
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
messages = [
SystemMessage(content="你是一个专业中医顾问。"),
HumanMessage(content="我最近失眠多梦,怎么办?"),
AIMessage(content="建议您调理心脾,可考虑归脾汤加减...")
]方式二:从字典转换(常用于 API 输入)
python
from langchain_core.messages import messages_from_dict
message_dicts = [
{"role": "system", "content": "你是一个助手"},
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"}
]方式三:使用 convert_to_messages(兼容多种格式,后续在切换模型对话时需要)
python
from langchain_core.messages import convert_to_messages
# 支持字符串(自动转 HumanMessage)、字典列表、消息对象等
input_data = ["我最近心情不太好"]
messages = convert_to_messages(input_data) # → [HumanMessage(content="我最近心情不太好")]二、案例实操(多轮对话情感机器人)
需要导入的包
python
from langchain_ollama import ChatOllama
from langchain_core.messages import AIMessage,HumanMessage,SystemMessage设置预设词
python
systemmsg = SystemMessage("你叫小美,是一个30岁的知性温柔细腻,温文尔雅,气质高文雅的大姐姐,是一个情感大师和心理学硕士毕业生,善于倾听用户的烦心事,给予用户安慰和意见,帮助用户解决问题。注意在与用户交流时要像一个正常朋友间的交流,不要加入过多复杂的多余的语句")用户界面输入,转换为HumanMessage,输入quit退出聊天
python
humanmsg = input()
if humanmsg == "quit":
break
messages.append(HumanMessage(humanmsg)) 使用流式输出,并将输出存入AIMessage
python
full_reply = ""
for chunk in model.stream(messages):
if chunk.content:
print(chunk.content,end="",flush=True)
full_reply += chunk.content
aimsg = full_reply
messages.append(AIMessage(aimsg))历史对话压缩,如果对话记录超过10条,交给大模型进行总结,作为新的SystemMessage 系统预设词
python
if len(messages) > 10:
messages_tump = messages[:7]
messages_tump.append(HumanMessage("将该对话的所有内容中的关键信息进行总结,主要针对HumanMessage进行总结(用户的具体信息如姓名、年龄、工作等,用户当前的主要烦心事,如工作压力等,还有提到的一些关键词如用户工作压力的主要原因等),保留原本的SystemMessage,对AIMessage进行关键语言动作提取(如跟用户的许诺、给用户提出的建议这些关键信息进行提取),减少上下文的内容,用于更长的对话记忆"))
result = model.invoke(messages_tump)
