在之前的章节中,我们讨论了正态分布和中心极限定理,那是解决"怎么算 P 值"的问题。
但在工业界实战中,毁掉一个实验的往往不是 P 值算错了,而是数据源头就错了。
你以为你写了一行 hash(uid) % 2,实验组和对照组就天生平等了吗?
你以为配置了 50% vs 50% 的流量,回收的数据就一定是这个比例吗?
今天我们要聊的是 AB 实验的物理根基------随机化 (Randomization) ,以及当这个根基出现裂痕时,那个最可怕的幽灵------SRM (Sample Ratio Mismatch)。
1. 为什么我们需要随机化?------寻找平行宇宙
做 AB 实验的终极目标是因果推断 (Causal Inference) 。
我们想知道:"如果用户 A 没有用这个策略,他的表现会怎样?"
这是一个反事实 (Counterfactual) 问题。现实中我们无法把用户 A 劈成两半,一半去 A 组,一半去 B 组。
所以,我们退而求其次,试图构建两个平行宇宙:
- 宇宙 A (实验组):一群用户接受策略。
- 宇宙 B (对照组):另一群用户不接受策略。
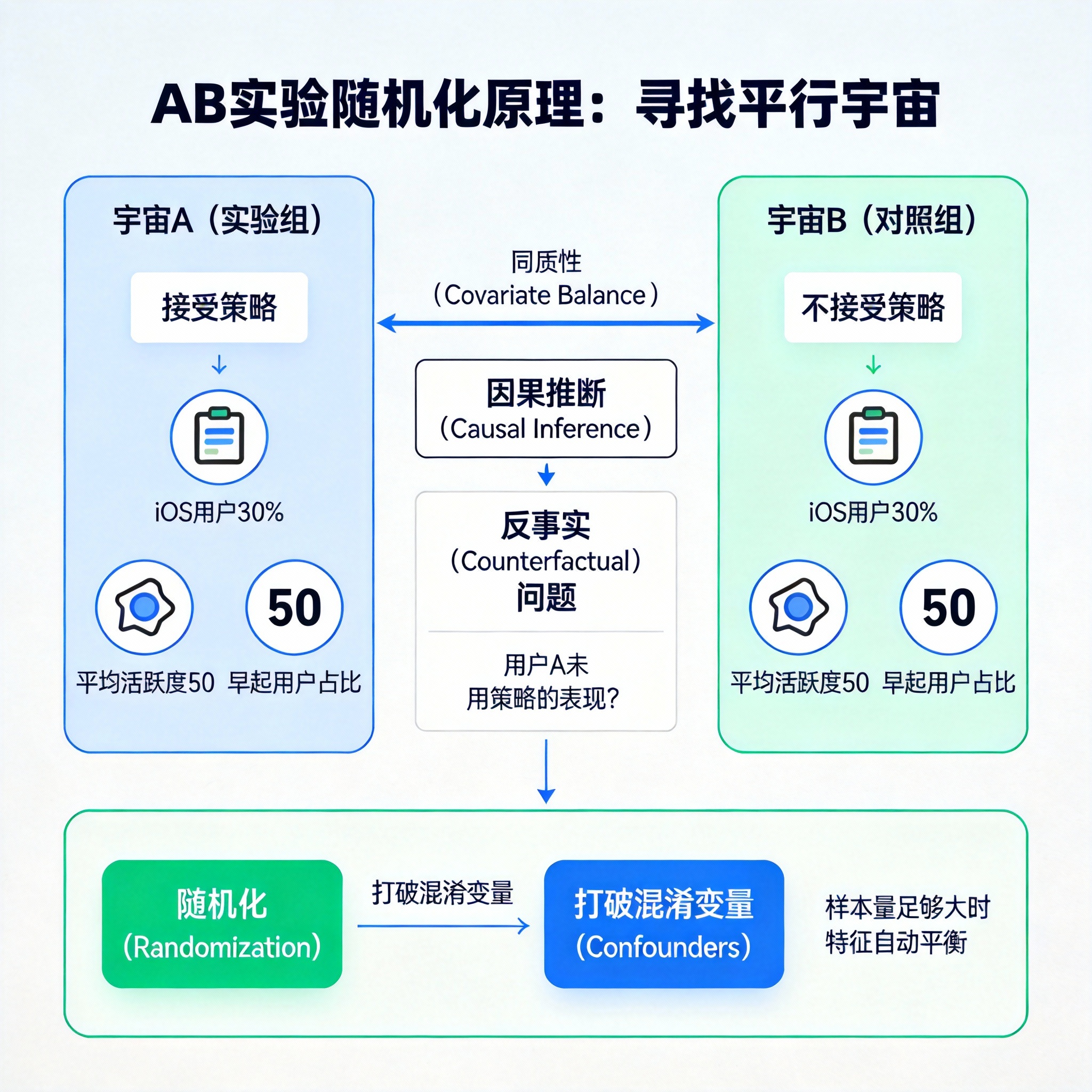 ### 核心概念:同质性 (Homogeneity) 为了让宇宙 B 能完美代表"没接受策略时的宇宙 A",这两个组必须满足**同质性**(学术上称为 **Covariate Balance**)。
### 核心概念:同质性 (Homogeneity) 为了让宇宙 B 能完美代表"没接受策略时的宇宙 A",这两个组必须满足**同质性**(学术上称为 **Covariate Balance**)。
这意味着:除了策略 (Treatment) 不同,A 组和 B 组在其他所有特征上必须是分布一致的。
- A 组有 30% 的 iOS 用户,B 组也得有 30%。
- A 组平均活跃度是 50,B 组也得是 50。
- A 组有多少"早起的鸟儿",B 组也得有多少。
随机化 (Randomization) 是上帝赐予我们打破混淆变量 (Confounders) 的唯一物理手段。它保证了在样本量足够大时,所有已知的(如机型)和未知的(如用户心情)特征,在两组间自动平衡。
2. 当随机失效时:选择偏差 (Selection Bias)
如果同质性被破坏,实验结果就是垃圾。这就是选择偏差。
经典案例:早起的鸟儿
假设你的分流算法写的有问题,跟时间戳耦合了:
- 早上 8:00 - 12:00 来的用户更容易分到 A 组。
- 晚上 20:00 - 24:00 来的用户更容易分到 B 组。
结果 A 组转化率大涨。
是策略有效吗? 不一定。可能是因为早上来的用户本身就是"高意向用户"(早起抢购),而晚上来的都是"闲逛党"。
在这里,"进入时间"成了一个混淆变量,它既影响了分组,又影响了转化率。你的策略效果被偏差 (Bias) 污染了。
3. 工业界最大杀手:SRM (Sample Ratio Mismatch)
在教科书里,随机化通常是完美的。但在复杂的分布式系统中,随机化极其脆弱。
最典型的症状就是 SRM 。
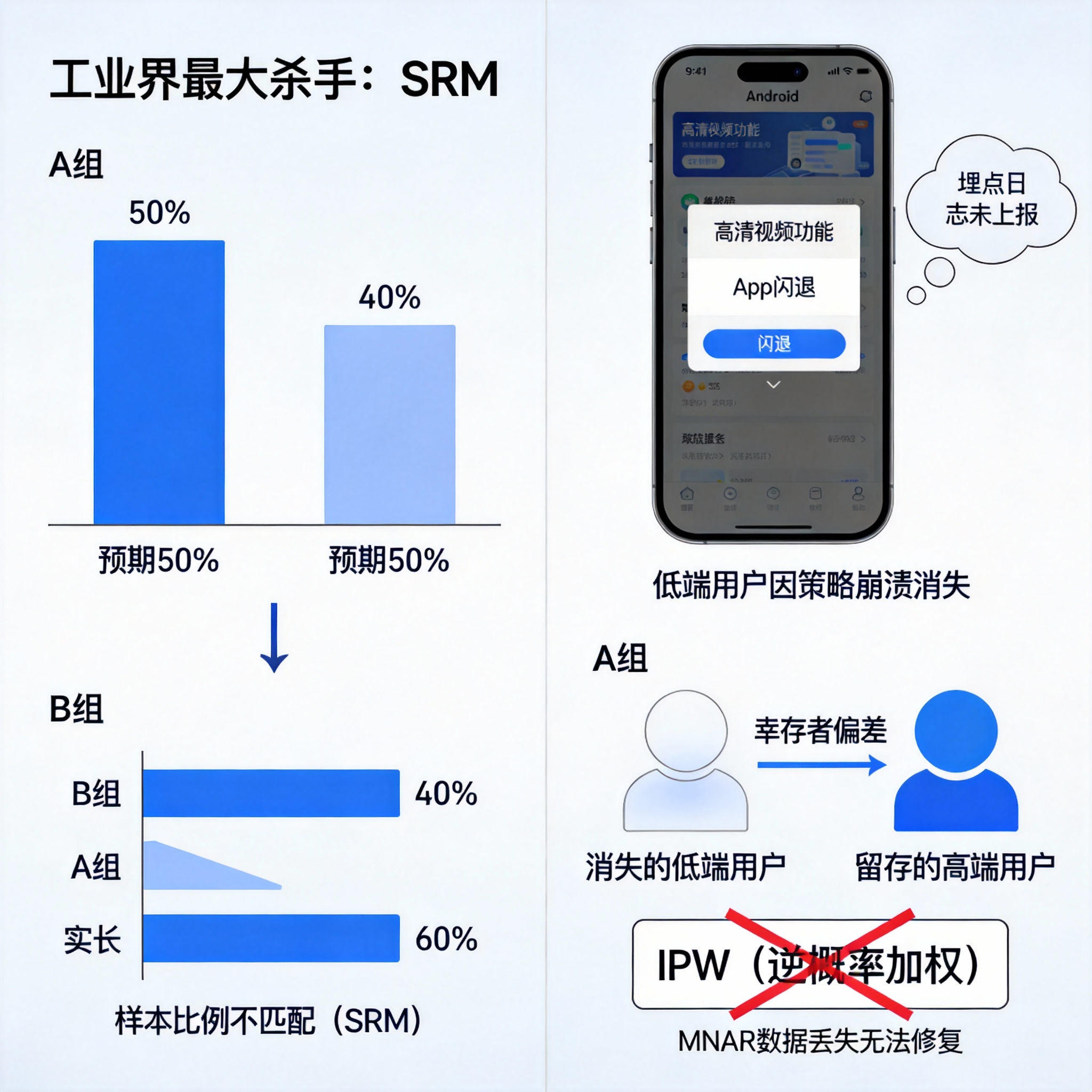
3.1 什么是 SRM?