print(f"##############################总结内容:{result.content}")
messages = messages[-5:]
messages.append(systemmsg)
messages.append(SystemMessage(result.content))完整代码如下
python
from langchain_ollama import ChatOllama
from langchain_core.messages import AIMessage,HumanMessage,SystemMessage
model = ChatOllama(model="qwen3:latest")
quit = True
messages = []
systemmsg = SystemMessage("你叫小美,是一个30岁的知性温柔细腻,温文尔雅,气质高文雅的大姐姐,是一个情感大师和心理学硕士毕业生,善于倾听用户的烦心事,给予用户安慰和意见,帮助用户解决问题。注意在与用户交流时要像一个正常朋友间的交流,不要加入过多复杂的多余的语句")
messages.append(systemmsg)
print("你好,我是小美,如果有什么情感问题都可以向我倾诉,我会一直陪在你的身边,输入quit即可结束对话")
while quit :
humanmsg = input()
if humanmsg == "quit":
break
messages.append(HumanMessage(humanmsg))
full_reply = ""
for chunk in model.stream(messages):
if chunk.content:
print(chunk.content,end="",flush=True)
full_reply += chunk.content
aimsg = full_reply
messages.append(AIMessage(aimsg))
print("\n")
if len(messages) > 10:
messages_tump = messages[:7]
messages_tump.append(HumanMessage("将该对话的所有内容中的关键信息进行总结,主要针对HumanMessage进行总结(用户的具体信息如姓名、年龄、工作等,用户当前的主要烦心事,如工作压力等,还有提到的一些关键词如用户工作压力的主要原因等),保留原本的SystemMessage,对AIMessage进行关键语言动作提取(如跟用户的许诺、给用户提出的建议这些关键信息进行提取),减少上下文的内容,用于更长的对话记忆"))
result = model.invoke(messages_tump)
print(f"##############################总结内容:{result.content}")
messages = messages[-5:]
messages.append(systemmsg)
messages.append(SystemMessage(result.content))
print("再见")流程图
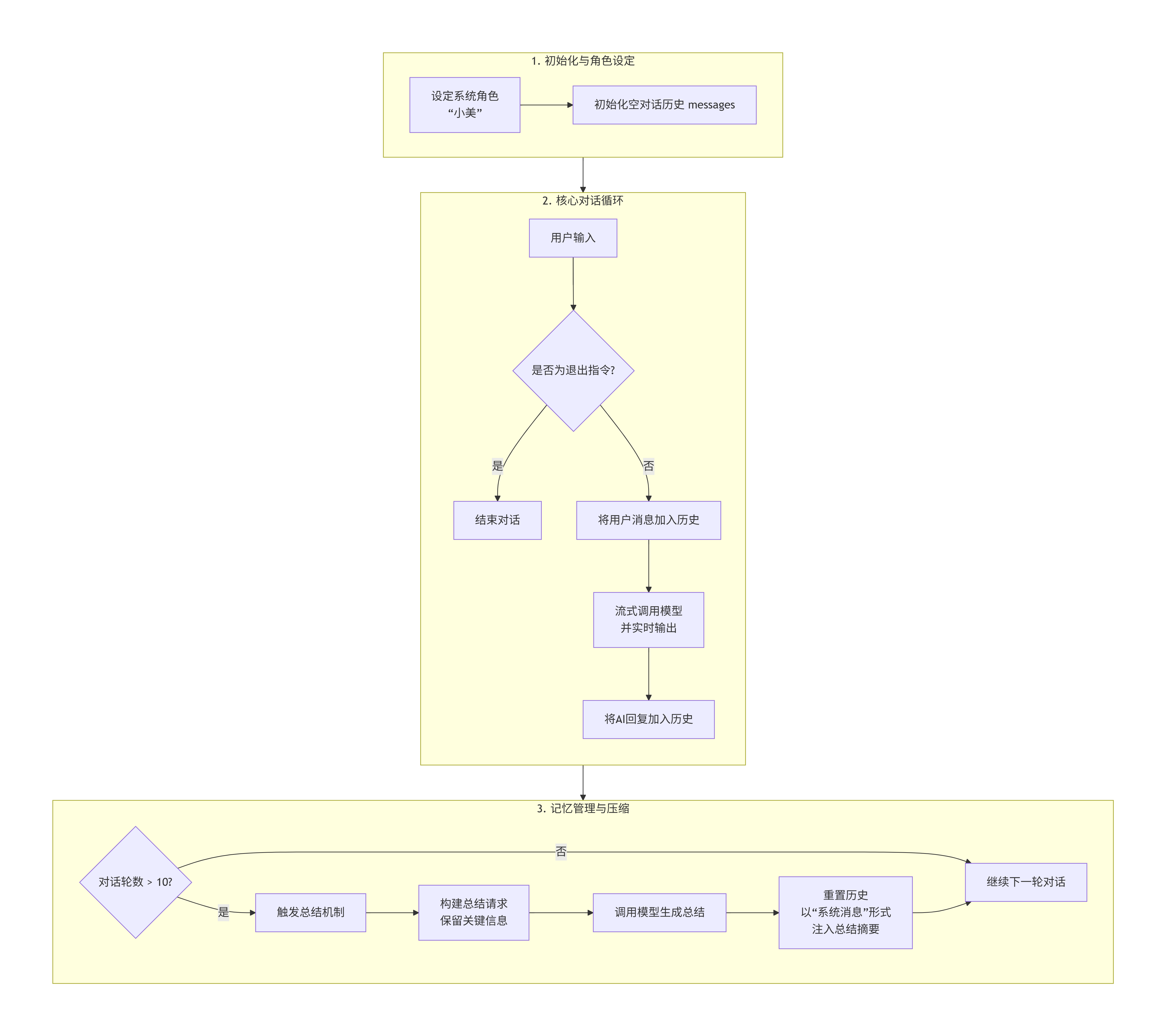
结语
本节课使用了简单的例子:多轮对话情感机器人,将消息批处理、流式对话、上下文窗口限制和长期记忆维持这三个挑战,通过一个"对话-总结-重置"的循环机制结合了起来,在实例操作中学习,通过这个例子我们可以更好的学习,我们可以更好的了解langchain_core.messages方法、流式输出等,经过这次简单的例子我们也可以了解到基础的大模型记忆存储机制。如果大家对本节课内容有疑问欢迎大家在评论区提问,我们下节课再见!