- 预期 :你配置的分流比例是 50:50。
- 实际 :实验跑完,你统计样本量发现是 40:60。
很多新手会觉得:"哎呀,可能是随机波动吧,或者 A 组人少点也没事,反正算的是人均值 (Mean)。"
大错特错。
3.2 为什么 SRM 意味着实验报废?
SRM 几乎总是意味着非随机的样本丢失 (Non-random Attrition) ,也就是幸存者偏差。
恐怖故事:Crash 的 A 组
- 策略:A 组上线了一个高清视频功能。
- Bug:这个功能在低端安卓机上会导致 App 闪退 (Crash)。
- 现象 :
- 低端安卓用户分到了 A 组。
- App 启动 -> 触发实验 -> 闪退。
- 关键点:因为闪退了,埋点日志没有发送成功,或者根本没来得及上报曝光。
- 结果:A 组的数据里,低端用户"消失"了。A 组剩下的全是高端机用户(幸存者)。
- 数据表现 :
- 样本量:A 组比 B 组少了 10% (SRM 出现)。
- 人均时长:A 组暴涨(因为剩下的都是高端用户)。
- 结论:你以为策略大获全胜,实际上你刚刚制造了一个重大事故。
3.3 为什么"加权修复"救不了?
有人问:"既然 A 组少了低端用户,那我给 A 组现有的低端用户加权 (IPW, Inverse Probability Weighting) 不行吗?"
不行。
因为你丢失的数据是 MNAR (Missing Not At Random) 。
你丢失的不是随机的低端用户,而是**"由于使用了你的策略而崩溃"**的那批特定用户。这部分信息永久丢失了,任何数学补救都是自欺欺人。
4. 检测手段:卡方检验 (Chi-Square Test)
在看任何业务指标(GMV、转化率)之前,第一眼必须看样本量比例。这是实验的"看门狗"。
我们要检验的是:实际观察到的样本分布 (OOO) 与理论预期分布 (EEE) 是否存在显著差异?
核心公式
χ2=∑(Oi−Ei)2Ei \chi^2 = \sum \frac{(O_i - E_i)^2}{E_i} χ2=∑Ei(Oi−Ei)2
- OiO_iOi (Observed):实际观测到的 A/B 组样本量。
- EiE_iEi (Expected):理论上应该有的样本量(总样本量 ×\times× 配置比例)。
判罚标准
- 计算出的 P 值 (P-value of Chi-Square)。
- 铁律 :如果 P<0.001P < 0.001P<0.001 (极度显著),说明样本比例严重失调。
- 动作 :立刻停止实验。不要看任何业务指标(看了也是错的)。
- 归因:排查分流服务 Bug、客户端日志上报丢失、策略引起的崩溃或阻断。
总结
- 随机化是因果推断的灵魂:它确保了 A/B 两组互为"平行宇宙"。
- SRM 是矿井里的金丝雀:一旦样本比例不对(SRM),往往预示着严重的系统性偏差(如 Crash、性能问题)。
- 先看比例,再看指标 :如果样本量本身都不平,后续所有的 T 检验、P 值、置信区间统统作废。不要试图在错误的样本上通过数学技巧找回真理。
如果这篇文章帮你理清了思路,不妨点个关注。我会持续分享 AB 实验、因果推断的硬核实战笔记,拒绝水文,只讲干货。
